Halaman ini menjelaskan dan membandingkan dua layanan Perlindungan Data Sensitif yang membantu Anda memahami data dan mengaktifkan alur kerja tata kelola data: layanan penemuan dan layanan inspeksi.
Penemuan data sensitif
Layanan penemuan memantau data di seluruh organisasi Anda. Layanan ini berjalan terus-menerus dan secara otomatis menemukan, mengklasifikasikan, dan membuat profil data. Penemuan dapat membantu Anda memahami lokasi dan sifat data yang Anda simpan, termasuk resource data yang mungkin tidak Anda ketahui. Data tidak diketahui (terkadang disebut data bayangan) biasanya tidak menjalani tingkat tata kelola data dan manajemen risiko yang sama seperti data yang diketahui.
Anda mengonfigurasi penemuan di berbagai cakupan. Anda dapat menetapkan jadwal pembuatan profil yang berbeda untuk subkumpulan data yang berbeda. Anda juga dapat mengecualikan subset data yang tidak perlu diprofilkan.
Output pemindaian penemuan: profil data
Output pemindaian penemuan adalah serangkaian profil data untuk setiap resource data dalam cakupan. Misalnya, pemindaian penemuan data BigQuery atau Cloud SQL menghasilkan profil data di tingkat project, tabel, dan kolom.
Profil data berisi metrik dan insight tentang resource yang diprofilkan. Hal ini mencakup klasifikasi data (atau infoTypes), tingkat sensitivitas, tingkat risiko data, ukuran data, bentuk data, dan elemen lain yang menjelaskan sifat data dan postur keamanan data (seberapa amannya data tersebut). Anda dapat menggunakan profil data untuk membuat keputusan yang tepat tentang cara melindungi data Anda—misalnya, dengan menyetel kebijakan akses pada tabel.
Pertimbangkan kolom BigQuery bernama ccn, di mana setiap baris berisi nomor kartu kredit unik dan tidak ada nilai null. Profil data tingkat kolom yang dihasilkan akan memiliki detail berikut:
| Nama tampilan | Nilai |
|---|---|
Field ID |
ccn |
Data risk |
High |
Sensitivity |
High |
Data type |
TYPE_STRING |
Policy tags |
No |
Free text score |
0 |
Estimated uniqueness |
High |
Estimated null proportion |
Very low |
Last profile generated |
DATE_TIME |
Predicted infoType |
CREDIT_CARD_NUMBER |
Selain itu, profil tingkat kolom ini adalah bagian dari profil tingkat tabel, yang memberikan insight seperti lokasi data, status enkripsi, dan apakah tabel dibagikan secara publik. Di konsol Google Cloud , Anda juga dapat melihat entri Cloud Logging untuk tabel, dan pokok IAM dengan peran untuk tabel.
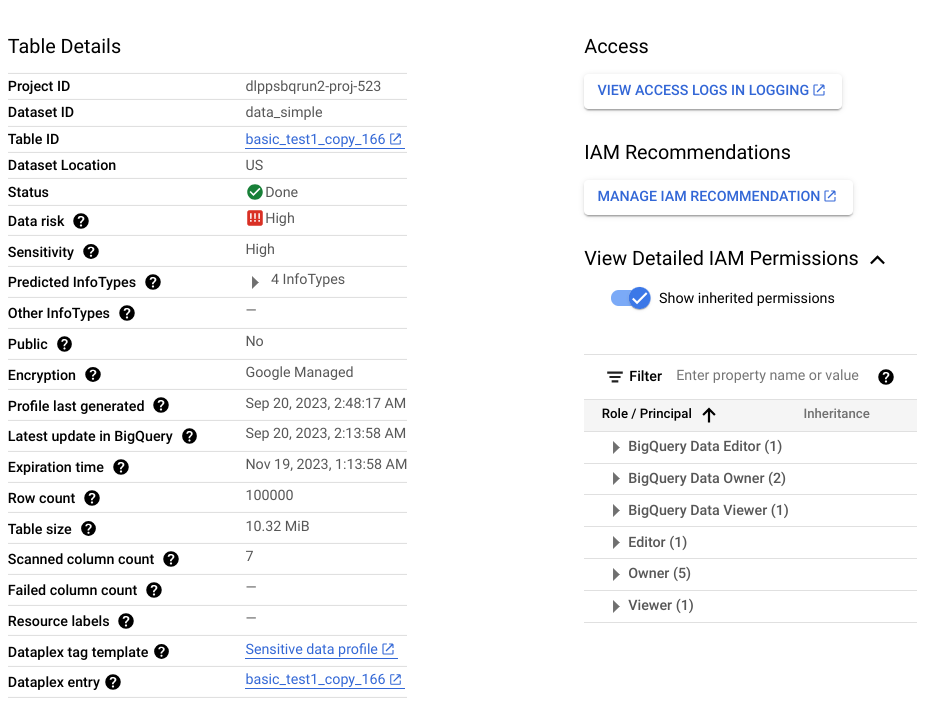
Untuk mengetahui daftar lengkap metrik dan insight yang tersedia di profil data, lihat Referensi metrik.
Kapan harus menggunakan penemuan
Saat merencanakan pendekatan pengelolaan risiko data, sebaiknya Anda memulai dengan penemuan. Layanan penemuan membantu Anda mendapatkan gambaran luas tentang data dan mengaktifkan pemberitahuan, pelaporan, dan perbaikan masalah.
Selain itu, layanan penemuan dapat membantu Anda mengidentifikasi resource tempat data tidak terstruktur mungkin berada. Resource tersebut mungkin memerlukan pemeriksaan menyeluruh. Data tidak terstruktur ditentukan oleh skor teks bebas tinggi dalam skala 0 hingga 1.
Pemeriksaan data sensitif
Layanan pemeriksaan melakukan pemindaian menyeluruh pada satu resource untuk menemukan setiap instance data sensitif. Pemeriksaan menghasilkan temuan untuk setiap instance yang terdeteksi.
Tugas pemeriksaan menyediakan serangkaian opsi konfigurasi yang lengkap untuk membantu Anda menentukan data yang ingin diperiksa. Misalnya, Anda dapat mengaktifkan pengambilan sampel untuk membatasi data yang akan diperiksa ke sejumlah baris tertentu (untuk data BigQuery) atau jenis file tertentu (untuk data Cloud Storage). Anda juga dapat menargetkan jangka waktu tertentu saat data dibuat atau diubah.
Tidak seperti penemuan, yang terus memantau data Anda, pemeriksaan adalah operasi sesuai permintaan. Namun, Anda dapat menjadwalkan tugas inspeksi berulang yang disebut pemicu tugas.
Output pemindaian inspeksi: temuan
Setiap temuan mencakup detail seperti lokasi instance yang terdeteksi, potensi infoType-nya, dan kepastian (juga disebut kemungkinan) bahwa temuan tersebut cocok dengan infoType. Bergantung pada setelan Anda, Anda juga bisa mendapatkan string sebenarnya yang terkait dengan temuan; string ini disebut kutipan dalam Perlindungan Data Sensitif.
Untuk mengetahui daftar lengkap detail yang disertakan dalam temuan inspeksi, lihat
Finding.
Kapan harus menggunakan pemeriksaan
Pemeriksaan berguna saat Anda perlu menyelidiki data tidak terstruktur (seperti komentar atau ulasan yang dibuat pengguna) dan mengidentifikasi setiap instance informasi identitas pribadi (PII). Jika pemindaian penemuan mengidentifikasi resource yang berisi data tidak terstruktur, sebaiknya jalankan pemindaian inspeksi pada resource tersebut untuk mendapatkan detail tentang setiap temuan.
Kapan sebaiknya tidak menggunakan pemeriksaan
Memeriksa resource tidak berguna jika kedua kondisi berikut berlaku. Pemindaian penemuan dapat membantu Anda memutuskan apakah pemindaian inspeksi diperlukan atau tidak.
- Anda hanya memiliki data terstruktur di resource. Artinya, tidak ada kolom data bentuk bebas, seperti komentar atau ulasan pengguna.
- Anda sudah mengetahui infoType yang disimpan dalam resource tersebut.
Misalnya, profil data dari pemindaian penemuan menunjukkan bahwa tabel BigQuery tertentu tidak memiliki kolom dengan data tidak terstruktur, tetapi memiliki kolom nomor kartu kredit unik. Dalam hal ini, memeriksa
nomor kartu kredit dalam tabel tidak berguna. Pemeriksaan akan menghasilkan
temuan untuk setiap item dalam kolom. Jika Anda memiliki 1 juta baris dan setiap baris berisi 1 nomor kartu kredit, tugas inspeksi akan menghasilkan 1 juta temuan untuk infoType CREDIT_CARD_NUMBER. Dalam contoh ini, pemeriksaan tidak
diperlukan karena pemindaian penemuan sudah menunjukkan bahwa
kolom berisi nomor kartu kredit unik.
Residensi, pemrosesan, dan penyimpanan data
Penemuan dan pemeriksaan mendukung persyaratan residensi data:
- Layanan penemuan memproses data Anda di tempat data tersebut berada dan menyimpan profil data yang dihasilkan di region atau multi-region yang sama dengan data yang diprofilkan. Untuk mengetahui informasi selengkapnya, lihat Pertimbangan residensi data.
- Saat memeriksa data dalam sistem penyimpanan Google Cloud , layanan pemeriksaan memproses data Anda di region yang sama dengan tempat data berada dan menyimpan tugas pemeriksaan di region tersebut. Saat memeriksa
data melalui tugas hybrid atau melalui metode
content, layanan pemeriksaan memungkinkan Anda menentukan tempat data Anda harus diproses. Untuk mengetahui informasi selengkapnya, lihat artikel Cara penyimpanan data.
Ringkasan perbandingan: layanan penemuan dan pemeriksaan
| Discovery | Inspeksi | |
|---|---|---|
| Manfaat |
|
|
| Biaya |
10 TB berbiaya sekitar US$300 per bulan dalam mode penggunaan. |
10 TB berbiaya sekitar US$10.000 per pemindaian. |
| Sumber data yang didukung | BigLake BigQuery Variabel lingkungan fungsi Cloud Run Variabel lingkungan revisi layanan Cloud Run Cloud SQL Cloud Storage Vertex AI Amazon S3 Azure Blob Storage |
BigQuery Cloud Storage Datastore Hybrid (sumber apa pun)1 |
| Cakupan yang didukung |
|
Satu tabel BigQuery, bucket Cloud Storage, atau jenis Datastore. |
| Template inspeksi bawaan | Ya | Ya |
| InfoType bawaan dan kustom | Ya | Ya |
| Output pemindaian | Ringkasan tingkat tinggi (profil data) semua data yang didukung. | Temuan konkret data sensitif dalam resource yang diperiksa. |
| Menyimpan hasil ke BigQuery | Ya | Ya |
| Mengirim ke Katalog Universal Dataplex sebagai tag (Tidak digunakan lagi) | Ya | Ya |
| Mengirim ke Dataplex Universal Catalog sebagai aspek | Ya | Tidak |
| Memublikasikan hasil ke Security Command Center | Ya | Ya |
| Memublikasikan temuan ke Google Security Operations | Ya untuk penemuan tingkat organisasi dan tingkat folder | Tidak |
| Publikasikan ke Pub/Sub | Ya | Ya |
| Dukungan residensi data | Ya | Ya |
1 Pemeriksaan hybrid memiliki model harga yang berbeda. Untuk mengetahui informasi selengkapnya, lihat Pemeriksaan data dari berbagai sumber .
Langkah berikutnya
- Pelajari strategi yang direkomendasikan untuk memitigasi risiko data (dokumen berikutnya dalam seri ini)