En esta página, se describe el servicio de descubrimiento de datos sensibles. Este servicio te ayuda a determinar dónde residen los datos sensibles y de alto riesgo en tu organización.
Descripción general
El servicio de descubrimiento te permite proteger los datos en toda tu organización, ya que identifica dónde residen los datos sensibles y de alto riesgo. Cuando creas una configuración de análisis de descubrimiento, Sensitive Data Protection analiza tus recursos para identificar los datos que se incluyen en el alcance de la generación de perfiles. Luego, genera perfiles de tus datos. Siempre que la configuración de descubrimiento esté activa, Sensitive Data Protection genera perfiles automáticamente de los datos que agregas y modificas. Puedes generar perfiles de datos en toda la organización, en carpetas individuales y en proyectos individuales.
Cada perfil de datos es un conjunto de estadísticas y metadatos que el servicio de descubrimiento recopila a partir del análisis de un recurso compatible. Las estadísticas incluyen los infoTypes previstos y los niveles de sensibilidad y riesgo de los datos calculados de tus datos. Usa estas estadísticas para tomar decisiones fundamentadas sobre cómo proteger, compartir y usar tus datos.
Los perfiles de datos se generan con distintos niveles de detalle. Por ejemplo, cuando generas perfiles de datos de BigQuery, se generan perfiles a nivel del proyecto, la tabla y la columna.
En la siguiente imagen, se muestra una lista de perfiles de datos a nivel de la columna. Haz clic en la imagen para ampliarla.

Para obtener una lista de las estadísticas y los metadatos incluidos en cada perfil de datos, consulta la Referencia de las métricas.
Para obtener más información sobre la jerarquía de recursos de Google Cloud , consulta Jerarquía de recursos.
Generación de perfiles de datos
Para comenzar a generar perfiles de datos, debes crear una configuración de análisis de descubrimiento (también llamada configuración de perfil de datos). En esta configuración de análisis, estableces el alcance de la operación de descubrimiento y el tipo de datos que deseas analizar. En la configuración del análisis, puedes establecer filtros para especificar subconjuntos de datos que deseas generar perfiles o omitir. También puedes establecer el programa de generación de perfiles.
Cuando creas una configuración de análisis, también estableces la plantilla de inspección que se usará. En la plantilla de inspección, especificas los tipos de datos sensibles (también llamados infoTypes) que debe buscar Sensitive Data Protection.
Cuando Sensitive Data Protection crea perfiles de datos, analiza tus datos según la configuración de análisis y la plantilla de inspección.
Sensitive Data Protection vuelve a generar el perfil de los datos como se describe en Frecuencia de generación de perfiles de datos. Puedes personalizar la frecuencia de generación de perfiles en la configuración de análisis creando un programa. Para forzar al servicio de descubrimiento a volver a generar el perfil de tus datos, consulta Cómo forzar una operación de volver a generar el perfil.
Tipos de descubrimiento
En esta sección, se describen los tipos de operaciones de descubrimiento que puedes realizar y los recursos de datos admitidos.
Descubrimiento para BigQuery y BigLake
Cuando generas perfiles de datos de BigQuery, se generan perfiles de datos a nivel del proyecto, la tabla y la columna. Después de generar el perfil de una tabla de BigQuery, puedes investigar más los resultados realizando una inspección detallada.
Tablas de perfiles de la Protección de datos sensibles que admite la API de lectura de BigQuery Storage, incluidas las siguientes:
- Tablas estándar de BigQuery
- Instantáneas de tablas
- Tablas de BigLake almacenadas en Cloud Storage
Las siguientes opciones no son compatibles:
- Tablas de BigQuery Omni
- Tablas en las que el tamaño de los datos serializados de las filas individuales supera el tamaño máximo de datos serializados que admite la API de BigQuery Storage Read (128 MB).
- Tablas externas que no son de BigLake, como Hojas de cálculo de Google
Para obtener información sobre cómo generar perfiles de datos de BigQuery, consulta lo siguiente:
- Genera perfiles de datos de BigQuery en un solo proyecto
- Genera perfiles de datos de BigQuery en una organización o una carpeta
Para obtener más información sobre BigQuery, consulta la documentación de BigQuery.
Discovery para Cloud SQL
Cuando generas perfiles de datos de Cloud SQL, se generan perfiles de datos a nivel de proyecto, tabla y columna. Antes de que pueda comenzar la detección, debes proporcionar los detalles de conexión de cada instancia de Cloud SQL que se incluirá en el perfil.
Para obtener información sobre cómo crear perfiles de datos de Cloud SQL, consulta lo siguiente:
- Crea perfiles de datos de Cloud SQL en un solo proyecto
- Genera perfiles de datos de Cloud SQL en una organización o una carpeta
Para obtener más información sobre Cloud SQL, consulta la documentación de Cloud SQL.
Descubrimiento para Cloud Storage
Cuando generas perfiles de datos de Cloud Storage, estos se generan a nivel del bucket. La Protección de datos sensibles agrupa los archivos detectados en clústeres de archivos y proporciona un resumen para cada clúster.
Para obtener información sobre cómo crear perfiles de datos de Cloud Storage, consulta lo siguiente:
- Crea perfiles de los datos de Cloud Storage en un solo proyecto
- Crea perfiles de los datos de Cloud Storage en una organización o una carpeta
Para obtener más información sobre Cloud Storage, consulta la documentación de Cloud Storage.
Discovery para Vertex AI
Cuando generas el perfil de un conjunto de datos de Vertex AI, Sensitive Data Protection genera un perfil de datos de almacén de archivos o un perfil de datos de tabla, según dónde se almacenen tus datos de entrenamiento: Cloud Storage o BigQuery.
Para obtener más información, consulta lo siguiente:
- Descubrimiento de datos sensibles para Vertex AI
- Genera perfiles de los datos de Vertex AI en un solo proyecto
- Genera perfiles de datos de Vertex AI en una organización o carpeta
Para obtener más información sobre Vertex AI, consulta la documentación de Vertex AI.
Detección para otros proveedores de servicios en la nube
Cuando generas perfiles de datos de S3, estos se generan a nivel del bucket. Cuando generas perfiles de los datos de Azure Blob Storage, estos se generan a nivel del contenedor.
En ambos casos, la Protección de datos sensibles agrupa los archivos detectados en clústeres de archivos y proporciona un resumen para cada clúster.
Para obtener más información, consulta lo siguiente:
- Descubrimiento de datos sensibles para datos de Amazon S3
- Crea perfiles de los datos de Azure Blob Storage
Variables de entorno de Cloud Run
El servicio de detección puede detectar la presencia de secretos en las variables de entorno de las revisiones de servicios y funciones de Cloud Run, y enviar los resultados a Security Command Center. No se generan perfiles de datos.
Para obtener más información, consulta Cómo informar secretos en variables de entorno a Security Command Center.
Roles obligatorios para configurar y ver perfiles de datos
En las siguientes secciones, se enumeran los roles de usuario necesarios, categorizados según su propósito. Según la configuración de tu organización, es posible que decidas que diferentes personas realicen diferentes tareas. Por ejemplo, la persona que configura los perfiles de datos puede ser diferente de la persona que los supervisa con regularidad.
Roles necesarios para trabajar con perfiles de datos a nivel de la organización o de la carpeta
Estos roles te permiten configurar y ver perfiles de datos a nivel de la organización o la carpeta.
Asegúrate de que estas funciones se otorguen a las personas adecuadas a nivel de la organización. Como alternativa, tu administrador de Google Cloud puede crear roles personalizados que solo tengan los permisos pertinentes.
| Objetivo | Función predefinida | Permisos relevantes |
|---|---|---|
| Crea una configuración de análisis de descubrimiento y visualiza los perfiles de datos | Administrador de DLP (roles/dlp.admin)
|
|
| Crea un proyecto para usarlo como contenedor de agente de servicio1 | Creador del proyecto (roles/resourcemanager.projectCreator) |
|
| Otorga acceso al descubrimiento2 | Uno de los siguientes:
|
|
| Ver perfiles de datos (solo lectura) | Lector de perfiles de datos de DLP (roles/dlp.dataProfilesReader) |
|
Lector de PPD (roles/dlp.reader) |
|
1 Si no tienes el rol de creador de proyectos (roles/resourcemanager.projectCreator), puedes crear una configuración de análisis, pero el contenedor del agente de servicio que uses debe ser un proyecto existente.
2 Si no tienes el rol de administrador de la organización (roles/resourcemanager.organizationAdmin) o administrador de seguridad (roles/iam.securityAdmin), puedes crear una configuración de análisis. Después de crear la configuración de análisis, alguien de tu organización que tenga uno de estos roles debe otorgar acceso de detección al agente de servicio.
Roles obligatorios para trabajar con perfiles de datos a nivel del proyecto
Estos roles te permiten configurar y ver perfiles de datos a nivel del proyecto.
Asegúrate de que estos roles se otorguen a las personas adecuadas a nivel del proyecto. Como alternativa, tu administrador de Google Cloud puede crear roles personalizados que solo tengan los permisos pertinentes.
| Objetivo | Función predefinida | Permisos relevantes |
|---|---|---|
| Cómo configurar y ver perfiles de datos | Administrador de DLP (roles/dlp.admin)
|
|
| Ver perfiles de datos (solo lectura) | Lector de perfiles de datos de DLP (roles/dlp.dataProfilesReader) |
|
Lector de PPD (roles/dlp.reader) |
|
Configuración de análisis de detección
Una configuración de análisis de descubrimiento (a veces llamada configuración de descubrimiento o configuración de análisis) especifica cómo debe Sensitive Data Protection crear el perfil de tus datos. En incluye los siguientes parámetros de configuración:
- Alcance (organización, carpeta o proyecto) de la operación de descubrimiento
- Tipo de recurso del que se generará el perfil
- Plantillas de inspección para usar
- Frecuencia de análisis
- Subconjuntos específicos de datos que se deben incluir en el descubrimiento o excluir de él
- Acciones que deseas que realice Sensitive Data Protection después del descubrimiento, por ejemplo, a qué servicios Google Cloud publicar los perfiles
- Agente de servicio que se usará para las operaciones de descubrimiento
Para obtener información sobre cómo crear una configuración de análisis de detección, consulta las siguientes páginas:
Descubrimiento de datos de BigQuery
Descubrimiento de datos de Cloud SQL
Descubrimiento de datos de Cloud Storage
Descubrimiento de datos de Vertex AI
Informa los secretos en las variables de entorno de Cloud Run a Security Command Center (no se generan perfiles)
Alcances de la configuración de análisis
Puedes crear una configuración de análisis en los siguientes niveles:
- Organización
- Carpeta
- Proyecto
- Recurso de datos único
A nivel de la organización y la carpeta, si dos o más parámetros de configuración de análisis activos tienen el mismo proyecto en su alcance, Sensitive Data Protection determina qué parámetro de configuración de análisis puede generar perfiles para ese proyecto. Para obtener más información, consulta Cómo anular la configuración de análisis en esta página.
Una configuración de análisis a nivel del proyecto siempre puede generar perfiles del proyecto objetivo y no compite con otras configuraciones a nivel de la organización o la carpeta principal.
Una configuración de análisis de un solo recurso tiene como objetivo ayudarte a explorar y probar la generación de perfiles en un solo recurso de datos.
Ubicación de la configuración de análisis
La primera vez que creas una configuración de análisis, especificas dónde quieres que Sensitive Data Protection la almacene. Todos los parámetros de configuración de análisis posteriores que crees se almacenarán en esa misma región.
Por ejemplo, si creas una configuración de análisis para la carpeta A y la almacenas en la región us-west1, cualquier configuración de análisis que crees más adelante para cualquier otro recurso también se almacenará en esa región.
Los metadatos sobre los datos que se perfilarán se copian en la misma región que la configuración de análisis, pero los datos en sí no se mueven ni se copian. Para obtener más información, consulta Consideraciones sobre la residencia de los datos.
Plantilla de inspección
Una plantilla de inspección especifica qué tipos de información (o infotipos) busca Sensitive Data Protection cuando analiza tus datos. Aquí, proporcionas una combinación de Infotipos integrados y Infotipos personalizados opcionales.
También puedes proporcionar un nivel de probabilidad para reducir lo que la Protección de datos sensibles considera una coincidencia. Puedes agregar conjuntos de reglas para excluir los resultados no deseados o incluir resultados adicionales.
De forma predeterminada, si cambias una plantilla de inspección que usa tu configuración de análisis, los cambios solo se aplican a los análisis futuros. Tu acción no provoca una operación de reprofilado en tus datos.
Si quieres que los cambios en la plantilla de inspección activen operaciones de generación de nuevos perfiles en los datos afectados, agrega o actualiza una programación en la configuración del análisis y activa la opción para generar un nuevo perfil de los datos cuando cambie la plantilla de inspección. Para obtener más información, consulta Frecuencia de generación de perfiles de datos.
Debes tener una plantilla de inspección en cada región en la que tengas datos para generar perfiles. Si deseas usar una sola plantilla para varias regiones, puedes usar una plantilla que se almacene en la región global. Si las políticas de la organización te impiden crear una plantilla de inspección en la región global, debes establecer una plantilla de inspección dedicada para cada región. Para obtener más información, consulta Consideraciones sobre la residencia de datos.
Las plantillas de inspección son un componente fundamental de la plataforma de Sensitive Data Protection. Los perfiles de datos usan las mismas plantillas de inspección que puedes usar en todos los servicios de Sensitive Data Protection. Para obtener más información sobre las plantillas de inspección, consulta Plantillas.
Contenedor del agente de servicio y agente de servicio
Cuando creas un parámetro de configuración de análisis para tu organización o una carpeta, Sensitive Data Protection te solicita que proporciones un contenedor de agente de servicio. Un contenedor de agente de servicio es un proyecto de Google Cloud que Sensitive Data Protection usa para hacer un seguimiento de los cargos facturados relacionados con las operaciones de generación de perfiles a nivel de la organización y de la carpeta.
El contenedor del agente de servicio contiene un agente de servicio, que Sensitive Data Protection usa para generar perfiles de datos en tu nombre. Necesitas un agente de servicio para autenticarte en Sensitive Data Protection y otras APIs. Tu agente de servicio debe tener todos los permisos necesarios para acceder a tus datos y crear perfiles de ellos. El ID del agente de servicio tiene el siguiente formato:
service-PROJECT_NUMBER@dlp-api.iam.gserviceaccount.com
Aquí, PROJECT_NUMBER es el identificador numérico del contenedor del agente de servicio.
Cuando configures el contenedor del agente de servicio, puedes elegir un proyecto existente. Si el proyecto que seleccionas contiene un agente de servicio, Sensitive Data Protection le otorga los permisos de IAM necesarios. Si el proyecto no tiene un agente de servicio, Sensitive Data Protection crea uno y le otorga automáticamente permisos de creación de perfiles de datos.
Como alternativa, puedes hacer que Sensitive Data Protection cree automáticamente el contenedor del agente de servicio y el agente de servicio. Sensitive Data Protection otorga automáticamente permisos de generación de perfiles de datos al agente de servicio.
En ambos casos, si Sensitive Data Protection no puede otorgar acceso a la generación de perfiles de datos a tu agente de servicio, se muestra un error cuando consultas los detalles de la configuración del análisis.
Para las configuraciones de análisis a nivel del proyecto, no necesitas un contenedor de agente de servicio. El proyecto que estás generando perfiles cumple con el propósito del contenedor del agente de servicio. Para ejecutar operaciones de generación de perfiles, Sensitive Data Protection usa el agente de servicio propio de ese proyecto.
Acceso a la generación de perfiles de datos a nivel de la organización o de la carpeta
Cuando configuras la generación de perfiles a nivel de la organización o la carpeta, Sensitive Data Protection intenta otorgar automáticamente acceso a la generación de perfiles de datos a tu agente de servicio. Sin embargo, si no tienes los permisos para otorgar roles de IAM, la Protección de datos sensibles no puede realizar esta acción en tu nombre. Alguien con esos permisos en tu organización, como un administrador de Google Cloud , debe otorgar acceso a la creación de perfiles de datos a tu agente de servicio.
Frecuencia de generación del perfil de datos
Después de crear una configuración de análisis de descubrimiento para un recurso en particular, Sensitive Data Protection realiza un análisis inicial y genera perfiles de los datos incluidos en el alcance de la configuración de análisis.
Después del análisis inicial, la Protección de datos sensibles supervisa continuamente el recurso del que se creó el perfil. Los datos que se agregan al recurso se generan automáticamente poco después de que se agregan.
Frecuencia de reajuste predeterminada
La frecuencia predeterminada de reajuste del perfil difiere según el tipo de descubrimiento de tu configuración de análisis:
- Generación de perfiles de BigQuery: Para cada tabla, espera 30 días y, luego, vuelve a generar el perfil de la tabla si tiene cambios en el esquema, las filas o la plantilla de inspección.
- Generación de perfiles de Cloud SQL: Para cada tabla, espera 30 días y, luego, vuelve a generar el perfil de la tabla si tiene cambios en el esquema o en la plantilla de inspección.
- Generación de perfiles de Vertex AI: Para cada conjunto de datos, espera 30 días y, luego, vuelve a generar el perfil del conjunto de datos si la plantilla de inspección tiene cambios.
Creación de perfiles de almacenamiento de archivos: Para cada almacenamiento de archivos en Google Cloud o en otras nubes, espera 30 días y, luego, vuelve a crear el perfil del almacenamiento de archivos si la plantilla de inspección tiene cambios.
Sensitive Data Protection usa el término almacén de archivos para hacer referencia a un bucket o contenedor de almacenamiento de archivos.
Cómo personalizar la frecuencia de la reprofilación
En la configuración del análisis, puedes personalizar la frecuencia de la creación de perfiles creando una o más programaciones para diferentes subconjuntos de tus datos.
Están disponibles las siguientes frecuencias de cambio de perfil:
- No volver a generar el perfil: Nunca se vuelve a generar el perfil después de que se generan los perfiles iniciales.
- Volver a generar el perfil diariamente: Espera 24 horas antes de volver a generar el perfil.
- Volver a generar el perfil semanalmente: Espera 7 días antes de volver a generar el perfil.
- Volver a generar el perfil mensualmente: Espera 30 días antes de volver a generar el perfil.
Reprofilado según un programa
En la configuración del análisis, puedes especificar si se debe volver a generar el perfil de un subconjunto de datos de forma periódica, independientemente de si los datos sufrieron cambios. La frecuencia que establezcas especificará cuánto tiempo debe transcurrir entre las operaciones de generación de perfiles. Por ejemplo, si estableces la frecuencia en semanal, Sensitive Data Protection genera el perfil de un recurso de datos siete días después de que se generó el último perfil.
Reprofiling on update
En la configuración de análisis, puedes especificar eventos que pueden activar operaciones de nuevo perfilado. Algunos ejemplos de estos eventos son las actualizaciones de plantillas de inspección.
Cuando seleccionas estos eventos, la programación que estableces especifica el tiempo más largo que espera la Protección de datos sensibles para que se acumulen las actualizaciones antes de volver a generar el perfil de tus datos. Si no se producen cambios aplicables (como cambios en el esquema o en la plantilla de inspección) dentro del período especificado, no se vuelve a generar el perfil de los datos. Cuando se produce el siguiente cambio aplicable, se vuelve a generar el perfil de los datos afectados en la siguiente oportunidad, lo que se determina según varios factores (como la capacidad de la máquina disponible o las unidades de suscripción compradas). Luego, la Protección de datos sensibles comienza a esperar a que se acumulen las actualizaciones nuevamente según el programa establecido.
Por ejemplo, supongamos que tu configuración de análisis está establecida para volver a generar el perfil mensualmente cuando se produzca un cambio en el esquema. Los perfiles de datos se crearon por primera vez el día 0. No se producen cambios en el esquema antes del día 30, por lo que no se vuelve a generar el perfil de los datos. El día 35, se produce el primer cambio de esquema. Sensitive Data Protection volverá a generar el perfil de los datos actualizados en la próxima oportunidad. Luego, el sistema espera otros 30 días para que se acumulen las actualizaciones del esquema antes de volver a generar el perfil de los datos actualizados.
Desde el momento en que comienza el cambio de perfil, la operación puede tardar hasta 24 horas en completarse. Si la demora dura más de 24 horas y estás en el modo de precios de suscripción, confirma si tienes capacidad restante para el mes.
Para ver situaciones de ejemplo, consulta los ejemplos de precios de la generación de perfiles de datos.
Para forzar al servicio de descubrimiento a volver a generar el perfil de tus datos, consulta Cómo forzar una operación de volver a generar el perfil.
Generación de perfiles de rendimiento
El tiempo que lleva generar el perfil de tus datos varía según varios factores, incluidos, sin limitaciones, los siguientes:
- Cantidad de recursos de datos para los que se genera el perfil
- Tamaños de los recursos de datos
- En el caso de las tablas, la cantidad de columnas
- Para las tablas, los tipos de datos en las columnas
Por lo tanto, el rendimiento de Sensitive Data Protection en una tarea de inspección o generación de perfiles anterior no indica cómo se desempeñará en tareas futuras de generación de perfiles.
Retención de perfiles de datos
La Protección de datos sensibles conserva la versión más reciente de un perfil de datos durante 13 meses. Cuando Sensitive Data Protection vuelve a generar el perfil de un recurso de datos, el sistema reemplaza los perfiles existentes de ese recurso de datos por perfiles nuevos.
En los siguientes ejemplos, se supone que está vigente la frecuencia de generación de perfiles predeterminada de BigQuery:
El 1 de enero, Sensitive Data Protection genera el perfil de la tabla A. La tabla A no cambia en más de un año, por lo que no se vuelve a perfilar. En este caso, la Protección de datos sensibles conserva los perfiles de datos de la tabla A durante 13 meses antes de borrarlos.
El 1 de enero, Sensitive Data Protection genera el perfil de la tabla A. Durante el mes, alguien de tu organización actualiza el esquema de esa tabla. Debido a este cambio, al mes siguiente, la Protección de datos sensibles vuelve a generar automáticamente el perfil de la tabla A. Los perfiles de datos recién generados reemplazan a los que se crearon en enero.
Para obtener información sobre cómo Sensitive Data Protection cobra por los datos de generación de perfiles, consulta Precios de descubrimiento.
Si deseas conservar los perfiles de datos de forma indefinida o mantener un registro de los cambios que sufren, considera guardarlos en BigQuery cuando configures la generación de perfiles. Tú eliges en qué conjunto de datos de BigQuery guardar los perfiles y controlas la política de vencimiento de la tabla para ese conjunto de datos.
Cómo anular la configuración de análisis
Solo puedes crear una configuración de análisis para cada combinación de alcance y tipo de descubrimiento. Por ejemplo, solo puedes crear una configuración de análisis a nivel de la organización para la creación de perfiles de datos de BigQuery y una configuración de análisis a nivel de la organización para el descubrimiento de secretos. Del mismo modo, solo puedes crear una configuración de análisis a nivel del proyecto para la creación de perfiles de datos de BigQuery y una configuración de análisis a nivel del proyecto para el descubrimiento de secretos.
Si dos o más parámetros de configuración de análisis activos tienen el mismo proyecto y tipo de descubrimiento en su alcance, se aplican las siguientes reglas:
- Entre las configuraciones de análisis a nivel de la organización y de la carpeta, la más cercana al proyecto podrá ejecutar el descubrimiento para ese proyecto. Esta regla se aplica incluso si también existe una configuración de análisis a nivel del proyecto con el mismo tipo de descubrimiento.
- La Protección de datos sensibles trata las configuraciones de análisis a nivel del proyecto de forma independiente de las configuraciones a nivel de la organización y de la carpeta. Una configuración de análisis que crees a nivel del proyecto no puede anular una que crees para una organización o carpeta principal.
Considera el siguiente ejemplo, en el que hay tres configuraciones de análisis activo. Supón que todas estas configuraciones de análisis son para la generación de perfiles de datos de BigQuery.
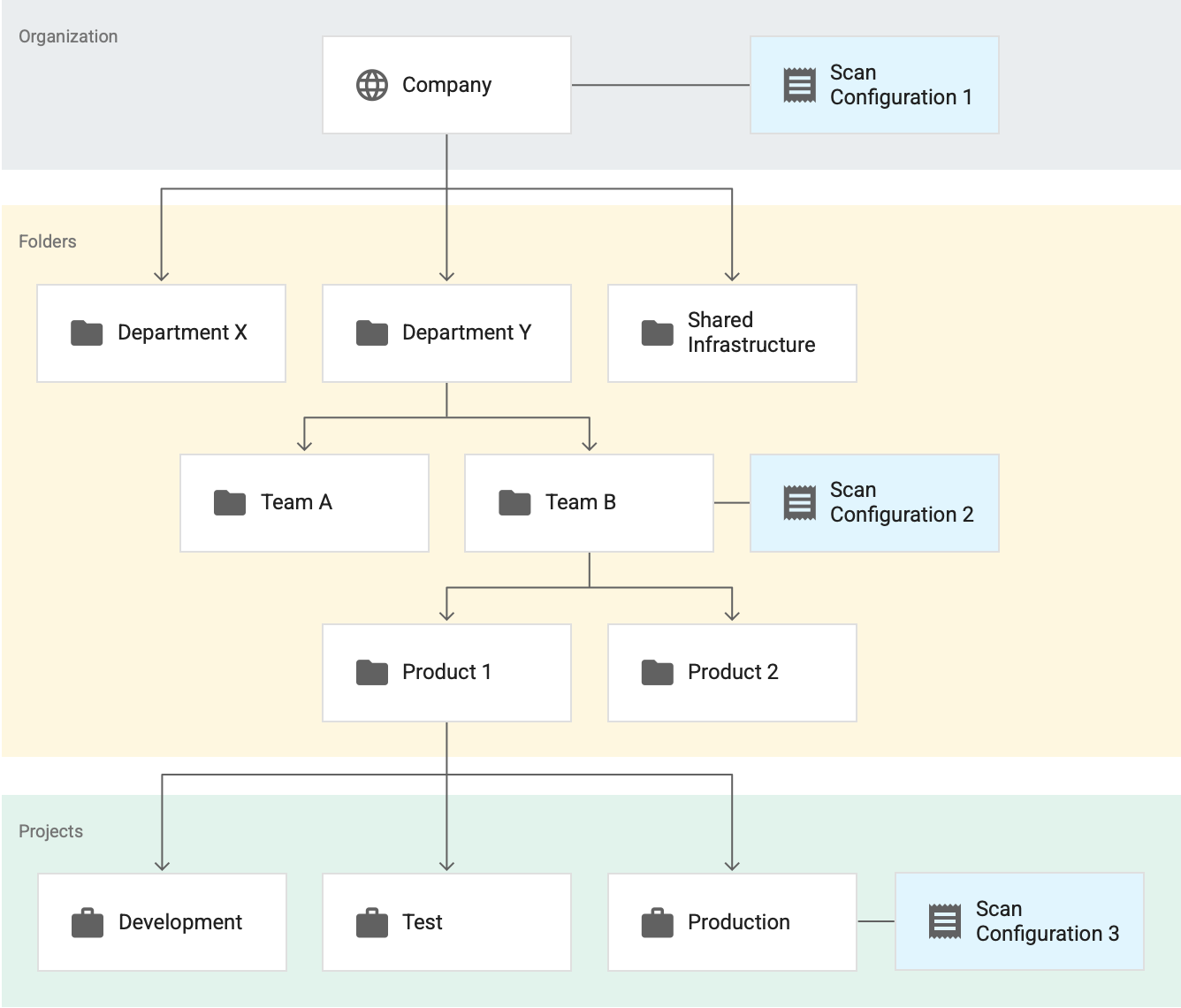
Aquí, la Configuración de análisis 1 se aplica a toda la organización, la Configuración de análisis 2 se aplica a la carpeta Equipo B y al Configuración de análisis 3 se aplica al proyecto de Producción. En este ejemplo:
- La Protección de datos sensibles genera perfiles de todas las tablas en los proyectos que no están en la carpeta Equipo B según la Configuración de análisis 1.
- La Protección de datos sensibles genera perfiles de todas las tablas en los proyectos de la carpeta Equipo B, incluidas las tablas del proyecto Producción, según la Configuración de análisis 2.
- La Protección de datos sensibles genera perfiles de todas las tablas en el proyecto Producción según la configuración de análisis 3.
En este ejemplo, Sensitive Data Protection genera dos conjuntos de perfiles para el proyecto Production: un conjunto para cada una de las siguientes configuraciones de análisis:
- Configuración de análisis 2
- Configuración de análisis 3
Sin embargo, aunque hay dos conjuntos de perfiles para el mismo proyecto, no los ves todos juntos en tu panel. Solo verás los perfiles que se generaron en el recurso (organización, carpeta o proyecto) y la región que estás viendo.
Para obtener más información sobre la jerarquía de recursos de Google Cloud, consulta Jerarquía de recursos.
Instantáneas de perfiles de datos
Cada perfil de datos incluye una instantánea de la configuración del análisis y la plantilla de inspección que se usaron para generarlo. Puedes usar esta instantánea para verificar la configuración que usaste para generar un perfil de datos en particular.
Consideraciones sobre la residencia de los datos
Las consideraciones sobre la residencia de datos difieren según si analizas datos deGoogle Cloud o datos de otros proveedores de servicios en la nube.
Consideraciones sobre la residencia de los datos para los Google Cloud datos
Esta sección solo se aplica al descubrimiento de datos sensibles para los recursos de Google Cloud. Para conocer las consideraciones sobre la residencia de los datos relacionadas con los recursos de otros proveedores de servicios en la nube, consulta Consideraciones sobre la residencia de los datos de otros proveedores de servicios en la nube en esta página.
Sensitive Data Protection se diseñó para admitir la residencia de datos. Si debes cumplir con los requisitos de residencia de datos, ten en cuenta los siguientes puntos:
Plantillas de inspección regionales
Esta sección solo se aplica al descubrimiento de datos sensibles para los recursos de Google Cloud. Para conocer las consideraciones sobre la residencia de los datos relacionadas con los recursos de otros proveedores de servicios en la nube, consulta Consideraciones sobre la residencia de los datos de otros proveedores de servicios en la nube en esta página.
Sensitive Data Protection procesa tus datos en la misma región en la que se almacenan. Es decir, tus datos no salen de su región actual.
Además, una plantilla de inspección solo se puede usar para generar perfiles de datos que residan en la misma región que esa plantilla. Por ejemplo, si configuras el descubrimiento para que use una plantilla de inspección almacenada en la región us-west1, Sensitive Data Protection solo podrá generar perfiles de los datos en esa región.
Puedes establecer una plantilla de inspección dedicada para cada región en la que tengas datos.
Si proporcionas una plantilla de inspección almacenada en la región global, Sensitive Data Protection usará esa plantilla para los datos de las regiones que no tengan una plantilla de inspección dedicada.
En la siguiente tabla, se proporcionan situaciones de ejemplo:
| Situación | Asistencia |
|---|---|
Analiza los datos en la región us con una plantilla de inspección de la región us. |
Admitido |
Analiza los datos de la región global con una plantilla de inspección de la región us. |
No compatible |
Analiza datos en la región us con una plantilla de inspección de la región global. |
Admitido |
Analiza datos en la región us con una plantilla de inspección de la región us-east1. |
No compatible |
Analiza los datos de la región us-east1 con una plantilla de inspección de la región us. |
No compatible |
Analiza datos en la región us con una plantilla de inspección de la región asia. |
No compatible |
Configuración del perfil de datos
Esta sección solo se aplica al descubrimiento de datos sensibles para los recursos de Google Cloud. Para conocer las consideraciones sobre la residencia de los datos relacionadas con los recursos de otros proveedores de servicios en la nube, consulta Consideraciones sobre la residencia de los datos de otros proveedores de servicios en la nube en esta página.
Cuando la Protección de datos sensibles crea perfiles de datos, toma una instantánea de tu configuración de análisis y plantilla de inspección, y las almacena en cada perfil de datos de tabla o perfil de datos de almacén de archivos.
Si configuras el descubrimiento para que use una plantilla de inspección de la región global, Sensitive Data Protection copiará esa plantilla a cualquier región que tenga datos para generar perfiles. Del mismo modo, copia la configuración de análisis en esas regiones.
Considera este ejemplo: El proyecto A contiene la tabla 1. La tabla 1 se encuentra en la región us-west1, la configuración de análisis en la región us-west2 y la plantilla de inspección en la región global.
Cuando Sensitive Data Protection analiza el proyecto A, crea perfiles de datos para la tabla 1 y los almacena en la región us-west1. El perfil de datos de la tabla 1 contiene copias de la configuración del análisis y de la plantilla de inspección que se usaron en la operación de generación de perfiles.
Si no quieres que se copie tu plantilla de inspección a otras regiones, no configures la Protección de datos sensibles para que analice datos en esas regiones.
Almacenamiento regional de perfiles de datos
Esta sección solo se aplica al descubrimiento de datos sensibles para los recursos de Google Cloud. Para conocer las consideraciones sobre la residencia de los datos relacionadas con los recursos de otros proveedores de servicios en la nube, consulta Consideraciones sobre la residencia de los datos de otros proveedores de servicios en la nube en esta página.
La Protección de datos sensibles procesa tus datos en la región o multirregión en la que residen y almacena los perfiles de datos generados en la misma región o multirregión.
Para ver los perfiles de datos en la consola de Google Cloud , primero debes seleccionar la región en la que residen. Si tienes datos en varias regiones, debes cambiar de región para ver cada conjunto de perfiles.
Regiones no admitidas
Esta sección solo se aplica al descubrimiento de datos sensibles para los recursos de Google Cloud. Para conocer las consideraciones sobre la residencia de los datos relacionadas con los recursos de otros proveedores de servicios en la nube, consulta Consideraciones sobre la residencia de los datos de otros proveedores de servicios en la nube en esta página.
Si tienes datos en una región que Sensitive Data Protection no admite, el servicio de descubrimiento omite esos recursos de datos y muestra un error cuando ves los perfiles de datos.
Multirregiones
Sensitive Data Protection trata una multirregión como una sola región, no como una colección de regiones. Por ejemplo, la multirregión us y la región us-west1 se consideran dos regiones separadas en lo que respecta a la residencia de los datos.
Recursos zonales
Sensitive Data Protection es un servicio regional y multirregional, y no distingue entre zonas. En el caso de un recurso zonal compatible, como una instancia de Cloud SQL, los datos se procesan en su región actual, pero no necesariamente en su zona actual. Por ejemplo, si una instancia de Cloud SQL se almacena en la zona us-central1-a, Protección de datos sensibles procesa y almacena los perfiles de datos en la región us-central1.
Para obtener información general sobre las ubicaciones de Google Cloud , consulta Geografía y regiones.
Consideraciones sobre la residencia de los datos de otros proveedores de servicios en la nube
Ten en cuenta lo siguiente cuando planifiques la creación de perfiles de datos de otros proveedores de servicios en la nube:
- Los perfiles de datos se almacenan junto con la configuración del análisis de descubrimiento. En cambio, cuando generas perfiles de datos de Google Cloud , los perfiles se almacenan en la misma región que los datos de los que se generarán los perfiles.
- Si almacenas tu plantilla de inspección en la región
global, se leerá una copia en memoria de esa plantilla en la región en la que almacenes la configuración del análisis de detección. - Tus datos no se modifican. Se lee una copia en memoria de tus datos en la región en la que almacenas la configuración del análisis de detección. Sin embargo, la Protección de datos sensibles no garantiza por dónde pasan los datos después de llegar a Internet pública. Los datos se encriptan con SSL.
Cumplimiento
Para obtener información sobre cómo Sensitive Data Protection maneja tus datos y te ayuda a cumplir con los requisitos de cumplimiento, consulta Seguridad de los datos.
¿Qué sigue?
Lee la entrada de blog de Identidad y seguridad Administración automática de riesgos de datos para BigQuery con la protección de datos sensibles.
Obtén información para estimar el costo de la generación de perfiles de datos.
Obtén información para generar perfiles de datos a nivel de la organización, la carpeta o el proyecto.
Obtén información sobre cómo la Protección de datos sensibles calcula el riesgo de datos y los niveles de sensibilidad cuando crea perfiles de tus datos.
Obtén información para corregir los resultados del descubrimiento.
Obtén más información para solucionar problemas con el generador de perfiles de datos.