Questa pagina descrive il servizio di rilevamento dei dati sensibili. Questo servizio ti aiuta a determinare dove si trovano i dati sensibili e ad alto rischio nella tua organizzazione.
Panoramica
Il servizio di rilevamento ti consente di proteggere i dati in tutta la tua organizzazione identificando la posizione dei dati sensibili e ad alto rischio. Quando crei una configurazione di scansione del rilevamento, Sensitive Data Protection analizza le tue risorse per identificare i dati inclusi nell'ambito della profilazione. Poi genera i profili dei tuoi dati. Finché la configurazione del rilevamento è attiva, Sensitive Data Protection crea automaticamente i profili dei dati che aggiungi e modifichi. Puoi generare profili dei dati per l'intera organizzazione, singole cartelle e singoli progetti.
Ogni profilo di dati è un insieme di approfondimenti e metadati che il servizio di rilevamento raccoglie dalla scansione di una risorsa supportata. Gli approfondimenti includono gli infoTypes previsti e i livelli di rischio e sensibilità dei dati calcolati. Utilizza questi insight per prendere decisioni informate su come proteggere, condividere e utilizzare i tuoi dati.
I profili dei dati vengono generati a vari livelli di dettaglio. Ad esempio, quando crei profili dei dati BigQuery, questi vengono generati a livello di progetto, tabella e colonna.
L'immagine seguente mostra un elenco di profili dei dati a livello di colonna. Fai clic sull'immagine per ingrandirla.

Per un elenco degli approfondimenti e dei metadati inclusi in ogni profilo dei dati, consulta Riferimento alle metriche.
Per ulteriori informazioni sulla gerarchia delle risorse Google Cloud , vedi Gerarchia delle risorse.
Generazione del profilo dati
Per iniziare a generare profili dei dati, crea una configurazione di scansione di rilevamento (chiamata anche configurazione del profilo dati). In questa configurazione di scansione imposti l'ambito dell'operazione di rilevamento e il tipo di dati di cui vuoi creare il profilo. Nella configurazione della scansione, puoi impostare filtri per specificare i sottoinsiemi di dati che vuoi profilare o ignorare. Puoi anche impostare la pianificazione della profilazione.
Quando crei una configurazione di scansione, imposti anche il modello di ispezione da utilizzare. Il modello di ispezione è il punto in cui specifichi i tipi di dati sensibili (chiamati anche infoTypes) che Sensitive Data Protection deve cercare.
Quando Sensitive Data Protection crea profili di dati, analizza i tuoi dati in base alla configurazione della scansione e al modello di ispezione.
Sensitive Data Protection riprofila i dati come descritto in Frequenza di generazione dei profili di dati. Puoi personalizzare la frequenza di profilazione nella configurazione di scansione creando una pianificazione. Per forzare il servizio di rilevamento a eseguire nuovamente il profilo dei dati, consulta Forzare un'operazione di riprofilatura.
Tipi di rilevamento
Questa sezione descrive i tipi di operazioni di rilevamento che puoi eseguire e le risorse di dati supportate.
Rilevamento per BigQuery e BigLake
Quando profili i dati BigQuery, i profili di dati vengono generati a livello di progetto, tabella e colonna. Dopo aver profilato una tabella BigQuery, puoi esaminare ulteriormente i risultati eseguendo un'ispezione approfondita.
Sensitive Data Protection profila le tabelle supportate dall'API BigQuery Storage Read, tra cui:
- Tabelle BigQuery standard
- Snapshot delle tabelle
- Tabelle BigLake archiviate in Cloud Storage
Le seguenti funzionalità non sono supportate:
- tabelle BigQuery Omni.
- Tabelle in cui le dimensioni dei dati serializzati delle singole righe superano le dimensioni massime dei dati serializzati supportate dall'API BigQuery Storage Read, ovvero 128 MB.
- Tabelle esterne non BigLake, come Fogli Google.
Per informazioni su come profilare i dati BigQuery, consulta quanto segue:
- Profilare i dati BigQuery in un unico progetto
- Profilare i dati BigQuery in un'organizzazione o in una cartella
Per ulteriori informazioni su BigQuery, consulta la documentazione di BigQuery.
Discovery per Cloud SQL
Quando profili i dati Cloud SQL, i profili di dati vengono generati a livello di progetto, tabella e colonna. Prima di poter iniziare il rilevamento, devi fornire i dettagli di connessione per ogni istanza Cloud SQL di cui creare il profilo.
Per informazioni su come profilare i dati Cloud SQL, consulta quanto segue:
- Profilare i dati Cloud SQL in un unico progetto
- Profilare i dati Cloud SQL in un'organizzazione o in una cartella
Per ulteriori informazioni su Cloud SQL, consulta la documentazione di Cloud SQL.
Rilevamento per Cloud Storage
Quando profili i dati di Cloud Storage, i profili di dati vengono generati a livello di bucket. Sensitive Data Protection raggruppa i file rilevati in cluster di file e fornisce un riepilogo per ogni cluster.
Per informazioni su come profilare i dati di Cloud Storage, consulta quanto segue:
- Profilare i dati Cloud Storage in un unico progetto
- Profilare i dati Cloud Storage in un'organizzazione o in una cartella
Per saperne di più su Cloud Storage, consulta la documentazione di Cloud Storage.
Discovery per Vertex AI
Quando profili un set di dati Vertex AI, Sensitive Data Protection genera un profilo dei dati dell'archivio file o un profilo dei dati della tabella, a seconda di dove sono archiviati i dati di addestramento: Cloud Storage o BigQuery.
Per ulteriori informazioni, consulta le seguenti risorse:
- Rilevamento di dati sensibili per Vertex AI
- Profilare i dati Vertex AI in un singolo progetto
- Profila i dati di Vertex AI in un'organizzazione o in una cartella
Per saperne di più su Vertex AI, consulta la documentazione di Vertex AI.
Discovery per altri cloud provider
Quando profili i dati S3, i profili di dati vengono generati a livello di bucket. Quando profili i dati di Azure Blob Storage, i profili dei dati vengono generati a livello di container.
In entrambi i casi, la protezione dei dati sensibili raggruppa i file rilevati in cluster di file e fornisce un riepilogo per ogni cluster.
Per ulteriori informazioni, consulta le seguenti risorse:
Variabili di ambiente Cloud Run
Il servizio di rilevamento può rilevare la presenza di secret in variabili di ambiente delle revisioni dei servizi Cloud Run e delle funzioni Cloud Run e inviare i risultati a Security Command Center. Non vengono generati profili dei dati.
Per maggiori informazioni, vedi Segnalare i secret nelle variabili di ambiente a Security Command Center.
Ruoli richiesti per configurare e visualizzare i profili di dati
Le sezioni seguenti elencano i ruoli utente richiesti, suddivisi in categorie in base al loro scopo. A seconda della configurazione della tua organizzazione, potresti decidere di far svolgere attività diverse a persone diverse. Ad esempio, la persona che configura i profili dei dati potrebbe essere diversa da quella che li monitora regolarmente.
Ruoli richiesti per lavorare con i profili di dati a livello di organizzazione o cartella
Questi ruoli ti consentono di configurare e visualizzare i profili dei dati a livello di organizzazione o cartella.
Assicurati che questi ruoli siano concessi alle persone giuste a livello di organizzazione. In alternativa, l'amministratore Google Cloud può creare ruoli personalizzati che dispongono solo delle autorizzazioni pertinenti.
| Finalità | Ruolo predefinito | Autorizzazioni pertinenti |
|---|---|---|
| Crea una configurazione di scansione di rilevamento e visualizza i profili di dati | Amministratore DLP (roles/dlp.admin)
|
|
| Crea un progetto da utilizzare come container dell'agente di servizio1 | Autore progetto (roles/resourcemanager.projectCreator) |
|
| Concedere l'accesso alla scoperta2 | Uno dei seguenti:
|
|
| Visualizzare i profili di dati (sola lettura) | DLP Data Profiles Reader (roles/dlp.dataProfilesReader) |
|
Lettore DLP (roles/dlp.reader) |
|
1 Se non disponi del ruolo Project Creator (roles/resourcemanager.projectCreator), puoi comunque creare una configurazione di scansione, ma il container dell'agente di servizio che utilizzi deve essere un progetto esistente.
2 Se non disponi del ruolo Amministratore dell'organizzazione (roles/resourcemanager.organizationAdmin) o Amministratore sicurezza (roles/iam.securityAdmin), puoi comunque creare una configurazione di scansione. Dopo aver
creato la configurazione della scansione, un membro della tua organizzazione con uno di questi ruoli deve concedere l'accesso al rilevamento all'agente di servizio.
Ruoli richiesti per lavorare con i profili dati a livello di progetto
Questi ruoli ti consentono di configurare e visualizzare i profili dei dati a livello di progetto.
Assicurati che questi ruoli vengano concessi alle persone giuste a livello di progetto. In alternativa, l'amministratore Google Cloud può creare ruoli personalizzati che dispongono solo delle autorizzazioni pertinenti.
| Finalità | Ruolo predefinito | Autorizzazioni pertinenti |
|---|---|---|
| Configurare e visualizzare i profili di dati | Amministratore DLP (roles/dlp.admin)
|
|
| Visualizzare i profili di dati (sola lettura) | DLP Data Profiles Reader (roles/dlp.dataProfilesReader) |
|
Lettore DLP (roles/dlp.reader) |
|
Configurazione scansione rilevamento
Una configurazione di scansione di rilevamento (a volte chiamata configurazione di rilevamento o configurazione di scansione) specifica in che modo Sensitive Data Protection deve profilare i tuoi dati. Include le seguenti impostazioni:
- Ambito (organizzazione, cartella o progetto) dell'operazione di rilevamento
- Tipo di risorsa da profilare
- Modelli di ispezione da utilizzare
- Frequenza di scansione
- Sottoinsiemi specifici di dati da includere o escludere dalla scoperta
- Azioni che vuoi che Sensitive Data Protection intraprenda dopo il rilevamento, ad esempio i servizi Google Cloud a cui pubblicare i profili
- Agente di servizio da utilizzare per le operazioni di rilevamento
Per informazioni su come creare una configurazione di scansione di rilevamento, consulta le seguenti pagine:
Discovery per i dati BigQuery
Discovery per i dati Cloud SQL
Rilevamento dei dati di Cloud Storage
Discovery per i dati di Vertex AI
Segnala i secret nelle variabili di ambiente Cloud Run a Security Command Center (nessun profilo generato)
Ambiti di configurazione della scansione
Puoi creare una configurazione di scansione ai seguenti livelli:
- Organizzazione
- Cartella
- Progetto
- Risorsa dati singola
A livello di organizzazione e cartella, se due o più configurazioni di scansione attive hanno lo stesso progetto nel loro ambito, Sensitive Data Protection determina quale configurazione di scansione può generare profili per quel progetto. Per ulteriori informazioni, vedi Override delle configurazioni di scansione in questa pagina.
Una configurazione di scansione a livello di progetto può sempre profilare il progetto di destinazione e non è in competizione con altre configurazioni a livello di cartella principale o organizzazione.
Una configurazione di scansione di una singola risorsa è pensata per aiutarti a esplorare e testare la profilazione di una singola risorsa di dati.
Posizione della configurazione di scansione
La prima volta che crei una configurazione della scansione, specifichi dove vuoi che Sensitive Data Protection la memorizzi. Tutte le configurazioni di scansione successive che crei vengono archiviate nella stessa regione.
Ad esempio, se crei una configurazione di analisi per la cartella A e la memorizzi nella regione us-west1, anche qualsiasi altra configurazione di analisi che crei in un secondo momento per qualsiasi altra risorsa viene memorizzata in quella regione.
I metadati relativi ai dati da profilare vengono copiati nella stessa regione delle configurazioni di scansione, ma i dati stessi non vengono spostati o copiati. Per ulteriori informazioni, consulta Considerazioni sulla residenza dei dati.
Modello di ispezione
Un modello di ispezione specifica quali tipi di informazioni (o infoType) Sensitive Data Protection cerca durante l'analisi dei dati. Qui fornisci una combinazione di infoType integrati e infoType personalizzati facoltativi.
Puoi anche fornire un livello di probabilità per restringere ciò che Sensitive Data Protection considera una corrispondenza. Puoi aggiungere set di regole per escludere risultati indesiderati o includere risultati aggiuntivi.
Per impostazione predefinita, se modifichi un modello di ispezione utilizzato dalla configurazione di scansione, le modifiche vengono applicate solo alle scansioni future. La tua azione non causa un'operazione di riprofilazione dei tuoi dati.
Se vuoi che le modifiche al modello di ispezione attivino operazioni di riprofilazione sui dati interessati, aggiungi o aggiorna una pianificazione nella configurazione di scansione e attiva l'opzione per riprofilare i dati quando il modello di ispezione cambia. Per scoprire di più, consulta la sezione Frequenza di generazione dei profili dei dati.
Devi disporre di un modello di ispezione in ogni regione in cui sono presenti dati da
profilare. Se vuoi utilizzare un singolo modello per più regioni, puoi utilizzare
un modello archiviato nella regione global. Se le norme
dell'organizzazione ti impediscono di creare un modello di ispezione nella regione global, devi impostare un modello di ispezione dedicato per ogni regione. Per ulteriori
informazioni, consulta Considerazioni
sulla residenza dei dati.
I modelli di ispezione sono un componente fondamentale della piattaforma Sensitive Data Protection. I profili dei dati utilizzano gli stessi modelli di ispezione che puoi utilizzare in tutti i servizi Sensitive Data Protection. Per ulteriori informazioni sui modelli di ispezione, vedi Modelli.
Container dell'agente di servizio e agente di servizio
Quando crei una configurazione di scansione per la tua organizzazione o per una cartella, Sensitive Data Protection richiede di fornire un contenitore dell'agente di servizio. Un container dell'agente di servizio è un progetto Google Cloud utilizzato da Sensitive Data Protection per monitorare gli addebiti fatturati relativi alle operazioni di profilazione a livello di organizzazione e cartella.
Il container dell'agente di servizio contiene un agente di servizio, che la protezione dei dati sensibili utilizza per profilare i dati per tuo conto. Per l'autenticazione a Sensitive Data Protection e ad altre API, è necessario un service agent. L'agente di servizio deve disporre di tutte le autorizzazioni necessarie per accedere ai dati e creare profili. L'ID dell'agente di servizio ha il seguente formato:
service-PROJECT_NUMBER@dlp-api.iam.gserviceaccount.com
In questo caso, PROJECT_NUMBER è l'identificatore numerico del container dell'agente di servizio.
Quando imposti il container dell'agente di servizio, puoi scegliere un progetto esistente. Se il progetto selezionato contiene un service agent, Sensitive Data Protection concede a quest'ultimo le autorizzazioni IAM richieste. Se il progetto non ha un agente di servizio, Sensitive Data Protection ne crea uno e gli concede automaticamente le autorizzazioni di profilazione dei dati.
In alternativa, puoi scegliere di fare in modo che Sensitive Data Protection crei automaticamente il service agent e il relativo container. Sensitive Data Protection concede automaticamente le autorizzazioni di profilazione dei dati all'agente di servizio.
In entrambi i casi, se la protezione dei dati sensibili non riesce a concedere l'accesso alla profilazione dei dati all'agente di servizio, viene visualizzato un errore quando visualizzi i dettagli della configurazione dell'analisi.
Per le configurazioni di scansione a livello di progetto, non è necessario un contenitore dell'agente di servizio. Il progetto di cui stai eseguendo la profilazione soddisfa lo scopo del container dell'agente di servizio. Per eseguire le operazioni di profilazione, Sensitive Data Protection utilizza l'agente di servizio del progetto.
Accesso alla profilazione dei dati a livello di organizzazione o cartella
Quando configuri la profilazione a livello di organizzazione o cartella, Sensitive Data Protection tenta di concedere automaticamente l'accesso alla profilazione dei dati al tuo service agent. Tuttavia, se non disponi delle autorizzazioni per concedere ruoli IAM, Sensitive Data Protection non può eseguire questa azione per tuo conto. Una persona con queste autorizzazioni nella tua organizzazione, ad esempio un amministratore, deve concedere l'accesso alla profilazione dei dati al tuo service agent. Google Cloud
Frequenza di generazione dei profili di dati
Dopo aver creato una configurazione di scansione del rilevamento per una risorsa specifica, Sensitive Data Protection esegue una scansione iniziale, profilando i dati nell'ambito della configurazione di scansione.
Dopo la scansione iniziale, Sensitive Data Protection monitora continuamente la risorsa profilata. I dati aggiunti nella risorsa vengono profilati automaticamente poco dopo l'aggiunta.
Frequenza di riprofilatura predefinita
La frequenza di riprofilazione predefinita varia a seconda del tipo di rilevamento della configurazione di scansione:
- Profilazione BigQuery: per ogni tabella, attendi 30 giorni e poi riprofila la tabella se sono state apportate modifiche allo schema, alle righe della tabella o al modello di ispezione.
- Profilazione Cloud SQL: per ogni tabella, attendi 30 giorni e poi esegui una nuova profilazione della tabella se lo schema o il modello di ispezione sono stati modificati.
- Profilazione di Vertex AI: per ogni set di dati, attendi 30 giorni e poi riprofila il set di dati se il modello di ispezione è stato modificato.
Profilazione dell'archivio file: per ogni archivio file in Google Cloud o in altri cloud, attendi 30 giorni e poi riprofila l'archivio file se il modello di ispezione ha modifiche.
Sensitive Data Protection utilizza il termine archivio file per fare riferimento a un bucket o un contenitore di archiviazione di file.
Personalizzare la frequenza di riprofilazione
Nella configurazione della scansione, puoi personalizzare la frequenza di riprofilazione creando una o più pianificazioni per diversi sottoinsiemi di dati.
Sono disponibili le seguenti frequenze di riprofilazione:
- Non riprofilare: non riprofilare mai dopo la generazione dei profili iniziali.
- Nuova profilazione ogni giorno: attendi 24 ore prima di eseguire una nuova profilazione.
- Nuova profilazione ogni settimana: attendi 7 giorni prima di eseguire una nuova profilazione.
- Nuova profilazione ogni mese: attendi 30 giorni prima di eseguire una nuova profilazione.
Riprofilazione in base a una programmazione
Nella configurazione della scansione, puoi specificare se un sottoinsieme di dati deve essere riprofilato regolarmente indipendentemente dal fatto che i dati abbiano subito modifiche. La frequenza impostata specifica il tempo che deve trascorrere tra le operazioni di profilazione. Ad esempio, se imposti la frequenza su settimanale, Sensitive Data Protection profila una risorsa di dati sette giorni dopo l'ultima profilazione.
Riprofilazione all'aggiornamento
Nella configurazione di scansione, puoi specificare gli eventi che possono attivare operazioni di riprofilazione. Esempi di questi eventi sono gli aggiornamenti dei modelli di ispezione.
Quando selezioni questi eventi, la pianificazione che imposti specifica il periodo di tempo più lungo che la protezione dei dati sensibili attende per l'accumulo di aggiornamenti prima di riprofilare i dati. Se non si verificano modifiche applicabili, ad esempio modifiche allo schema o ai modelli di ispezione, nel periodo specificato, non viene eseguita una nuova profilazione dei dati. Quando si verifica la successiva modifica applicabile, i dati interessati vengono riprofilati alla prima opportunità, che è determinata da vari fattori (ad esempio la capacità della macchina disponibile o le unità di abbonamento acquistate). Sensitive Data Protection inizia quindi ad attendere nuovamente l'accumulo di aggiornamenti in base alla pianificazione impostata.
Ad esempio, supponiamo che la configurazione di analisi sia impostata per la riprofilazione mensile in caso di modifica dello schema. I profili dei dati sono stati creati il giorno 0. Entro il giorno 30 non vengono apportate modifiche allo schema, pertanto non viene eseguita una nuova profilazione dei dati. Il 35° giorno si verifica la prima modifica dello schema. Sensitive Data Protection riprofila i dati aggiornati alla prima opportunità. Il sistema attende altri 30 giorni per l'accumulo degli aggiornamenti dello schema prima di riprofilare i dati aggiornati.
Dal momento in cui inizia la riprofilatura, possono trascorrere fino a 24 ore prima che l'operazione venga completata. Se il ritardo dura più di 24 ore e ti trovi in modalità di prezzi dell'abbonamento, verifica se hai capacità rimanente per il mese.
Per scenari di esempio, consulta Esempi di prezzi della profilazione dei dati.
Per forzare il servizio di rilevamento a eseguire nuovamente il profilo dei dati, consulta Forzare un'operazione di riprofilatura.
Profilazione del rendimento
Il tempo necessario per profilare i dati varia a seconda di diversi fattori, inclusi, a titolo esemplificativo:
- Numero di risorse di dati di cui viene eseguita la profilazione
- Dimensioni delle risorse di dati
- Per le tabelle, il numero di colonne
- Per le tabelle, i tipi di dati nelle colonne
Pertanto, il rendimento di Sensitive Data Protection in un'attività di ispezione o profilazione precedente non è indicativo del suo rendimento nelle attività di profilazione future.
Conservazione dei profili di dati
Sensitive Data Protection conserva l'ultima versione di un profilo dati per 13 mesi. Quando Sensitive Data Protection riprofila una risorsa di dati, il sistema sostituisce i profili esistenti della risorsa di dati con quelli nuovi.
Nei seguenti scenari di esempio, supponi che sia in vigore la frequenza di profilazione predefinita per BigQuery:
Il 1° gennaio, Sensitive Data Protection profila la tabella A. La tabella A non cambia da più di un anno, quindi non viene profilata di nuovo. In questo caso, Sensitive Data Protection conserva i profili dati per la tabella A per 13 mesi prima di eliminarli.
Il 1° gennaio, Sensitive Data Protection profila la tabella A. Entro il mese, un utente della tua organizzazione aggiorna lo schema della tabella. A causa di questa modifica, il mese successivo Sensitive Data Protection esegue automaticamente una nuova profilazione della tabella A. I profili di dati appena generati sovrascrivono quelli creati a gennaio.
Per informazioni su come Sensitive Data Protection addebita la profilazione dei dati, consulta Prezzi per il rilevamento.
Se vuoi conservare i profili dati a tempo indeterminato o tenere traccia delle modifiche apportate, valuta la possibilità di salvarli in BigQuery quando configuri la profilazione. Scegli il set di dati BigQuery in cui salvare i profili e controlli le norme di scadenza delle tabelle per quel set di dati.
Override delle configurazioni di scansione
Puoi creare una sola configurazione di scansione per ogni combinazione di ambito e tipo di rilevamento. Ad esempio, puoi creare una sola configurazione della scansione a livello di organizzazione per la profilazione dei dati BigQuery e una sola configurazione della scansione a livello di organizzazione per il rilevamento dei secret. Allo stesso modo, puoi creare una sola configurazione di scansione a livello di progetto per la profilazione dei dati BigQuery e una sola configurazione di scansione a livello di progetto per il rilevamento dei secret.
Se due o più configurazioni di scansione attive hanno lo stesso progetto e lo stesso tipo di rilevamento nel loro ambito, si applicano le seguenti regole:
- Tra le configurazioni della scansione a livello di organizzazione e di cartella, quella più vicina al progetto potrà eseguire il rilevamento per quel progetto. Questa regola si applica anche se esiste una configurazione di scansione a livello di progetto con lo stesso tipo di rilevamento.
- Sensitive Data Protection tratta le configurazioni di scansione a livello di progetto indipendentemente dalle configurazioni a livello di organizzazione e cartella. Una configurazione di scansione creata a livello di progetto non può ignorare una configurazione creata per un'organizzazione o una cartella padre.
Considera il seguente esempio, in cui sono presenti tre configurazioni dell'analisi attive. Supponiamo che tutte queste configurazioni di scansione siano per la profilazione dei dati BigQuery.
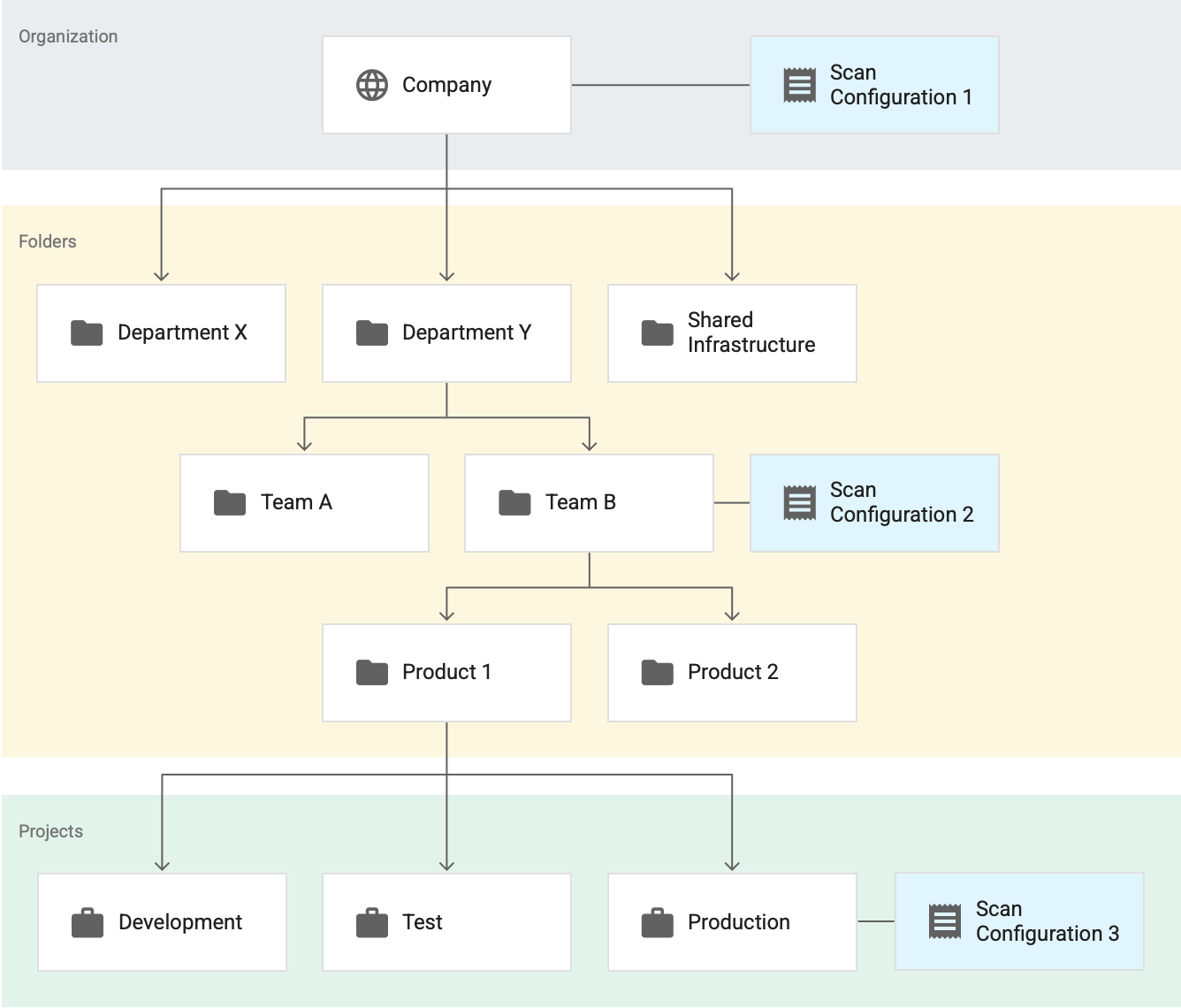
In questo caso, la configurazione di scansione 1 si applica all'intera organizzazione, la configurazione di scansione 2 si applica alla cartella Team B e la configurazione di scansione 3 si applica al progetto Produzione. In questo esempio:
- Sensitive Data Protection profila tutte le tabelle nei progetti che non si trovano nella cartella Team B in base alla Configurazione di scansione 1.
- Sensitive Data Protection profila tutte le tabelle nei progetti della cartella Team B, incluse le tabelle del progetto Produzione, in base alla configurazione di analisi 2.
- Sensitive Data Protection profila tutte le tabelle nel progetto Production in base alla configurazione di scansione 3.
In questo esempio, Sensitive Data Protection genera due set di profili per il progetto Production, uno per ciascuna delle seguenti configurazioni di scansione:
- Configurazione scansione 2
- Configurazione scansione 3
Tuttavia, anche se esistono due set di profili per lo stesso progetto, non li vedi tutti insieme nella dashboard. Vengono visualizzati solo i profili generati nella risorsa (organizzazione, cartella o progetto) e nella regione che stai visualizzando.
Per ulteriori informazioni sulla gerarchia delle risorse di Google Cloud, vedi Gerarchia delle risorse.
Snapshot del profilo di dati
Ogni profilo dati include uno snapshot della configurazione dell'analisi e del modello di ispezione utilizzati per generarlo. Puoi utilizzare questo snapshot per controllare le impostazioni che hai utilizzato per generare un profilo di dati specifico.
Considerazioni sulla residenza dei dati
Le considerazioni sulla residenza dei dati variano a seconda che tu stia eseguendo la scansione diGoogle Cloud dati o dati di altri provider cloud.
Considerazioni sulla residenza dei dati per i dati Google Cloud
Questa sezione si applica solo al rilevamento dei dati sensibili per le risorse Google Cloud. Per considerazioni sulla residenza dei dati relative alle risorse di altri cloud provider, vedi Considerazioni sulla residenza dei dati per i dati di altri cloud provider in questa pagina.
Sensitive Data Protection è progettato per supportare la residenza dei dati. Se devi rispettare i requisiti di residenza dei dati, considera i seguenti punti:
Modelli di ispezione regionali
Questa sezione si applica solo al rilevamento dei dati sensibili per le risorse Google Cloud. Per considerazioni sulla residenza dei dati relative alle risorse di altri cloud provider, vedi Considerazioni sulla residenza dei dati per i dati di altri cloud provider in questa pagina.
Sensitive Data Protection elabora i tuoi dati nella stessa regione in cui sono archiviati. ovvero i tuoi dati non lasciano la regione attuale.
Inoltre, un modello di ispezione può essere utilizzato solo per profilare i dati che
si trovano nella stessa regione del modello. Ad esempio, se configuri
l'individuazione in modo che utilizzi un modello di ispezione archiviato nella regione us-west1, Sensitive Data Protection può profilare solo i dati in quella regione.
Puoi
impostare un modello di ispezione dedicato
per ogni regione in cui sono presenti dati.
Se fornisci un modello di ispezione archiviato nella regione global, Sensitive Data Protection lo utilizza per i dati nelle regioni senza un modello di ispezione dedicato.
La seguente tabella fornisce scenari di esempio:
| Scenario | Assistenza |
|---|---|
Scansiona i dati nella regione us utilizzando un modello di ispezione della regione us. |
Supportato |
Scansiona i dati nella regione global utilizzando un modello di ispezione
della regione us. |
Non supportata |
Scansiona i dati nella regione us utilizzando un modello di ispezione della regione global. |
Supportato |
Scansiona i dati nella regione us utilizzando un modello di ispezione della regione us-east1. |
Non supportata |
Scansiona i dati nella regione us-east1 utilizzando un modello di ispezione
della regione us. |
Non supportata |
Scansiona i dati nella regione us utilizzando un modello di ispezione della regione asia. |
Non supportata |
Configurazione del profilo dati
Questa sezione si applica solo al rilevamento dei dati sensibili per le risorse Google Cloud. Per considerazioni sulla residenza dei dati relative alle risorse di altri cloud provider, vedi Considerazioni sulla residenza dei dati per i dati di altri cloud provider in questa pagina.
Quando Sensitive Data Protection crea profili dati, acquisisce uno snapshot della configurazione di analisi e del modello di ispezione e li archivia in ogni profilo dati
della tabella
o profilo dati
dell'archivio file.
Se configuri l'individuazione in modo che utilizzi un modello di ispezione della regione global, Sensitive Data Protection copia il modello in qualsiasi regione contenente dati da profilare. Analogamente, copia la configurazione della scansione in queste
regioni.
Considera questo esempio: il progetto A contiene la tabella 1. La tabella 1 si trova
nella regione us-west1; la configurazione della scansione si trova nella regione us-west2
e il modello di ispezione si trova nella regione global.
Quando Sensitive Data Protection esegue la scansione del progetto A, crea profili di dati per la tabella 1 e li archivia nella regione us-west1. Il profilo dei dati della tabella 1 contiene copie della configurazione di scansione e del modello di ispezione utilizzati nell'operazione di profilazione.
Se non vuoi che il modello di ispezione venga copiato in altre regioni, non configurare Sensitive Data Protection per analizzare i dati in queste regioni.
Archiviazione regionale dei profili di dati
Questa sezione si applica solo al rilevamento dei dati sensibili per le risorse Google Cloud. Per considerazioni sulla residenza dei dati relative alle risorse di altri cloud provider, vedi Considerazioni sulla residenza dei dati per i dati di altri cloud provider in questa pagina.
Sensitive Data Protection elabora i tuoi dati nella regione o nella multiregione in cui si trovano e archivia i profili di dati generati nella stessa regione o multiregione.
Per visualizzare i profili dei dati nella console Google Cloud , devi prima selezionare la regione in cui si trovano. Se hai dati in più regioni, devi cambiare regione per visualizzare ogni insieme di profili.
Regioni non supportate
Questa sezione si applica solo al rilevamento dei dati sensibili per le risorse Google Cloud. Per considerazioni sulla residenza dei dati relative alle risorse di altri cloud provider, vedi Considerazioni sulla residenza dei dati per i dati di altri cloud provider in questa pagina.
Se hai dati in una regione non supportata da Sensitive Data Protection, il servizio di rilevamento ignora queste risorse di dati e mostra un errore quando visualizzi i profili dei dati.
Più regioni
Sensitive Data Protection considera una multiregione come una
regione e non come un insieme di regioni. Ad esempio, la località a più regioni us e la regione us-west1 sono trattate come due regioni separate per quanto riguarda la residenza dei dati.
Risorse di zona
Sensitive Data Protection è un servizio regionale e multiregionale; non
distingue tra zone. Per una risorsa di zona supportata come un'istanza Cloud SQL, i dati vengono elaborati nella regione attuale, ma non necessariamente nella zona attuale. Ad esempio, se un'istanza Cloud SQL
è archiviata nella zona us-central1-a, Sensitive Data Protection
elabora e archivia i profili di dati nella regione us-central1.
Per informazioni generali sulle Google Cloud posizioni, vedi Area geografica e regioni.
Considerazioni sulla residenza dei dati per i dati di altri cloud provider
Considera quanto segue quando pianifichi di profilare i dati di altri cloud provider:
- I profili dati vengono archiviati insieme alla configurazione della scansione di rilevamento. Al contrario, quando profili i dati di Google Cloud , i profili vengono archiviati nella stessa regione dei dati da profilare.
- Se memorizzi il modello di ispezione nella regione
global, viene letta una copia in memoria del modello nella regione in cui memorizzi la configurazione della scansione di rilevamento. - I tuoi dati non vengono modificati. Una copia in memoria dei tuoi dati viene letta nella regione in cui memorizzi la configurazione della scansione di rilevamento. Tuttavia, Sensitive Data Protection non fornisce garanzie sul percorso dei dati dopo che raggiungono la rete internet pubblica. I dati vengono criptati con SSL.
Conformità
Per informazioni su come Sensitive Data Protection gestisce i tuoi dati e ti aiuta a soddisfare i requisiti di conformità, consulta Sicurezza dei dati.
Passaggi successivi
Leggi il post del blog Identity & Security Gestione automatica dei rischi correlati ai dati per BigQuery con Sensitive Data Protection.
Scopri come stimare il costo della profilazione dei dati.
Scopri come profilare i dati a livello di organizzazione, cartella o progetto.
Scopri in che modo Sensitive Data Protection calcola i livelli di rischio e sensibilità dei dati durante la profilazione dei dati.
Scopri come correggere i risultati della scoperta.
Scopri come risolvere i problemi relativi al profiler dei dati.