Sie können die API ohne Code verwenden und ein benutzerdefiniertes Speech-to-Text-Modell erstellen und trainieren, um die Erkennungsgenauigkeit eines vorhandenen Speech-to-Text-Modells zu verbessern. Dieser vollständig verwaltete Dienst stellt automatisch Rechenressourcen bereit, führt den Trainingsanwendungscode aus und sorgt für das Löschen von Rechenressourcen nach dem Trainingsjob. Sie erhalten ein vollständig optimiertes Transkriptionsmodell, das für nachgelagerte Anwendungen nützlich ist.
Ähnlich wie bei Machine-Learning-Modellen ist das Training eines benutzerdefinierten Speech-to-Text-Modells in der Regel ein iterativer Prozess. Dabei wird ein Basismodell als Ausgangspunkt ausgewählt, mit Ihren Text- und Audio-Datasets optimiert und dann die Erkennungsqualität des Modells getestet. Wenn die Ergebnisse nicht Ihren Erwartungen entsprechen, trainieren Sie ein neues Modell mit einer anderen Datenmischung, testen es noch einmal oder verwenden es direkt zur Transkription in Ihrer Domain.
Hinweise
Prüfen Sie, ob Sie sich für ein Google Cloud Konto registriert, ein Google Cloud Projekt erstellt und die Speech-to-Text API aktiviert haben: Rufen Sie in der Google Cloud Console Speech auf und rufen Sie die Speech-to-Text API auf. Arbeiten Sie im Bereich Benutzerdefinierte Modelle der Navigationsleiste auf der linken Seite.
Ein benutzerdefiniertes Modell erstellen
Erstellen Sie zuerst ein benutzerdefiniertes Speech-to-Text-Modell und definieren Sie dessen Parameter gemäß Basismodell und Transkriptionssprache:
- Klicken Sie auf Erstellen, um ein benutzerdefiniertes Modell zu erstellen.
- Geben Sie einen Modellnamen ein, der für die Anzeige verwendet und in Ihren API-Anfragen und der Google Cloud Speech Console referenziert wird.
- Geben Sie eine Beschreibung für das Modell ein.
- Wählen Sie ein Basismodell aus, das am besten für Ihren Anwendungsfall geeignet ist.
- Wählen Sie die Transkriptionssprache des Modells aus.
- Wählen Sie die Region aus, in der das Training stattfinden soll.
- Klicken Sie auf Weiter.
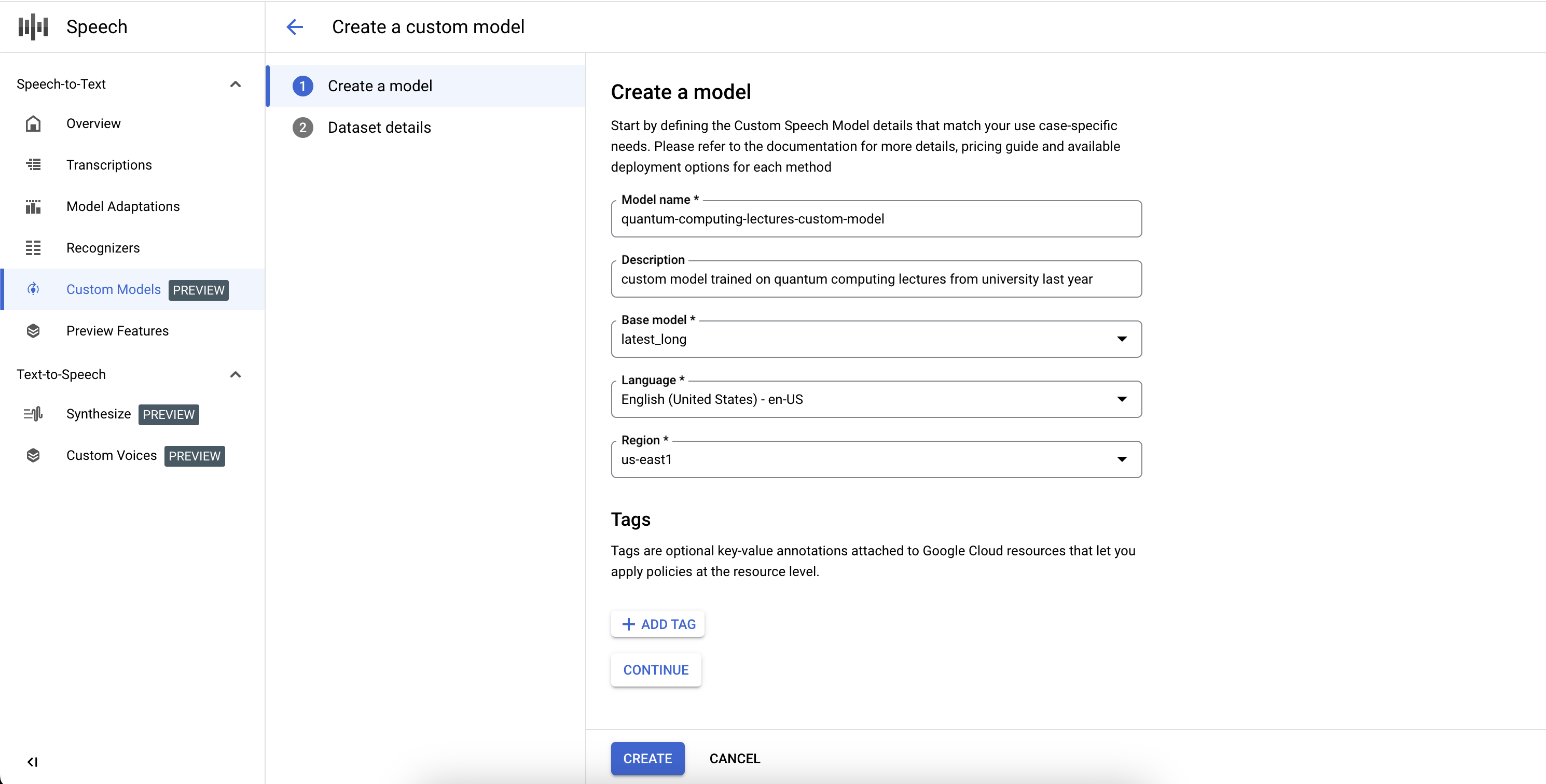
Um die Definition des benutzerdefinierten Speech-to-Text-Modelljobs abzuschließen und das Training zu starten, müssen Sie die Trainings- und Validierungs-Datasets definieren.
- Wählen Sie ein Trainings-Dataset aus, indem Sie einen gültigen Cloud Storage-Verzeichnis-URI angeben. Achten Sie darauf, dass nur Audio- und Textdateien vorhanden sind und dass die Gesamtdauer der Audiodaten den Anforderungen für Trainings-Datasets entspricht.
- Wählen Sie ein Validierungs-Dataset aus, indem Sie einen gültigen Cloud Storage-Verzeichnis-URI angeben. Achten Sie darauf, dass nur Audio- und Textdateien vorhanden sind und dass die Gesamtdauer der Audiodaten den Anforderungen für Validierungs-Datasets entspricht.
- Klicken Sie auf Erstellen, um den Trainingsprozess zu starten.
Wenn nicht genügend Audio-Stunden indexiert wurden oder die Dateien nicht den Richtlinien entsprechen, schlägt der Trainingsjob fehl.

Trainingsjobs können in unserem System hinter anderen Jobs in die Warteschlange eingereiht werden. Das Training eines Modells kann je nach Größe des Datasets einige Stunden bis einige Tage dauern. Nach dem Modelltraining wird der Status als Aktiv gekennzeichnet.
Benutzerdefiniertes Modell löschen
Bevor Sie beginnen, müssen Sie dafür sorgen, dass kein Traffic über einen Endpunkt an Ihr benutzerdefiniertes Speech-to-Text-Modell weitergeleitet wird, da es nach dem Löschen keine Anfragen mehr verarbeitet.
- Rufen Sie im Abschnitt Benutzerdefinierte Modelle den Tab Modelle auf.
- Klicken Sie, um die Optionen zu maximieren, und klicken Sie dann auf Löschen. Das benutzerdefinierte Speech-to-Text-Modell wird in wenigen Momenten zusammen mit allen zugehörigen Endpunkten gelöscht und stellt keinen Traffic mehr bereit.
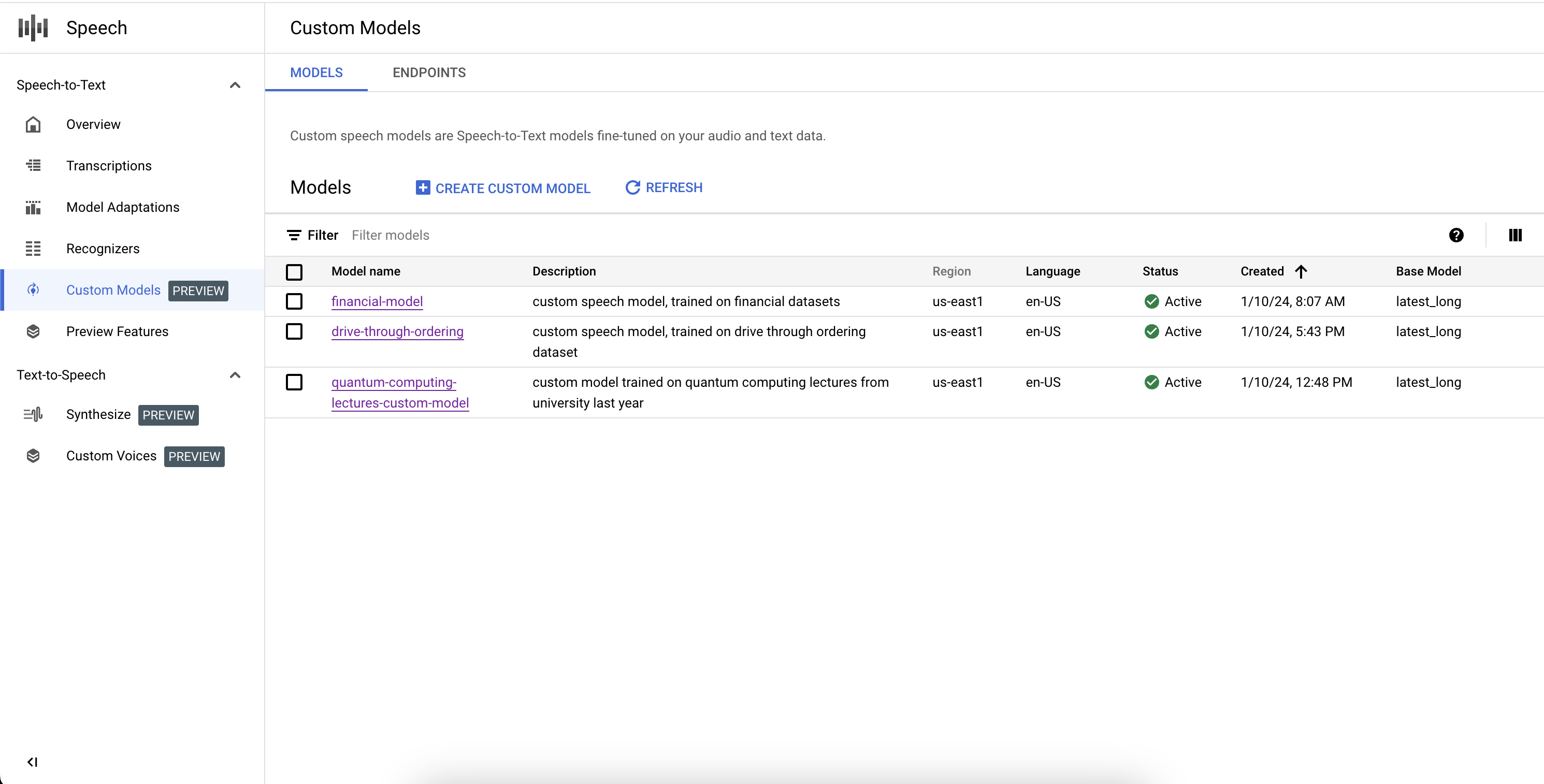
Benutzerdefinierte Modelle auflisten
Durch Auswahl der Modelle im Abschnitt Benutzerdefinierte Modelle können Sie auch alle Ihre benutzerdefinierten Speech-to-Text-Modelle auflisten, einschließlich der Modelle, die trainiert werden, aktiv sind oder gelöscht werden.
Nächste Schritte
Folgen Sie den Ressourcen, um benutzerdefinierte Sprachmodelle in Ihrer Anwendung zu nutzen:
- Modellendpunkte bereitstellen und verwalten.
- Benutzerdefinierte Modelle verwenden
- Benutzerdefinierte Modelle bewerten