Verwenden Sie ein trainiertes benutzerdefiniertes Speech-to-Text-Modell in Ihrer Produktionsanwendung oder in Benchmarking-Workflows. Sie müssen das Modell über einen dedizierten Endpunkt bereitstellen und verfügbar machen, der unter anderem dazu dient, das Modell in der von Ihnen ausgewählten Region bereitzustellen. Sie erhalten automatisch programmatischen Zugriff über ein Erkennungsobjekt. Es wird direkt über die V2 API oder in der Google Cloud Console verwendet. Sie können Ihr Modell in einer anderen Region als der bereitstellen, in der es trainiert wurde. Es wird jedoch eine Kopie des Modells in der vom Endpunkt angegebenen Region erstellt.
Wenn Sie ein benutzerdefiniertes Sprachmodell verwenden möchten, müssen Sie es über einen dedizierten Endpunkt bereitstellen und verfügbar machen. Wenn Sie einen Endpunkt erstellen, stellen Sie das Modell in der Region Ihrer Wahl bereit. Sie erhalten automatisch programmatischen Zugriff über ein Erkennungsobjekt, das Sie direkt über die V2 API für Inferenz oder in der Google Cloud Console verwenden können.
Hinweise
Sie müssen sich für ein Google Cloud -Konto registriert, ein Projekt erstellt und ein benutzerdefiniertes Sprachmodell trainiert haben.
- Rufen Sie in der Google Cloud Console Speech auf und navigieren Sie dann zu Speech-to-Text.
- Navigieren Sie über die Navigationsleiste auf der linken Seite zum Bereich Benutzerdefinierte Modelle.
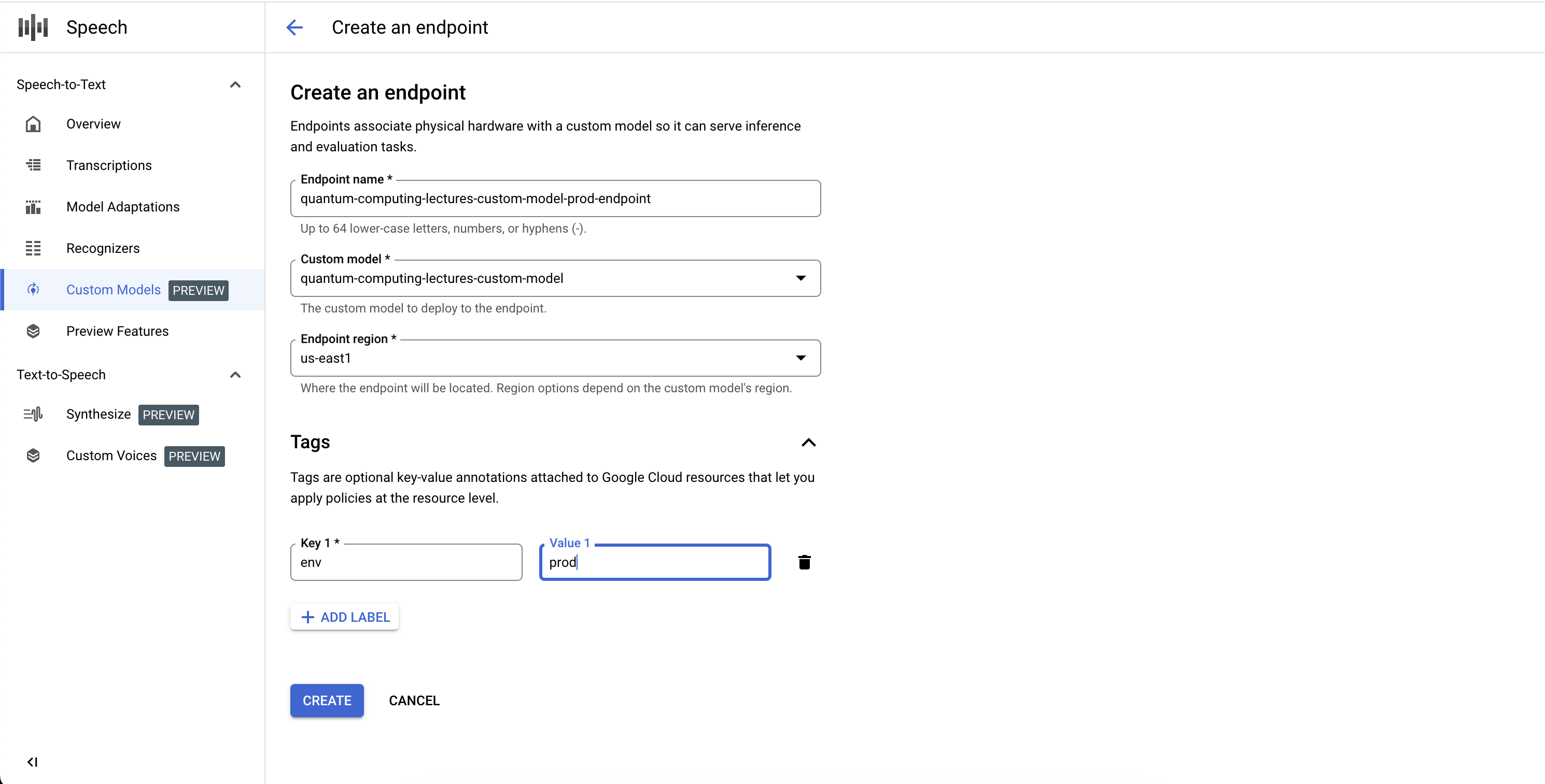
Endpunkt erstellen
- Rufen Sie im Abschnitt Benutzerdefinierte Modelle den Tab Endpunkte auf.
- Klicken Sie auf Neuer Endpunkt.
- Geben Sie einen Namen für den Endpunkt ein. Dieser Name dient als eindeutige Kennung für Ihre Endpunktressource und wird zum Aufrufen Ihres benutzerdefinierten Sprachmodells für die Inferenz verwendet.
- Definieren Sie die Region, in der Ihr benutzerdefiniertes Sprachmodell bereitgestellt werden soll. Wenn das Modell in einer anderen Region trainiert wurde als der, die in der Endpunktkonfiguration festgelegt wurde, wird automatisch eine neue Modellkopie erstellt.
- Wählen Sie aus der Liste das trainierte benutzerdefinierte Sprachmodell aus, das Sie über den Endpunkt bereitstellen möchten.
- Klicken Sie auf Erstellen. Nach wenigen Augenblicken wird Ihr benutzerdefiniertes Sprachmodell in Ihrem Endpunkt bereitgestellt und kann für Inferenz und Benchmarking verwendet werden.
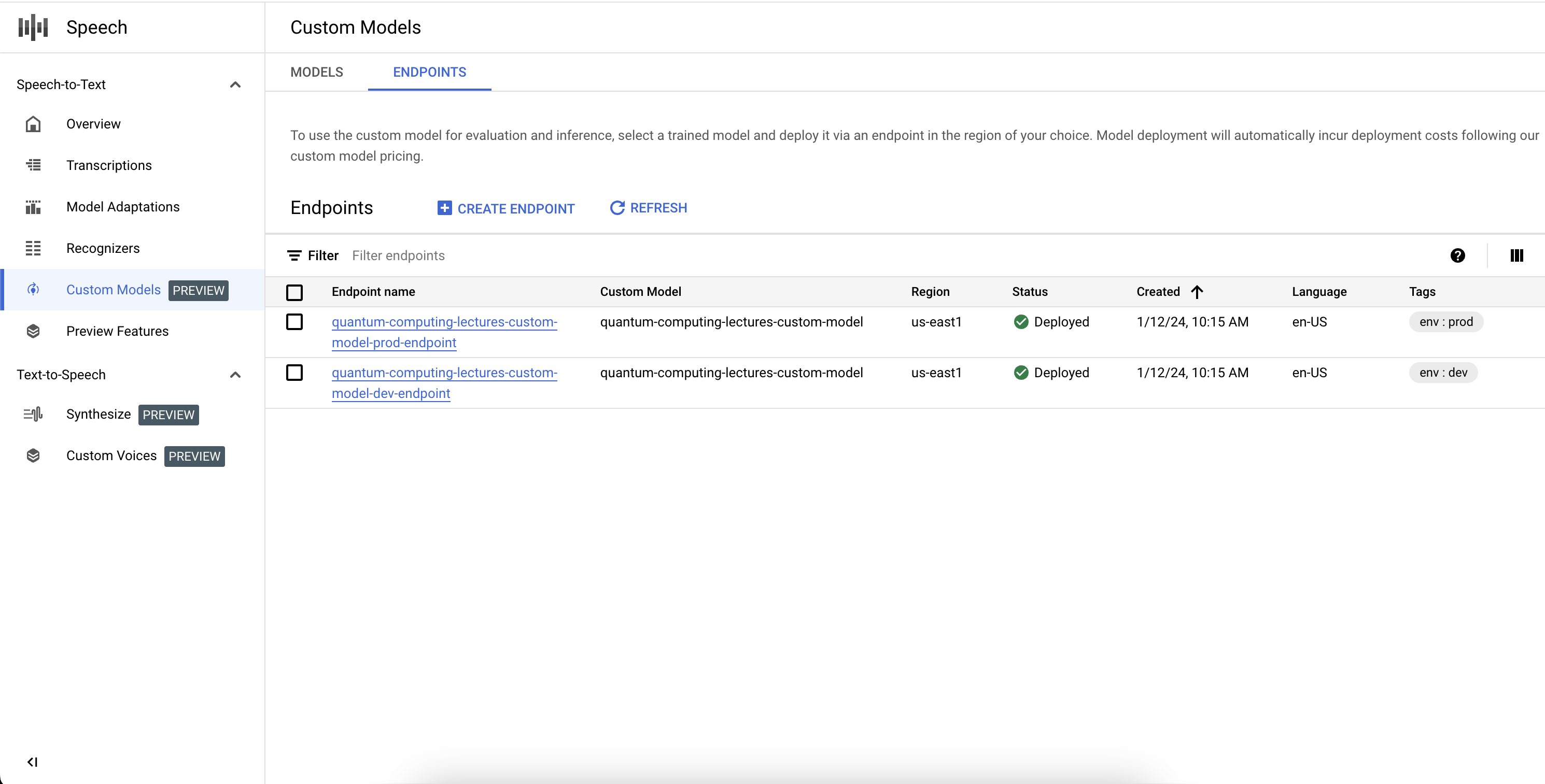
Endpunkte auflisten
Sie können die zugehörigen Endpunkte in der Console verwalten, indem Sie im Abschnitt „Benutzerdefinierte Modelle“ den Tab „Endpunkte“ auswählen. Sie können auch die Endpunkte auflisten, die Sie in der Konsole erstellt haben, zusammen mit ihrem aktuellen Status und dem zugehörigen benutzerdefinierten Speech-to-Text-Modell.
Endpunkt löschen
Bevor Sie beginnen, sollten Sie dafür sorgen, dass kein Traffic über Ihren Endpunkt geleitet wird, da er nach dem Löschen keine Anfragen mehr bedienen kann.
- Rufen Sie im Abschnitt Benutzerdefinierte Modelle den Tab Endpunkte auf.
- Klicken Sie auf dem Tab Endpunkte, um die Optionen zu maximieren, und dann auf Löschen. Der Endpunkt wird in wenigen Momenten gelöscht und stellt keinen Traffic mehr bereit.
Modell vergleichen
Um das benutzerdefinierte Speech-to-Text-Modell und Ihr Benchmarking-Dataset zur Bewertung der Accuracy Ihres Modells zu nutzen, folgen Sie dem Leitfaden zum Messen und Verbessern der Accuracy.