MedLM est une famille de modèles de fondation affinés pour le secteur de la santé. Med-PaLM 2 est l'un des modèles textuels développés par Google Research qui alimente MedLM. Il s'agit du premier système d'IA à atteindre un niveau d'expertise humain pour répondre aux questions types de l'US Medical Licensing Examination (USMLE). Le développement de ces modèles a été influencé par les besoins spécifiques des clients, tels que des réponses à des questions médicales et la rédaction de synthèses.
Fiche de modèle MedLM
La fiche de modèle MedLM décrit les détails du modèle, tels que l'utilisation prévue, la présentation des données et les informations de sécurité. Cliquez sur le lien suivant pour télécharger une version PDF de la fiche de modèle MedLM :
Télécharger la fiche de modèle MedLM
Cas d'utilisation
- Systèmes de questions-réponses : fournir des réponses sous forme de texte aux questions médicales.
- Synthèse : rédiger une version plus courte d'un document (synthèse après visite, ou note d'anamnèse et d'examen clinique) qui intègre des informations pertinentes sur le texte d'origine.
Pour en savoir plus sur la conception de requêtes textuelles, consultez Présentation des stratégies de requête.
Requête HTTP
MedLM-medium (medlm-medium) :
POST https://us-central1-aiplatform.googleapis.com/v1/projects/{PROJECT_ID}/locations/us-central1/publishers/google/models/medlm-medium:predict
MedLM-large (medlm-large) :
POST https://us-central1-aiplatform.googleapis.com/v1/projects/{PROJECT_ID}/locations/us-central1/publishers/google/models/medlm-large:predict
Pour en savoir plus, consultez la méthode predict.
Versions de modèle
MedLM fournit les modèles suivants :
- MedLM-medium (
medlm-medium) - MedLM-large (
medlm-large)
Le tableau suivant contient les versions de modèles stables disponibles :
| modèle medlm-medium | Date de disponibilité |
|---|---|
medlm-medium |
13 décembre 2023 |
| modèle medlm-large | Date de disponibilité |
|---|---|
medlm-large |
13 décembre 2023 |
MedLM-medium et MedLM-large ont des points de terminaison distincts et offrent aux clients une flexibilité supplémentaire pour leurs cas d'utilisation. MedLM-medium fournit aux clients de meilleurs débits et inclut des données plus récentes. MedLM-large est le même modèle que celui de la phase preview. Les deux modèles continueront d'être actualisés tout au long du cycle de vie du produit. Sur cette page, "MedLM" fait référence aux deux modèles.
Pour en savoir plus, consultez la page Versions et cycle de vie des modèles.
Filtres et attributs de sécurité MedLM
Le contenu traité via l'API MedLM est évalué en fonction d'une liste d'attributs de sécurité, y compris les "catégories dangereuses" et les sujets pouvant être considérés comme sensibles. Si une réponse de remplacement s'affiche, par exemple "Je ne peux pas vous aider, car je ne suis qu'un modèle de langage", cela signifie que la requête ou la réponse déclenche un filtre de sécurité.
Seuils de sécurité
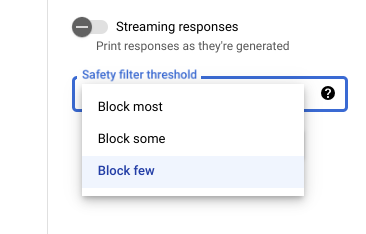
Avec Vertex AI Studio, vous pouvez utiliser un seuil de filtre de sécurité ajustable pour déterminer la probabilité d'affichage de réponses pouvant être dangereuses. Les réponses du modèle sont bloquées, car elles pourraient comporter des contenus relevant du harcèlement, incitant à la haine, dangereux ou à caractère sexuel explicite. Le paramètre de filtre de sécurité est situé à droite de la zone de requête dans Vertex AI Studio. Vous avez le choix entre trois options : block most, block some et block few.
Tester vos seuils de confiance et de gravité
Vous pouvez tester les filtres de sécurité de Google et définir des seuils de confiance adaptés à votre entreprise. Ces seuils vous permettent de prendre des mesures complètes pour détecter les contenus qui ne respectent pas les règles d'utilisation ou les Conditions d'utilisation de Google, et d'agir en conséquence.
Les scores de confiance ne sont que des prédictions. Vous ne devez pas vous appuyer sur ces scores pour la fiabilité ou la précision. Google n'est pas responsable de l'interprétation ni de l'utilisation de ces scores pour les décisions commerciales.
Pratiques recommandées
Pour utiliser cette technologie de manière sécurisée et responsable, il est également important de prendre en compte d'autres risques spécifiques à votre cas d'utilisation, aux utilisateurs et au contexte commercial en plus des protections techniques intégrées.
Nous vous recommandons de suivre les étapes ci-dessous :
- Évaluez les risques de sécurité de votre application.
- Envisagez de faire des ajustements pour limiter les risques de sécurité.
- Effectuez des tests de sécurité adaptés à votre cas d'utilisation.
- Sollicitez les commentaires des utilisateurs et surveillez le contenu.
Pour en savoir plus, consultez les recommandations de Google concernant l'IA responsable.
Corps de la requête
{
"instances": [
{
"content": string
}
],
"parameters": {
"temperature": number,
"maxOutputTokens": integer,
"topK": integer,
"topP": number
}
}
Utilisez les paramètres suivants pour les modèles medlm-medium et medlm-large.
Pour en savoir plus, consultez la section Concevoir des requêtes textuelles.
| Paramètre | Description | Valeurs acceptables |
|---|---|---|
|
Saisie de texte pour générer une réponse du modèle. Les requêtes peuvent inclure un préambule, des questions, des suggestions, des instructions ou des exemples. | Texte |
|
La température est utilisée pour l'échantillonnage pendant la génération des réponses, qui se produit lorsque topP et topK sont appliqués. La température permet de contrôler le degré de hasard dans la sélection des jetons.
Les températures inférieures sont idéales pour les requêtes qui nécessitent une réponse moins ouverte ou créative, tandis que des températures plus élevées peuvent conduire à des résultats plus diversifiés ou créatifs. Une température de 0 signifie que les jetons de probabilité les plus élevés sont toujours sélectionnés. Dans ce cas, les réponses pour une requête donnée sont principalement déterministes, mais une petite quantité de variation est toujours possible.
Si le modèle renvoie une réponse trop générique ou trop courte, ou s'il renvoie une réponse de remplacement, essayez d'augmenter la température. |
|
|
Le nombre maximal de jetons pouvant être générés dans la réponse. Un jeton correspond environ à quatre caractères. 100 jetons correspondent environ à 60-80 mots.
Spécifiez une valeur inférieure pour obtenir des réponses plus courtes et une valeur supérieure pour des réponses potentiellement plus longues. |
|
|
Top-K modifie la façon dont le modèle sélectionne les jetons pour la sortie. Une valeur top-K de 1 signifie que le prochain jeton sélectionné est le plus probable parmi tous les jetons du vocabulaire du modèle (une stratégie également appelée décodage glouton), tandis qu'une valeur top-K de 3 signifie que le jeton suivant est sélectionné parmi les trois jetons les plus probables à l'aide de la température.
Pour chaque étape de sélection des jetons, les jetons top-K avec les probabilités les plus élevées sont échantillonnés. Les jetons sont ensuite filtrés en fonction du top-P avec le jeton final sélectionné à l'aide de l'échantillonnage de température. Spécifiez une valeur inférieure pour obtenir des réponses moins aléatoires et une valeur supérieure pour des réponses plus aléatoires. |
|
|
Top-P modifie la façon dont le modèle sélectionne les jetons pour la sortie. Les jetons sont sélectionnés en partant de la probabilité la plus forte (voir top-K) à la plus basse, jusqu'à ce que la somme de leurs probabilités soit égale à la valeur top-P. Par exemple, si les jetons A, B et C ont une probabilité de 0,3, 0,2 et 0,1 et que la valeur de top-P est 0.5, le modèle sélectionne A ou B comme jeton suivant à l'aide de la température et exclut le jeton C comme candidat.
Spécifiez une valeur inférieure pour obtenir des réponses moins aléatoires et une valeur supérieure pour des réponses plus aléatoires. |
|
Exemple de requête
Lorsque vous utilisez l'API MedLM, il est important d'intégrer le prompt engineering. Par exemple, nous vous recommandons vivement de fournir des instructions pertinentes et spécifiques à la tâche au début de chaque requête. Pour en savoir plus, consultez Présentation des requêtes.
REST
Avant d'utiliser les données de requête, effectuez les remplacements suivants :
PROJECT_ID: ID de votre projetMEDLM_MODEL: modèle MedLM (medlm-mediumoumedlm-large)
Méthode HTTP et URL :
POST https://us-central1-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/publishers/google/models/MEDLM_MODEL:predict
Corps JSON de la requête :
{
"instances": [
{
"content": "Question: What causes you to get ringworm?"
}
],
"parameters": {
"temperature": 0,
"maxOutputTokens": 256,
"topK": 40,
"topP": 0.95
}
}
Pour envoyer votre requête, choisissez l'une des options suivantes :
curl
Enregistrez le corps de la requête dans un fichier nommé request.json.
Exécutez la commande suivante dans le terminal pour créer ou écraser ce fichier dans le répertoire actuel :
cat > request.json << 'EOF'
{
"instances": [
{
"content": "Question: What causes you to get ringworm?"
}
],
"parameters": {
"temperature": 0,
"maxOutputTokens": 256,
"topK": 40,
"topP": 0.95
}
}
EOFExécutez ensuite la commande suivante pour envoyer votre requête REST :
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://us-central1-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/publishers/google/models/MEDLM_MODEL:predict"
PowerShell
Enregistrez le corps de la requête dans un fichier nommé request.json.
Exécutez la commande suivante dans le terminal pour créer ou écraser ce fichier dans le répertoire actuel :
@'
{
"instances": [
{
"content": "Question: What causes you to get ringworm?"
}
],
"parameters": {
"temperature": 0,
"maxOutputTokens": 256,
"topK": 40,
"topP": 0.95
}
}
'@ | Out-File -FilePath request.json -Encoding utf8Exécutez ensuite la commande suivante pour envoyer votre requête REST :
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://us-central1-aiplatform.googleapis.com/v1/projects/PROJECT_ID/locations/us-central1/publishers/google/models/MEDLM_MODEL:predict" | Select-Object -Expand Content
Corps de la réponse
{
"predictions": [
{
"content": string,
"citationMetadata": {
"citations": [
{
"startIndex": integer,
"endIndex": integer,
"url": string,
"title": string,
"license": string,
"publicationDate": string
}
]
},
"logprobs": {
"tokenLogProbs": [ float ],
"tokens": [ string ],
"topLogProbs": [ { map<string, float> } ]
},
"safetyAttributes": {
"categories": [ string ],
"blocked": boolean,
"scores": [ float ],
"errors": [ int ]
}
}
],
"metadata": {
"tokenMetadata": {
"input_token_count": {
"total_tokens": integer,
"total_billable_characters": integer
},
"output_token_count": {
"total_tokens": integer,
"total_billable_characters": integer
}
}
}
}
| Élément de réponse | Description |
|---|---|
content |
Résultat généré à partir du texte d'entrée. |
categories |
Noms à afficher des catégories d'attributs de sécurité associées au contenu généré. L'ordre correspond aux scores. |
scores |
Scores de confiance de chaque catégorie. Une valeur supérieure signifie une confiance plus élevée. |
blocked |
Option indiquant si l'entrée ou la sortie du modèle a été bloquée. |
errors |
Code d'erreur qui identifie la raison du blocage de l'entrée ou de la sortie. Pour obtenir la liste des codes d'erreur, consultez la section Filtres et attributs de sécurité. |
startIndex |
Index de la sortie de prédiction où la citation commence (inclus). La valeur doit être supérieure ou égale à 0 et inférieure à end_index. |
endIndex |
Index de la sortie de prédiction où la citation se termine (exclus). La valeur doit être supérieure à start_index et inférieure à len(output). |
url |
URL associée à cette citation. Si elle est présente, cette URL renvoie vers la page Web de la source de la citation. Les URL possibles incluent les sites Web d'actualités, les dépôts GitHub, etc. |
title |
Titre associé à cette citation. S'il est présent, il s'agit du titre de la source de la citation. Les titres possibles sont les titres des actualités, des livres, etc. |
license |
Licence associée à cette citation. Si elle est présente, il s'agit de la licence de la source de la citation. Les licences possibles incluent les licences de code, telles que la licence MIT. |
publicationDate |
Date de publication associée à cette citation. Si elle est présente, il s'agit de la date à laquelle la source de la citation a été publiée. Les formats possibles sont AAAA, AAAA-MM, AAAA-MM-JJ. |
input_token_count |
Nombre de jetons d'entrée. Il s'agit du nombre total de jetons pour l'ensemble des requêtes, préfixes et suffixes. |
output_token_count |
Nombre de jetons de sortie. Il s'agit du nombre total de jetons dans content pour l'ensemble des prédictions. |
tokens |
Jetons échantillonnés. |
tokenLogProbs |
Probabilités logarithmiques des jetons échantillonnés. |
topLogProb |
Jetons candidats les plus probables et leurs probabilités logarithmiques à chaque étape. |
logprobs |
Résultats du paramètre "logprobs". Le mappage 1-1 correspond à "candidates". |
Exemple de réponse
{
"predictions": [
{
"citationMetadata": {
"citations": []
},
"content": "\n\nAnswer and Explanation:\nRingworm is a fungal infection of the skin that is caused by a type of fungus called dermatophyte. Dermatophytes can live on the skin, hair, and nails, and they can be spread from person to person through direct contact or through contact with contaminated objects.\n\nRingworm can cause a variety of symptoms, including:\n\n* A red, itchy rash\n* A raised, circular border\n* Blisters or scales\n* Hair loss\n\nRingworm is most commonly treated with antifungal medications, which can be applied to the skin or taken by mouth. In some cases, surgery may be necessary to remove infected hair or nails.",
"safetyAttributes": {
"scores": [
1
],
"blocked": false,
"categories": [
"Health"
]
}
}
],
"metadata": {
"tokenMetadata": {
"outputTokenCount": {
"totalTokens": 140,
"totalBillableCharacters": 508
},
"inputTokenCount": {
"totalTokens": 10,
"totalBillableCharacters": 36
}
}
}
}