Cloud TPU VM でモデルをプロファイリングする
プロファイリングを使用すると、Cloud TPU でのモデルのトレーニング パフォーマンスを最適化できます。TensorBoard と Cloud TPU TensorBoard プラグインを使用して、モデルをプロファイリングします。
サポートされているフレームワークのいずれかと TensorBoard を使用する方法については、次のドキュメントをご覧ください。
トレーニング スクリプトのプロファイリングの前提条件
TPU プロファイリング ツールを使用する前に、次のことを行う必要があります。
モデル トレーニング セッションを開始する
- v4-8 TPU を設定してモデルをトレーニングします。このドキュメントで説明するプロファイリング手順では ResNet モデルを使用しますが、v4 TPU でトレーニングされる別のモデルを使用することもできます。
TPU VM で、プロファイラ サーバーを起動する行をトレーニング スクリプトに追加します。
ResNET トレーニングの場合、トレーニング スクリプトは
/usr/share/tpu/tensorflow/resnet50_keras/resnet50.pyにあります。ハイライト表示された行を resnet50.py に挿入します。ファイルの先頭に、次のインポートを追加します。
import tensorflow.compat.v2 as tf2
スクリプトがトレーニング ループを開始する直前に、ハイライト表示された行を追加します。
if name == 'main': tf.logging.set_verbosity(tf.logging.INFO) tf2.profiler.experimental.server.start(6000) app.run(main)
スクリプトを実行すると、TPU VM で TensorFlow Profiler サーバーが起動します。
モデルのトレーニングを開始します。
トレーニング スクリプトを実行し、モデルがアクティブにトレーニングされていることを示す出力が表示されるまで待ちます。出力はコードとモデルによって異なります。
Epoch 1/100のような出力を探します。 または、Google Cloud コンソール の Cloud TPU ページに移動して TPU を選択し、CPU 使用率のグラフを表示することもできます。CPU 使用率のグラフには TPU 使用率は表示されませんが、TPU によってモデルがトレーニングされていることを示す良いサインです。
モデル トレーニングのプロファイリングを開始する
モデルがトレーニング中である場合は、別のターミナル ウィンドウまたは Cloud Shell を開きます。次の手順で、モデル トレーニングのプロファイリングを開始します。
新しいウィンドウまたはシェルで、ポート転送を使用して TPU VM に接続します。
gcloud compute tpus tpu-vm ssh your-vm --zone=us-central2-b --ssh-flag="-4 -L 9001:localhost:9001"
ポート転送を使用すると、ローカル ブラウザが TPU VM 上で実行されている TensorBoard サーバーと通信できるようになります。
TensorFlow の要件をインストールします。
TPU VM には、デフォルトで TensorBoard がインストールされています。TensorFlow を手動でインストールすることもできます。どちらの場合も、追加の依存関係が必要になる場合があります。次のコマンドを実行して、TPU VM にこれらの依存関係をインストールします。
pip3 install -r /usr/share/tpu/models/official/requirements.txt
Cloud TPU TensorBoard プラグインをインストールします。
TPU VM から、次のコマンドを実行します。
pip3 install --upgrade "cloud-tpu-profiler>=2.3.0" pip3 install tensorflow pip3 install tensorboard_plugin_profile
TensorBoard サーバーを起動する
TensorBoard を実行し、TensorBoard がプロファイリング データを書き込むことができる TPU VM にログ ディレクトリ(
logdir)を作成します。--logdirフラグを使用してログ ディレクトリを指定します。例:mkdir log-directory TPU_LOAD_LIBRARY=0 tensorboard --logdir log-directory --port 9001
TensorBoard でウェブサーバーが起動され、その URL が表示されます。
Serving TensorBoard on localhost; to expose to the network, use a proxy or pass --bind_all TensorBoard 2.3.0 at http://localhost:9001 (Press CTRL+C to quit)
ウェブブラウザを開き、TensorBoard の出力に表示されている URL に移動します。TensorBoard ページの右上にあるプルダウン メニューから [プロファイル] を選択します。使用可能なプロファイリング ツールのリストが、左側のサイドバーの [ツール] プルダウン メニューに表示されます。
TPU VM でプロファイルをキャプチャする
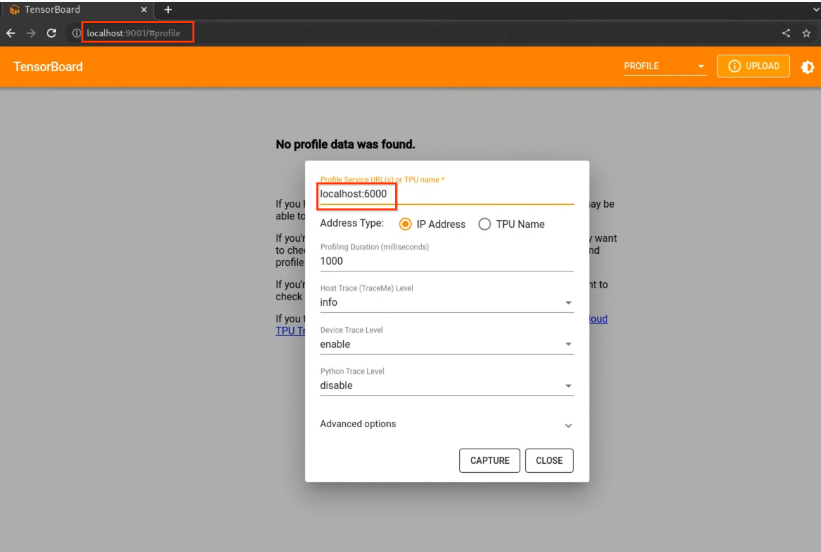
- [CAPTURE PROFILE] ボタンを選択します。
- [IP アドレス] ラジオボタンを選択します。
Profile Service URLフィールドに「HOSTNAME:6000」と入力します。- CAPTUREボタンを選択します。
TensorBoard でプロファイル データを表示する
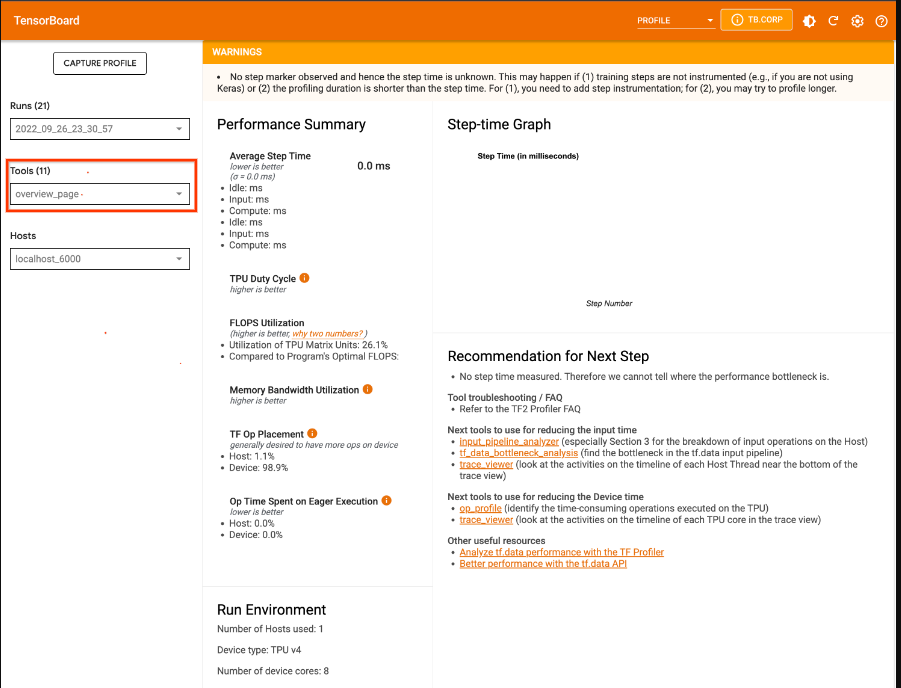
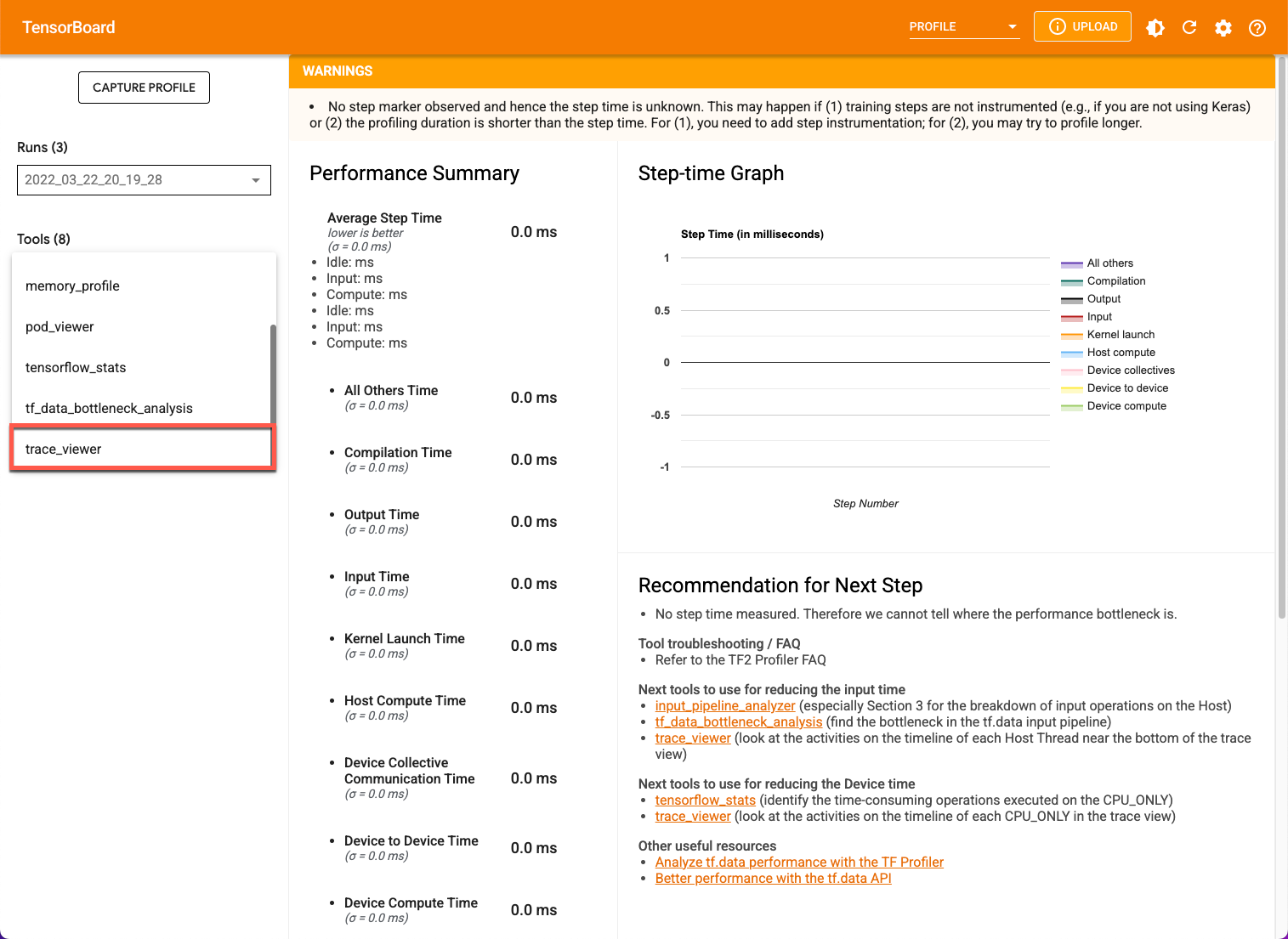
プロファイルをキャプチャすると、TensorBoard に「overview_page」が表示されます。使用できるプロファイリング ツールのリストが左側のペインに表示されます。
プロフィール
[Profile] タブは、一部のモデルデータがキャプチャされると表示されます。TensorBoard ページでの [更新] ボタンのクリックが必要になる場合があります。データが利用可能になり、[Profile] タブをクリックすると、パフォーマンス分析に役立つ次のようなツールが表示されます。次のいずれかのツールを使用してモデルをプロファイリングできます。
- 概要ページ
- 入力パイプライン分析ツール
- XLA 演算プロファイル
- トレース ビューア(Chrome ブラウザのみ)
- メモリビューア
プロファイルの概要ページ
[overview_page] ページにある概要ページ(overview_page)には、キャプチャ中のモデルがどのように実行されたかが表示されます。このページには、すべての TPU を集計した概要と入力パイプライン全体の分析結果が表示されます。ホスト プルダウンから個別の TPU を選択することもできます。
このページでは、次のパネルにデータが表示されます。
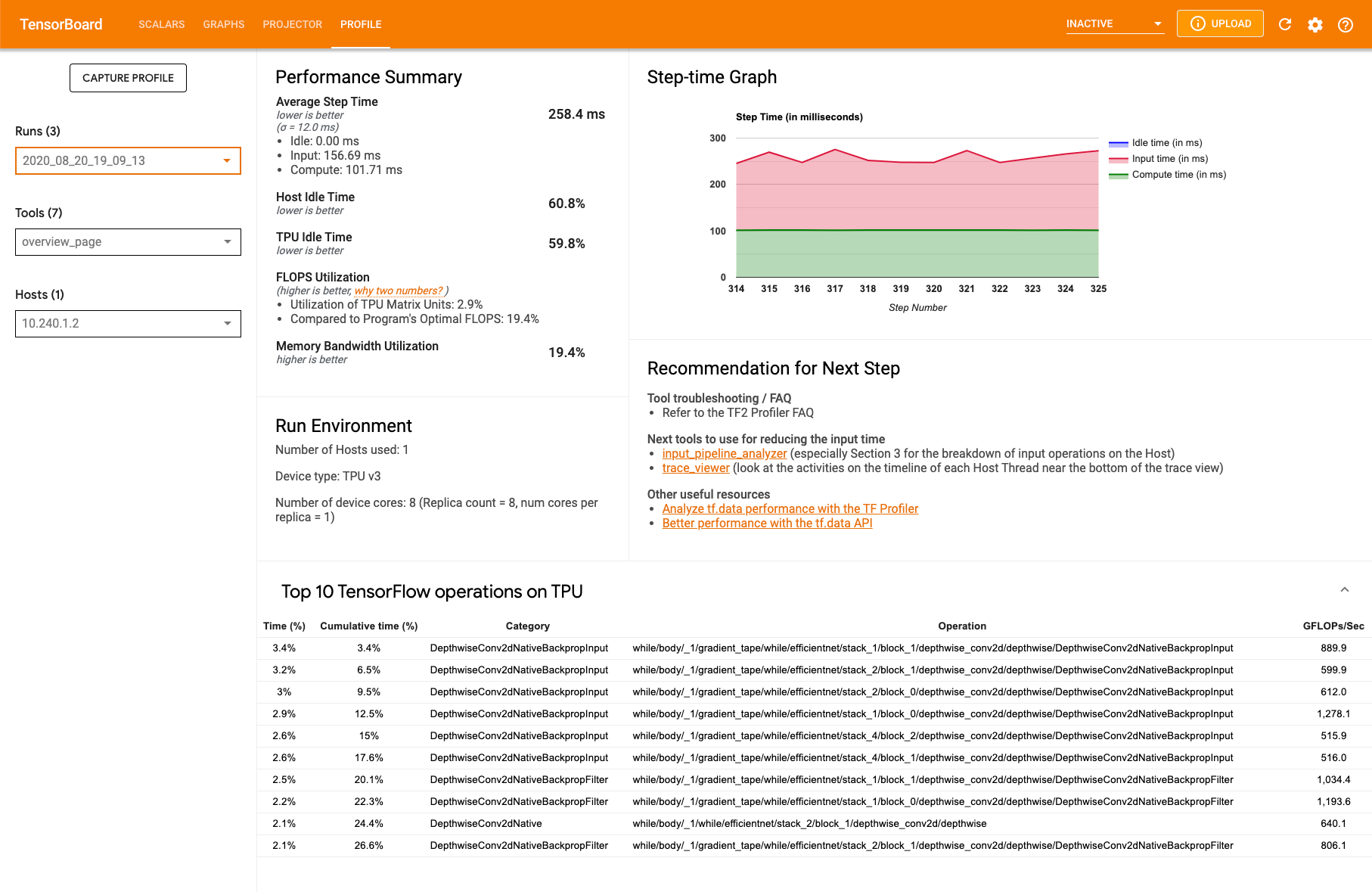
パフォーマンス サマリー
- FLOPS 使用率 - TPU マトリックス ユニットの使用率
TPU での上位 10 個の TensorFlow 演算では、最も多くの時間が費やされた TensorFlow 演算が表示されます。
各行には、演算に費やされた自己時間 (すべての演算にかかった時間に占める割合)、累積時間、カテゴリ、名前、および達成された FLOPS 率が表示されます。
実行環境
- 使用されるホストの数
- 使用される TPU のタイプ
- TPU コアの数
入力パイプライン分析ツール
入力パイプライン分析ツールを使用すると、パフォーマンスの結果をより詳しく分析できます。 このツールは、プログラムで負荷の高い入力処理をすぐに通知し、デバイス側とホスト側で分析を行い、ボトルネックとなっているパイプラインのステージをデバッグできます。
パイプラインのパフォーマンスの最適化について詳しくは、入力パイプラインのパフォーマンスに関するガイダンスをご覧ください。
入力パイプライン
TensorFlow プログラムがファイルからデータを読み込むと、読み取りプロセスは連続した複数のデータ処理ステージに分割されます。1 つのステージの出力が次のステージの入力になります。この読み込み方式を入力パイプラインといいます。
ファイルからレコードを読み取るための一般的なパイプラインには、次のステージがあります。
- ファイルの読み取り
- ファイルの前処理(オプション)
- ホストマシンからデバイスへのファイル転送
入力パイプラインが非効率な場合、アプリケーションの速度が大幅に低下する可能性があります。入力パイプラインに多くの時間が費やされている場合、このアプリケーションは入力バウンドとみなされます。入力パイプライン分析ツールを使用すると、非効率な入力パイプラインを特定できます。
入力パイプライン ダッシュボード
入力パイプライン分析ツールを開くには、[プロファイル] を選択し、[ツール] プルダウンから [input_pipeline_analyzer] を選択します。
ダッシュボードには、デバイス側とホスト側の分析の詳細が表示されます。
デバイス側の分析 - デバイスのステップ時間の詳細が表示されます。
- デバイスのステップ時間の統計情報。
- 入力データを待機しているデバイスのステップ時間の割合
ホスト側の分析
このセクションには、ホスト側の分析の詳細が表示されます。これは、いくつかのカテゴリに分類されています。
- デバイスに転送するデータのエンキュー。デバイスへの転送前にデータがインフィード キューに追加される際に費やされた時間。
- データの前処理 画像の圧縮など、前処理演算に費やされた時間。
- ファイルからの事前のデータ読み取り: キャッシュ保存、プリフェッチ、インターリーブなど、ファイルの読み取りに費やされた時間。
- ファイルからのオンデマンドのデータ読み取り キャッシュ保存、プリフェッチ、インターリーブなしで、ファイルからデータを読み取る際に費やされた時間。
- その他のデータの読み取りまたは処理
tf.dataを使用しない、その他の入力関連の演算に費やされた時間。

個別の入力演算の統計とそれらのカテゴリの内訳を実行時間別に表示するには、[Show Input Op statistics] セクションを開きます。
ソースデータ テーブルは次のようになります。
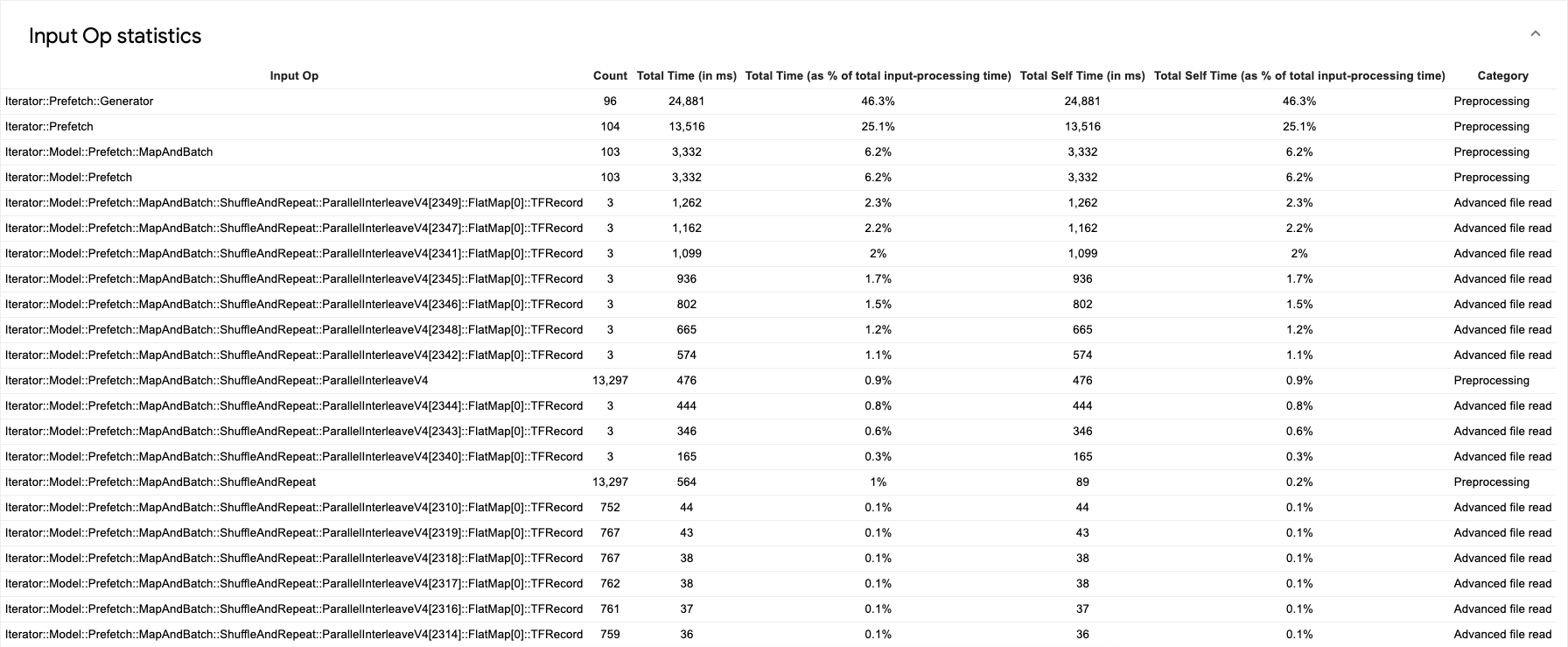
各テーブル エントリには、次の情報が含まれます。
- 入力演算: 入力演算の TensorFlow 演算名が表示されます。
- カウント: プロファイリング期間中に実行された演算のインスタンスの合計数が表示されます。
- 合計時間(ミリ秒): 各演算インスタンスに費やされた時間の累積合計が表示されます。
- 合計時間(%): 演算に費やされた合計時間が、入力処理に費やされた合計時間との割合で表示されます。
- 合計自己時間(ミリ秒): 関数のすべてのインスタンスの累積時間を示します。この自己時間は、関数本体内で費やされた時間を測定したもので、関数本体から呼び出される関数で費やされた時間は含まれません。たとえば、
Iterator::PaddedBatch::Filter::ForeverRepeat::MapはIterator::PaddedBatch::Filterによって呼び出されるため、その合計自己時間は、後者の合計自己時間から除外されます。 - 合計自己時間(%): 合計自己時間が、入力処理に費やされた合計時間との割合で表示されます。
- カテゴリ: 入力演算の処理カテゴリを示します。
演算プロファイル
演算プロファイルは、プロファイリング期間中に実行された XLA 演算のパフォーマンス統計を表示する Cloud TPU ツールです。演算プロファイルには次の情報が表示されます。
- アプリケーションによる Cloud TPU の使用状況。演算に費やされた時間の割合がカテゴリ別に表示されます。また、TPU FLOPS の使用率も表示されます。
- 最も時間のかかる演算。これらの演算は、最適化の潜在的なターゲットとなります。
- 個々の演算の詳細。演算で使用される形状、パディング、式などが表示されます。
演算プロファイルを使用すると、最適化のターゲットを見つけることができます。たとえば、演算プロファイルを使用して、実行に最も長い時間を要している XLA 演算と、それらの演算で消費される TPU FLOPS の量を特定できます。
演算プロファイルの使用
演算プロファイル ツールには、XLA 演算のパフォーマンス統計が含まれています。画面上部の [プロファイル] タブをクリックし、[ツール] プルダウンから [op_profile] を選択すると、TensorBoard で演算プロファイル データを表示できます。次のような画面が表示されます。
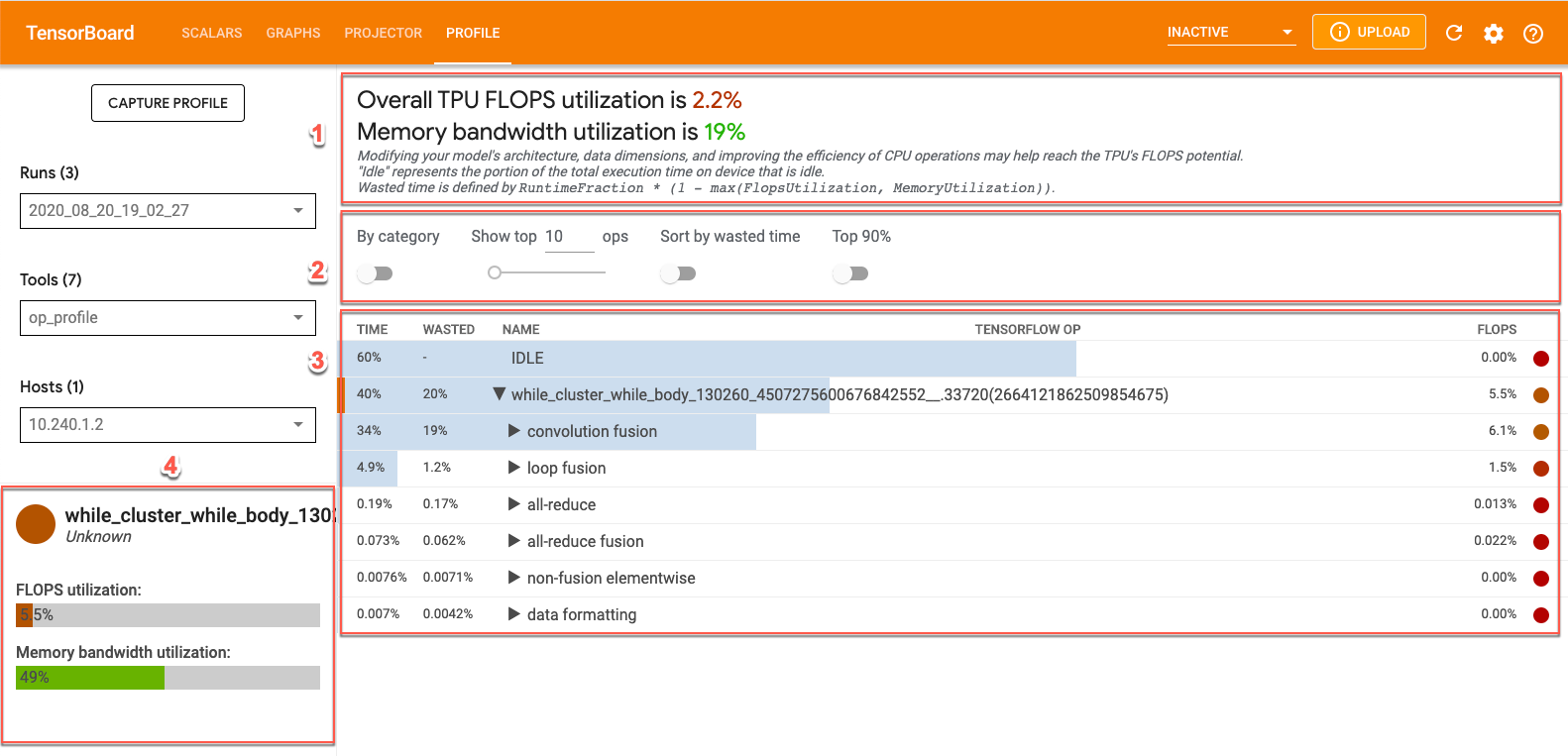
- 概要セクション: Cloud TPU の使用率を表示され、最適化のための推奨事項が表示されます。
- コントロール パネル: テーブルに表示されるオペレーションの数、表示されるオペレーション、並べ替え方法を設定するためのコントロールが含まれます。
- 演算テーブル: XLA 演算に関連付けられている TensorFlow 演算の上位カテゴリを一覧表示します。これらの演算は、Cloud TPU 使用率の順に並んでいます。
- 演算詳細カード: テーブル内の演算にカーソルを合わせると、演算の詳細が表示されます。FLOPS 使用率、演算が使用されている式、演算レイアウト(fit)などの詳細が表示されます。
XLA 演算テーブル
演算テーブルには、Cloud TPU 使用率の高い順に XLA 演算カテゴリが表示されます。テーブルには、実行時間の割合、演算カテゴリ名、関連する TensorFlow 演算名、カテゴリの FLOPS 使用率が表示されます。カテゴリで最も時間のかかる XLA 演算の上位 10 個の表示と非表示を切り替えるには、テーブル内のカテゴリ名の横にある三角形をクリックします。
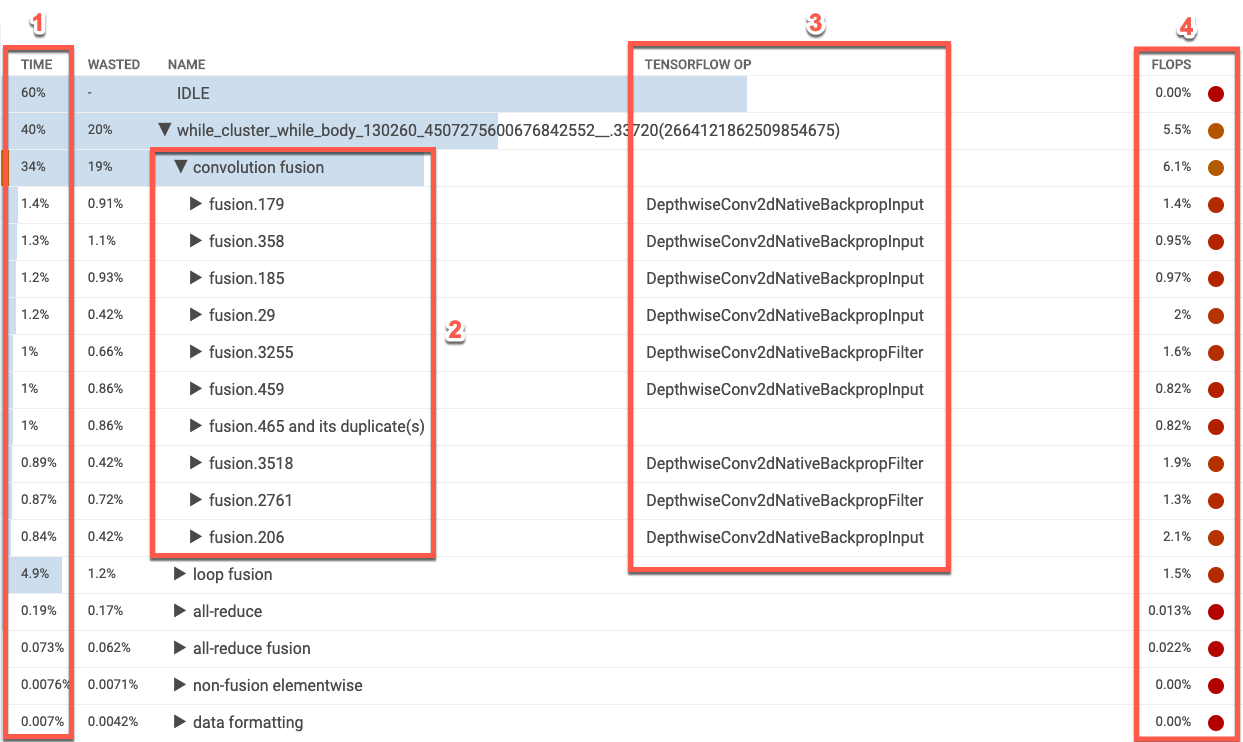
- 時間: そのカテゴリに含まれるすべての演算の実行時間の合計を割合で表します。クリックするとエントリが展開され、個々の演算によって費やされた時間の内訳が表示されます。
- 上位 10 個の演算: カテゴリ名の横にあるトグル。カテゴリ内で時間のかかる上位 10 個の演算を表示または非表示にします。演算リストに fusion 演算が表示されている場合、このエントリを展開すると、fusion 以外の要素ごとの演算が表示されます。
- TensorFlow 演算: XLA 演算に関連付けられている TensorFlow 演算名が表示されます。
- FLOPS: FLOPS 使用率が表示されます。FLOPS の測定値が Cloud TPU ピーク FLOPS の割合として表示されます。FLOPS 使用率が高いほど、演算が速くなります。テーブルセルは色分けされています。FLOPS 使用率が高い場合には緑色(良好)、FLOPS 使用率が低い場合には赤色(不良)です。
演算詳細カード
テーブル エントリを選択すると、XLA 演算または演算カテゴリの詳細を表示するカードが表示されます。通常、次のようなカードが表示されます。
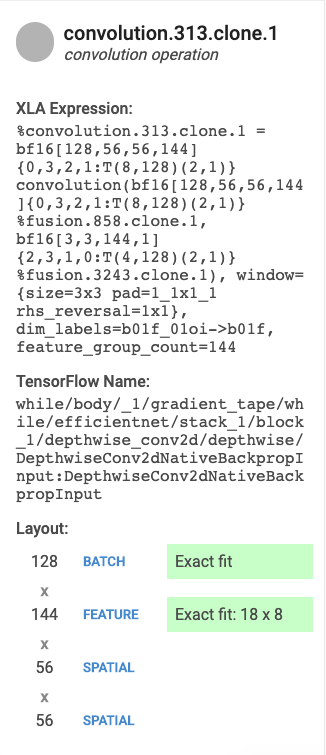
- 名前とカテゴリ: XLA 演算名とカテゴリが強調表示されます。
- FLOPS 使用率 FLOPS の使用率が FLOPS の合計数に対する割合として表示されます。
- 式: 演算を含む XLA 式が表示されます。
- メモリ使用率: プログラムによるピーク時のメモリ使用率が表示されます。
- レイアウト(畳み込み演算のみ): XLA コンパイラによって実行されるパディングの説明を含む、テンソルの形状とレイアウトが表示されます。
結果の解釈
畳み込み演算の場合は、次のいずれかまたは両方の理由で TPU FLOPS の使用率が低くなる可能性があります。
- パディング(マトリックス ユニットが部分的に使用されている)
- 畳み込み演算がメモリバインドになっている
このセクションでは、FLOPS 使用率が低いモデルのパフォーマンス指標について解釈します。この例では、出力フュージョン と 畳み込み が実行時間の大半を占めています。FLOPS 使用率が低いベクトル演算またはスカラー演算が多数ありました。
このようなプロファイルを最適化する方法としては、ベクトル演算またはスカラー演算を畳み込み演算に変換する方法があります。
次の例で、%convolution.399 は前の例の %convolution.340 よりも FLOPS とメモリ使用率が低くなっています。
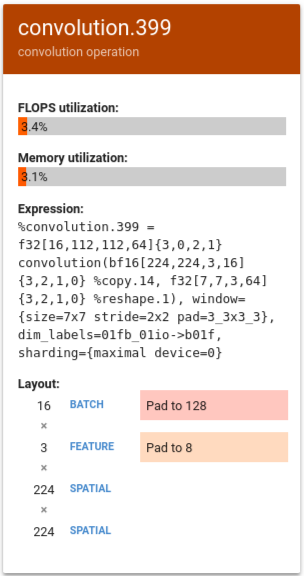
この例では、バッチサイズは 128 にパディングされ、特徴サイズは 8 にパディングされています。この場合は、マトリックス ユニットの 5% のみが有効に使用されています。使用率は、(((batch_time * num_of_features) / padding_size ) / num_of_cores) で計算されます。この例の FLOPS をパディングを使用しない前の例の %convolution.340 と比較します。
トレース ビューア
トレース ビューアは、[プロファイル] ページで利用可能な Cloud TPU パフォーマンス分析ツールです。このツールは、Chrome トレース イベント プロファイリング ビューアを使用するため、Chrome ブラウザでのみ機能します。
トレース ビューアには次のタイムラインが表示されます。
- TensorFlow モデルによって実行された演算の実行期間。
- 演算を実行したシステムの部分(TPU またはホストマシン)。通常、ホストマシンがトレーニング データを前処理して TPU に転送する infeed 演算を実行し、TPU は実際のモデル トレーニングを行います。
トレース ビューアを使用すると、モデル内のパフォーマンスの問題を特定し、問題を解決する対策を講じることができます。たとえば、大まかには、インフィードとモデル トレーニングのどちらに大部分の時間を費やしているかどうかを識別できます。さらに詳しく見ると、実行に最も時間がかかっている TensorFlow 演算も識別できます。
トレース ビューアは、Cloud TPU ごとに 100 万件のイベントに制限されています。他のイベントを評価する必要がある場合は、代わりにストリーミング トレース ビューアを使用してください。
トレース ビューアのインターフェース
トレース ビューアを開くには、TensorBoard に移動して画面上部の [プロファイル] タブをクリックし、[ツール] プルダウンから [trace_viewer] を選択します。ビューアが開き、最新の実行結果が表示されます。
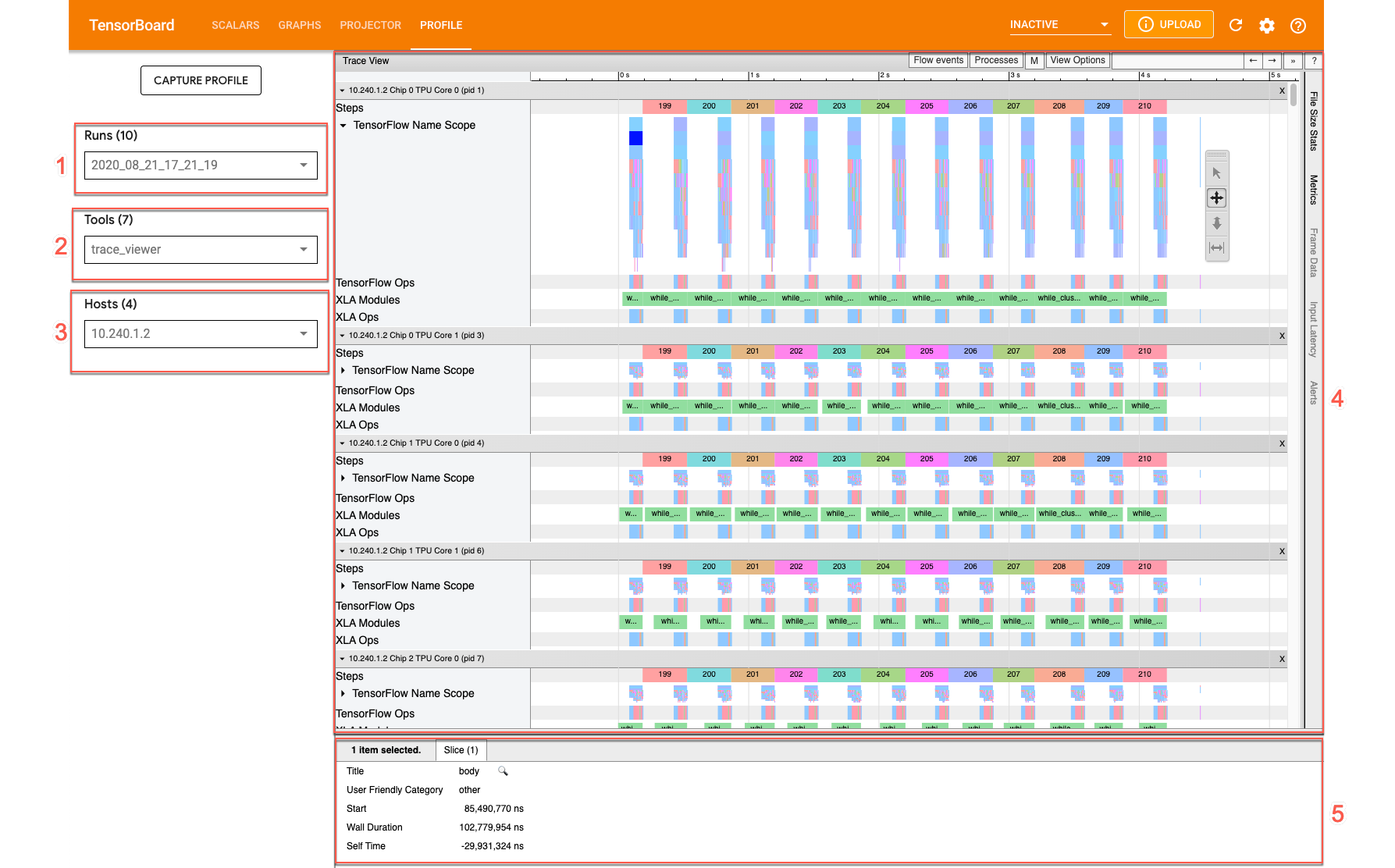
この画面には、次の主要な要素(前のスクリーンショットで番号が付けられています)が表示されます。
- 実行プルダウン: トレース情報をキャプチャしたすべての実行が表示されます。デフォルトのビューは最新の実行ですが、プルダウンを開いて別の実行を選択することもできます。
- ツール プルダウン: さまざまなプロファイリング ツールを選択します。
- ホスト プルダウン: Cloud TPU セットを含むホストを選択します。
- [Timeline] ペイン: Cloud TPU とホストマシンで実行された演算が時系列で表示されます。
- 詳細ウィンドウペイン: [Timeline] ペインで選択した演算の詳細情報が表示されます。
では、[Timeline] ペインについて詳しく見てみましょう。
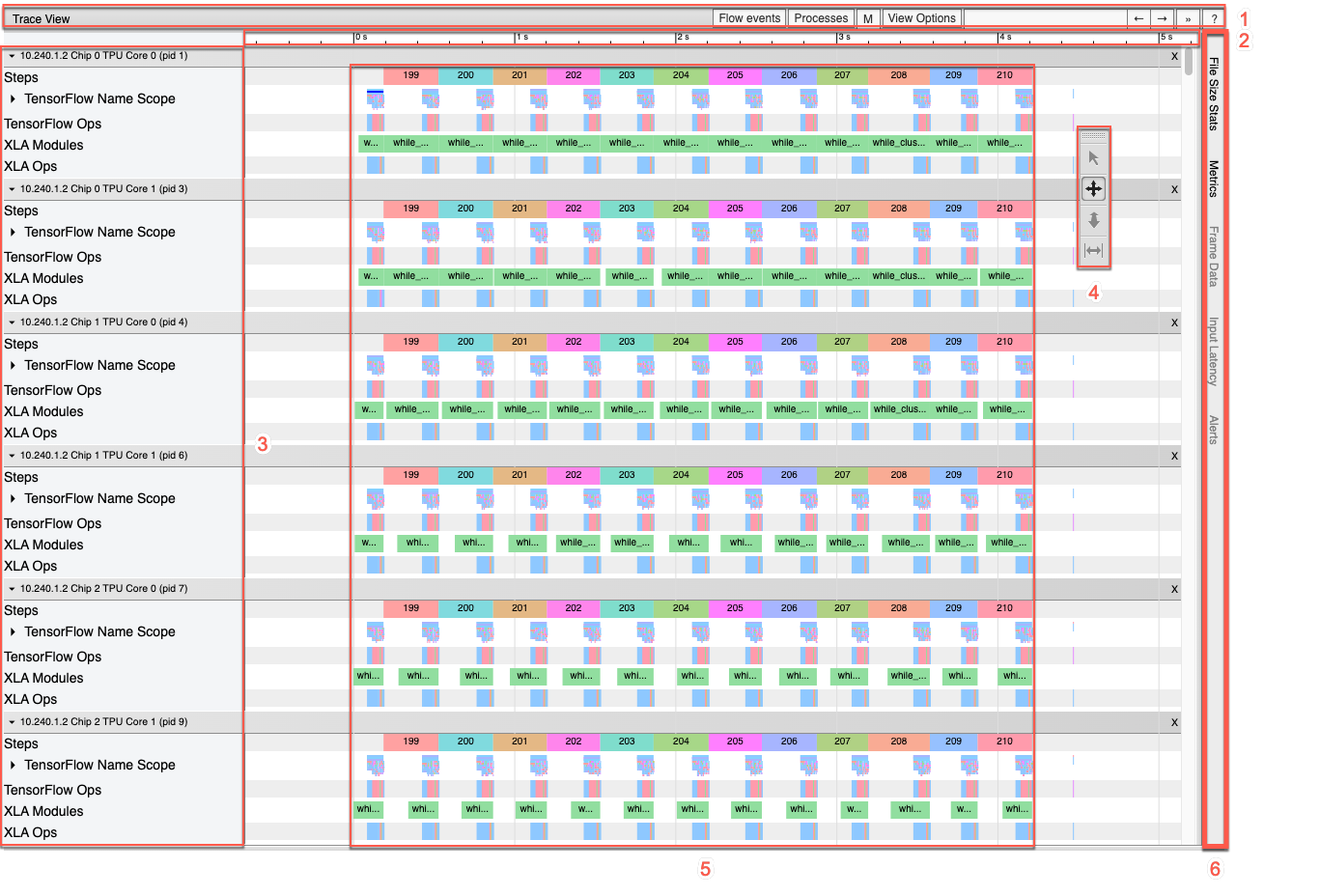
[Timeline] ペインには、次の要素が含まれます。
- 上部バー: さまざまな補助コントロールが表示されます。
- 時間軸 トレースの開始を基準にして時間を表示します。
- セクションとトラックのラベル: 各セクションには複数のトラックが含まれています。左側にある三角形をクリックすると、セクションの展開や折りたたみを行うことができます。システムで処理中の要素ごとに 1 つのセクションがあります。
- ツールセレクタ: トレース ビューアを操作するためのさまざまなツールが用意されています。
- イベント: 演算が実行されていた時間やトレーニング ステップなどのメタイベントの期間を示します。
- 垂直タブバー: Cloud TPU での使用は適しません。このバーは、Chrome が提供する汎用のトレース ビューアツールの一部で、さまざまなパフォーマンス分析タスクに使用されます。
セクションとトラック
トレース ビューアには、次のセクションがあります。
- TPU ノードごとに 1 つのセクション。ラベルとして TPU チップの数とチップ内の TPU コアの数が使用されます(例: 「Chip 2: TPU Core 1」)。TPU ノードのセクションには、次のトラックが含まれます。
- ステップ: TPU で実行されていたトレーニング ステップの期間が表示されます。
- TensorFlow Ops:: TPU 上で実行される TensorFlow 演算。
- XLA 演算: TPU 上で実行された XLA 演算が表示されます。1 つの演算が 1 つ以上の XLA 演算に変換されます。XLA コンパイラにより、XLA 演算が TPU 上で実行されるコードに変換されます。
- ホストの CPU 上で実行されるスレッドのセクション。「Host Threads」というラベルが付いています。このセクションには、CPU スレッドごとに 1 つのトラックが含まれます。注: セクション ラベルと一緒に表示される情報は無視してもかまいません。
タイムラインのツールセレクタ
TensorBoard のタイムライン ツールセレクタを使用して、タイムライン ビューを操作できます。タイムライン ツールをクリックしてツールを有効にしてハイライト表示します。タイムライン ツールセレクタを移動するには、上部の点線部分をクリックしてセレクタを目的の場所にドラッグします。
タイムライン ツールの使い方は次のとおりです。
|
選択ツール イベントをクリックして選択します。または、複数のイベントを選択するにはドラッグします。選択したイベントに関する詳細情報(名前、開始時間、期間)が、詳細ペインに表示されます。 |
|
パンツール ドラッグしてタイムライン ビューを水平方向または垂直方向にパンします。 |
|
ズームツール 水平方向(時間軸)に沿って上にドラッグするとズームインし、下にドラッグするとズームアウトします。マウスカーソルの水平位置により、ズームが行われる中心が決まります。 注: マウスボタンを放してもズームツールがアクティブなままの場合は、タイムライン ビューをクリックしてズームツールを無効にします。 |
|
タイミング ツール 水平方向にドラッグして、時間間隔をマークできます。間隔の長さは時間軸に表示されます。間隔を調整するには、間隔の両端をドラッグします。間隔をクリアするには、タイムライン ビュー内の任意の場所をクリックします。 別のツールを選択しても、間隔はマークされたままになります。 |




メモリビューア
メモリビューアでは、プログラムのピーク時のメモリ使用量とメモリ使用の傾向を視覚化できます。
メモリビューアのユーザー インターフェースは次のようになります。
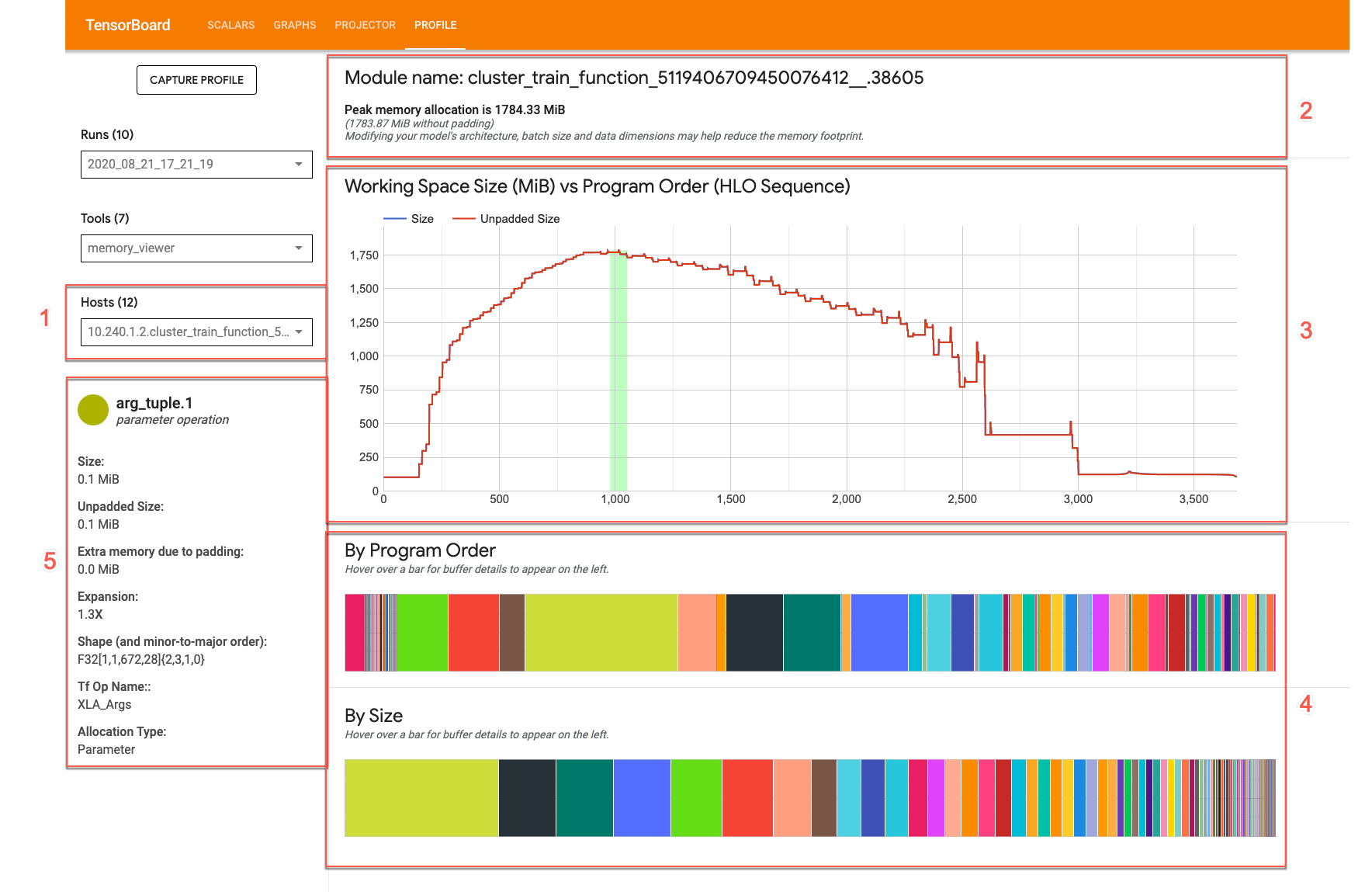
- [ホスト] プルダウン: 表示する TPU ホストと XLA High Level Optimizer(HLO)モジュールを選択します。
- メモリの概要: ピーク時のメモリ割り当てとパディングなしのサイズが表示されます。
- 作業スペースのグラフ: ピーク時のメモリ使用量と、プログラムのメモリ使用の傾向が表示されます。いずれかのバッファグラフでバッファにカーソルを合わせると、バッファ割り当てカードに詳細が表示されます。
- バッファグラフ: ピーク時のメモリ使用量でのバッファ割り当てを示す 2 つのグラフ。いずれかのバッファグラフでバッファにカーソルを合わせると、バッファの詳細カードに追加情報が表示されます。
- バッファ割り当て詳細カード バッファの割り当ての詳細が表示されます。
メモリ概要パネル
メモリの概要パネルには、合計バッファ割り当てサイズが最大に達したときのモジュール名とピークメモリ割り当てが表示されます。比較のため、パディングされていないピーク割り当てサイズも表示されます。

作業スペースグラフ
このグラフには、ピーク時のメモリ使用量とプログラムのメモリ使用の傾向が表示されます。縦線は、プログラムのピーク時のメモリ使用率を表します。このグラフは、プログラムが使用可能なグローバル メモリ空間に収まるかどうかを示しています。
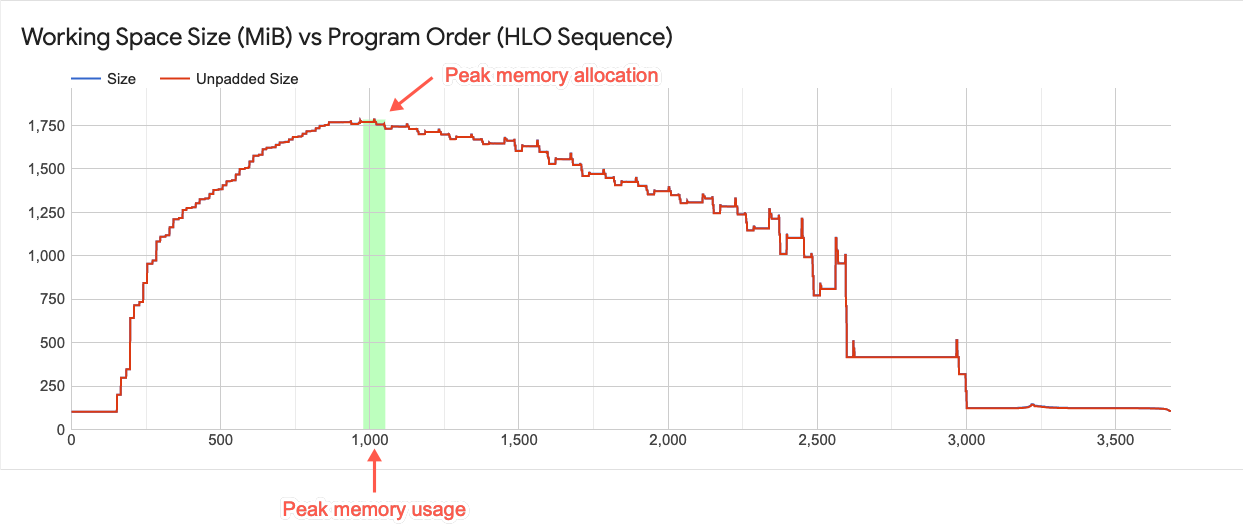
グラフの各ポイントは、XLA HLO プログラムの「プログラム ポイント」を表します。線は、プログラムのメモリ使用量が時間の経過とともにどのように変化するかを示しています。
バッファグラフ要素の操作
バッファグラフでバッファにカーソルを合わせると、作業スペースグラフにバッファの存続期間を示す水平線が表示されます。
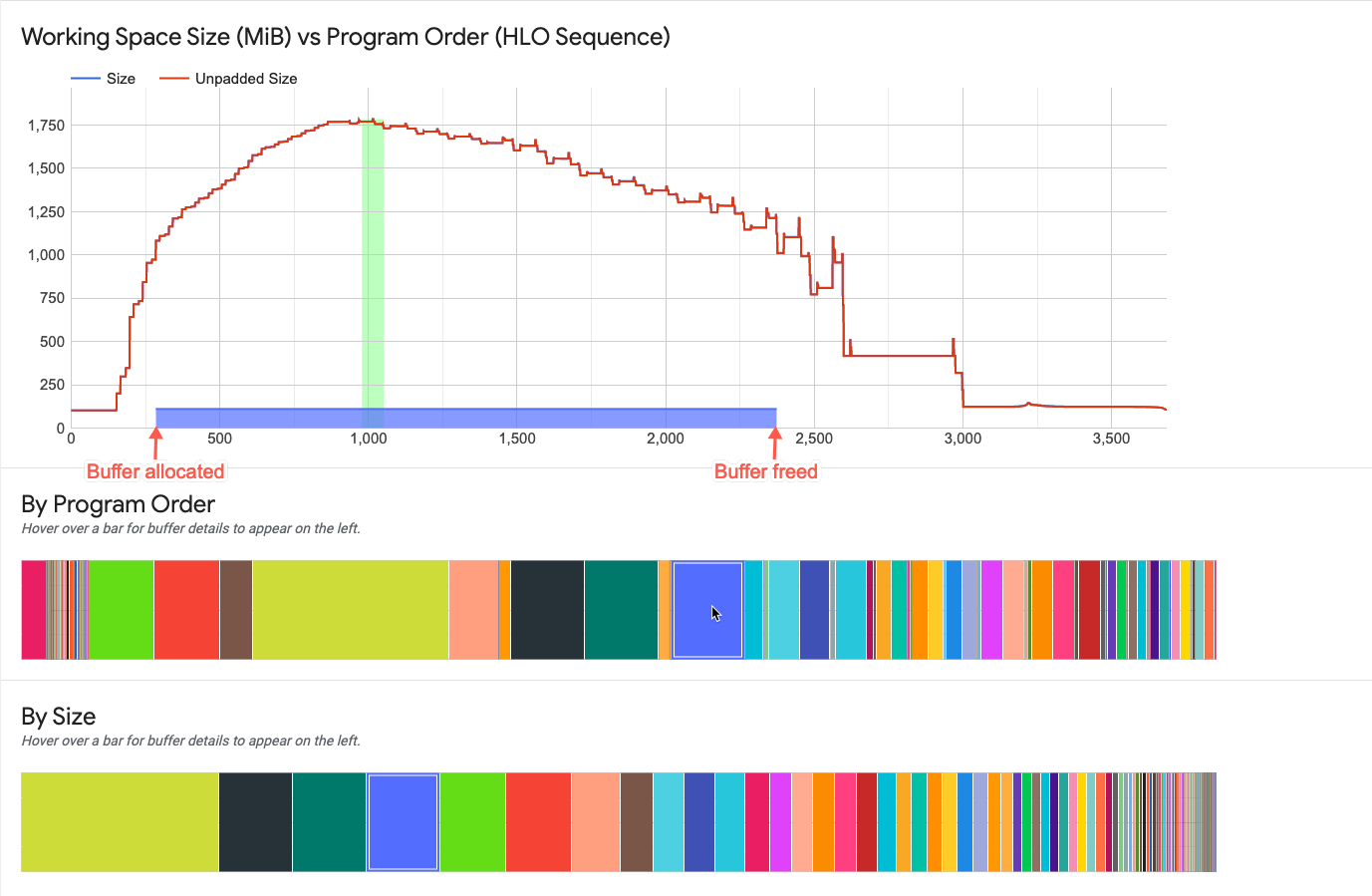
水平線の太さは、ピーク時のメモリ割り当てに対するバッファサイズの相対的な大きさを示します。線の長さはバッファの存続期間を示します。
バッファグラフ
2 つのグラフで、ピーク時のメモリ使用量の内訳が表示されます。
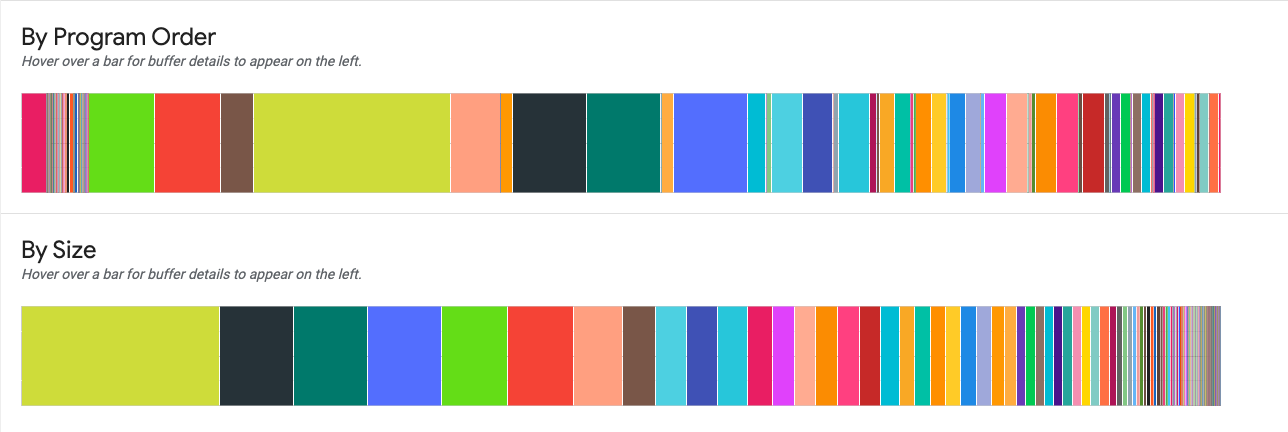
プログラム順序 プログラムの実行中にアクティブだったバッファが左から右へ順に表示されます。
サイズ別: プログラム実行中にアクティブだったバッファがサイズの降順で表示されます。
バッファ割り当て詳細カード
バッファグラフのいずれかに表示されているバッファにカーソルを合わせると、バッファ割り当ての詳細カードが表示されます。通常、次のような詳細カードが表示されます。
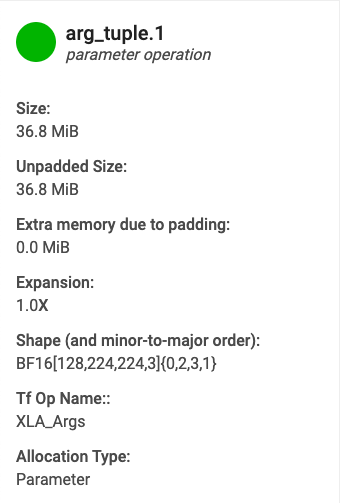
- 名前 - XLA オペレーションの名前。
- カテゴリ - オペレーションのカテゴリ。
- サイズ - バッファ割り当てのサイズ(パディングを含む)。
- パディングなしのサイズ - パディングなしのバッファ割り当てサイズ。
- 拡張 - パディングありとパディングなしのバッファサイズを比較した場合の違い。
- 追加メモリ - パディングのために余分に使用されるメモリ量を示します。
- シェイプ - N 次元配列のランク、サイズ、データ型。
- TensorFlow 演算名 - バッファ割り当てに関連した TensorFlow 演算の名前が表示されます。
- 割り当てタイプ: バッファ割り当てカテゴリ(パラメータ、出力、スレッド ローカル、一時(fusion 内のバッファ割り当てなど))を示します。
メモリ不足エラー
モデルの実行中にメモリ不足エラーが発生した場合は、このドキュメントのガイドラインを使用してプロファイルを取得します。スクリプトがモデルをトレーニングするまで待ってから、プロファイラを開始します。プロファイリングの出力は、エラーの原因を特定するのに役立ちます。