Dengan menggunakan API, tanpa kode apa pun, Anda dapat membuat dan melatih model Speech-to-Text Kustom untuk meningkatkan akurasi pengenalan dari model Speech-to-Text yang ada. Layanan terkelola sepenuhnya ini akan otomatis menyediakan resource komputasi, mengeksekusi kode aplikasi pelatihan, dan memastikan penghapusan resource komputasi setelah tugas pelatihan. Anda akan mendapatkan model transkripsi yang sepenuhnya di-fine-tune dan berguna untuk aplikasi downstream apa pun.
Mirip dengan model machine learning, pelatihan model Speech-to-Text Kustom biasanya bersifat iteratif dan melibatkan pemilihan model dasar sebagai titik awal, penyesuaiannya dengan set data teks dan audio Anda, lalu pengujian kualitas pengenalan model. Jika hasilnya tidak sesuai dengan yang Anda harapkan, Anda dapat melatih ulang model baru dengan campuran data yang berbeda, menguji lagi, atau menggunakannya secara langsung untuk transkripsi di domain Anda.
Sebelum memulai
Pastikan Anda telah mendaftar untuk mendapatkan akun Google Cloud , membuat project Google Cloud , dan mengaktifkan Speech-to-Text API: Buka Speech di konsol Google Cloud , lalu buka Speech-to-Text API. Lakukan operasi di bagian Model Kustom pada menu navigasi di sebelah kiri.
Buat model kustom
Mulai dengan membuat model Speech-to-Text kustom dan menentukan parameternya, seperti model dasar dan bahasa transkripsi:
- Klik Buat untuk membuat model kustom.
- Masukkan Nama model, yang akan digunakan untuk tampilan dan dirujuk dalam permintaan API dan Konsol Speech Anda. Google Cloud
- Masukkan Deskripsi untuk model.
- Pilih Model dasar yang paling sesuai untuk kasus penggunaan Anda.
- Pilih Bahasa transkripsi model.
- Pilih Region tempat pelatihan akan dilakukan.
- Klik Lanjutkan.
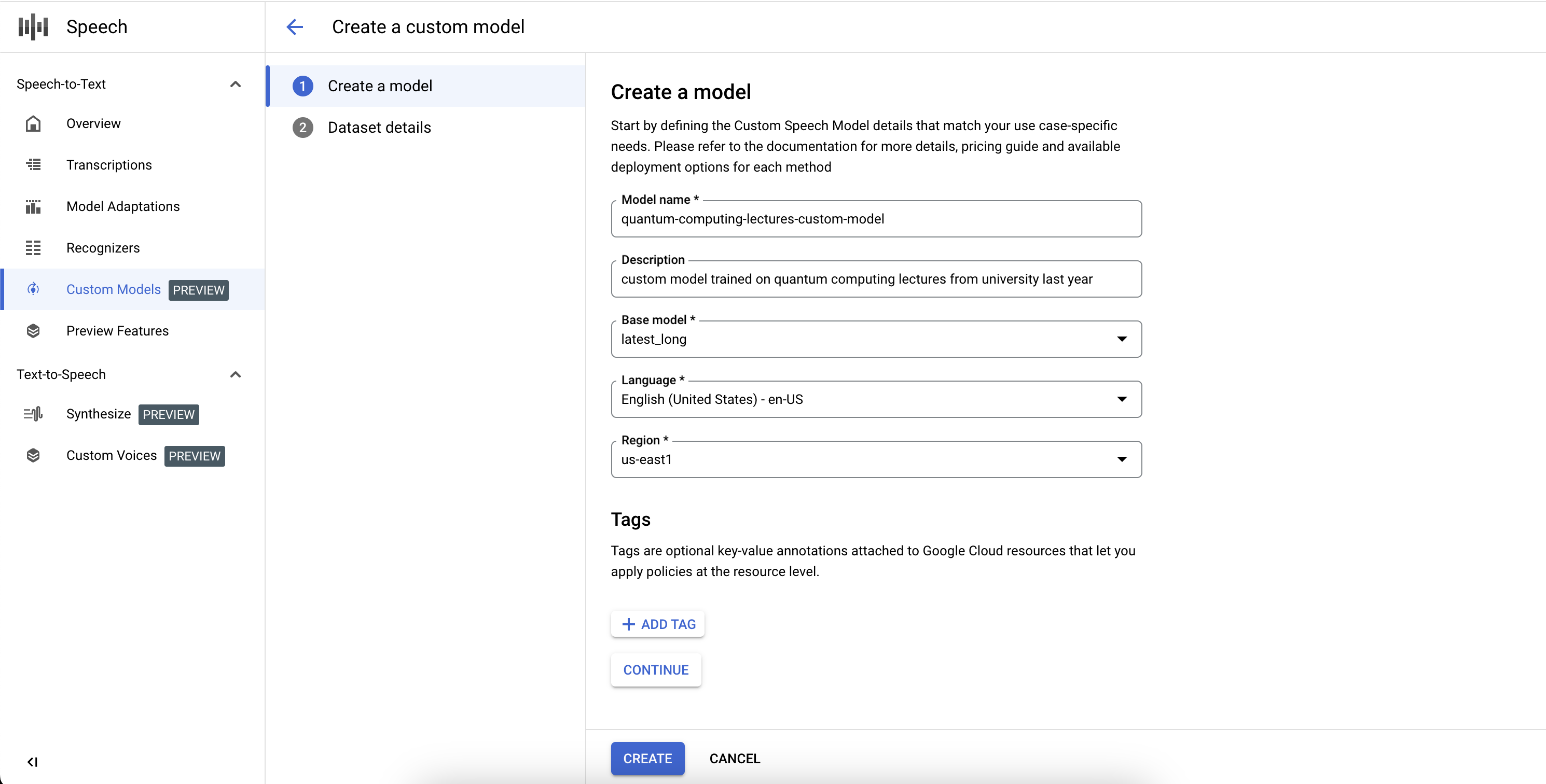
Untuk menyelesaikan definisi tugas model Speech-to-Text Kustom dan memulai pelatihan, Anda harus menentukan set data pelatihan dan validasi.
- Pilih set data pelatihan, dengan memberikan URI direktori Cloud Storage yang valid. Pastikan hanya file audio dan teks yang ada dan total durasi audio mengikuti persyaratan set data pelatihan.
- Pilih set data validasi, dengan memberikan URI direktori Cloud Storage yang valid. Pastikan hanya ada file audio dan teks, serta total durasi audio mengikuti persyaratan set data validasi.
- Klik Create untuk memulai proses pelatihan.
Jika jam audio yang diindeks tidak cukup atau file tidak mengikuti pedoman, tugas pelatihan akan gagal.
Tugas pelatihan dapat diantrekan di belakang tugas lain dalam sistem kami, dan pelatihan model dapat memerlukan waktu mulai dari beberapa jam hingga beberapa hari, bergantung pada ukuran set data. Setelah pelatihan model, statusnya akan ditandai sebagai Aktif.
Menghapus model kustom
Sebelum memulai, pastikan tidak ada traffic yang dirutekan ke model Custom Speech-to-Text Anda melalui endpoint mana pun, karena jika dihapus, model tersebut tidak akan lagi menayangkan permintaan apa pun.
- Buka tab Models di bagian Custom Models.
- Klik untuk meluaskan opsi, lalu klik Hapus. Dalam beberapa saat, model Speech-to-Text Kustom akan dihapus, beserta semua endpoint-nya, dan tidak akan lagi menyalurkan traffic.
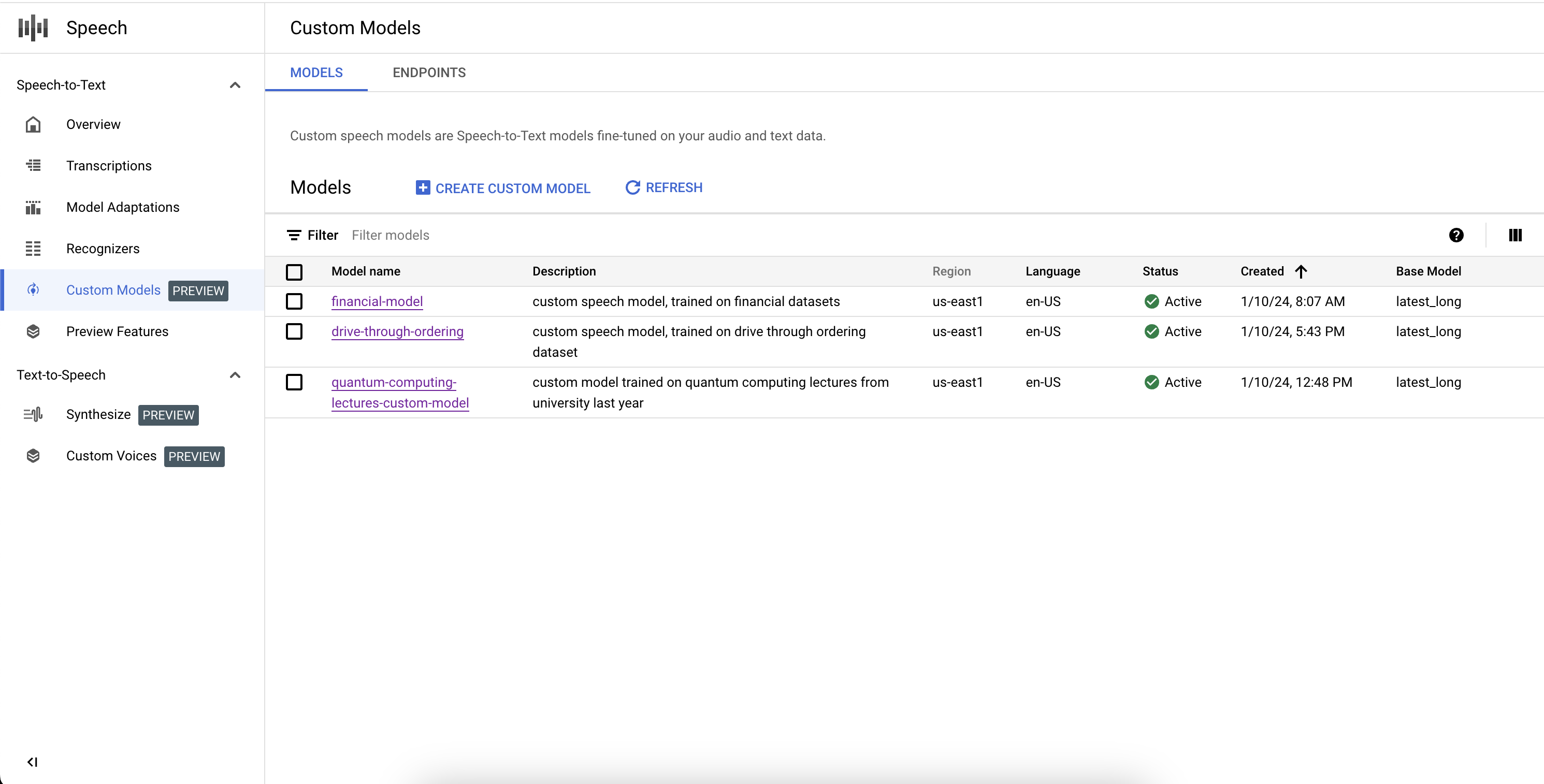
Mencantumkan model kustom Anda
Dengan memilih Model di bagian Model Kustom, Anda juga dapat mencantumkan semua model Speech-to-Text Kustom, termasuk model yang sedang dilatih, aktif, dan dihapus.
Langkah berikutnya
Ikuti referensi untuk memanfaatkan model ucapan kustom dalam aplikasi Anda: