TPU v6e
In diesem Dokument werden die Architektur und die unterstützten Konfigurationen von Cloud TPU v6e (Trillium) beschrieben.
Trillium ist der KI-Beschleuniger der neuesten Generation für Cloud TPU. Auf allen technischen Oberflächen, z. B. in der API und in Logs, sowie in diesem Dokument wird Trillium als v6e bezeichnet.
Mit 256 Chips pro Pod ähnelt die v6e-Architektur der v5e-Architektur. Dieses optimierte System ist ein hochwertiges Produkt für das Training, die Feinabstimmung und die Bereitstellung von Transformer-, Text-zu-Bild- und CNN-Modellen (Convolutional Neural Network).
Systemarchitektur
Jeder v6e-Chip enthält einen TensorCore. Jeder TensorCore hat 2 MXUs (Matrix Multiply Units), eine Vektoreinheit und eine Skalareinheit. In der folgenden Tabelle sind die wichtigsten Spezifikationen und ihre Werte für TPU v6e im Vergleich zu TPU v5e aufgeführt.
| Spezifikation | v5e | v6e |
|---|---|---|
| Leistung/Gesamtbetriebskosten (erwartet) | 0,65x | 1 |
| Maximale Rechenleistung pro Chip (bf16) | 197 TFLOPs | 918 TFLOPs |
| Maximale Rechenleistung pro Chip (Int8) | 393 TOPS | 1.836 TOPS |
| HBM-Kapazität pro Chip | 16 GB | 32 GB |
| HBM-Bandbreite pro Chip | 800 Gbit/s | 1.600 Gbit/s |
| ICI-Bandbreite (Inter-Chip Interconnect) | 1.600 Gbit/s | 3.200 Gbit/s |
| ICI-Ports pro Chip | 4 | 4 |
| DRAM pro Host | 512 GiB | 1.536 GiB |
| Chips pro Host | 8 | 8 |
| TPU-Pod-Größe | 256 Chips | 256 Chips |
| Interconnect-Topologie | 2D-Torus | 2D-Torus |
| Maximale BF16-Rechenleistung pro Pod | 50,63 PFLOPs | 234,9 PFLOPs |
| All-Reduce-Bandbreite pro Pod | 51,2 TB/s | 102,4 TB/s |
| Bisektionsbandbreite pro Pod | 1,6 TB/s | 3,2 TB/s |
| NIC-Konfiguration pro Host | NIC mit 2 × 100 Gbit/s | NIC mit 4 × 200 Gbit/s |
| Netzwerkbandbreite des Rechenzentrums pro Pod | 6,4 Tbit/s | 25,6 Tbit/s |
| Besondere Features | - | SparseCore |
Unterstützte Konfigurationen
In der folgenden Tabelle sind die 2D-Slice-Formen aufgeführt, die für v6e unterstützt werden:
| Topologie | TPU-Chips | Hosts | VMs | Beschleunigertyp (TPU API) | Maschinentyp (GKE API) | Umfang |
|---|---|---|---|---|---|---|
| 1x1 | 1 | 1/8 | 1 | v6e-1 |
ct6e-standard-1t |
Untergeordneter Host |
| 2x2 | 4 | 1/2 | 1 | v6e-4 |
ct6e-standard-4t |
Untergeordneter Host |
| 2x4 | 8 | 1 | 1 | v6e-8 |
ct6e-standard-8t |
Einzelner Host |
| 2x4 | 8 | 1 | 2 | - | ct6e-standard-4t |
Einzelner Host |
| 4x4 | 16 | 2 | 4 | v6e-16 |
ct6e-standard-4t |
Mehrere Hosts |
| 4x8 | 32 | 4 | 8 | v6e-32 |
ct6e-standard-4t |
Mehrere Hosts |
| 8x8 | 64 | 8 | 16 | v6e-64 |
ct6e-standard-4t |
Mehrere Hosts |
| 8x16 | 128 | 16 | 32 | v6e-128 |
ct6e-standard-4t |
Mehrere Hosts |
| 16x16 | 256 | 32 | 64 | v6e-256 |
ct6e-standard-4t |
Mehrere Hosts |
Slices mit 8 Chips (v6e-8), die an eine einzelne VM angehängt sind, sind für Inferenz optimiert. So können alle 8 Chips in einer einzelnen Bereitstellungsarbeitslast verwendet werden. Sie können die Inferenz mit mehreren Hosts mit Pathways on Cloud ausführen. Weitere Informationen finden Sie unter Inferenz auf mehreren Hosts mit Pathways durchführen.
Informationen zur Anzahl der VMs für jede Topologie finden Sie unter VM-Typen.
VM-Typen
Jede TPU v6e-VM kann 1, 4 oder 8 Chips enthalten. Slices mit 4 oder weniger Chips haben denselben NUMA-Knoten (Non-Uniform Memory Access). Weitere Informationen zu NUMA-Knoten finden Sie im Wikipedia-Artikel zu Non-Uniform Memory Access.
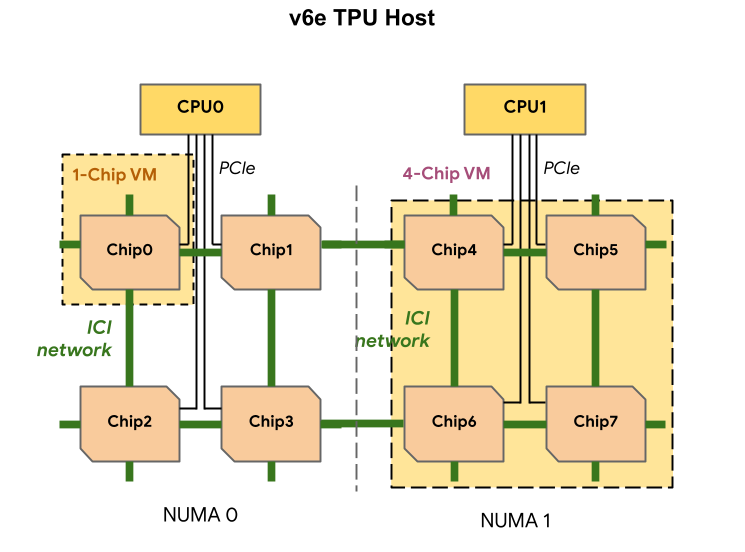
v6e-Slices werden mit Half-Host-VMs erstellt, die jeweils 4 TPU-Chips haben. Für diese Regel gibt es zwei Ausnahmen:
v6e-1: eine VM mit nur einem Chip, die hauptsächlich für Tests vorgesehen istv6e-8: eine VM mit vollständigem Host, die für einen Inferenzanwendungsfall optimiert wurde und bei der alle 8 Chips an eine einzelne VM angehängt sind
In der folgenden Tabelle werden die TPU v6e-VM-Typen verglichen:
| VM-Typ | Anzahl der vCPUs pro VM | RAM (GB) pro VM | Anzahl der NUMA-Knoten pro VM |
|---|---|---|---|
| VM mit einem Chip | 44 | 176 | 1 |
| VM mit 4 Chips | 180 | 720 | 1 |
| VM mit 8 Chips | 180 | 1440 | 2 |
v6e-Konfiguration angeben
Wenn Sie einen TPU v6e-Slice mit der TPU API zuweisen, geben Sie seine Größe und Form mit dem Parameter AcceleratorType an.
Wenn Sie GKE verwenden, geben Sie mit dem Flag --machine-type einen Maschinentyp an, der die TPU unterstützt, die Sie verwenden möchten. Weitere Informationen finden Sie in der GKE-Dokumentation unter TPUs in GKE planen.
AcceleratorType verwenden
Wenn Sie TPU-Ressourcen zuweisen, geben Sie mit AcceleratorType die Anzahl der TensorCores in einem Slice an. Der Wert, den Sie für AcceleratorType angeben, ist ein String im Format v$VERSION-$TENSORCORE_COUNT.
v6e-8 gibt beispielsweise einen v6e-TPU-Slice mit 8 TensorCores an.
Das folgende Beispiel zeigt, wie Sie mit AcceleratorType einen TPU v6e-Slice mit 32 TensorCores erstellen:
gcloud
$ gcloud compute tpus tpu-vm create tpu-name \ --zone=zone \ --accelerator-type=v6e-32 \ --version=v2-alpha-tpuv6e
Console
Rufen Sie in der Google Cloud Console die Seite TPUs auf:
Klicken Sie auf TPU erstellen.
Geben Sie im Feld Name einen Namen für die TPU ein.
Wählen Sie im Feld Zone die Zone aus, in der Sie die TPU erstellen möchten.
Wählen Sie im Feld TPU-Typ die Option
v6e-32aus.Wählen Sie im Feld TPU-Softwareversion die Option
v2-alpha-tpuv6eaus. Beim Erstellen einer Cloud TPU-VM wird im Feld „TPU-Softwareversion“ die Version der zu installierenden TPU-Laufzeit angegeben. Weitere Informationen finden Sie unter TPU-Softwareversionen.Klicken Sie auf die Ein/Aus-Schaltfläche Warteschlange aktivieren.
Geben Sie im Feld Name der Ressource in der Warteschlange einen Namen für die Anfrage für in die Warteschlange gestellte Ressourcen ein.
Klicken Sie auf Erstellen.
Nächste Schritte
- Training und Inferenz mit TPU v6e ausführen