TPU v6e
このドキュメントでは、Cloud TPU v6e(Trillium)のアーキテクチャとサポートされている構成について説明します。
Trillium は、Cloud TPU の最新の生成 AI アクセラレータです。API やログなどのすべての技術的な側面から、Trillium はこのドキュメント全体で v6e と呼んでいます。
Pod あたり 256 チップのフットプリントを備えた v6e は、v5e と多くの類似点があります。このシステムは、トランスフォーマー、テキスト画像変換、畳み込みニューラル ネットワーク(CNN)のトレーニング、ファインチューニング、サービングに適した最適なプロダクトとなるように最適化されています。
システム アーキテクチャ
各 v6e チップには 1 つの TensorCore が含まれています。各 TensorCore には、2 つのマトリックス乗算ユニット(MXU)、ベクトル ユニット、スカラー ユニットがあります。次の表に、TPU v5e と TPU v6e の主な仕様と値を示します。
| 仕様 | v5e | v6e |
|---|---|---|
| パフォーマンス / 総所有コスト(TCO)(予想) | 0.65x | 1 |
| チップあたりのピーク コンピューティング(bf16) | 197 TFLOPS | 918 TFLOPS |
| チップあたりのピーク コンピューティング(Int8) | 393 TOPS | 1,836 TOPS |
| チップあたりの HBM 容量 | 16 GB | 32 GB |
| チップあたりの HBM 帯域幅 | 800 GBps | 1,600 Gbps |
| チップ間相互接続(ICI)帯域幅 | 1,600 Gbps | 3200 Gbps |
| チップあたりの ICI ポート | 4 | 4 |
| ホストあたりの DRAM | 512 GiB | 1,536 GiB |
| ホストあたりのチップ数 | 8 | 8 |
| TPU Pod のサイズ | 256 チップ | 256 チップ |
| 相互接続トポロジ | 2D トーラス | 2D トーラス |
| Pod あたりの BF16 ピーク コンピューティング | 50.63 PFLOPs | 234.9 PFLOPs |
| Pod あたりの all-reduce 帯域幅 | 51.2 TB/秒 | 102.4 TB/秒 |
| Pod あたりの二分割帯域幅 | 1.6 TB/秒 | 3.2 TB/秒 |
| ホストごとの NIC 構成 | 2 x 100 Gbps NIC | 4 x 200 Gbps NIC |
| Pod あたりのデータセンターのネットワーク帯域幅 | 6.4 Tbps | 25.6 Tbps |
| 特別な機能 | - | SparseCore |
サポートされている構成
次の表に、v6e でサポートされている 2D スライス シェイプを示します。
| トポロジ | TPU チップ | ホスト | VM | アクセラレータ タイプ(TPU API) | マシンタイプ(GKE API) | 範囲 |
|---|---|---|---|---|---|---|
| 1×1 | 1 | 1/8 | 1 | v6e-1 |
ct6e-standard-1t |
サブホスト |
| 2x2 | 4 | 1/2 | 1 | v6e-4 |
ct6e-standard-4t |
サブホスト |
| 2x4 | 8 | 1 | 1 | v6e-8 |
ct6e-standard-8t |
単一ホスト |
| 2x4 | 8 | 1 | 2 | - | ct6e-standard-4t |
単一ホスト |
| 4x4 | 16 | 2 | 4 | v6e-16 |
ct6e-standard-4t |
マルチホスト |
| 4x8 | 32 | 4 | 8 | v6e-32 |
ct6e-standard-4t |
マルチホスト |
| 8x8 | 64 | 8 | 16 | v6e-64 |
ct6e-standard-4t |
マルチホスト |
| 8x16 | 128 | 16 | 32 | v6e-128 |
ct6e-standard-4t |
マルチホスト |
| 16x16 | 256 | 32 | 64 | v6e-256 |
ct6e-standard-4t |
マルチホスト |
1 つの VM に 8 個のチップ(v6e-8)が接続されたスライスは推論用に最適化されており、8 個のチップをすべて 1 つのサービング ワークロードで使用できます。Cloud 上の Pathways を使用してマルチホスト推論を実行できます。詳細については、Pathways を使用してマルチホスト推論を実行するをご覧ください。
各トポロジの VM 数については、VM の種類をご覧ください。
VM の種類
各 TPU v6e VM には、1、4、8 個のチップを含めることができます。4 チップ以下のスライスには、同じ不均一メモリアクセス(NUMA)ノードがあります。NUMA の詳細については、Wikipedia の 不均一メモリアクセスをご覧ください。
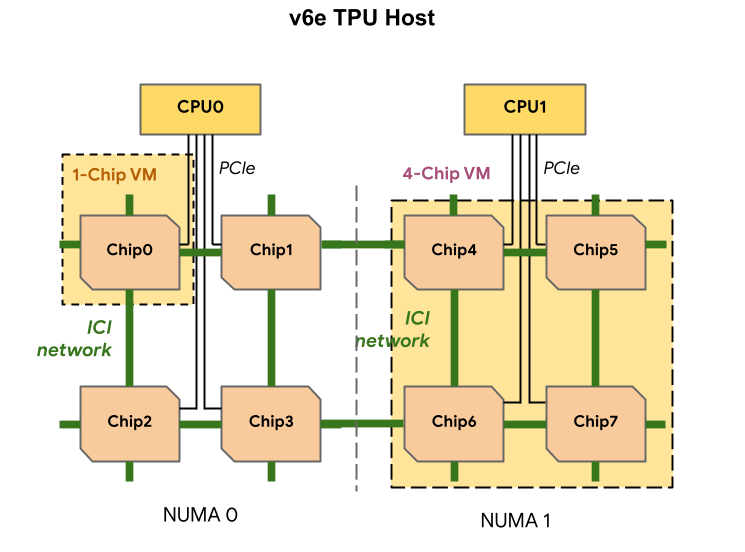
v6e スライスは、それぞれ 4 つの TPU チップを持つハーフホスト VM を使用して作成されます。この推奨事項には 2 つの例外があります。
v6e-1: チップが 1 つしかない VM。主にテスト用v6e-8: 8 個すべてのチップを 1 つの VM に接続した、推論ユースケース用に最適化されたフルホスト VM。
次の表に、TPU v6e VM タイプの比較を示します。
| VM の種類 | VM あたりの vCPU 数 | VM あたりの RAM(GB) | VM あたりの NUMA ノードの数 |
|---|---|---|---|
| 1 チップ VM | 44 | 176 | 1 |
| 4 チップ VM | 180 | 720 | 1 |
| 8 チップ VM | 180 | 1440 | 2 |
v6e 構成を指定する
TPU API を使用して TPU v6e スライスを割り当てる場合は、AcceleratorType パラメータを使用してサイズとシェイプを指定します。
GKE を使用している場合は、--machine-type フラグを使用して、使用する TPU をサポートするマシンタイプを指定します。詳細については、GKE ドキュメントの GKE で TPU を計画するをご覧ください。
AcceleratorType を使用する
TPU リソースを割り当てる場合は、AcceleratorType を使用してスライス内の TensorCore 数を指定します。AcceleratorType に指定する値は、v$VERSION-$TENSORCORE_COUNT 形式の文字列です。たとえば、v6e-8 は、8 個の TensorCore を含む v6e TPU スライスを指定します。
次の例は、AcceleratorType を使用して 32 個の TensorCore を持つ TPU v6e スライスを作成する方法を示しています。
gcloud
$ gcloud compute tpus tpu-vm create tpu-name \ --zone=zone \ --accelerator-type=v6e-32 \ --version=v2-alpha-tpuv6e
コンソール
Google Cloud コンソールで、[TPU] ページに移動します。
[TPU を作成] をクリックします。
[名前] フィールドに、TPU の名前を入力します。
[ゾーン] ボックスで、TPU を作成するゾーンを選択します。
[TPU タイプ] ボックスで、[
v6e-32] を選択します。[TPU ソフトウェア バージョン] ボックスで、
v2-alpha-tpuv6eを選択します。Cloud TPU VM の作成時には、この TPU ソフトウェア バージョンによって、インストールされる TPU ランタイム バージョンが指定されます。詳細については、TPU VM イメージをご覧ください。[キューイングを有効にする] トグルをクリックします。
[キューに格納されたリソースの名前] フィールドに、キューに格納されたリソース リクエストの名前を入力します。
[作成] をクリックします。