TPU v4
In diesem Dokument werden die Architektur und die unterstützten Konfigurationen von Cloud TPU v4 beschrieben.
Systemarchitektur
Jeder TPU v4-Chip enthält zwei TensorCores. Jeder TensorCore hat vier MXUs (Matrix Multiply Units), eine Vektoreinheit und eine Skalareinheit. In der folgenden Tabelle sehen Sie die wichtigsten Spezifikationen für einen v4 TPU-Pod.
| Wichtige Spezifikationen | v4-Pod-Werte |
|---|---|
| Maximale Rechenleistung pro Chip | 275 TeraFLOPS (bf16 oder int8) |
| HBM2-Kapazität und ‑Bandbreite | 32 GiB, 1.200 Gbit/s |
| Gemessene minimale/durchschnittliche/maximale Leistung | 90/170/192 W |
| TPU-Pod-Größe | 4.096 Chips |
| Interconnect-Topologie | 3D-Mesh |
| Maximale Rechenleistung pro Pod | 1,1 Exaflops (bf16 oder int8) |
| All-Reduce-Bandbreite pro Pod | 1,1 PB/s |
| Bisektionsbandbreite pro Pod | 24 TB/s |
Das folgende Diagramm zeigt einen TPU v4-Chip.
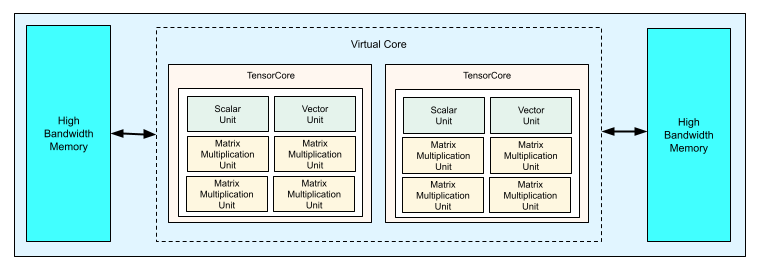
Weitere Informationen zu Architekturdetails und Leistungsmerkmalen für TPU v4 finden Sie im Paper TPU v4: An Optically Reconfigurable Supercomputer for Machine Learning with Hardware Support for Embeddings.
3D-Mesh und 3D-Torus
TPUs der 4. Generation haben eine direkte Verbindung zu den nächstgelegenen benachbarten Chips in 3 Dimensionen, was zu einem 3D-Mesh von Netzwerkverbindungen führt. Die Verbindungen können als 3D-Torus auf Slices konfiguriert werden, wobei die Topologie AxBxC entweder 2A=B=C oder 2A=2B=C ist und jede Dimension ein Vielfaches von 4 ist. Beispiele: 4 × 4 × 8, 4 × 8 × 8 oder 12 × 12 × 24. Im Allgemeinen ist die Leistung einer 3D-Toruskonfiguration besser als die einer 3D-Mesh-Konfiguration. Weitere Informationen finden Sie im Paper Twisted Torus Topologies.
Leistungsvorteile von TPU v4 im Vergleich zu v3
In diesem Abschnitt wird eine speichereffiziente Methode zum Ausführen eines Beispiel-Trainingsskripts auf TPU v4 beschrieben sowie die Leistungsverbesserungen für TPU v4 im Vergleich zu TPU v3 .
Arbeitspeichersystem
NUMA (Non Uniform Memory Access) ist eine Arbeitsspeicherarchitektur für Computer mit mehreren CPUs. Jede CPU hat direkten Zugriff auf einen Block mit schnellem Arbeitsspeicher. Eine CPU und ihr Arbeitsspeicher werden als NUMA-Knoten bezeichnet. NUMA-Knoten sind mit anderen NUMA-Knoten verbunden, die direkt nebeneinander liegen. Eine CPU aus einem NUMA-Knoten kann auf den Arbeitsspeicher in einem anderen NUMA-Knoten zugreifen, dieser Zugriff ist jedoch langsamer als der Zugriff auf den Arbeitsspeicher innerhalb eines NUMA-Knotens.
Software, die auf einer Maschine mit mehreren CPUs ausgeführt wird, kann Daten, die von einer CPU benötigt werden, in ihrem NUMA-Knoten platzieren, wodurch der Speicherdurchsatz erhöht wird. Weitere Informationen zu NUMA finden Sie im Wikipedia-Artikel Non-Uniform Memory Access.
Sie können die Vorteile der NUMA-Lokalität nutzen, indem Sie Ihr Trainingsskript an NUMA-Knoten 0 binden.
So aktivieren Sie die NUMA-Knotenbindung:
Installieren Sie das numactl-Befehlszeilentool. Mit numactl können Sie Prozesse mit einer bestimmten NUMA-Zuweisungs- oder Speicherplatzierungsrichtlinie ausführen.
$ sudo apt-get update $ sudo apt-get install numactl
Binden Sie Ihren Skriptcode an NUMA-Knoten 0. Ersetzen Sie your-training-script durch den Pfad zu Ihrem Trainingsskript.
$ numactl --cpunodebind=0 python3 your-training-script
Aktivieren Sie die NUMA-Knotenbindung in folgenden Fällen:
- Wenn Ihre Arbeitslast unabhängig vom Framework stark von CPU-Arbeitslasten abhängig ist (z. B. Bildklassifizierung, Empfehlungsarbeitslasten).
- Wenn Sie eine TPU-Laufzeitversion ohne das Suffix „-pod“ verwenden (z. B.
tpu-vm-tf-2.10.0-v4).
Weitere Unterschiede beim Arbeitsspeicher:
- v4-TPU-Chips haben einen einheitlichen 32-GiB-HBM-Arbeitsspeicher über den gesamten Chip hinweg, was eine bessere Koordination zwischen den beiden TensorCores auf dem Chip ermöglicht.
- Verbesserte HBM-Leistung durch die Verwendung der neuesten Speicherstandards und -geschwindigkeiten.
- Verbessertes DMA-Leistungsprofil mit integrierter Unterstützung für leistungsstarkes Stride-Verfahren mit einer Granularität von 512 Byte.
TensorCores
- Doppelte Anzahl von MXUs und eine höhere Taktfrequenz mit maximal 275 TFLOPS.
- 2‑fache Transpositions- und Permutationsbandbreite.
- Load-Store-Speicherzugriffsmodell für Common Memory (Cmem).
- Schnellere Bandbreite für das Laden von MXU-Gewichten und Unterstützung des 8-Bit-Modus für kleinere Batch-Größen und eine verbesserte Inferenzlatenz.
Inter-Chip-Interconnect
Sechs Interconnect-Links pro Chip für Netzwerk-Topologien mit kleineren Netzwerkdurchmessern.
Sonstiges
- x16 PCIE Gen3-Schnittstelle zum Host (direkte Verbindung)
- Verbessertes Sicherheitsmodell
- Höhere Energieeffizienz
Konfigurationen
Ein TPU v4-Pod besteht aus 4.096 Chips, die über rekonfigurierbare Hochgeschwindigkeitsverbindungen miteinander verbunden sind. Die flexible Vernetzung von TPU v4 ermöglicht es Ihnen, die Chips in einem Slice derselben Größe auf verschiedene Arten zu verbinden. Beim Erstellen eines TPU-Slice geben Sie die TPU-Version und die Anzahl der erforderlichen TPU-Ressourcen an. Wenn Sie ein TPU v4-Slice erstellen, können Sie seinen Typ und seine Größe auf zwei Arten angeben: AcceleratorType und AccleratorConfig.
AcceleratorType verwenden
Verwenden Sie „AcceleratorType“, wenn Sie keine Topologie angeben. Wenn Sie v4-TPUs mit AcceleratorType konfigurieren möchten, verwenden Sie das Flag --accelerator-type, um den TPU-Slice zu erstellen. Legen Sie --accelerator-type auf einen String fest, der die TPU-Version und die Anzahl der TensorCores enthält, die Sie verwenden möchten. Wenn Sie beispielsweise ein v4-Slice mit 32 TensorCores erstellen möchten, verwenden Sie --accelerator-type=v4-32.
Verwenden Sie den Befehl gcloud compute tpus tpu-vm create, um mit dem Flag --accelerator-type ein TPU-Slice der Version 4 mit 512 TensorCores zu erstellen:
$ gcloud compute tpus tpu-vm create your-tpu-name \ --zone=us-central2-b \ --accelerator-type=v4-512 \ --version=tpu-ubuntu2204-base
Die Zahl nach der TPU-Version (v4) gibt die Anzahl der TensorCores an.
Eine v4 TPU hat zwei TensorCores. Die Anzahl der TPU-Chips wäre also 512/2 = 256.
Weitere Informationen zum Verwalten von TPUs finden Sie unter TPUs verwalten. Weitere Informationen zur Systemarchitektur von Cloud TPU finden Sie unter Systemarchitektur.
AcceleratorConfig verwenden
Verwenden Sie AcceleratorConfig, wenn Sie die physische Topologie Ihres TPU-Slice anpassen möchten. Dies ist in der Regel für die Leistungsoptimierung mit Slices mit mehr als 256 Chips erforderlich.
Wenn Sie v4-TPUs mit AcceleratorConfig konfigurieren möchten, verwenden Sie die Flags --type und --topology. Setzen Sie --type auf die TPU-Version, die Sie verwenden möchten, und --topology auf die physische Anordnung der TPU-Chips im Slice.
Sie geben eine TPU-Topologie mit einem 3-Tupel AxBxC an, wobei A<=B<=C und A, B, C entweder alle <= 4 oder alle ganzzahlige Vielfache von 4 sind. Die Werte A, B und C sind die Anzahl der Chips in den drei Dimensionen. Wenn Sie beispielsweise einen v4-Slice mit 16 Chips erstellen möchten, legen Sie --type=v4 und --topology=2x2x4 fest.
Verwenden Sie den Befehl gcloud compute tpus tpu-vm create, um ein TPU v4-Slice mit 128 TPU-Chips zu erstellen, die in einem 4 × 4 × 8-Array angeordnet sind:
$ gcloud compute tpus tpu-vm create your-tpu-name \ --zone=us-central2-b \ --type=v4 \ --topology=4x4x8 \ --version=tpu-ubuntu2204-base
Topologien, bei denen 2A=B=C oder 2A=2B=C gilt, haben auch Topologievarianten, die für die All-to-All-Kommunikation optimiert sind, z. B. 4×4×8, 8×8×16 und 12×12×24. Diese werden als Twisted-Torus-Topologien bezeichnet.
Die folgenden Abbildungen zeigen einige gängige TPU v4-Topologien.
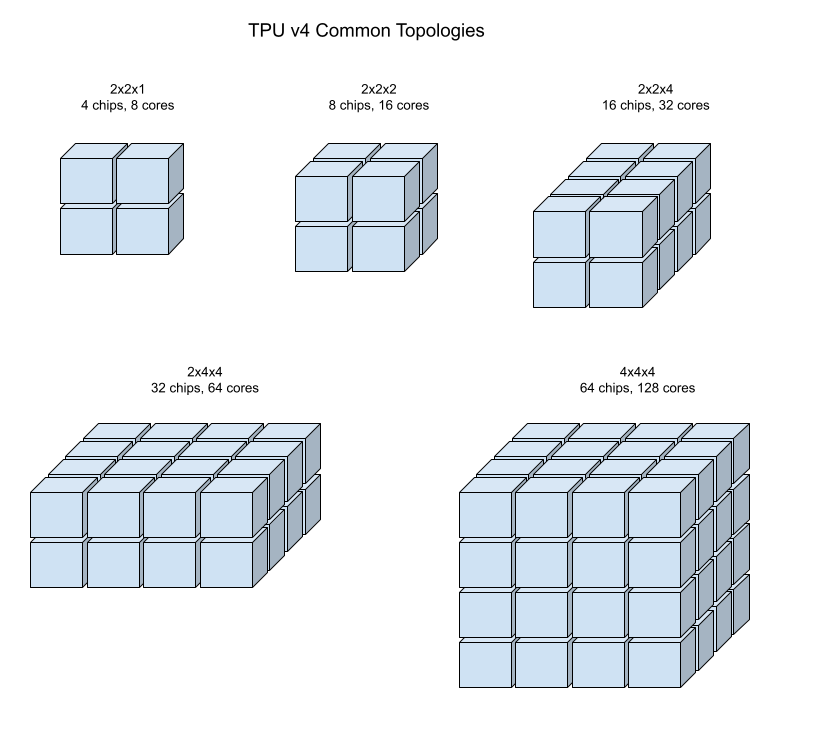
Größere Slices können aus einem oder mehreren 4 × 4 × 4-Cubes von Chips bestehen.
Weitere Informationen zum Verwalten von TPUs finden Sie unter TPUs verwalten. Weitere Informationen zur Systemarchitektur von Cloud TPU finden Sie unter Systemarchitektur.
Twisted-Torus-Topologie
Einige v4-3D-Torus-Slice-Formen bieten die Möglichkeit, eine sogenannte Twisted-Torus-Topologie zu verwenden. Beispiel: Zwei v4-Cubes können als 4x4x8-Slice oder 4x4x8_twisted angeordnet werden. Twisted-Topologien bieten eine deutlich höhere Bisektionsbandbreite. Ein Slice mit der Topologie „4x4x8_twisted“ bietet beispielsweise eine theoretische Steigerung der Bisektionsbandbreite um 70 % im Vergleich zu einem nicht-twisted 4x4x8-Slice. Eine höhere Bisektionsbandbreite ist nützlich für Arbeitslasten, die globale Kommunikationsmuster verwenden. Twisted-Topologien können die Leistung für die meisten Modelle verbessern. Das gilt insbesondere für große TPU-Einbettungsarbeitslasten.
Bei Arbeitslasten, bei denen die Datenparallelität die einzige Parallelitätsstrategie ist, kann die Leistung von Twisted-Topologien etwas besser sein. Bei LLMs kann die Leistung bei Verwendung einer Twisted-Topologie je nach Art der Parallelität (DP, MP usw.) variieren. Es empfiehlt sich, Ihr LLM sowohl mit als auch ohne Twisted-Topologie zu trainieren, um zu sehen, welche Option die beste Leistung für Ihr Modell bietet. Bei einigen Tests mit dem FSDP-MaxText-Modell wurden mit einer Twisted-Topologie Verbesserungen von 1–2 MFU erzielt.
Der Hauptvorteil von verdrehten Topologien besteht darin, dass sie eine asymmetrische Torus-Topologie (z. B. 4×4×8) in eine eng verwandte symmetrische Topologie umwandeln. Die symmetrische Topologie bietet viele Vorteile:
- Verbessertes Load Balancing
- Höhere Bisektionsbandbreite
- Kürzere Paketrouten
Diese Vorteile führen letztendlich zu einer besseren Leistung bei vielen globalen Kommunikationsmustern.
Die TPU-Software unterstützt Twisted-Tori auf Slices, bei denen die Größe jeder Dimension entweder gleich oder doppelt so groß wie die kleinste Dimension ist. Beispiele: 4 × 4 × 8, 4 × 8 × 8 oder 12 × 12 × 24.
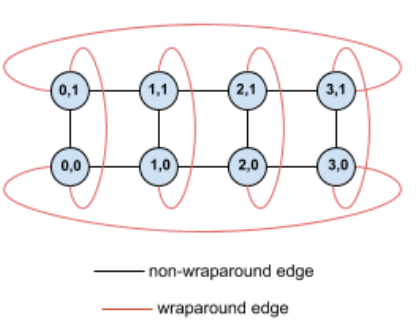
Hier ein Beispiel für eine 4 × 2-Torus-Topologie mit TPUs, die mit ihren (X,Y)-Koordinaten im Slice gekennzeichnet sind:
Die Kanten in diesem Topologiegrafen werden zur besseren Übersicht als ungerichtete Kanten dargestellt. In der Praxis ist jede Kante eine bidirektionale Verbindung zwischen TPUs. Die Kanten zwischen einer Seite dieses Rasters und der gegenüberliegenden Seite werden als Wrap-around-Kanten bezeichnet, wie im Diagramm dargestellt.
Durch das Verdrehen dieser Topologie erhalten wir eine vollständig symmetrische 4 × 2-Topologie mit Twisted-Torus:
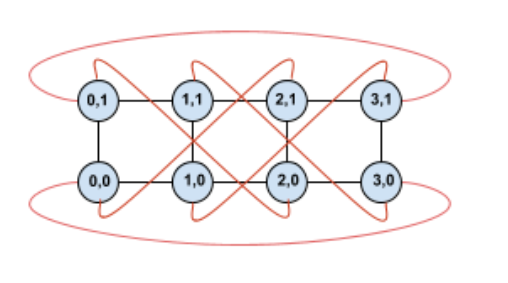
Der einzige Unterschied zwischen diesem und dem vorherigen Diagramm sind die Y-Wrap-around-Kanten. Anstatt eine Verbindung zu einer anderen TPU mit derselben X-Koordinate herzustellen, wurden sie so verschoben, dass sie eine Verbindung zur TPU mit der Koordinate X+2 mod 4 herstellen.
Dasselbe gilt für verschiedene Dimensionsgrößen und unterschiedliche Anzahlen von Dimensionen. Das resultierende Netzwerk ist symmetrisch, solange jede Dimension gleich oder doppelt so groß wie die kleinste Dimension ist.
Weitere Informationen zum Angeben einer Twisted-Torus-Konfiguration beim Erstellen einer Cloud TPU finden Sie unter AcceleratorConfig verwenden.
In der folgenden Tabelle sind die unterstützten Twisted-Topologien und die theoretische Steigerung der Bisektionsbandbreite im Vergleich zu Nicht-Twisted-Topologien aufgeführt.
| Twisted-Topologie | Theoretische Steigerung der Bisektionsbandbreite im Vergleich zu einem Nicht-Twisted-Torus |
|---|---|
| 4×4×8_twisted | ~70 % |
| 8x8x16_twisted | |
| 12×12×24_twisted | |
| 4×8×8_twisted | ~40 % |
| 8×16×16_twisted |
TPU v4-Topologievarianten
Einige Topologien mit derselben Anzahl von Chips können unterschiedlich angeordnet werden. Ein TPU-Segment mit 512 Chips (1.024 TensorCores) kann beispielsweise mit den folgenden Topologien konfiguriert werden: 4 × 4 × 32, 4 × 8 × 16 oder 8 × 8 × 8. Ein TPU-Slice mit 2.048 Chips (4.096 TensorCores) bietet noch mehr Topologieoptionen: 4 x 4x 128, 4 x 8 x 64, 4 x 16 x 32 und 8 x 16 x 16.
Die Standardtopologie, die einer bestimmten Anzahl von Chips zugeordnet ist, ist diejenige, die einem Cube am ähnlichsten ist. Diese Form ist wahrscheinlich die beste Wahl für datenparalleles ML-Training. Andere Topologien können für Arbeitslasten mit mehreren Arten von Parallelität nützlich sein, z. B. Modell- und Datenparallelität oder räumliche Partitionierung einer Simulation. Diese Arbeitslasten funktionieren am besten, wenn die Topologie an die verwendete Parallelität angepasst ist. Wenn Sie beispielsweise eine 4-fache Modellparallelität in der X-Dimension und 256-fache-Datenparallelität in der Y- und Z-Dimension platzieren, entspricht das einer 4 × 16 × 16-Topologie.
Modelle mit mehreren Parallelitätsdimensionen funktionieren am besten, wenn ihre Parallelitätsdimensionen den TPU-Topologiedimensionen zugeordnet sind. Dabei handelt es sich in der Regel um daten- und modellparallele Large Language Models (LLMs). Bei einem TPU v4-Slice mit der Topologie 8 × 16 × 16 sind die TPU-Topologiedimensionen beispielsweise 8, 16 und 16. Es ist leistungsfähiger, 8- oder 16-fache Modellparallelität zu verwenden, die einer der physischen TPU-Topologiedimensionen zugeordnet ist. Eine 4-fache Modellparallelität wäre bei dieser Topologie nicht optimal, da sie an keiner der TPU-Topologiedimensionen ausgerichtet ist. Bei einer 4 x 16 x 32-Topologie mit derselben Anzahl von Chips wäre sie jedoch optimal.
TPU v4-Konfigurationen bestehen aus zwei Gruppen: Konfigurationen mit Topologien mit weniger als 64 Chips (kleine Topologien) und Konfigurationen mit Topologien mit mehr als 64 Chips (große Topologien).
Kleine v4-Topologien
Cloud TPU unterstützt die folgenden TPU v4-Segmente mit weniger als 64 Chips, einem 4 × 4 × 4-Cube. Sie können diese kleinen v4-Topologien entweder mit dem TensorCore-basierten Namen (z. B. v4-32) oder mit der Topologie (z. B. 2 x 2 x 4) erstellen:
| Name (basierend auf der Anzahl der TensorCores) | Anzahl der Chips | Topologie |
| v4-8 | 4 | 2 x 2 x 1 |
| v4-16 | 8 | 2 x 2 x2 |
| v4-32 | 16 | 2 x 2 x 4 |
| v4-64 | 32 | 2 x 4 x 4 |
Große v4-Topologien
TPU v4-Slices sind in Schritten von 64 Chips verfügbar. Die Formen sind in allen drei Dimensionen Vielfache von 4. Die Dimensionen müssen in aufsteigender Reihenfolge angegeben werden. In der folgenden Tabelle finden Sie einige Beispiele. Einige dieser Topologien sind benutzerdefinierte Topologien, die nur mit den Flags --type und --topology erstellt werden können, da es mehrere Möglichkeiten gibt, die Chips anzuordnen.
| Name (basierend auf der Anzahl der TensorCores) | Anzahl der Chips | Topologie |
| v4-128 | 64 | 4 x 4 x 4 |
| v4-256 | 128 | 4 x 4 x 8 |
| v4-512 | 256 | 4 x 8 x 8 |
Benutzerdefinierte Topologie: Die Flags --type und --topology müssen verwendet werden. |
256 | 4 x 4 x 16 |
| v4-1024 | 512 | 8 x 8 x 8 |
| v4-1536 | 768 | 8 x 8 x 12 |
| v4-2048 | 1.024 | 8 x 8 x 16 |
Benutzerdefinierte Topologie: Die Flags --type und --topology müssen verwendet werden. |
1.024 | 4 x 16 x 16 |
| v4-4096 | 2.048 | 8 x 16 x 16 |
| … | … | … |