Práticas recomendadas de escalonamento para o Cloud Service Mesh no GKE
Neste guia, descrevemos as práticas recomendadas para resolver problemas de escalonamento em arquiteturas gerenciadas do Cloud Service Mesh no Google Kubernetes Engine. O principal objetivo dessas recomendações é garantir o desempenho, a confiabilidade e o uso de recursos ideais para seus aplicativos de microsserviços à medida que eles crescem.
Para entender as limitações de escalonabilidade, consulte Limites de escalonabilidade do Cloud Service Mesh.
A escalonabilidade do Cloud Service Mesh no GKE depende da operação eficiente dos dois principais componentes: o plano de dados e o plano de controle. Este documento se concentra principalmente no escalonamento do plano de dados.
Identificar problemas de escalonamento do plano de controle e do plano de dados
No Cloud Service Mesh, os problemas de escalonamento podem ocorrer no plano de controle ou no plano de dados. Veja como identificar o tipo de problema de escalonamento que você está enfrentando:
Sintomas de problemas de escalonamento do plano de controle
Descoberta de serviço lenta:novos serviços ou endpoints levam muito tempo para serem descobertos e ficarem disponíveis.
Atrasos na configuração:as mudanças nas regras de gerenciamento de tráfego ou nas políticas de segurança levam muito tempo para serem propagadas.
Aumento da latência nas operações do plano de controle:operações como criação, atualização ou exclusão de recursos do Cloud Service Mesh ficam lentas ou não respondem.
Erros relacionados ao Traffic Director:é possível observar erros nos registros do Cloud Service Mesh ou nas métricas do plano de controle que indicam problemas de conectividade, esgotamento de recursos ou limitação da API.
Escopo do impacto:problemas no plano de controle geralmente afetam toda a malha, causando uma degradação generalizada do desempenho.
Sintomas de problemas de escalonamento do plano de dados
Aumento da latência na comunicação entre serviços:as solicitações a um serviço na malha têm latência ou tempos limite mais altos, mas não há uso elevado de CPU/memória nos contêineres do serviço.
Alto uso de CPU ou memória em proxies do Envoy:o alto uso de CPU ou memória pode indicar que os proxies estão com dificuldades para processar a carga de tráfego.
Impacto localizado:os problemas no plano de dados geralmente afetam serviços ou cargas de trabalho específicos, dependendo dos padrões de tráfego e da utilização de recursos dos proxies do Envoy.
Como escalonar o plano de dados
Para escalonar o plano de dados, tente as seguintes técnicas:
- Configurar o escalonamento automático horizontal de pods (HPA)
- Otimizar a configuração do proxy do Envoy
- Monitorar e ajustar
Configurar o escalonamento automático horizontal de pods (HPA) para cargas de trabalho
Use o escalonamento automático horizontal de pods (HPA) para escalonar dinamicamente as cargas de trabalho com pods adicionais com base na utilização de recursos. Considere o seguinte ao configurar o HPA:
Use o parâmetro
--horizontal-pod-autoscaler-sync-periodparakube-controller-managere ajustar a taxa de polling do controlador HPA. A taxa de sondagem padrão é de 15 segundos, e você pode considerar definir um valor menor se esperar picos de tráfego mais rápidos. Para saber mais sobre quando usar o HPA com o GKE, consulte Escalonamento automático horizontal de pods.O comportamento de escalonamento padrão pode resultar na implantação (ou encerramento) de um grande número de pods de uma só vez, o que pode causar um pico no uso de recursos. Use políticas de escalonamento automático para limitar a taxa de implantação de pods.
Use EXIT_ON_ZERO_ACTIVE_CONNECTIONS para evitar a queda de conexões durante o redução de escala.
Para mais detalhes sobre o HPA, consulte Escalonamento automático horizontal de pods na documentação do Kubernetes.
Otimizar a configuração de proxy do Envoy
Para otimizar a configuração do proxy Envoy, considere as seguintes recomendações:
Limites de recurso
É possível definir solicitações e limites de recursos para sidecars do Envoy nas especificações do pod. Isso evita a disputa de recursos e garante uma performance consistente.
Também é possível configurar limites de recursos padrão para todos os proxies do Envoy na malha usando anotações de recursos.
Os limites ideais de recursos para seus proxies do Envoy dependem de fatores como volume de tráfego, complexidade da carga de trabalho e recursos de nós do GKE. Monitore e ajuste continuamente sua malha de serviço para garantir a performance ideal.
Consideração importante:
- Qualidade de serviço (QoS): definir solicitações e limites garante que seus proxies do Envoy tenham uma qualidade de serviço previsível.
Escopo das dependências do serviço
Considere reduzir o gráfico de dependência da malha declarando todas as dependências pela API Sidecar. Isso limita o tamanho e a complexidade da configuração enviada a uma determinada carga de trabalho, o que é fundamental para malhas maiores.
Por exemplo, este é o gráfico de tráfego do aplicativo de amostra da boutique on-line.
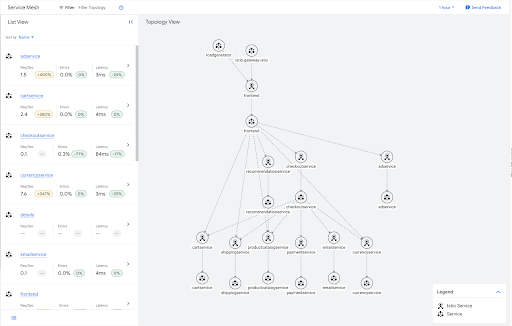
Muitos desses serviços são folhas no gráfico e, portanto, não precisam ter informações de saída para nenhum dos outros serviços na malha. É possível aplicar um recurso sidecar que limita o escopo da configuração do sidecar para esses serviços de folha, conforme mostrado no exemplo a seguir.
apiVersion: networking.istio.io/v1beta1
kind: Sidecar
metadata:
name: leafservices
namespace: default
spec:
workloadSelector:
labels:
app: cartservice
app: shippingservice
app: productcatalogservice
app: paymentservice
app: emailservice
app: currencyservice
egress:
- hosts:
- "~/*"
Consulte o aplicativo de amostra Online Boutique para saber como implantar esse aplicativo.
Outro benefício do escopo do sidecar é a redução de consultas DNS desnecessárias. O escopo das dependências de serviço garante que um secundário do Envoy só faça consultas de DNS para serviços com que ele vai se comunicar, em vez de todos os clusters na malha de serviço.
Para implantações em grande escala que enfrentam problemas com tamanhos de configuração grandes nos sidecars, o escopo das dependências de serviço é altamente recomendado para a escalonabilidade da malha.
Para limitar o escopo da configuração de todas as cargas de trabalho em um único namespace, crie um recurso sidecar nesse namespace. Isso instrui todos os proxies do Envoy nesse namespace a receber apenas a configuração dos serviços no próprio namespace.
apiVersion: networking.istio.io/v1beta1
kind: Sidecar
metadata:
name: sidecar
namespace: my-app
spec:
egress:
- hosts:
- "my-app/*"
É possível aplicar um comportamento padrão a todos os namespaces na malha aplicando um único recurso sidecar ao namespace raiz, geralmente istio-system.
O arquivo secundário a seguir restringe o tráfego de saída de todos os arquivos secundários na malha para serviços localizados no próprio namespace.
apiVersion: networking.istio.io/v1beta1
kind: Sidecar
metadata:
name: sidear
namespace: istio-system
spec:
egress:
- hosts:
- "./*"
O Cloud Service Mesh impõe um limite no número total de recursos de sidecar que podem ser criados em uma única malha. Devido a essa restrição, a prática recomendada é criar um sidecar no nível do namespace.
Monitorar e ajustar
Depois de definir os limites iniciais de recursos, é crucial monitorar os proxies do Envoy para garantir que eles estejam funcionando de maneira ideal. Use os painéis do GKE para monitorar o uso de CPU e memória e ajuste os limites de recursos conforme necessário.
Para determinar se um proxy do Envoy precisa de limites de recursos maiores, monitore o consumo de recursos dele em condições de tráfego típicas e de pico. Veja o que procurar:
Uso alto da CPU:se o uso da CPU do Envoy se aproximar ou exceder consistentemente o limite, talvez ele esteja com dificuldades para processar solicitações, o que leva ao aumento da latência ou à perda de solicitações. Considere aumentar o limite de CPU.
Você pode querer usar o escalonamento horizontal nesse caso, mas se o proxy sidecar não conseguir processar as solicitações tão rápido quanto o contêiner do aplicativo, ajustar os limites de CPU pode produzir os melhores resultados.
Alto uso de memória:se o uso de memória do Envoy se aproximar ou exceder o limite, ele poderá começar a descartar conexões ou apresentar erros de falta de memória (OOM). Aumente o limite de memória para evitar esses problemas.
Registros de erros:examine os registros do Envoy em busca de erros relacionados ao esgotamento de recursos, como erro de conexão upstream ou desconexão ou redefinição antes dos cabeçalhos ou muitos arquivos abertos. Esses erros podem indicar que o proxy precisa de mais recursos. Consulte os documentos de solução de problemas de escalonamento para outros erros relacionados a problemas de escalonamento.
Métricas de desempenho:monitore métricas de desempenho importantes, como latência de solicitação, taxas de erro e capacidade. Se você notar uma degradação de performance correlacionada com alta utilização de recursos, talvez seja necessário aumentar os limites.
Ao definir e monitorar ativamente os limites de recursos para seus proxies de plano de dados, é possível garantir que a malha de serviço seja escalonada de maneira eficiente no GKE.
Como escalonar o plano de controle
Nesta seção, descrevemos as configurações que podem ser ajustadas para dimensionar seu plano de controle.
Seletores de descoberta
Os seletores de descoberta são um campo no MeshConfig que permite especificar o conjunto de namespaces que os planos de controle consideram ao calcular atualizações de configuração para sidecars.
Por padrão, o Cloud Service Mesh monitora todos os namespaces no cluster. Isso pode ser um gargalo para clusters grandes que não precisam monitorar todos os recursos.
Use discoverySelectors para reduzir a carga computacional no plano de controle
limitando o número de recursos do Kubernetes (como serviços, pods e
endpoints) que são monitorados e processados.
Ao usar a implementação do plano de controle TRAFFIC_DIRECTOR, o Cloud Service Mesh cria apenas recursos Google Cloud , como serviços de back-end e grupos de endpoints de rede, para recursos do Kubernetes em namespaces especificados em discoverySelectors.
Para mais informações, consulte Seletores de descoberta na documentação do Istio.
Desenvolver a resiliência
É possível ajustar as seguintes configurações para aumentar a capacidade de recuperação da malha de serviço:
Detecção de outlier
A detecção de outliers monitora hosts em um serviço upstream e os remove do pool de balanceamento de carga ao atingir um determinado limite de erro.
- Configuração principal:
outlierDetection: configurações que controlam a remoção de hosts não íntegros do pool de balanceamento de carga.
- Benefícios:mantém um conjunto íntegro de hosts no pool de balanceamento de carga.
Para mais informações, consulte Detecção de outliers na documentação do Istio.
Novas tentativas
Mitigar erros temporários repetindo automaticamente as solicitações com falha.
- Configuração principal:
attempts: número de novas tentativas.perTryTimeout: tempo limite por tentativa de nova tentativa. Defina um valor menor que o tempo limite geral. Ele determina quanto tempo você vai esperar por cada tentativa individual.retryBudget: número máximo de novas tentativas simultâneas.
- Benefícios:maiores taxas de sucesso para solicitações, impacto reduzido de falhas intermitentes.
Fatores a considerar:
- Idempotência:verifique se a operação que está sendo repetida é idempotente, ou seja, pode ser repetida sem efeitos colaterais indesejados.
- Número máximo de novas tentativas:limite o número de novas tentativas (por exemplo, no máximo três) para evitar loops infinitos.
- Quebra de circuito:integre novas tentativas com disjuntores para evitar novas tentativas quando um serviço falha constantemente.
Para mais informações, consulte Retries na documentação do Istio.
Tempo limite
Use tempos limite para definir o tempo máximo permitido para o processamento de solicitações.
- Configuração principal:
timeout: tempo limite da solicitação para um serviço específico.idleTimeout: tempo que uma conexão pode permanecer inativa antes de ser fechada.
- Benefícios:melhor capacidade de resposta do sistema, prevenção de vazamentos de recursos e proteção contra tráfego malicioso.
Fatores a considerar:
- Latência de rede:considere o tempo de retorno (RTT) esperado entre serviços. Deixe uma margem para atrasos inesperados.
- Gráfico de dependência de serviço:para solicitações encadeadas, verifique se o tempo limite de um serviço de chamada é menor do que o tempo limite cumulativo das dependências dele para evitar falhas em cascata.
- Tipos de operações:tarefas de longa duração podem precisar de tempos limite significativamente maiores do que as recuperações de dados.
- Tratamento de erros:os tempos limite precisam acionar a lógica de tratamento de erros adequada (por exemplo, nova tentativa, substituição, interrupção de circuito).
Para mais informações, consulte Timeouts na documentação do Istio.
Monitorar e ajustar
Comece com as configurações padrão de tempos limite, detecção de outliers e novas tentativas e ajuste-as gradualmente com base nos requisitos específicos do serviço e nos padrões de tráfego observados. Por exemplo, analise dados reais sobre quanto tempo seus serviços normalmente levam para responder. Em seguida, ajuste os tempos limite para corresponder às características específicas de cada serviço ou endpoint.
Telemetria
Use a telemetria para monitorar continuamente a malha de serviço e ajustar a configuração dela para otimizar a performance e a confiabilidade.
- Métricas:use métricas abrangentes, especificamente volumes de solicitações, latência e taxas de erro. Integre com o Cloud Monitoring para visualização e alertas.
- Rastreamento distribuído:ative a integração do rastreamento distribuído com o Cloud Trace para ter insights detalhados sobre os fluxos de solicitações nos seus serviços.
- Registro em registros:configure o registro de acesso para capturar informações detalhadas sobre solicitações e respostas.
Informações adicionais
- Para saber mais sobre o Cloud Service Mesh, consulte a visão geral do Cloud Service Mesh.
- Para orientações gerais sobre escalonabilidade da engenharia de confiabilidade do site (SRE), consulte os capítulos Como lidar com sobrecarga e Como lidar com falhas em cascata no livro do Google sobre SRE.