Diese Seite enthält Informationen, die Sie kennen sollten, bevor Sie eine Instanz aus einer Sicherung wiederherstellen oder eine Wiederherstellung zu einem bestimmten Zeitpunkt (Point-In-Time Recovery, PITR) ausführen.
Was geschieht während der Wiederherstellung?
Bei Cloud SQL Enterprise und Cloud SQL Enterprise Plus können Sie eine Instanz aus einer Sicherung wiederherstellen. Sie können Sicherungen auch über Instanzen verschiedener Versionen hinweg wiederherstellen.
Wenn Sie eine Instanz wiederherstellen, werden die folgenden Daten aus der primären Instanz in der neuen Instanz wiederhergestellt:
- Datenbanken
- Nutzer
Durch den Wiederherstellungsvorgang wird die Instanz neu gestartet.
Wiederherstellung zu einem bestimmten Zeitpunkt
Mit der Wiederherstellung zu einem bestimmten Zeitpunkt (PITR) können Sie eine Instanz auf einem bestimmten Stand wiederherstellen. Wenn beispielsweise ein Fehler zu einem Datenverlust geführt hat, haben Sie die Möglichkeit, genau den Zustand der Datenbank wiederherzustellen, den sie zum Zeitpunkt vor Auftreten des Fehlers hatte.
Bei der PITR wird immer eine neue Instanz erstellt. Diese Art der Wiederherstellung kann nicht für eine vorhandene Instanz durchgeführt werden. Die neue Instanz übernimmt die Einstellungen der Quellinstanz, ähnlich wie beim Klonen von Instanzen.
Wenn Sie eine Cloud SQL-Instanz in der Google Cloud -Konsole erstellen, ist PITR standardmäßig aktiviert.Bei der PITR wird das binäre Logging zum Archivieren von Logs verwendet. Standardmäßig ist die Wiederherstellung zu einem bestimmten Zeitpunkt für Cloud SQL Enterprise Plus-Instanzen aktiviert.
Wenn Sie eine Sicherung auf einer Cloud SQL-Instanz wiederherstellen, bevor Sie die Point-in-Time-Wiederherstellung aktivieren, verlieren Sie die archivierten Logs, die die Verwendung der Point-in-Time-Wiederherstellung ermöglichen. Wenn die Größe Ihrer Binär-Logs auf dem Laufwerk Leistungsprobleme für Ihre Instanz verursacht, deaktivieren Sie die Wiederherstellung zu einem bestimmten Zeitpunkt und aktivieren Sie sie noch einmal. Dadurch wird sichergestellt, dass neue Logs in Cloud Storage statt auf dem Laufwerk gespeichert werden.Eine detaillierte Anleitung zur Durchführung einer PITR finden Sie unter Wiederherstellung zu einem bestimmten Zeitpunkt verwenden.
Nicht verfügbare Instanz wiederherstellen
Mit der Wiederherstellung zu einem bestimmten Zeitpunkt können Sie eine Cloud SQL-Instanz wiederherstellen, die nicht verfügbar ist. Die Wiederherstellung zu einem bestimmten Zeitpunkt bietet in der Regel ein Recovery Point Objective (RPO) von fünf Minuten oder weniger.
Wenn die Instanz nicht verfügbar ist, können Sie mit der API den frühesten und neuesten Wiederherstellungszeitpunkt abrufen, gemäß dem Sie die Instanz wiederherstellen können, und die Wiederherstellung bis zu diesem Zeitpunkt durchführen. Wenn auf die Zone, in der die Instanz konfiguriert ist, nicht zugegriffen werden kann, können Sie die Instanz in einer anderen primären oder sekundären Zone wiederherstellen. Dazu geben Sie Werte für die bevorzugten Zonen an.
Angenommen, eine Cloud SQL-Instanz ist ab 16:00 Uhr EST nicht mehr verfügbar. Wenn der letzte Wiederherstellungszeitpunkt um 15:55 Uhr EST (UTC-5) ist, können Sie die Instanz gemäß diesem Zeitpunkt wiederherstellen.
Gelöschte Instanz mithilfe der Wiederherstellung zu einem bestimmten Zeitpunkt wiederherstellen
Mit der Wiederherstellung zu einem bestimmten Zeitpunkt können Sie eine Cloud SQL-Instanz nach dem Löschen wiederherstellen. Damit Sie diese Funktion nutzen können, müssen für Ihre Instanz PITR und beibehaltene Backups aktiviert sein, bevor die Instanz gelöscht wird. Wenn diese Option aktiviert ist, werden PITR-Logs beibehalten, nachdem Sie die Instanz gelöscht haben.
Nachdem eine Instanz gelöscht wurde, richten sich die PITR-Logs weiterhin nach den Aufbewahrungseinstellungen, die für die Instanz festgelegt wurden, als sie aktiv war. Die PITR-Logs laufen nach dem Löschen der Instanz basierend auf den Aufbewahrungseinstellungen fortlaufend ab. Der rollierende Zeitraum wird basierend auf dem PITR-Aufbewahrungszeitraum definiert, der für die Instanz vor dem Löschen festgelegt wurde. Wenn für Ihre Cloud SQL Enterprise Plus-Instanz beispielsweise eine PITR-Aufbewahrungsdauer von 14 Tagen festgelegt ist, wird das letzte PITR-Log 14 Tage nach dem Löschen der Instanz gelöscht. Wenn ein PITR-Log abläuft, kann es nicht wiederhergestellt werden.
Da Instanznamen nach dem Löschen einer Instanz in Cloud SQL wiederverwendet werden können, können beibehaltene PITR-Logs in Google Cloud anhand der folgenden Felder identifiziert werden:
instance_deletion_timelog_retention_days
Mithilfe dieser Felder können Sie feststellen, ob ein PITR-Log zu einer gelöschten Instanz gehört.
Das PITR-Wiederherstellungszeitfenster wird als frühester und letzter Wiederherstellungszeitpunkt definiert, der für die Wiederherstellung Ihrer Instanz mit PITR verfügbar ist. Informationen zum Ermitteln der frühesten und spätesten Wiederherstellungszeiten für Ihre gelöschte Instanz finden Sie unter Früheste und späteste Wiederherstellungszeit abrufen.
Informationen zum Wiederherstellen einer Instanz mit PITR nach dem Löschen der Instanz finden Sie unter PITR für eine gelöschte Instanz ausführen.
Allgemeine Tipps zur Wiederherstellung
Wenn Sie eine Instanz aus einer Sicherung wiederherstellen, sei es in derselben Instanz oder in einer anderen Instanz, sollten Sie Folgendes beachten:
- Mit der Wiederherstellung werden alle Daten in der Zielinstanz überschrieben.
- Während der Wiederherstellung ist die Zielinstanz nicht für Verbindungen verfügbar. Bestehende Verbindungen werden getrennt.
- Wenn Sie eine Instanz wiederherstellen, die Lesereplikate hat, müssen Sie alle Replikate löschen und nach Abschluss der Wiederherstellung neu erstellen.
- Durch den Wiederherstellungsvorgang wird die Instanz neu gestartet.
Eine detaillierte Anleitung, wie Sie eine Wiederherstellung ausführen, finden Sie unter:
Tipps und Anforderungen zur Wiederherstellung in einer anderen Instanz
Beachten Sie zum Wiederherstellen einer Sicherung auf einer anderen Instanz die folgenden Einschränkungen und Best Practices:
Die Zielinstanz muss eine Datenbank der gleichen Version haben wie die Instanz, von der die Sicherung erstellt wurde.
Wenn Sie die Datenbankversion für Ihre Instanz aktualisieren möchten, führen Sie die unter Direkte Datenbankaktualisierung durchführen beschriebenen Schritte aus.
Cloud SQL setzt die Speicherkapazität der Zielinstanz immer auf den Höchstwert der Größe des konfigurierten Laufwerks und des Sicherungslaufwerks. Das Sicherungslaufwerk ist die Größe des Laufwerks zum Zeitpunkt der Sicherung.
Die Speicherkapazität der Zielinstanz muss mindestens so groß sein wie die Kapazität der Instanz, die gesichert wird. Der tatsächlich genutzte Speicher spielt dabei keine Rolle. Die Speicherkapazität der Instanz können Sie in der Console auf der Seite Cloud SQL-Instanzen einsehen.
Die Zielinstanz muss den Status
RUNNABLEhaben.Die Zielinstanz und die gesicherte Instanz können sich in der Anzahl der Kerne oder dem verfügbaren Speicherplatz unterscheiden.
Die Zielinstanz kann sich in einer anderen Region als die Quellinstanz befinden.
Während eines Ausfalls können Sie weiterhin eine Liste der Sicherungen in einem bestimmten Projekt abrufen. Weitere Informationen finden Sie unter Sicherungen während eines Ausfalls ansehen.
Einschränkungen der Wiederherstellungsrate
Es sind maximal drei Wiederherstellungsvorgänge alle 30 Minuten pro Instanz, Region und Projekt möglich. Wenn ein Wiederherstellungsvorgang fehlschlägt, wird es nicht auf dieses Kontingent angerechnet. Wenn Sie das Limit erreichen, schlägt der Vorgang mit einer Fehlermeldung fehl, die Sie darüber informiert, wann Sie den Vorgang noch einmal ausführen können.
Sehen wir uns nun an, wie Cloud SQL die Ratenbegrenzung für Wiederherstellungen ausführt.
Cloud SQL verwendet Tokens aus einem Bucket, um zu ermitteln, wie viele Wiederherstellungsvorgänge gleichzeitig verfügbar sind. Für jede Sicherung gibt es für jedes Zielprojekt und jede Zielregion eine Bucket. Die Zielinstanzen aus demselben Projekt teilen einen Bucket, wenn sie sich in derselben Region befinden. Jeder Bucket kann maximal drei Tokens enthalten, die Sie für Wiederherstellungsvorgänge verwenden können. Alle 10 Minuten wird dem Bucket ein neues Token hinzugefügt. Wenn der Bucket voll ist, läuft das Token über.
Jedes Mal, wenn Sie einen Wiederherstellungsvorgang ausführen, wird ein Token aus dem Bucket gewährt. Wenn der Vorgang erfolgreich ist, wird das Token aus dem Bucket entfernt. Wenn der Vorgang fehlschlägt, wird das Token an den Bucket zurückgegeben. Dies wird im folgenden Diagramm veranschaulicht:

In der folgenden Abbildung sind beispielsweise Backup1, Backup2 und Backup3 die Sicherungen derselben Quellinstanz.
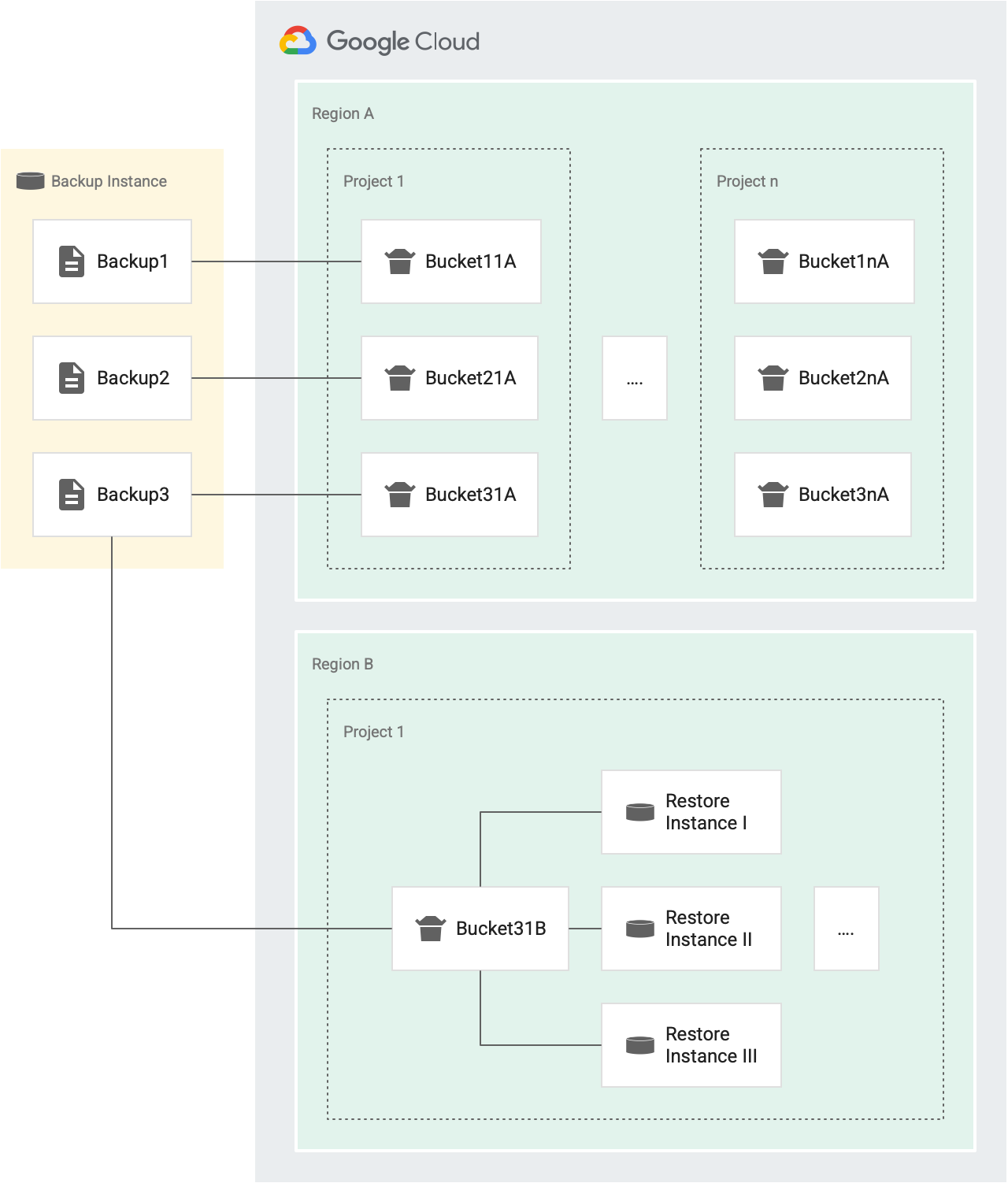
- Jede Sicherung (Backup1, Backup2 und Backup3) hat einen eigenen Bucket mit Tokens für Wiederherstellungsvorgänge, die auf verschiedene Instanzen in Projekt 1 in Region A (Bucket11A, Bucket21A und Bucket31A) ausgerichtet sind. Da jede Sicherung einen eigenen Bucket hat, können Sie jede Sicherung dreimal alle 30 Minuten wiederherstellen.
- Jede Sicherung hat einen Bucket für ein separates Projekt und für eine separate Region.
Wenn es beispielsweise fünf Projekte in einer Region gibt, gibt es fünf Buckets für diese Sicherung in dieser Region, einer in jedem Projekt. In der vorherigen Abbildung haben wir zwei Projekte in Region A: Projekt 1 und Projekt n.
- Backup1 hat zwei Buckets mit Tokens für Wiederherstellungsvorgänge in Region A. Einen Bucket für Projekt 1 (Bucket11A) und einen Bucket für Projekt n (Bucket1nA).
- In ähnlicher Weise hat Backup3 zwei Buckets für Wiederherstellungsvorgänge in Region A. Eine für Projekt 1 (Bucket31A) und eine für Projekt n (Bucket3nA).
- Backup3 hat einen Bucket in Region B für Projekt1, da alle Instanzen im selben Zielprojekt und in derselben Zielregion einen Bucket gemeinsam nutzen.
Nächste Schritte
- Daten aus einer Sicherung wiederherstellen
- Wiederherstellung zu einem bestimmten Zeitpunkt (PITR) verwenden