このガイドでは、Pub/Sub の信頼性機能について説明します。
Pub/Sub を使う理由
メッセージングのパラダイムとして、publish-subscribe はメッセージのプロデューサーとそれらのメッセージのコンシューマーを分離するように設計されています。プロデューサーは、データをコンシューマーに直接リクエストを送信するのではなく、Pub/Sub などの Pub/Sub サービスにデータをパブリッシュします。このサービスは、サブスクライブしている関心のあるコンシューマーにこれらのメッセージを非同期で配信します。
その結果、このサービスは、データに関心のあるコンシューマーを見つける煩雑さをすべて吸収します。容量に基づいてコンシューマーがデータを受信するレートも管理します。分離することにより、データ プロデューサーは、コンシューマーの行動とは無関係に、低レイテンシで大規模にメッセージを書き込むことができます。
Pub/Sub は、スケーラビリティと信頼性に優れたメッセージ配信を提供します。このサービスの多くは自動的に処理されますが、可用性とパフォーマンスに影響するパブリッシャーとサブスクライバーのさまざまな側面を制御できます。このガイドの残りの部分では、これらの側面について詳しく説明します。
分離
デフォルトでは、Pub/Sub はグローバル サービスです。トピックとサブスクリプションは本質的に特定のリージョンに結び付けられておらず、必要に応じて、リージョン間の Pub/Sub サービス内でメッセージが流れます。グローバル エンドポイント pubsub.googleapis.com を使用すると、パブリッシャーとサブスクライバーは、Pub/Sub が実行されるネットワークに最も近いリージョンに接続します。us-central1-pubsub.googleapis.com などのリージョン エンドポイントや、pubsub.us-central1.rep.googleapis.com などのロケーション エンドポイントを使用すると、パブリッシャーとサブスクライバーは指定されたリージョンの Pub/Sub に接続します。 Google Cloudの外部でパブリッシャーやサブスクライバーを実行する場合、想定されるリージョン間でメッセージが一貫して流れるように、リージョン エンドポイントまたはロケーション エンドポイントを使用するのがベストです。
リージョン分離
単一リージョン外でパブリッシュ / サブスクライブ オペレーションが依存するインフラストラクチャを最小限に抑え、すべてのデータがそのリージョンに分離された状態を維持するには、次の操作を行います。
リージョンごとにトピックを作成します。
Pub/Sub の名前空間はグローバルであり、トピックとサブスクリプションを特定のリージョンに結び付けることはできませんが、すべてのリソースのメタデータはリージョン内のローカル データストアに複製されます。したがって、リソースを作成すると、別のリージョンで問題が発生した場合でも、その構成を使用できます。停止が発生した場合、トピックまたはサブスクリプションの構成の更新がすぐに反映されないことがあります。
グローバル エンドポイントの使用は避けてください。
代わりに、使用可能な場合はリージョン エンドポイントを使用し、リージョン エンドポイントが使用できない場合はロケーション エンドポイントを使用します。リージョン エンドポイントはリージョン分離を強化しますが、まだすべてのリージョンで使用できるわけではありません。
メッセージ ストレージ ポリシーを使用して、
enforceInTransitをTrueに設定します。転送を適用を有効にすると、データはリージョンから離れることはなく、特定のリージョンのトピックに接続するすべてのクライアントが、そのリージョンにメッセージ ストレージ ポリシーを設定します。
このように構成されたトピックを使用すると、すべてのパブリッシュ オペレーションとサブスクライブ オペレーションで、リージョン内のデータのみが書き込みと読み取りの対象になります。単一のリージョンでパブリッシャー、サブスクライバー、Pub/Sub に障害が発生した場合、そのリージョンでのメッセージ配信が停止します。他のリージョンのトピックとサブスクリプションのメッセージ配信は影響を受けません。
トピックとサブスクリプションの管理オペレーションと名前空間もリージョンごとに分離する必要がある場合は、Managed Service for Apache Kafka の使用を検討してください。
フェイルオーバー
リージョン分離が必要ない場合は、Pub/Sub の複数のリージョンにメッセージを効率的に配信する機能を利用して、マルチリージョン フェイルオーバー機能を実現できます。このセクションの残りの部分では、さまざまな種類のフェイルオーバーとデータ冗長性をサポートするために、トピックとサブスクリプションを作成し、パブリッシャーとサブスクライバーを配置する方法について説明します。
デフォルトのフェイルオーバー セマンティクス
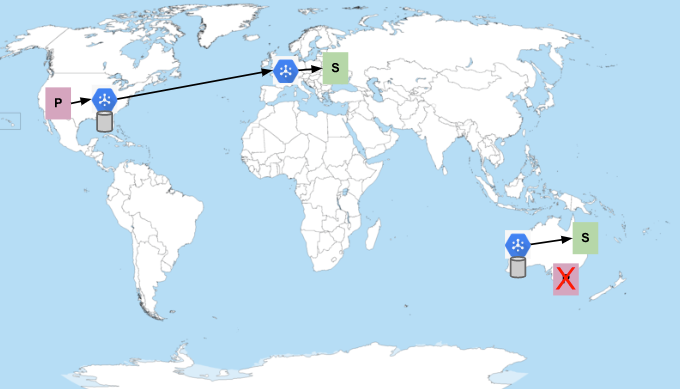
単一のトピックとサブスクリプションがある場合を考えてみましょう。パブリッシャーは米国とオーストラリアのリージョンに、サブスクライバーはヨーロッパとオーストラリアの Google Cloud リージョンにいます。すべてのサブスクライバーにメッセージの受信に十分な容量がある場合、メッセージのフローは次のようになります。
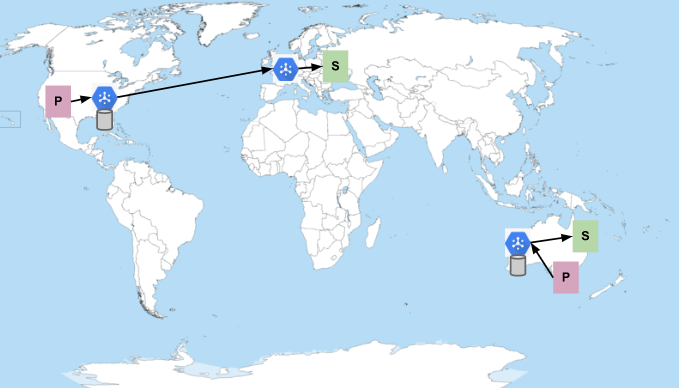
P はパブリッシャーを表し、S はサブスクライバーを表します。青い六角形は Pub/Sub サービスを表します。円柱は、メッセージが保存される場所を表します(メッセージは、パブリッシュされたリージョンの複数のゾーンに常に永続化されます)。Pub/Sub は、サブスクライバーが利用可能な場合、パブリッシュされたのと同じリージョン内でメッセージを送信することを優先します。それ以外の場合は、容量のあるサブスクライバーがいる最も近いネットワーク リージョンにメッセージを送信します。そのため、前の図に示すように、米国で公開されたメッセージはヨーロッパの購読者に配信され、オーストラリア国内で公開されたメッセージはオーストラリア国内に留まります。
以降のセクションでは、さまざまな障害シナリオで発生する事象について説明します。
ヨーロッパのサブスクライバーが使用できない
ヨーロッパのサブスクライバーが拒否されたり、頻繁にクラッシュしたりして、Pub/Sub への接続を維持できないとします。この場合、サービスはオーストラリアのサブスクライバーへのメッセージの配信を開始します。
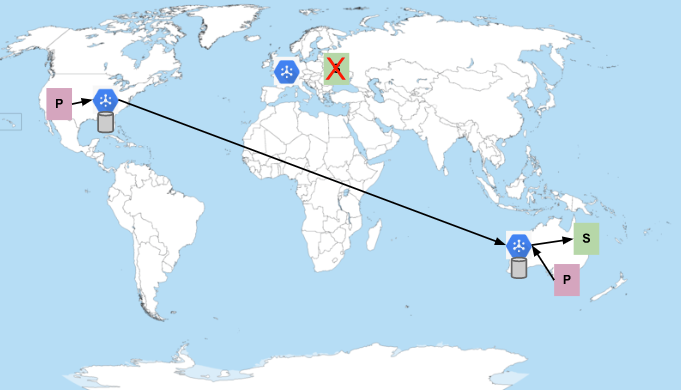
ヨーロッパとオーストラリアのサブスクライバーが使用できない
すべてのサブスクライバーが使用できない場合、Pub/Sub は構成済みのメッセージ保持期間までメッセージを保存します。
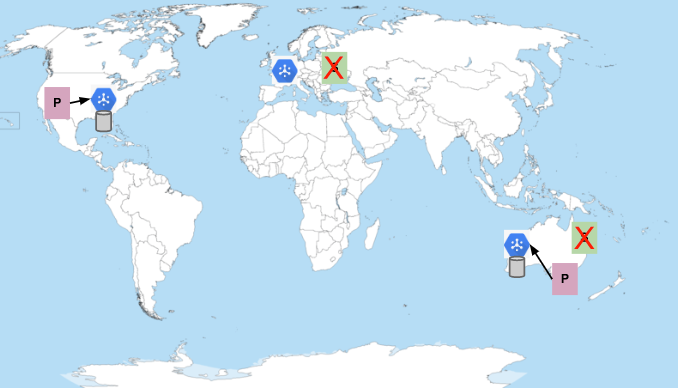
サブスクライバーが再接続されると、停止が構成済みのメッセージ保持期間を超えない限り、メッセージは配信されます。デフォルトでは、サブスクリプション メッセージの保持期間は 7 日間に設定されています。トピックのメッセージ保持を最大 31 日間構成することもできます。想定される最大停止時間または許容できる最大停止時間よりも短いメッセージ保持期間は選択しないでください。
Pub/Sub がヨーロッパで使用できない
まれですが、Pub/Sub 自体が使用できない場合にも対処する場合があります。Pub/Sub が使用できない場合、パブリッシュ リクエストまたはサブスクライブ リクエストで予期しないエラーが長期間発生したり、パブリッシュされたメッセージをサブスクライバーに配信できなくなったりします。たとえば、ヨーロッパのリージョンで Pub/Sub がダウンした場合、サブスクライバーがダウンした場合とほぼ同じシナリオになります。
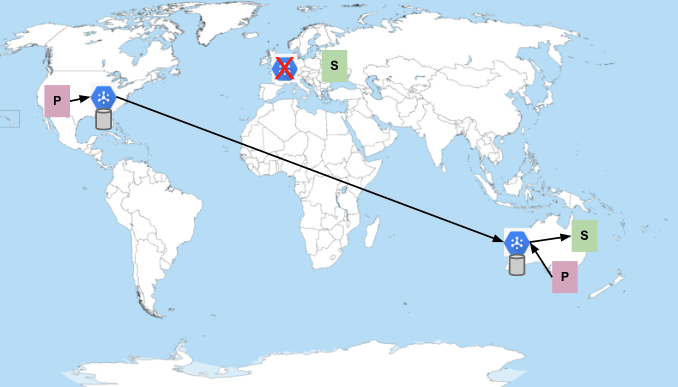
この場合、グローバル エンドポイントを使用している場合でも、ヨーロッパのサブスクライバーは別のリージョンにフェイルオーバーしません。Pub/Sub は、意図的に自動フェイルオーバーを行いません。サブスクライバー自身が Pub/Sub で予期しない問題を発生させ、使用不能になったとします。このような問題は、重大な停止として扱われます。ただし、停止の影響範囲は、サブスクライバーが接続したリージョンに限定できます。サービスで別のリージョンへのフェイルオーバーが許可されている場合、サブスクライバーがそのリージョンで利用不可になる可能性があり、サービス全体でカスケード障害が発生する可能性があります。
オーストラリアのパブリッシャーが使用できない
1 つのリージョンのパブリッシャーが使用できなくなっても、すでにパブリッシュされているメッセージは最も近いサブスクライバーに配信されます。
最終的に、すべてのメッセージがサブスクライバーによって使用され、確認応答されます。Pub/Sub は、メッセージを送信する際に、ネットワーク距離を最小限に抑えようとします。 したがって、ヨーロッパのサブスクライバーに米国で公開されたすべてのメッセージを処理するのに十分な容量がある場合、オーストラリアのリージョンのサブスクライバーはメッセージの受信を停止できます。
Pub/Sub が米国で使用できない
Pub/Sub は、リージョン内の複数のゾーンにメッセージを同期的に書き込みます。したがって、メッセージの配信を防ぐには、ゾーンの停止では不十分です。リージョン全体を使用不可にする必要があります。パブリッシャーがメッセージを送信しているリージョンで Pub/Sub が使用できなくなると、サービスが完全に復元されるまでそのリージョンのメッセージは配信されない可能性があります。
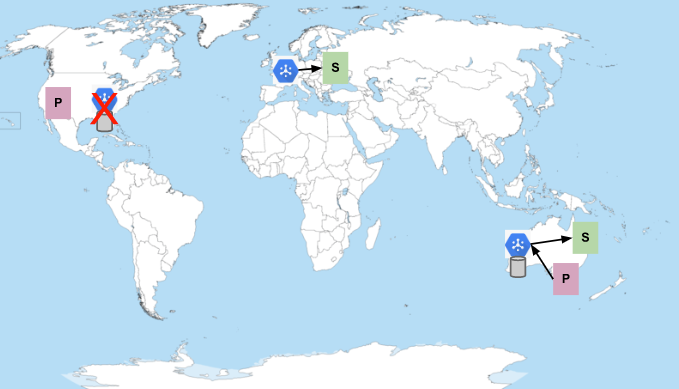
メッセージは、停止期間中遅延しますが、最終的に配信されます(メッセージの保持期間が経過していないと想定)。 サブスクライバーと同様に、米国のパブリッシャーもサービス障害中に別のリージョンにフェイルオーバーしません。この動作により、障害のあるパブリッシャーまたはサブスクライバーが原因でリージョン間で連鎖的な障害が発生する可能性を回避できます。
お客様が制御するフェイルオーバーと冗長性
Pub/Sub のデフォルトのフェイルオーバー セマンティクスでは、途中のどこかで停止が発生した場合に、メッセージが常にパブリッシャーからサブスクライバーに流れることを完全に保証できないことがあります。サービス停止は、クライアントや、パブリッシャーまたはサブスクライバーが稼働するサービス、ネットワーク、さらには Pub/Sub 自体においても、さまざまな場所で発生する可能性があります。 このような停止に対するサービスの復元性が必要な場合は、独自の冗長性を実装する必要があります。通常、これらの冗長性には、パブリッシャーとサブスクライバーのクライアントの複数のインスタンスを使用することがあり、それぞれが異なるロケーション エンドポイントを使用します。
ゾーンまたはリージョンという 2 つの異なる影響範囲に対して復元力を設定できます。 それぞれの設定オプションは次のとおりです。
ゾーンの復元性
Pub/Sub には、ゾーン間のレプリケーションが組み込まれています。サービス自体に影響を与えるシングルゾーンの停止に対処するために、特別な手順を行う必要はありません。ただし、クライアントまたはネットワークの停止に対する復元力を確保するには、リージョン内の複数のゾーンで十分な容量を持つパブリッシャーとサブスクライバーを実行することをおすすめします。1 つのゾーンがダウンした場合、他のゾーンのクライアントはトラフィックを取得してメッセージを処理できます。バグが発生しても、手つかずの他のゾーンがメッセージの処理を継続できるように、これらのクライアントに対する変更を同時に公開しないことをおすすめします。
リージョンの復元性
リージョンの障害に対する耐障害性を確保するには、パブリッシャーとサブスクライバーに追加の冗長性を設定します。複数のリージョンでパブリッシャーとサブスクライバーを実行して、クライアントまたはネットワークの停止の可能性に対処できます。
リージョンで Pub/Sub の障害が発生した場合に備えて復元力を確保するには、このような停止に対処するためのフェイルオーバー メカニズムを用意する必要があります。可能なアプローチは、エンドツーエンドのメッセージ配信レイテンシと費用のトレードオフです。
費用が問題にならない場合は、レイテンシを最小限に抑えるために、常に異なるリージョンで同時にパブリッシュとサブスクライブを行うのが最適な戦略です。まず、冗長性が必要なリージョンの数を選択します。 次に、厳密には必要ありませんが、これらの各リージョンにトピックとサブスクリプションを設定できます。
各パブリッシャーは、リージョンと同じ数のパブリッシャー クライアントを作成し(リージョンごとに 1 つずつ)、異なるロケーション エンドポイントを使用して、メッセージが別々のリージョンに送られるようにします。別々のトピックを使用する場合、各パブリッシャー クライアントは対応するリージョンごとのトピックにパブリッシュする必要があります。メッセージごとに、パブリッシャーは各クライアントにパブリッシュします。冗長なパブリッシュを使用すると、いずれかのパブリッシュが失敗しても、パブリッシュを再試行する必要はありません。
同様に、各サブスクライバーは、リージョンと同じ数のサブスクライバー クライアントを作成し(リージョンごとに 1 つずつ)、ロケーション エンドポイントを使用して別のリージョンに接続します。リージョンごとに異なるサブスクリプションを使用する場合は、各サブスクライバー クライアントが対応するサブスクリプションを使用する必要があります。パブリッシャーとサブスクライバーに使用されるリージョンは、必ずしも同じである必要はありません。サブスクライバーは、3 つのサブスクリプション全体でメッセージを受信して処理します。
この設定には、いくつかの重要な機能と要件があります。
- シングルリージョンの停止は、すでにパブリッシュされたメッセージの処理や、停止中にパブリッシュされたメッセージの処理に影響しません。メッセージは複数のリージョンにパブリッシュされているため、1 つのリージョンがダウンしても他のリージョンで使用できます。停止中は、影響を受けるリージョンでパブリッシュ呼び出しが失敗しますが、他のリージョンでは成功します。
- メッセージが流れるリージョンのいずれかが使用可能である限り、メッセージ処理のレイテンシは影響を受けません。
- メッセージ処理はべき等である必要があります。すべてのメッセージが複数回配信されるため、メッセージ処理は重複に対して復元力がある必要があります。リージョンが停止した場合、これらの重複の一部は、メッセージが最初に配信されたときよりもはるかに遅れて配信されることがあります。これらに重複は、停止が発生していない別のリージョンで発生している可能性があります。
このような種類の冗長性を実行することにより、いかなる種類の停止に対しても高い復元力を実現できます。Pub/Sub に依存し、最高の可用性を必要とする内部 Google サービスには、この設定が推奨されます。ただし、この設定では、メッセージ配信の費用が使用するリージョン数の倍数となるというトレードオフがあります。リージョン間で移動する必要があるメッセージについては、リージョン間のネットワーク使用量の追加費用も発生します。
冗長性のもう 1 つのアプローチは、リクエストが失敗した場合や、パブリッシャーからサブスクライバーにメッセージが想定どおりに流れない場合にのみフェイルオーバーすることです。このシナリオでは、ロケーション エンドポイントを介してパブリッシャーとサブスクライバーを転送するプライマリ リージョンがあります。前述のとおり、これらのリージョンは同じである必要はありません。また、プライマリ リージョンが使用できない場合に使用されるパブリッシャーとサブスクライバーのフォールバック リージョンも用意されています。
パブリッシャーは、リクエストが正常に送信された場合(ロケーション エンドポイントを介して)プライマリ リージョンにのみパブリッシュします。リージョンがダウンしていると判断された場合は、パブリッシャーは代わりにフォールバック リージョンへの公開を開始します。リージョンがダウンしていることを確認してフェイルオーバーを行うには、次の 2 つの方法があります。これは手動プロセスで行うことができ、ニュース メディアで構成が動的に更新されます。パブリッシャーは、パブリッシュ リクエストのエラー率が十分に高い場合は、構成を自ら更新することもできます。
サブスクライバーは、常にロケーション エンドポイントを介してプライマリ リージョンに接続する必要があります。次の 1 つ以上のトリガーを使用して、フォールバック リージョンを使用できることをサブスクライバーに通知できます。
- 常にフォールバック リージョンにサブスクライブする。この場合、サブスクライバーはプライマリ リージョンとフォールバック リージョンの両方への接続を常に維持します。パブリッシャーとサブスクライバーの両方のプライマリとフォールバックに同じリージョンを使用できます。この場合、パブリッシャーがフェイルオーバーした場合にのみ、サブスクライバーはバックアップ リージョンを介してメッセージを受信する必要があります。
- 構成を通じて、サブスクライバーをフォールバック リージョンに手動で検出して切り替えます。停止が検出された場合は、フォールバック リージョンにフェイルオーバーし、停止が収まったらプライマリ リージョンに戻ることができます。
- サブスクライバー エラーでフェイルオーバーします。サブスクライバー リクエストでエラーが返された場合、これをフォールバック リージョンにフェイルオーバーする必要があることを示すものとして使用できます。Pub/Sub クライアント ライブラリは、一時的なエラーが発生するとストリーミング プルリクエストを内部的に再試行するため、予期しないエラーが長期間発生していることを検出できない場合があります。また、通常のオペレーション中であっても、ストリーミング プルのエラー率は 100% になることが想定されています。
- サブスクライバーがメッセージを受信せずに、予期せず長時間経過した場合にフェイルオーバーする。メッセージが継続的にパブリッシュされると仮定すると、サブスクライバーは常にメッセージを受信できます。サブスクライブがメッセージを長期に渡ってしない場合、プライマリ リージョンの Pub/Sub にサブスクライブ側の問題がある可能性があります。これは、フォールバック リージョンにフェイルオーバーすることで修正されます。
4 つのオプションのうち、最初のオプションが理想的です。サブスクライバーの接続にメッセージが流れない場合、サブスクライバーの接続に料金は発生しません。唯一の費用は、サブスクライバー クライアント ライブラリの追加インスタンスのフットプリントですが、これはごくわずかである場合があります。また、リージョン割り当てごとのオープン ストリーミング pull 接続数にも注意する必要があります。
この 2 番目のモデルの利点は、メッセージが 1 回だけパブリッシュされるため、Pub/Sub の費用に乗数が含まれないことです。ただし、この方法には、特定のタイプの停止の場合、停止前にパブリッシュされたメッセージが停止の解決後に利用可能になるというトレードオフがあります。使用できないリージョンに保存されているメッセージは、接続場所に関係なく、サブスクライバーに配信できない場合があります。停止中にフォールバック リージョンにパブリッシュされたメッセージは使用可能になる可能性があります。また、パブリッシャーまたはサブスクライバーでエラー率が増加し、利用できない期間が発生する可能性があります。これは、停止の検出に使用される方法と、フォールバック リージョンにフェイルオーバーする時間によって異なります。
どのオプションを選択する場合でも、Pub/Sub の機能との相互作用に注意してください。順序指定配信と1 回限りの配信は、どちらもリージョン内で保証を提供します。たとえば、フェイルオーバーの冗長性技術を使用する場合、メッセージ配信は、同じリージョンにパブリッシュされるメッセージに対してのみ保証されます。メッセージが最初にプライマリー リージョンにパブリッシュされていた場合でも、プライマリ リージョンにメッセージがパブリッシュされる前に、サブスクライバーは、フォールバック リージョンにパブリッシュされたメッセージを受信できます。
パブリッシャーのファインチューニング
どのフェイルオーバー オプションを選択した場合でも、パブリッシャー内で実行する追加のチューニング手順があります。パブリッシャーの動作を調整することで、高負荷時のパフォーマンスを最適化できます。メッセージのバッチ処理は、コストとレイテンシをトレードオフする方法ですが、信頼性にはそれほど重要でないため、ここでは説明しません。代わりに、再試行設定やフロー制御設定など、信頼性を調整するうえで役立つ他のパラメータに注目してください。
パブリッシュは、ネットワーク使用不能などの一時的なものや、権限の変更などユーザーの操作が必要なものなど、さまざまな理由で失敗する可能性があります。Pub/Sub クライアント ライブラリは、再試行設定で指定されたパラメータを使用して、一時的なエラーを再試行します。これらの設定は、一時的な理由で失敗したパブリッシュ RPC の再試行における指数バックオフの動作を制御します。通常、デフォルト設定はほとんどのシナリオで適切に機能しますが、これらの値を調整する必要がある場合もあります。
調整する可能性が高い 2 つのプロパティは、初期 RPC タイムアウトと合計タイムアウトです。初期 RPC タイムアウトは、最初のパブリッシュ RPC が完了するまでの時間です。RPC が失敗またはタイムアウトした場合、リクエストの合計数または合計タイムアウトを超えるまで、より長いタイムアウトで別の RPC が試行されます。
パブリッシャーがネットワークで制約されている場合や、Pub/Sub を実行する最寄りの Google Cloud データセンターから離れている場合は、初期タイムアウトを調整できます。ネットワーク制約は、パブリッシャーが実行されているマシンのスループットの制限である場合や、同じマシンで実行されている他のサービスがネットワークを大量に使用していることが原因である場合があります。タイムアウトの設定が短すぎると、最初の RPC が繰り返し失敗し、パブリッシュに成功するまでの試行が多くなります(タイムアウトが長くなります)。再試行が繰り返し必要になると、公開のレイテンシが増加します。このような状況では、初期タイムアウトを増やすと、公開が速くなる可能性があります。
ネットワーク接続の信頼性が低い場合は、合計タイムアウトと初期タイムアウトを増やすと解決できることがあります。合計タイムアウトを長くすると、パブリッシュ RPC が常に完了するための時間が長くなります。パブリッシュ RPC が期限超過エラーで一貫して失敗する場合は、これらの値の調整を検討してください。
連続した期限超過エラーは、パブリッシャーのフロー制御を調整する必要があることを示している場合もあります。これらの設定により、パブリッシャーは、Pub/Sub に送信されるメッセージの増加につながる受信トラフィックの急増に対応できます。送信リクエストが大幅に増加すると、パブリッシャーの CPU、メモリ、ネットワーク容量が過負荷になる可能性があります。パブリッシュが過負荷状態になると、タイムアウト前にパブリッシュ リクエストやレスポンスを処理できなくなります。これにより、公開リクエストがさらに増え、最終的に合計タイムアウトに達します。パブリッシャー フロー制御では、パブリッシュ リクエストからのレスポンスのない未処理のメッセージまたはバイト数が制限されます。このようにリクエスト数を制限すると、スパイクが発生した場合でも、リソース使用率を管理可能なレベルに維持できます。パブリッシャーの運用方法によっては、パブリッシュで以降のリクエストをブロックできるようにすることで、以降のパブリッシュ RPC が容量を待機できるようにすることができます。また、容量に達したときにフロー制御でエラーを返すようにして、サービスの呼び出し元にプッシュバックすることもできます。パブリッシャー クライアント ライブラリが上限超過の動作でどのように応答するかを構成します。
チャンネル登録者の微調整
確実に動作させるには、サブスクライバーの調整が必要になることもあります。パブリッシャーと同様に、サブスクライバーのフロー制御の設定を調整して、サブスクライバーが過負荷にならないようにすることができます。サブスクライバー クライアント ライブラリはストリーミング プルを使用します。クライアントがサーバーへの永続的なストリームを開き、サーバーはメッセージが利用可能になるとメッセージを送信します。パブリッシュされたメッセージが大幅に増加した場合、サブスクライバーは処理できる以上のメッセージを受信する可能性があります。フロー制御が有効になっている場合、クライアントに未確認のメッセージの数が制限されます。これにより、同時に処理されるメッセージの数が減少し、長期間にわたって処理を分散させます。負荷の分散により、サブスクライバーをメッセージ処理に影響を与えるリソースの制限内にとどまらせることができます。これによりメッセージを処理できなくなるカスケード効果が発生する可能性があります。
処理するデータ量の急増が最終的に収まることが予想される場合は、フロー制御のみで十分です。使用率の増加によってトラフィックが時間とともに増加する場合、フロー制御によってサブスクライバーを保護します。ただし、バックログが継続的に増加し、メッセージ保持期間が経過する前にメッセージを配信できなくなる可能性があります。このような場合は、未確認メッセージの増加に対応してより多くのサブスクライバーを起動するように自動スケーリングを設定することもできます。この設定方法は、サブスクライバーに使用しているコンピューティング プラットフォームによって異なります。たとえば、Compute Engine の自動スケーラーを使用すると、未配信メッセージの数などの指標に基づいてスケーリングできます。自動スケーリングとフロー制御の両方を使用すると、メッセージ スループットでの他の短期的な急増や多くのコンピューティング能力を必要とする長期的な増加に対しても、サブスクライバーの復元力を確保できます。Pub/Sub 指標をスケーリング シグナルとして使用する際のベスト プラクティスに沿って操作してください。
安全なデプロイのためにスナップショットとシークを使用する
通常、メッセージ損失は致命的な事態です。Pub/Sub では、パブリッシュされたすべてのメッセージについて、少なくとも 1 回の配信が行われます。ただし、これらのメッセージの正しい処理はサブスクライバーの動作に依存します。メッセージが正常に確認応答されると、Pub/Sub はメッセージを再配信しません。したがって、デプロイする新しいサブスクライバー コードでバグが発生し、メッセージが正しく処理されなかった場合、サブスクライバーによってメッセージが失われる可能性があります。 Pub/Sub には、サブスクライバーのバグが発生した場合でも、すべてのメッセージを正しく処理できるようにするスナップショットとシーク機能があります。
すべてのサブスクライバー デプロイのパターンは次のとおりです。
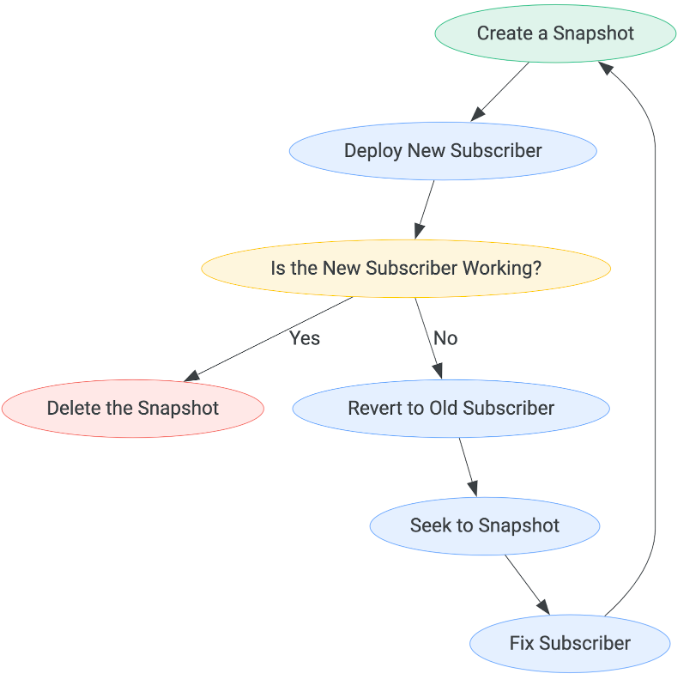
新しいサブスクライバーが機能しているかどうかを判断するまでの待機時間は、ユースケースによって異なる場合があります。手順のフローを終了できるのは、サブスクライバーが動作していると判断された場合のみです。この時点で、スナップショットを削除できます。
スナップショットとシークの使用は、非本番環境でのソフトウェアの初回実行と本番環境への段階的なデプロイに関するベスト プラクティスに代わるものではありません。これらは、データ処理の信頼性を確保するための、保護強化策を提供するものです。トレードオフは、スナップショットまでシークすると、サブスクライバーが処理したメッセージが重複して配信される可能性があることです。ただし、Pub/Sub には少なくとも 1 回配信のセマンティクスがあるため、サブスクライバーはすでにメッセージの再配信に対して復元性を備えています。