Gli host on-premise possono raggiungere un endpoint di previsione online di Vertex AI tramite internet pubblico o in privato tramite un'architettura di rete ibrida che utilizza Private Service Connect (PSC) su Cloud VPN o Cloud Interconnect. Entrambe le opzioni offrono la crittografia SSL/TLS. Tuttavia, l'opzione privata offre prestazioni molto migliori ed è quindi consigliata per le applicazioni critiche.
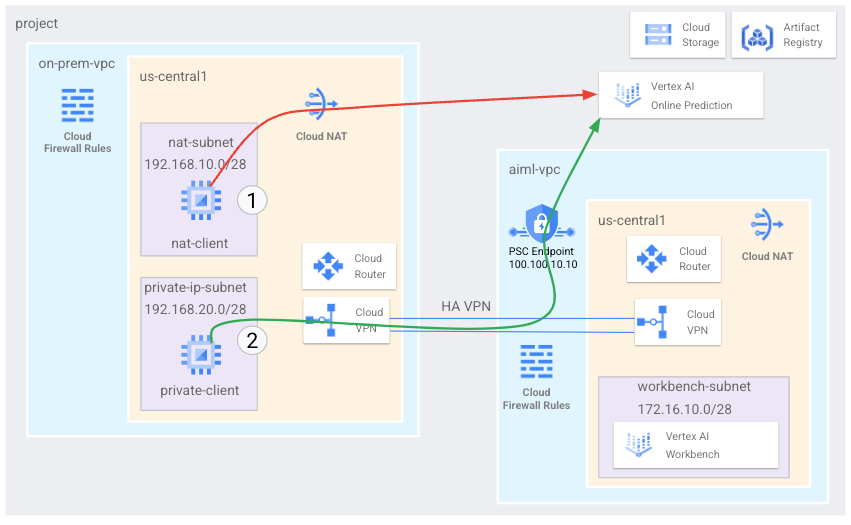
In questo tutorial utilizzi la VPN ad alta disponibilità (HA VPN) per accedere a un endpoint di previsione online sia pubblicamente, tramite Cloud NAT, sia privatamente, tra due reti Virtual Private Cloud che possono servire da base per la connettività privata multi-cloud e on-premise.
Questo tutorial è rivolto ad amministratori di reti aziendali, data scientist e ricercatori che hanno familiarità con Vertex AI, Virtual Private Cloud (VPC), la console Google Cloud e Cloud Shell. La conoscenza di Vertex AI Workbench è utile, ma non obbligatoria.
Obiettivi
- Crea due reti Virtual Private Cloud (VPC), come mostrato nel diagramma precedente:
- Uno (
on-prem-vpc) rappresenta una rete on-premise. - L'altro (
aiml-vpc) è per la creazione e il deployment di un modello di previsione online di Vertex AI.
- Uno (
- Esegui il deployment di gateway VPN ad alta disponibilità, tunnel Cloud VPN e router Cloud per connettere
aiml-vpceon-prem-vpc. - Crea ed esegui il deployment di un modello di previsione online di Vertex AI.
- Crea un endpoint Private Service Connect (PSC) per inoltrare le richieste di previsione online private al modello di cui è stato eseguito il deployment.
- Attiva la modalità di annuncio personalizzato di Cloud Router in
aiml-vpcper annunci route per l'endpoint Private Service Connect aon-prem-vpc. - Crea due istanze VM Compute Engine in
on-prem-vpcper rappresentare le applicazioni client:- Uno (
nat-client) invia richieste di previsione online tramite internet pubblico (tramite Cloud NAT). Questo metodo di accesso è indicato da una freccia rossa e dal numero 1 nel diagramma. - L'altra (
private-client) invia richieste di previsione in privato tramite VPN ad alta disponibilità. Questo metodo di accesso è indicato da una freccia verde e dal numero 2.
- Uno (
Costi
In questo documento vengono utilizzati i seguenti componenti fatturabili di Google Cloud:
Per generare una stima dei costi in base all'utilizzo previsto,
utilizza il calcolatore prezzi.
Al termine delle attività descritte in questo documento, puoi evitare l'addebito di ulteriori costi eliminando le risorse che hai creato. Per ulteriori informazioni, vedi Pulizia.
Prima di iniziare
-
In the Google Cloud console, go to the project selector page.
-
Select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
- Apri Cloud Shell per eseguire i comandi elencati in questo tutorial. Cloud Shell è un ambiente shell interattivo Google Cloud che ti consente di gestire i tuoi progetti e le tue risorse dal browser web.
- In Cloud Shell, imposta il progetto corrente sul tuo
ID progetto Google Cloud e memorizza lo stesso
ID progetto nella variabile di shell
projectid:projectid="PROJECT_ID" gcloud config set project ${projectid} -
Grant roles to your user account. Run the following command once for each of the following IAM roles:
roles/appengine.appViewer, roles/artifactregistry.admin, roles/compute.instanceAdmin.v1, roles/compute.networkAdmin, roles/compute.securityAdmin, roles/dns.admin, roles/iap.admin, roles/iap.tunnelResourceAccessor, roles/notebooks.admin, roles/oauthconfig.editor, roles/resourcemanager.projectIamAdmin, roles/servicemanagement.quotaAdmin, roles/iam.serviceAccountAdmin, roles/iam.serviceAccountUser, roles/servicedirectory.editor, roles/storage.admin, roles/aiplatform.usergcloud projects add-iam-policy-binding PROJECT_ID --member="user:USER_IDENTIFIER" --role=ROLE
Replace the following:
PROJECT_ID: your project ID.USER_IDENTIFIER: the identifier for your user account—for example,myemail@example.com.ROLE: the IAM role that you grant to your user account.
-
Enable the DNS, Artifact Registry, IAM, Compute Engine, Notebooks, and Vertex AI APIs:
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles.gcloud services enable dns.googleapis.com
artifactregistry.googleapis.com iam.googleapis.com compute.googleapis.com notebooks.googleapis.com aiplatform.googleapis.com
Crea le reti VPC
In questa sezione crei due reti VPC: una per creare un modello di previsione online ed eseguirne il deployment in un endpoint e l'altra per l'accesso privato a quell'endpoint. In ognuna delle due reti VPC, crea un router Cloud e un gateway Cloud NAT. Un gateway Cloud NAT fornisce connettività in uscita per le istanze di macchine virtuali (VM) Compute Engine senza indirizzi IP esterni.
Crea la rete VPC per l'endpoint di previsione online (aiml-vpc)
Crea la rete VPC:
gcloud compute networks create aiml-vpc \ --project=$projectid \ --subnet-mode=customCrea una subnet denominata
workbench-subnetcon un intervallo IPv4 principale di172.16.10.0/28:gcloud compute networks subnets create workbench-subnet \ --project=$projectid \ --range=172.16.10.0/28 \ --network=aiml-vpc \ --region=us-central1 \ --enable-private-ip-google-accessCrea un router Cloud regionale denominato
cloud-router-us-central1-aiml-nat:gcloud compute routers create cloud-router-us-central1-aiml-nat \ --network aiml-vpc \ --region us-central1Aggiungi un gateway Cloud NAT al router Cloud:
gcloud compute routers nats create cloud-nat-us-central1 \ --router=cloud-router-us-central1-aiml-nat \ --auto-allocate-nat-external-ips \ --nat-all-subnet-ip-ranges \ --region us-central1
Crea la rete VPC "on-premise" (on-prem-vpc)
Crea la rete VPC:
gcloud compute networks create on-prem-vpc \ --project=$projectid \ --subnet-mode=customCrea una subnet denominata
nat-subnetcon un intervallo IPv4 principale di192.168.10.0/28:gcloud compute networks subnets create nat-subnet \ --project=$projectid \ --range=192.168.10.0/28 \ --network=on-prem-vpc \ --region=us-central1Crea una subnet denominata
private-ip-subnetcon un intervallo IPv4 principale di192.168.20.0/28:gcloud compute networks subnets create private-ip-subnet \ --project=$projectid \ --range=192.168.20.0/28 \ --network=on-prem-vpc \ --region=us-central1Crea un router Cloud regionale denominato
cloud-router-us-central1-on-prem-nat:gcloud compute routers create cloud-router-us-central1-on-prem-nat \ --network on-prem-vpc \ --region us-central1Aggiungi un gateway Cloud NAT al router Cloud:
gcloud compute routers nats create cloud-nat-us-central1 \ --router=cloud-router-us-central1-on-prem-nat \ --auto-allocate-nat-external-ips \ --nat-all-subnet-ip-ranges \ --region us-central1
Crea l'endpoint Private Service Connect (PSC)
In questa sezione crei l'endpoint Private Service Connect (PSC) utilizzato dalle istanze VM nella rete on-prem-vpc per accedere all'endpoint di previsione online tramite l'API Vertex AI.
L'endpoint Private Service Connect (PSC) è un indirizzo IP interno della rete on-prem-vpc a cui i client della rete possono accedere direttamente. Questo endpoint viene creato eseguendo il deployment di una regola di inoltro che indirizza il traffico di rete corrispondente all'indirizzo IP dell'endpoint PSC a un pacchetto di API di Google.
L'indirizzo IP (100.100.10.10) dell'endpoint PSC verrà annunciato dal router Cloud aiml-cr-us-central1 come route annunciata personalizzata alla rete on-prem-vpc in un passaggio successivo.
Prenota gli indirizzi IP per l'endpoint PSC:
gcloud compute addresses create psc-ip \ --global \ --purpose=PRIVATE_SERVICE_CONNECT \ --addresses=100.100.10.10 \ --network=aiml-vpcCrea l'endpoint PSC:
gcloud compute forwarding-rules create pscvertex \ --global \ --network=aiml-vpc \ --address=psc-ip \ --target-google-apis-bundle=all-apisElenca gli endpoint PSC configurati e verifica che l'endpoint
pscvertexsia stato creato:gcloud compute forwarding-rules list \ --filter target="(all-apis OR vpc-sc)" --globalVisualizza i dettagli dell'endpoint PSC configurato e verifica che l'indirizzo IP sia
100.100.10.10:gcloud compute forwarding-rules describe pscvertex \ --global
Configura la connettività ibrida
In questa sezione crei due gateway VPN ad alta disponibilità connessi tra loro. Ogni gateway contiene un router Cloud e una coppia di tunnel VPN.
Crea il gateway VPN ad alta disponibilità per la rete VPC
aiml-vpc:gcloud compute vpn-gateways create aiml-vpn-gw \ --network=aiml-vpc \ --region=us-central1Crea il gateway VPN ad alta disponibilità per la rete VPC
on-prem-vpc:gcloud compute vpn-gateways create on-prem-vpn-gw \ --network=on-prem-vpc \ --region=us-central1Nella console Google Cloud, vai alla pagina VPN.
Nella pagina VPN, fai clic sulla scheda Gateway Cloud VPN.
Nell'elenco dei gateway VPN, verifica che siano presenti due gateway e che ciascuno abbia due indirizzi IP.
In Cloud Shell, crea un router Cloud per la rete
aiml-vpcVirtual Private Cloud:gcloud compute routers create aiml-cr-us-central1 \ --region=us-central1 \ --network=aiml-vpc \ --asn=65001Crea un router Cloud per la rete
on-prem-vpcVirtual Private Cloud:gcloud compute routers create on-prem-cr-us-central1 \ --region=us-central1 \ --network=on-prem-vpc \ --asn=65002
Crea i tunnel VPN per aiml-vpc
Crea un tunnel VPN denominato
aiml-vpc-tunnel0:gcloud compute vpn-tunnels create aiml-vpc-tunnel0 \ --peer-gcp-gateway on-prem-vpn-gw \ --region us-central1 \ --ike-version 2 \ --shared-secret [ZzTLxKL8fmRykwNDfCvEFIjmlYLhMucH] \ --router aiml-cr-us-central1 \ --vpn-gateway aiml-vpn-gw \ --interface 0Crea un tunnel VPN denominato
aiml-vpc-tunnel1:gcloud compute vpn-tunnels create aiml-vpc-tunnel1 \ --peer-gcp-gateway on-prem-vpn-gw \ --region us-central1 \ --ike-version 2 \ --shared-secret [bcyPaboPl8fSkXRmvONGJzWTrc6tRqY5] \ --router aiml-cr-us-central1 \ --vpn-gateway aiml-vpn-gw \ --interface 1
Crea i tunnel VPN per on-prem-vpc
Crea un tunnel VPN denominato
on-prem-vpc-tunnel0:gcloud compute vpn-tunnels create on-prem-tunnel0 \ --peer-gcp-gateway aiml-vpn-gw \ --region us-central1 \ --ike-version 2 \ --shared-secret [ZzTLxKL8fmRykwNDfCvEFIjmlYLhMucH] \ --router on-prem-cr-us-central1 \ --vpn-gateway on-prem-vpn-gw \ --interface 0Crea un tunnel VPN denominato
on-prem-vpc-tunnel1:gcloud compute vpn-tunnels create on-prem-tunnel1 \ --peer-gcp-gateway aiml-vpn-gw \ --region us-central1 \ --ike-version 2 \ --shared-secret [bcyPaboPl8fSkXRmvONGJzWTrc6tRqY5] \ --router on-prem-cr-us-central1 \ --vpn-gateway on-prem-vpn-gw \ --interface 1Nella console Google Cloud, vai alla pagina VPN.
Nella pagina VPN, fai clic sulla scheda Tunnel Cloud VPN.
Nell'elenco dei tunnel VPN, verifica che siano stati stabiliti quattro tunnel VPN.
Definizione di sessioni BGP
Cloud Router utilizza il protocollo BGP (Border Gateway Protocol) per scambiare le route tra la tua rete VPC (in questo caso aiml-vpc) e la tua rete on-premise (rappresentata da on-prem-vpc). Su Cloud Router, devi configurare un'interfaccia e un peer BGP per il tuo router on-premise.
L'abbinamento dell'interfaccia e della configurazione peer BGP crea una sessione BGP.
In questa sezione, creerai due sessioni BGP per aiml-vpc e altre due per on-prem-vpc.
Stabilisci sessioni BGP per aiml-vpc
In Cloud Shell, crea la prima interfaccia BGP:
gcloud compute routers add-interface aiml-cr-us-central1 \ --interface-name if-tunnel0-to-onprem \ --ip-address 169.254.1.1 \ --mask-length 30 \ --vpn-tunnel aiml-vpc-tunnel0 \ --region us-central1Crea il primo peer BGP:
gcloud compute routers add-bgp-peer aiml-cr-us-central1 \ --peer-name bgp-on-premises-tunnel0 \ --interface if-tunnel1-to-onprem \ --peer-ip-address 169.254.1.2 \ --peer-asn 65002 \ --region us-central1Crea la seconda interfaccia BGP:
gcloud compute routers add-interface aiml-cr-us-central1 \ --interface-name if-tunnel1-to-onprem \ --ip-address 169.254.2.1 \ --mask-length 30 \ --vpn-tunnel aiml-vpc-tunnel1 \ --region us-central1Crea il secondo peer BGP:
gcloud compute routers add-bgp-peer aiml-cr-us-central1 \ --peer-name bgp-on-premises-tunnel1 \ --interface if-tunnel2-to-onprem \ --peer-ip-address 169.254.2.2 \ --peer-asn 65002 \ --region us-central1
Stabilisci sessioni BGP per on-prem-vpc
Crea la prima interfaccia BGP:
gcloud compute routers add-interface on-prem-cr-us-central1 \ --interface-name if-tunnel0-to-aiml-vpc \ --ip-address 169.254.1.2 \ --mask-length 30 \ --vpn-tunnel on-prem-tunnel0 \ --region us-central1Crea il primo peer BGP:
gcloud compute routers add-bgp-peer on-prem-cr-us-central1 \ --peer-name bgp-aiml-vpc-tunnel0 \ --interface if-tunnel1-to-aiml-vpc \ --peer-ip-address 169.254.1.1 \ --peer-asn 65001 \ --region us-central1Crea la seconda interfaccia BGP:
gcloud compute routers add-interface on-prem-cr-us-central1 \ --interface-name if-tunnel1-to-aiml-vpc \ --ip-address 169.254.2.2 \ --mask-length 30 \ --vpn-tunnel on-prem-tunnel1 \ --region us-central1Crea il secondo peer BGP:
gcloud compute routers add-bgp-peer on-prem-cr-us-central1 \ --peer-name bgp-aiml-vpc-tunnel1 \ --interface if-tunnel2-to-aiml-vpc \ --peer-ip-address 169.254.2.1 \ --peer-asn 65001 \ --region us-central1
Convalida la creazione della sessione BGP
Nella console Google Cloud, vai alla pagina VPN.
Nella pagina VPN, fai clic sulla scheda Tunnel Cloud VPN.
Nell'elenco dei tunnel VPN, ora dovresti vedere che il valore nella colonna Stato sessione BGP per ciascuno dei quattro tunnel è passato da Configura sessione BGP a BGP stabilito. Per visualizzare i nuovi valori, potrebbe essere necessario aggiornare la Google Cloud scheda del browser della console.
Verifica che aiml-vpc abbia appreso le route delle sottoreti tramite la VPN ad alta disponibilità
Nella console Google Cloud, vai alla pagina Reti VPC.
Nell'elenco delle reti VPC, fai clic su
aiml-vpc.Fai clic sulla scheda Percorsi.
Seleziona us-central1 (Iowa) nell'elenco Regione e fai clic su Visualizza.
Nella colonna Intervallo IP di destinazione, verifica che la rete VPC
aiml-vpcabbia appreso le route dalle subnetnat-subnet(192.168.10.0/28) eprivate-ip-subnet(192.168.20.0/28) delle reti VPCon-prem-vpc.
Verifica che on-prem-vpc abbia appreso le route delle sottoreti tramite la VPN ad alta disponibilità
Nella console Google Cloud, vai alla pagina Reti VPC.
Nell'elenco delle reti VPC, fai clic su
on-prem-vpc.Fai clic sulla scheda Percorsi.
Seleziona us-central1 (Iowa) nell'elenco Regione e fai clic su Visualizza.
Nella colonna Intervallo IP di destinazione, verifica che la rete VPC
on-prem-vpcabbia appreso i route dalla subnetworkbench-subnet(172.16.10.0/28) delle reti VPCaiml-vpc.
Creare una route pubblicizzata personalizzata per aiml-vpc
L'indirizzo IP dell'endpoint Private Service Connect non viene pubblicizzato automaticamente dal router cloud aiml-cr-us-central1 perché la subnet non è configurata nella rete VPC.
Di conseguenza, dovrai creare una route annunciata personalizzata dal router Cloud aiml-cr-us-central per l'indirizzo IP dell'endpoint 100.100.10.10 annunciata all'ambiente on-premise tramite BGP a on-prem-vpc.
Nella console Google Cloud, vai alla pagina Cloud Routers.
Nell'elenco dei router Cloud, fai clic su
aiml-cr-us-central1.Nella pagina Dettagli del router, fai clic su Modifica.
Nella sezione Route annunciate, seleziona Route per Crea route personalizzate.
Fai clic su Aggiungi un percorso personalizzato.
In Origine, seleziona Intervallo IP personalizzato.
In Intervallo di indirizzi IP, inserisci
100.100.10.10.In Descrizione, inserisci
Private Service Connect Endpoint IP.Fai clic su Fine e poi su Salva.
Verifica che on-prem-vpc abbia appreso l'indirizzo IP dell'endpoint PSC tramite la VPN ad alta disponibilità
Nella console Google Cloud, vai alla pagina Reti VPC.
Nell'elenco delle reti VPC, fai clic su
on-prem-vpc.Fai clic sulla scheda Percorsi.
Seleziona us-central1 (Iowa) nell'elenco Regione e fai clic su Visualizza.
Nella colonna Intervallo IP di destinazione, verifica che la rete VPC
on-prem-vpcabbia appreso l'indirizzo IP dell'endpoint PSC (100.100.10.10).
Creare una route pubblicizzata personalizzata per on-prem-vpc
Per impostazione predefinita, il router Cloud on-prem-vpc pubblicizza tutte le subnet, ma è necessaria solo la subnet private-ip-subnet.
Nella sezione seguente, aggiorna gli annunci di route dal
on-prem-cr-us-central1 router Cloud.
Nella console Google Cloud, vai alla pagina Cloud Routers.
Nell'elenco dei router Cloud, fai clic su
on-prem-cr-us-central1.Nella pagina Dettagli del router, fai clic su Modifica.
Nella sezione Route annunciate, seleziona Route per Crea route personalizzate.
Se la casella di controllo Annuncia tutte le subnet visibili al router Cloud è selezionata, deselezionala.
Fai clic su Aggiungi un percorso personalizzato.
In Origine, seleziona Intervallo IP personalizzato.
In Intervallo di indirizzi IP, inserisci
192.168.20.0/28.In Descrizione, inserisci
Private Service Connect Endpoint IP subnet (private-ip-subnet).Fai clic su Fine e poi su Salva.
Verifica che aiml-vpc abbia appreso il percorso private-ip-subnet dal on-prem-vpc
Nella console Google Cloud, vai alla pagina Reti VPC.
Nell'elenco delle reti VPC, fai clic su
aiml-vpc.Fai clic sulla scheda Percorsi.
Seleziona us-central1 (Iowa) nell'elenco Regione e fai clic su Visualizza.
Nella colonna Intervallo IP di destinazione, verifica che la rete VPC
aiml-vpcabbia appreso la routeprivate-ip-subnet(192.168.20.0/28).
Crea le istanze VM di test
Creare un account di servizio gestito dall'utente
Se hai applicazioni che devono chiamare Google Cloud API, Google consiglia di collegare un account di servizio gestito dall'utente alla VM su cui è in esecuzione l'applicazione o il carico di lavoro. Di conseguenza, in questa sezione crei un account di servizio gestito dall'utente da applicare alle istanze VM che crei in seguito in questo tutorial.
In Cloud Shell, crea l'account di servizio:
gcloud iam service-accounts create gce-vertex-sa \ --description="service account for vertex" \ --display-name="gce-vertex-sa"Assegna il ruolo IAM Amministratore istanze Compute (v1) (
roles/compute.instanceAdmin.v1) all'account di servizio:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:gce-vertex-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/compute.instanceAdmin.v1"Assegna il ruolo IAM Utente Vertex AI (
roles/aiplatform.user) all'account di servizio:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:gce-vertex-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.user"
Crea le istanze VM di test
In questo passaggio crei istanze VM di test per convalidare diversi metodi per raggiungere le API Vertex AI, in particolare:
- L'istanza
nat-clientutilizza Cloud NAT per risolvere Vertex AI per accedere all'endpoint di previsione online tramite la rete internet pubblica. - L'istanza
private-clientutilizza l'indirizzo IP100.100.10.10di Private Service Connect per accedere all'endpoint di previsione online tramite VPN ad alta disponibilità.
Per consentire a Identity-Aware Proxy (IAP) di connettersi alle tue istanze VM, crea una regola firewall che:
- Si applica a tutte le istanze VM che vuoi rendere accessibili tramite IAP.
- Consente il traffico TCP attraverso la porta 22 dall'intervallo IP
35.235.240.0/20. Questo intervallo contiene tutti gli indirizzi IP utilizzati da IAP per l'inoltro TCP.
Crea l'istanza VM
nat-client:gcloud compute instances create nat-client \ --zone=us-central1-a \ --image-family=debian-11 \ --image-project=debian-cloud \ --subnet=nat-subnet \ --service-account=gce-vertex-sa@$projectid.iam.gserviceaccount.com \ --scopes=https://www.googleapis.com/auth/cloud-platform \ --no-address \ --metadata startup-script="#! /bin/bash sudo apt-get update sudo apt-get install tcpdump dnsutils -y"Crea l'istanza VM
private-client:gcloud compute instances create private-client \ --zone=us-central1-a \ --image-family=debian-11 \ --image-project=debian-cloud \ --subnet=private-ip-subnet \ --service-account=gce-vertex-sa@$projectid.iam.gserviceaccount.com \ --scopes=https://www.googleapis.com/auth/cloud-platform \ --no-address \ --metadata startup-script="#! /bin/bash sudo apt-get update sudo apt-get install tcpdump dnsutils -y"Crea la regola firewall IAP:
gcloud compute firewall-rules create ssh-iap-on-prem-vpc \ --network on-prem-vpc \ --allow tcp:22 \ --source-ranges=35.235.240.0/20
Crea un'istanza di Vertex AI Workbench
Crea un account di servizio gestito dall'utente per Vertex AI Workbench
Quando crei un'istanza di Vertex AI Workbench,
Google consiglia vivamente di specificare un account di servizio gestito dall'utente anziché
utilizzare l'account di servizio predefinito di Compute Engine.
Se la tua organizzazione non applica il vincolo dei criteri dell'organizzazione iam.automaticIamGrantsForDefaultServiceAccounts, all'account di servizio Compute Engine predefinito (e quindi a qualsiasi utente specificato come utente dell'istanza) viene concesso il ruolo Editor (roles/editor) nel progettoGoogle Cloud . Per disattivare questo comportamento, consulta
Disattivare la concessione automatica dei ruoli per gli account di servizio predefiniti.
In Cloud Shell, crea un account di servizio denominato
workbench-sa:gcloud iam service-accounts create workbench-sa \ --display-name="workbench-sa"Assegna il ruolo IAM Amministratore dello spazio di archiviazione (
roles/storage.admin) all'account di servizio:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/storage.admin"Assegna il ruolo IAM Utente Vertex AI (
roles/aiplatform.user) all'account di servizio:gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/aiplatform.user"Assegna il ruolo IAM Amministratore del registry di elementi all'account di servizio:
gcloud projects add-iam-policy-binding $projectid \ --member="serviceAccount:workbench-sa@$projectid.iam.gserviceaccount.com" \ --role="roles/artifactregistry.admin"
Crea l'istanza di Vertex AI Workbench
In Cloud Shell, crea un'istanza di Vertex AI Workbench, specificando il service account
workbench-sa:gcloud workbench instances create workbench-tutorial \ --vm-image-project=deeplearning-platform-release \ --vm-image-family=common-cpu-notebooks \ --machine-type=n1-standard-4 \ --location=us-central1-a \ --subnet-region=us-central1 \ --shielded-secure-boot=True \ --subnet=workbench-subnet \ --disable-public-ip \ --service-account-email=workbench-sa@$projectid.iam.gserviceaccount.com
Crea ed esegui il deployment di un modello di previsione online
prepara l'ambiente
Nella console Google Cloud, vai alla scheda Istanze nella pagina Vertex AI Workbench.
Accanto al nome dell'istanza Vertex AI Workbench (
workbench-tutorial), fai clic su Apri JupyterLab.L'istanza di Vertex AI Workbench apre JupyterLab.
Nel resto di questa sezione, fino al deployment del modello incluso, lavorerai in Jupyterlab, non nella console Google Cloud o in Cloud Shell.
Seleziona File > Nuovo > Terminale.
Nel terminale JupyterLab (non in Cloud Shell), definisci una variabile di ambiente per il project. Sostituisci PROJECT_ID con l'ID progetto:
PROJECT_ID=PROJECT_IDCrea una nuova directory denominata
cpr-codelabecdal suo interno (ancora nel terminale JupyterLab):mkdir cpr-codelab cd cpr-codelabNel File Browser, fai doppio clic sulla nuova cartella
cpr-codelab.Se questa cartella non viene visualizzata nel browser dei file, aggiorna la Google Cloud scheda del browser della console e riprova.
Seleziona File > Nuovo > Notebook.
Nel menu Seleziona kernel, seleziona Python [conda env:base] * (locale) e fai clic su Seleziona.
Rinomina il nuovo file del notebook come segue:
Nel File Browser, fai clic con il tasto destro del mouse sull'icona del file
Untitled.ipynbe inseriscitask.ipynb.La directory
cpr-codelabdovrebbe avere il seguente aspetto:+ cpr-codelab/ + task.ipynbNei passaggi seguenti, crei il modello nel notebook Jupyterlab creando nuove celle del notebook, incollando il codice al loro interno ed eseguendole.
Installa le dipendenze come segue.
Quando apri il nuovo notebook, è presente una cella di codice predefinita in cui inserire il codice. Sembra
[ ]:seguito da un campo di testo. In questo campo di testo devi incollare il codice.Incolla il seguente codice nella cella e fai clic su Esegui le celle selezionate e vai avanti per creare un file
requirements.txtda utilizzare come input per il passaggio successivo:%%writefile requirements.txt fastapi uvicorn==0.17.6 joblib~=1.1.1 numpy>=1.17.3, <1.24.0 scikit-learn>=1.2.2 pandas google-cloud-storage>=2.2.1,<3.0.0dev google-cloud-aiplatform[prediction]>=1.18.2In questo passaggio e in ciascuno dei seguenti, aggiungi una cella di codice facendo clic su Inserisci una cella sotto, incolla il codice nella cella e poi fai clic su Esegui le celle selezionate ed esegui l'avanzamento.
Utilizza
Pipper installare le dipendenze nell'istanza di Notebooks:!pip install -U --user -r requirements.txtAl termine dell'installazione, seleziona Kernel > Riavvia kernel per riavviare il kernel e assicurarti che la libreria sia disponibile per l'importazione.
Incolla il seguente codice in una nuova cella del notebook per creare le directory per archiviare il modello e gli elementi di preelaborazione:
USER_SRC_DIR = "src_dir" !mkdir $USER_SRC_DIR !mkdir model_artifacts # copy the requirements to the source dir !cp requirements.txt $USER_SRC_DIR/requirements.txt
Nel File Browser, la struttura di directory
cpr-codelabdovrebbe avere il seguente aspetto:+ cpr-codelab/ + model_artifacts/ + src_dir/ + requirements.txt + requirements.txt + task.ipynb
Addestra il modello
Continua ad aggiungere celle di codice al notebook task.ipynb, incolla e
esegui il seguente codice in ogni nuova cella:
Importa le librerie:
import seaborn as sns import numpy as np import pandas as pd from sklearn import preprocessing from sklearn.ensemble import RandomForestRegressor from sklearn.pipeline import make_pipeline from sklearn.compose import make_column_transformer import joblib import logging # set logging to see the docker container logs logging.basicConfig(level=logging.INFO)Definisci le seguenti variabili, sostituendo PROJECT_ID con il tuo ID progetto:
REGION = "us-central1" MODEL_ARTIFACT_DIR = "sklearn-model-artifacts" REPOSITORY = "diamonds" IMAGE = "sklearn-image" MODEL_DISPLAY_NAME = "diamonds-cpr" PROJECT_ID = "PROJECT_ID" BUCKET_NAME = "gs://PROJECT_ID-cpr-bucket"Crea un bucket Cloud Storage:
!gcloud storage buckets create $BUCKET_NAME --location=us-central1Carica i dati dalla libreria seaborn e poi crea due frame di dati, uno con gli elementi e l'altro con l'etichetta:
data = sns.load_dataset('diamonds', cache=True, data_home=None) label = 'price' y_train = data['price'] x_train = data.drop(columns=['price'])Esamina i dati di addestramento e verifica che ogni riga rappresenti un diamante.
x_train.head()Guarda le etichette, che corrispondono ai prezzi.
y_train.head()Definisci una trasformazione della colonna sklearn per codificare one-hot le caratteristiche categoriche e eseguire la scalatura delle caratteristiche numeriche:
column_transform = make_column_transformer( (preprocessing.OneHotEncoder(), [1,2,3]), (preprocessing.StandardScaler(), [0,4,5,6,7,8]))Definisci il modello di foresta casuale:
regr = RandomForestRegressor(max_depth=10, random_state=0)Crea una pipeline sklearn. Questa pipeline prende i dati di input, li codifica e li scala e li passa al modello.
my_pipeline = make_pipeline(column_transform, regr)Addestra il modello:
my_pipeline.fit(x_train, y_train)Chiama il metodo di previsione sul modello, passando un esempio di test.
my_pipeline.predict([[0.23, 'Ideal', 'E', 'SI2', 61.5, 55.0, 3.95, 3.98, 2.43]])Potresti visualizzare avvisi come
"X does not have valid feature names, but", ma puoi ignorarli.Salva la pipeline nella directory
model_artifactse copiala nel tuo bucket Cloud Storage:joblib.dump(my_pipeline, 'model_artifacts/model.joblib') !gcloud storage cp model_artifacts/model.joblib {BUCKET_NAME}/{MODEL_ARTIFACT_DIR}/
Salvare un artefatto di preelaborazione
Crea un artefatto di preelaborazione. Questo artefatto verrà caricato nel contenitore personalizzato all'avvio del server del modello. L'elemento pre-elaborazione può essere di quasi qualsiasi forma (ad esempio un file pickle), ma in questo caso scriverai un dizionario in un file JSON:
clarity_dict={"Flawless": "FL", "Internally Flawless": "IF", "Very Very Slightly Included": "VVS1", "Very Slightly Included": "VS2", "Slightly Included": "S12", "Included": "I3"}
Crea un container di pubblicazione personalizzato utilizzando il server del modello CPR
La funzionalità
claritynei nostri dati di addestramento era sempre nella forma abbreviata (ad es. "FL" anziché "Perfetto"). Al momento della pubblicazione, vogliamo verificare che anche i dati relativi a questa funzionalità siano abbreviati. Questo perché il nostro modello sa come codificare in one-hot "FL", ma non "Flawless". Scriverai questa logica di preelaborazione personalizzata in un secondo momento. Per il momento, salva questa tabella di ricerca in un file JSON e poi scrivila nel tuo bucket Cloud Storage:import json with open("model_artifacts/preprocessor.json", "w") as f: json.dump(clarity_dict, f) !gcloud storage cp model_artifacts/preprocessor.json {BUCKET_NAME}/{MODEL_ARTIFACT_DIR}/Nel File Browser, la struttura di directory dovrebbe avere il seguente aspetto:
+ cpr-codelab/ + model_artifacts/ + model.joblib + preprocessor.json + src_dir/ + requirements.txt + requirements.txt + task.ipynbNel notebook, incolla ed esegui il seguente codice per creare una sottoclasse di
SklearnPredictore scriverla in un file Python insrc_dir/. Tieni presente che in questo esempio personalizziamo solo i metodi load, preprocess e postprocess, non il metodo predict.%%writefile $USER_SRC_DIR/predictor.py import joblib import numpy as np import json from google.cloud import storage from google.cloud.aiplatform.prediction.sklearn.predictor import SklearnPredictor class CprPredictor(SklearnPredictor): def __init__(self): return def load(self, artifacts_uri: str) -> None: """Loads the sklearn pipeline and preprocessing artifact.""" super().load(artifacts_uri) # open preprocessing artifact with open("preprocessor.json", "rb") as f: self._preprocessor = json.load(f) def preprocess(self, prediction_input: np.ndarray) -> np.ndarray: """Performs preprocessing by checking if clarity feature is in abbreviated form.""" inputs = super().preprocess(prediction_input) for sample in inputs: if sample[3] not in self._preprocessor.values(): sample[3] = self._preprocessor[sample[3]] return inputs def postprocess(self, prediction_results: np.ndarray) -> dict: """Performs postprocessing by rounding predictions and converting to str.""" return {"predictions": [f"${value}" for value in np.round(prediction_results)]}Utilizza l'SDK Vertex AI per Python per creare l'immagine utilizzando routine di previsione personalizzate. Viene generato il Dockerfile e viene creata un'immagine.
from google.cloud import aiplatform aiplatform.init(project=PROJECT_ID, location=REGION) import os from google.cloud.aiplatform.prediction import LocalModel from src_dir.predictor import CprPredictor # Should be path of variable $USER_SRC_DIR local_model = LocalModel.build_cpr_model( USER_SRC_DIR, f"{REGION}-docker.pkg.dev/{PROJECT_ID}/{REPOSITORY}/{IMAGE}", predictor=CprPredictor, requirements_path=os.path.join(USER_SRC_DIR, "requirements.txt"), )Scrivi un file di test con due esempi per la previsione. Una delle istanze ha il nome abbreviato della chiarezza, ma l'altra deve essere prima convertita.
import json sample = {"instances": [ [0.23, 'Ideal', 'E', 'VS2', 61.5, 55.0, 3.95, 3.98, 2.43], [0.29, 'Premium', 'J', 'Internally Flawless', 52.5, 49.0, 4.00, 2.13, 3.11]]} with open('instances.json', 'w') as fp: json.dump(sample, fp)Testa il contenitore localmente eseguendo il deployment di un modello locale.
with local_model.deploy_to_local_endpoint( artifact_uri = 'model_artifacts/', # local path to artifacts ) as local_endpoint: predict_response = local_endpoint.predict( request_file='instances.json', headers={"Content-Type": "application/json"}, ) health_check_response = local_endpoint.run_health_check()Puoi visualizzare i risultati della previsione con:
predict_response.contentL'output è il seguente:
b'{"predictions": ["$479.0", "$586.0"]}'
Esegui il deployment del modello nell'endpoint del modello di previsione online
Ora che hai testato il contenitore in locale, è il momento di eseguire il push dell'immagine in Artifact Registry e caricare il modello in Vertex AI Model Registry.
Configura Docker per accedere ad Artifact Registry.
!gcloud artifacts repositories create {REPOSITORY} \ --repository-format=docker \ --location=us-central1 \ --description="Docker repository" !gcloud auth configure-docker {REGION}-docker.pkg.dev --quietEsegui il push dell'immagine.
local_model.push_image()Carica il modello.
model = aiplatform.Model.upload(local_model = local_model, display_name=MODEL_DISPLAY_NAME, artifact_uri=f"{BUCKET_NAME}/{MODEL_ARTIFACT_DIR}",)Esegui il deployment del modello:
endpoint = model.deploy(machine_type="n1-standard-2")Attendi il deployment del modello prima di procedere al passaggio successivo. Il deployment dovrebbe richiedere circa 10-15 minuti.
Testa il modello di cui è stato eseguito il deployment ottenendo una previsione:
endpoint.predict(instances=[[0.23, 'Ideal', 'E', 'VS2', 61.5, 55.0, 3.95, 3.98, 2.43]])L'output è il seguente:
Prediction(predictions=['$479.0'], deployed_model_id='3171115779319922688', metadata=None, model_version_id='1', model_resource_name='projects/721032480027/locations/us-central1/models/8554949231515795456', explanations=None)
Convalida l'accesso pubblico a internet alle API Vertex AI
In questa sezione, accedi all'istanza VM nat-client in una scheda della sessione Cloud Shell e utilizza un'altra scheda della sessione per convalidare la connettività alle API Vertex AI eseguendo i comandi dig e tcpdump sul dominio us-central1-aiplatform.googleapis.com.
In Cloud Shell (scheda 1), esegui i comandi seguenti, sostituendo PROJECT_ID con il tuo ID progetto:
projectid=PROJECT_ID gcloud config set project ${projectid}Accedi all'istanza VM
nat-clientutilizzando IAP:gcloud compute ssh nat-client \ --project=$projectid \ --zone=us-central1-a \ --tunnel-through-iapEsegui il comando
dig:dig us-central1-aiplatform.googleapis.comDalla VM
nat-client(scheda 1), esegui il seguente comando per verificare la risoluzione DNS quando invii una richiesta di previsione online all'endpoint.sudo tcpdump -i any port 53 -nApri una nuova sessione Cloud Shell (scheda 2) facendo clic su Apri una nuova scheda in Cloud Shell.
Nella nuova sessione Cloud Shell (scheda 2), esegui i seguenti comandi, sostituendo PROJECT_ID con l'ID progetto:
projectid=PROJECT_ID gcloud config set project ${projectid}Accedi all'istanza VM
nat-client:gcloud compute ssh --zone "us-central1-a" "nat-client" --project "$projectid"Dalla VM
nat-client(scheda 2), utilizza un editor di testo comevimonanoper creare un fileinstances.json. Devi anteporresudoper avere l'autorizzazione a scrivere nel file, ad esempio:sudo vim instances.jsonAggiungi la seguente stringa di dati al file:
{"instances": [ [0.23, 'Ideal', 'E', 'VS2', 61.5, 55.0, 3.95, 3.98, 2.43], [0.29, 'Premium', 'J', 'Internally Flawless', 52.5, 49.0, 4.00, 2.13, 3.11]]}Salva il file come segue:
- Se utilizzi
vim, premi il tastoEsc, quindi digita:wqper salvare il file ed uscire. - Se utilizzi
nano, digitaControl+Oe premiEnterper salvare il file, quindi digitaControl+Xper uscire.
- Se utilizzi
Individua l'ID endpoint di previsione online per l'endpoint PSC:
Nella console Google Cloud, nella sezione Vertex AI, vai alla scheda Endpoint nella pagina Previsione online.
Trova la riga dell'endpoint che hai creato, nominato
diamonds-cpr_endpoint.Individua l'ID endpoint di 19 cifre nella colonna ID e copialo.
In Cloud Shell, dalla VM
nat-client(scheda 2), esegui i seguenti comandi, sostituendo PROJECT_ID con il tuo ID progetto e ENDPOINT_ID con l'ID endpoint PSC:projectid=PROJECT_ID gcloud config set project ${projectid} ENDPOINT_ID=ENDPOINT_IDDalla VM
nat-client(scheda 2), esegui il seguente comando per inviare una richiesta di previsione online:curl -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" -H "Content-Type: application/json" https://us-central1-aiplatform.googleapis.com/v1/projects/${projectid}/locations/us-central1/endpoints/${ENDPOINT_ID}:predict -d @instances.json
Ora che hai eseguito la previsione, vedrai che i risultati tcpdump
(scheda 1) mostrano l'istanza VM nat-client (192.168.10.2) che esegue una
query Cloud DNS al server DNS locale (169.254.169.254) per il
dominio dell'API Vertex AI (us-central1-aiplatform.googleapis.com).
La query DNS restituisce indirizzi IP virtuali pubblici (VIP) per
le API Vertex AI.
Convalida l'accesso privato alle API Vertex AI
In questa sezione, accedi all'istanza VM private-client utilizzando Identity-Aware Proxy in una nuova sessione Cloud Shell (scheda 3), quindi convalida la connettività alle API Vertex AI eseguendo il comando dig sul dominio Vertex AI (us-central1-aiplatform.googleapis.com).
Apri una nuova sessione Cloud Shell (scheda 3) facendo clic su Apri una nuova scheda in Cloud Shell. Questa è la scheda Tre.
Nella nuova sessione Cloud Shell (scheda 3), esegui i seguenti comandi, sostituendo PROJECT_ID con l'ID progetto:
projectid=PROJECT_ID gcloud config set project ${projectid}Accedi all'istanza VM
private-clientutilizzando IAP:gcloud compute ssh private-client \ --project=$projectid \ --zone=us-central1-a \ --tunnel-through-iapEsegui il comando
dig:dig us-central1-aiplatform.googleapis.comNell'istanza VM
private-client(scheda 3), utilizza un editor di testo comevimonanoper aggiungere la seguente riga al file/etc/hosts:100.100.10.10 us-central1-aiplatform.googleapis.comQuesta riga assegna l'indirizzo IP dell'endpoint PSC (
100.100.10.10) al nome di dominio completo per l'API Google Vertex AI (us-central1-aiplatform.googleapis.com). Il file modificato dovrebbe avere il seguente aspetto:127.0.0.1 localhost ::1 localhost ip6-localhost ip6-loopback ff02::1 ip6-allnodes ff02::2 ip6-allrouters 100.100.10.10 us-central1-aiplatform.googleapis.com # Added by you 192.168.20.2 private-client.c.$projectid.internal private-client # Added by Google 169.254.169.254 metadata.google.internal # Added by GoogleDalla VM
private-client(scheda 3), esegui un ping all'endpoint Vertex AI e premiControl+Cper uscire quando viene visualizzato l'output:ping us-central1-aiplatform.googleapis.comIl comando
pingrestituisce il seguente output contenente l'indirizzo IP dell'endpoint PSC:PING us-central1-aiplatform.googleapis.com (100.100.10.10) 56(84) bytes of data.Dalla VM
private-client(scheda 3), utilizzatcpdumpper eseguire il seguente comando per convalidare la risoluzione DNS e il percorso dei dati IP quando invii una richiesta di previsione online all'endpoint:sudo tcpdump -i any port 53 -n or host 100.100.10.10Apri una nuova sessione Cloud Shell (scheda 4) facendo clic su Apri una nuova scheda in Cloud Shell.
Nella nuova sessione Cloud Shell (scheda 4), esegui i seguenti comandi, sostituendo PROJECT_ID con l'ID progetto:
projectid=PROJECT_ID gcloud config set project ${projectid}Nella scheda Quattro, accedi all'istanza
private-client:gcloud compute ssh \ --zone "us-central1-a" "private-client" \ --project "$projectid"Dalla VM
private-client(scheda 4), utilizzando un editor di testo comevimonano, crea un fileinstances.jsoncontenente la seguente stringa di dati:{"instances": [ [0.23, 'Ideal', 'E', 'VS2', 61.5, 55.0, 3.95, 3.98, 2.43], [0.29, 'Premium', 'J', 'Internally Flawless', 52.5, 49.0, 4.00, 2.13, 3.11]]}Dalla VM
private-client(scheda 4), esegui i seguenti comandi, sostituendo PROJECT_ID con il nome del progetto e ENDPOINT_ID con l'ID endpoint PSC:projectid=PROJECT_ID echo $projectid ENDPOINT_ID=ENDPOINT_IDDalla VM
private-client(scheda 4), esegui il seguente comando per inviare una richiesta di previsione online:curl -v -X POST -H "Authorization: Bearer $(gcloud auth print-access-token)" -H "Content-Type: application/json" https://us-central1-aiplatform.googleapis.com/v1/projects/${projectid}/locations/us-central1/endpoints/${ENDPOINT_ID}:predict -d @instances.jsonDalla VM
private-clientin Cloud Shell (scheda 3), verifica che l'indirizzo IP dell'endpoint PSC (100.100.10.10) sia stato utilizzato per accedere alle API Vertex AI.Dal terminale
private-clienttcpdumpnella scheda 3 di Cloud Shell, puoi vedere che non è necessaria una ricerca DNS perus-central1-aiplatform.googleapis.comperché la riga che hai aggiunto al file/etc/hostsha la precedenza e l'indirizzo IP del PSC100.100.10.10viene utilizzato nel percorso dei dati.
Esegui la pulizia
Per evitare che al tuo Google Cloud account vengano addebitati costi relativi alle risorse utilizzate in questo tutorial, elimina il progetto che contiene le risorse oppure mantieni il progetto ed elimina le singole risorse.
Puoi eliminare le singole risorse del progetto nel seguente modo:
Elimina l'istanza di Vertex AI Workbench come segue:
Nella sezione Vertex AI della console Google Cloud, vai alla scheda Istanze nella pagina Workbench.
Seleziona l'
workbench-tutorialistanza Vertex AI Workbench e fai clic su Elimina.
Elimina l'immagine del contenitore come segue:
Nella console Google Cloud, vai alla pagina Artifact Registry.
Seleziona il contenitore Docker
diamondse fai clic su Elimina.
Elimina il bucket di archiviazione come segue:
Nella console Google Cloud, vai alla pagina Cloud Storage.
Seleziona il bucket di archiviazione e fai clic su Elimina.
Annullare il deployment del modello dall'endpoint come segue:
Nella console Google Cloud, nella sezione Vertex AI, vai alla pagina Endpoint.
Fai clic su
diamonds-cpr_endpointper andare alla pagina dei dettagli dell'endpoint.Nella riga del modello,
diamonds-cpr, fai clic su Annulla il deployment del modello .Nella finestra di dialogo Annulla il deployment del modello nell'endpoint, fai clic su Annulla deployment.
Elimina il modello come segue:
Nella console Google Cloud, nella sezione Vertex AI, vai alla pagina Model Registry.
Seleziona il modello
diamonds-cpr.Per eliminare il modello, fai clic su Azioni e poi su Elimina modello.
Elimina l'endpoint di previsione online come segue:
Nella console Google Cloud, nella sezione Vertex AI, vai alla pagina Previsione online.
Seleziona l'endpoint
diamonds-cpr_endpoint.Per eliminare l'endpoint, fai clic su Azioni e poi su Elimina endpoint.
In Cloud Shell, elimina le risorse rimanenti eseguendo i seguenti comandi.
projectid=PROJECT_ID gcloud config set project ${projectid}gcloud compute forwarding-rules delete pscvertex \ --global \ --quietgcloud compute addresses delete psc-ip \ --global \ --quietgcloud compute networks subnets delete workbench-subnet \ --region=us-central1 \ --quietgcloud compute vpn-tunnels delete aiml-vpc-tunnel0 aiml-vpc-tunnel1 on-prem-tunnel0 on-prem-tunnel1 \ --region=us-central1 \ --quietgcloud compute vpn-gateways delete aiml-vpn-gw on-prem-vpn-gw \ --region=us-central1 \ --quietgcloud compute routers nats delete cloud-nat-us-central1 \ --router=cloud-router-us-central1-aiml-nat \ --region=us-central1 \ --quietgcloud compute routers delete aiml-cr-us-central1 cloud-router-us-central1-aiml-nat \ --region=us-central1 \ --quietgcloud compute routers delete cloud-router-us-central1-on-prem-nat on-prem-cr-us-central1 \ --region=us-central1 \ --quietgcloud compute instances delete nat-client private-client \ --zone=us-central1-a \ --quietgcloud compute firewall-rules delete ssh-iap-on-prem-vpc \ --quietgcloud compute networks subnets delete nat-subnet private-ip-subnet \ --region=us-central1 \ --quietgcloud compute networks delete on-prem-vpc \ --quietgcloud compute networks delete aiml-vpc \ --quietgcloud iam service-accounts delete gce-vertex-sa@$projectid.iam.gserviceaccount.com \ --quietgcloud iam service-accounts delete workbench-sa@$projectid.iam.gserviceaccount.com \ --quiet
Passaggi successivi
- Scopri le opzioni di networking aziendale per accedere a servizi ed endpoint di Vertex AI
- Scopri come funziona Private Service Connect e perché offre vantaggi significativi in termini di prestazioni.
- Scopri come utilizzare i Controlli di servizio VPC per creare perimetri sicuri per consentire o negare l'accesso a Vertex AI e ad altre API Google sul tuo endpoint di previsione online.
- Scopri come e perché
utilizzare una zona di inoltro DNS instead of updating the
/etc/hostsfile in large scale and production environments.