You can use the Google Cloud console or the Cloud Monitoring API to monitor Pub/Sub.
This document shows you how to monitor your Pub/Sub usage in the Google Cloud console using Monitoring.
If you want to view metrics from other Google Cloud resources in addition to Pub/Sub metrics, use Monitoring.
Otherwise, you can use the monitoring dashboards provided within Pub/Sub. See Monitor topics and Monitor subscriptions.
For best practices about using metrics in your autoscaling, see Best practices for using Pub/Sub metrics as a scaling signal.
Before you begin
Before you use Monitoring, ensure that you've prepared the following:
A Cloud Billing account
A Pub/Sub project with billing enabled
One way to ensure that you've obtained both is to complete the Quickstart using the Cloud console.
View an existing dashboard
A dashboard lets you view and analyze data from different sources in the same context. Google Cloud provides both predefined and custom dashboards. For example, you can view a predefined Pub/Sub dashboard or create a custom dashboard that displays metric data, alerting policies, and log entries related to Pub/Sub.
To monitor your Pub/Sub project by using Cloud Monitoring, perform the following steps:
In the Google Cloud console, go to the Monitoring page.
Select the name of your project if it is not already selected at the top of the page.
Click Dashboards from the navigation menu.
In the Dashboards overview page, create a new dashboard or select the existing Pub/Sub dashboard.
To search for the existing Pub/Sub dashboard, in the filter for All Dashboards, select the Name property and enter
Pub/Sub.
For more information on how to create, edit, and manage a custom dashboard, see Manage custom dashboards.
View a single Pub/Sub metric
To view a single Pub/Sub metric by using the Google Cloud console, perform the following steps:
In the Google Cloud console, go to the Monitoring page.
In the navigation pane, select Metrics explorer.
In the Configuration section, click Select a metric.
In the filter, enter
Pub/Sub.In Active resources, select Pub/Sub Subscription or Pub/Sub Topic.
Drill down to a specific metric and click Apply.
The page for a specific metric opens.
You can learn more about the monitoring dashboard by reading the Cloud Monitoring documentation.
View Pub/Sub metrics and resource types
To see what metrics Pub/Sub reports to Cloud Monitoring, see the Pub/Sub metrics list in the Cloud Monitoring documentation.
To see the details for the
pubsub_topic,pubsub_subscription, orpubsub_snapshotmonitored resource types, see Monitored resource types in the Cloud Monitoring documentation.
Access the PromQL editor
Metrics Explorer is an interface within Cloud Monitoring designed for exploring and visualizing your metrics data. Within Metrics Explorer, you can use Prometheus Query Language (PromQL) to query and analyze your Pub/Sub metrics.
To access the code editor and query Cloud Monitoring metrics with PromQL in Metrics Explorer, see Use the code editor for PromQL.
For example, you can input a PromQL query to monitor the count of messages sent to a specific subscription over a rolling 1-hour period:
sum(
increase({
"__name__"="pubsub.googleapis.com/subscription/sent_message_count",
"monitored_resource"="pubsub_subscription",
"project_id"="your-project-id",
"subscription_id"="your-subscription-id"
}[1h])
)
Monitor quota usage
For a given project, you can use the IAM & Admin Quotas dashboard to view current quotas and usage.
You can view your historical quota usage by using the following metrics:
These metrics use the
consumer_quota monitored
resource type. For more quota-related metrics, see the
Metrics list.
For example, the following PromQL query creates a chart with the fraction of publisher quota being used in each region:
sum by (quota_metric, location) (
rate({
"__name__"="serviceruntime.googleapis.com/quota/rate/net_usage",
"monitored_resource"="consumer_quota",
"service"="pubsub.googleapis.com",
"quota_metric"="pubsub.googleapis.com/regionalpublisher"
}[${__interval}])
)
/
(max by (quota_metric, location) (
max_over_time({
"__name__"="serviceruntime.googleapis.com/quota/limit",
"monitored_resource"="consumer_quota",
"service"="pubsub.googleapis.com",
"quota_metric"="pubsub.googleapis.com/regionalpublisher"
}[${__interval}])
) / 60 )
If you anticipate your usage exceeding the default quota limits, create alerting policies for all the relevant quotas. These alerts fire when your usage reaches some fraction of the limit. For example, the following PromQL query triggers an alerting policy when any Pub/Sub quota exceeds 80% usage:
sum by (quota_metric, location) (
increase({
"__name__"="serviceruntime.googleapis.com/quota/rate/net_usage",
"monitored_resource"="consumer_quota",
"service"="pubsub.googleapis.com"
}[1m])
)
/
max by (quota_metric, location) (
max_over_time({
"__name__"="serviceruntime.googleapis.com/quota/limit",
"monitored_resource"="consumer_quota",
"service"="pubsub.googleapis.com"
}[1m])
)
> 0.8
For more customized monitoring and alerting on quota metrics, see Using quota metrics.
See Quotas and limits for more information about quotas.
Maintain a healthy subscription
To maintain a healthy subscription, you can monitor several subscription properties using Pub/Sub-provided metrics. For example, you can monitor the volume of unacknowledged messages, the expiration of message acknowledgment deadlines, and so on. You can also check whether your subscription is healthy enough to achieve a low message delivery latency.
Refer to the next sections to get more details about the specific metrics.
Monitor message backlog
To ensure that your subscribers are keeping up with the flow of messages, create a dashboard. The dashboard can show the following backlog metrics, aggregated by resource, for all your subscriptions:
Unacknowledged messages (
subscription/num_unacked_messages_by_region) to see the number of unacknowledged messages.Oldest unacknowledged message age (
subscription/oldest_unacked_message_age_by_region) to see the age of the oldest unacknowledged message in the backlog of the subscription.Delivery latency health score (
subscription/delivery_latency_health_score) to check the overall subscription health in relation to delivery latency. For more information about this metric, see the relevant section of this document.
Create alerting policies that trigger when these values are outside of the acceptable range in the context of your system. For instance, the absolute number of unacknowledged messages is not necessarily meaningful. A backlog of a million messages might be acceptable for a million message-per-second subscription, but unacceptable for a one message-per-second subscription.
Common backlog issues
| Symptoms | Problem | Solutions |
|---|---|---|
Both the oldest_unacked_message_age_by_region and
num_unacked_messages_by_region are growing in tandem. |
Subscribers not keeping up with message volume |
|
If there's a steady, small backlog size combined with a steadily
growing oldest_unacked_message_age_by_region, there may be a few messages that cannot be processed. |
Stuck messages |
|
The oldest_unacked_message_age_by_region exceeds the subscription
message retention duration. |
Permanent data loss |
|
Monitor delivery latency health
In Pub/Sub, delivery latency is the time it takes for a published
message to be delivered to a subscriber.
If your message backlog is increasing, you can use the Delivery latency health
score (subscription/delivery_latency_health_score) to check which factors are contributing to an increased latency.
This metric measures the health of a single subscription over a rolling 10-minute window. The metric provides insight into the following criteria, which are necessary for a subscription to achieve consistent low latency:
Negligible seek requests.
Negligible negatively acknowledged messages (nacked) messages.
Negligible expired message acknowledgment deadlines.
Consistent acknowledgment latency less than 30 seconds.
Consistent low utilization, meaning that the subscription consistently has adequate capacity to process new messages.
The Delivery latency health score metric reports a score of either 0 or 1 for each of the specified criteria. A score of 1 denotes a healthy state and a score of 0 denotes an unhealthy state.
Seek requests: If the subscription had any seek requests in the last 10 minutes, the score is set to 0. Seeking a subscription might cause old messages to be replayed long after they were first published, giving them an increased delivery latency.
Negatively acknowledged (nacked) messages: If the subscription had any negative acknowledgment (nack) requests in the last 10 minutes, the score is set to 0. A negative acknowledgment causes a message to be redelivered with an increased delivery latency.
Expired acknowledgment deadlines: If the subscription had any expired acknowledgment deadlines in the last 10 minutes, the score is set to 0. Messages whose acknowledgment deadline expired are redelivered with an increased delivery latency.
Acknowledgment latencies: If the 99.9th percentile of all acknowledgment latencies over the past 10 minutes was ever greater than 30 seconds, the score is set to 0. A high acknowledgment latency is a sign that a subscriber client is taking an abnormally long time to process a message. This score could imply a bug or some resource constraints on the subscriber client side.
Low utilization: Utilization is calculated differently for each subscription type.
StreamingPull: If you do not have enough streams open, the score is set to 0. Open more streams to ensure you have adequate capacity for new messages.
Push: If you have too many messages outstanding to your push endpoint, the score is set to 0. Add more capacity to your push endpoint so you have capacity for new messages.
Pull: If you do not have enough outstanding pull requests, the score is set to 0. Open more concurrent pull requests to ensure you're ready to receive new messages.
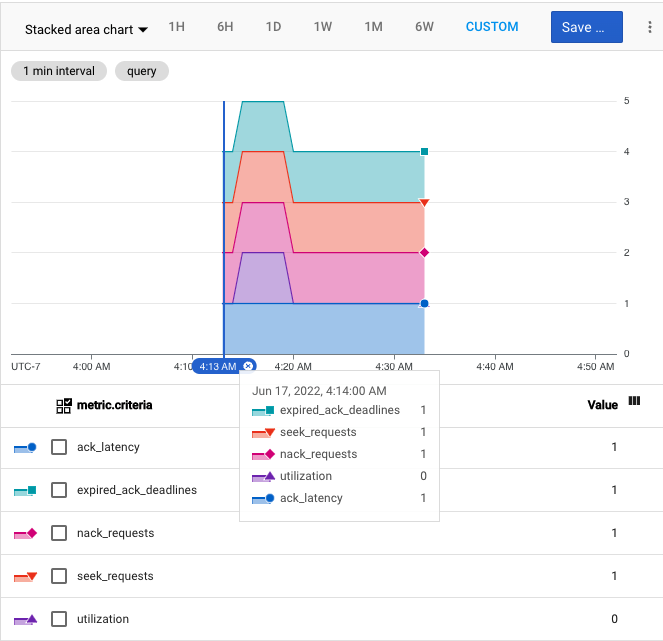
To view the metric, in Metrics explorer, select the Delivery latency health score metric for the Pub/Sub subscription resource type. Add a filter to select just one subscription at a time. Select the Stacked area chart and point to a specific time to check the criteria scores for the subscription for that point in time.
The following is a screenshot of the metric plotted for a one-hour period using a stacked area chart. The combined health score goes up to 5 at 4:15 AM, with a score of 1 for each criterion. Later, the combined score decreases to 4 at 4:20 AM, when the utilization score drops down to 0.
PromQL provides an expressive, text-based interface to Cloud Monitoring time-series data. The following PromQL query creates a chart to measure the delivery latency health score for a subscription.
sum_over_time(
{
"__name__"="pubsub.googleapis.com/subscription/delivery_latency_health_score",
"monitored_resource"="pubsub_subscription",
"subscription_id"="$SUBSCRIPTION"
}[${__interval}]
)
Monitor acknowledgment deadline expiration
In order to reduce message delivery latency, Pub/Sub allows subscriber clients a limited amount of time to acknowledge (ack) a given message. This time period is known as the ack deadline. If your subscribers take too long to acknowledge messages, the messages are redelivered, resulting in the subscribers seeing duplicate messages. This redelivery can happen for various reasons:
Your subscribers are under-provisioned (you need more threads or machines).
Each message takes longer to process than the message acknowledgment deadline. Cloud Client Libraries generally extend the deadline for individual messages up to a configurable maximum. However, a maximum extension deadline is also in effect for the libraries.
Some messages consistently crash the client.
You can measure the rate at which subscribers miss the ack deadline. The specific metric depends on the subscription type:
Pull and StreamingPull:
subscription/expired_ack_deadlines_countPush:
subscription/push_request_countfiltered byresponse_code != "success"
Excessive ack deadline expiration rates can result in costly inefficiencies in your system. You pay for every redelivery and for attempting to process each message repeatedly. Conversely, a small expiration rate (for example, 0.1–1%) might be healthy.
Monitor message throughput
Pull and StreamingPull subscribers might receive batches of messages in each pull response; push subscriptions receive a single message in each push request. You can monitor the batch message throughput being processed by your subscribers with these metrics:
Pull:
subscription/pull_request_count(note that this metric may also include pull requests which returned with no messages)StreamingPull:
subscription/streaming_pull_response_count
You can monitor the individual or unbatched message throughput being
processed by your subscribers with the metric
subscription/sent_message_count
filtered by the delivery_type label.
The following PromQL query gives you a time-series chart showing the total number
of messages sent to a specific Pub/Sub subscription over a
rolling 10-minute period. Replace the placeholder values for $PROJECT_NAME and
$SUBSCRIPTION_NAME with your actual project and topic identifiers.
sum(
increase({
"__name__"="pubsub.googleapis.com/subscription/sent_message_count",
"monitored_resource"="pubsub_subscription",
"project_id"="$PROJECT_NAME",
"subscription_id"="$SUBSCRIPTION_NAME"
}[10m])
)
Monitor push subscriptions
For push subscriptions, monitor these metrics:
subscription/push_request_countGroup the metric by
response_codeandsubscription_id. Since Pub/Sub push subscriptions use response codes as implicit message acknowledgments, it's important to monitor push request response codes. Because push subscriptions exponentially back off when they encounter timeouts or errors, your backlog can grow quickly based on how your endpoint responds.Consider setting an alert for high error rates since these rates lead to slow delivery and a growing backlog. You can create a metric filtered by response class. However, push request counts are likely to be more useful as a tool for investigating the growing backlog size and age.
subscription/num_outstanding_messagesPub/Sub generally limits the number of outstanding messages. Aim for fewer than 1,000 outstanding messages in most situations. After the throughput achieves a rate on the order of 10,000 messages per second, the service adjusts the limit for the number of outstanding messages. This limitation is done in increments of 1,000. No specific guarantees are made beyond the maximum value, so 1,000 outstanding messages is a good guide.
subscription/push_request_latenciesThis metric helps you understand the response latency distribution of the push endpoint. Because of the limit on the number of outstanding messages, endpoint latency affects subscription throughput. If it takes 100 milliseconds to process each message, your throughput limit is likely to be 10 messages per second.
To access higher outstanding message limits, push subscribers must acknowledge more than 99% of the messages that they receive.
You can calculate the fraction of messages that subscribers acknowledge using the PromQL. The following PromQL query creates a chart with the fraction of messages that subscribers acknowledge on a subscription:
rate({
"__name__"="pubsub.googleapis.com/subscription/push_request_count",
"monitored_resource"="pubsub_subscription",
"subscription_id"="$SUBSCRIPTION",
"response_class"="ack"
}[${__interval}])
/
rate({
"__name__"="pubsub.googleapis.com/subscription/push_request_count",
"monitored_resource"="pubsub_subscription",
"subscription_id"="$SUBSCRIPTION"
}[${__interval}])
Monitor subscriptions with filters
If you configure a filter on a subscription, Pub/Sub automatically acknowledges messages that don't match the filter. You can monitor this auto-acknowledgment.
The backlog metrics only include messages that match the filter.
To monitor the rate of auto-acked messages that don't match the filter, use the
subscription/ack_message_count
metric with the delivery_type label set to filter.
To monitor the throughput and cost of auto-acked messages that don't match the
filter, use the subscription/byte_cost
metric with the operation_type label set to
filter_drop. For more information about the fees for these messages, see
the Pub/Sub pricing page.
Monitor subscriptions with SMTs
If your subscription contains an SMT that filters out messages, the backlog metrics include the filtered-out messages until the SMT actually runs on them. This means that the backlog might appear larger and the oldest unacked message age might appear older than what will be delivered to your subscriber. It is especially important to keep this in mind if you are using these metrics to autoscale subscribers.
Monitor forwarded undeliverable messages
To monitor undeliverable messages that Pub/Sub
forwards to a dead-letter topic, use the
subscription/dead_letter_message_count
metric. This metric shows the number
of undeliverable messages that Pub/Sub forwards from a
subscription.
To verify that Pub/Sub is forwarding undeliverable messages, you
can compare the subscription/dead_letter_message_count metric with the
topic/send_request_count
metric. Do the comparison for the dead-letter topic to which
Pub/Sub forwards these messages.
You can also attach a subscription to the dead-letter topic and then monitor the forwarded undeliverable messages on this subscription using the following metrics:
subscription/num_unacked_messages_by_region- the number of forwarded messages that have accumulated in the subscription
subscription/oldest_unacked_message_age_by_region- the age of the oldest forwarded message in the subscription
Maintain a healthy publisher
The primary goal of a publisher is to persist message data quickly. Monitor this
performance usingtopic/send_request_count,
grouped by response_code. This
metric gives you an indication of whether Pub/Sub is healthy and
accepting requests.
A background rate of retryable errors (lower than 1%) is not a
cause for concern, since most Cloud Client Libraries retry
message failures. Investigate error rates that are greater than 1%.
Because non-retryable codes are handled by your application (rather than by the
client library), you should examine response codes. If your publisher
application does not have a good way of signaling an unhealthy state, consider
setting an alert on the topic/send_request_count metric.
It's equally important to track failed publish requests in your publish client. While client libraries generally retry failed requests, they do not guarantee publication. Refer to Publishing messages for ways to detect permanent publish failures when using Cloud Client Libraries. At a minimum, your publisher application must log permanent publish errors. If you log those errors to Cloud Logging, you can set up a logs-based metric with an alerting policy.
Monitor message throughput
Publishers might send messages in batches. You can monitor the message throughput sent by your publishers with these metrics:
topic/send_request_count: the volume of batch messages being sent by publishers.A count of
topic/message_sizes: the volume of individual (unbatched) messages being sent by publishers.
To obtain a precise count of published messages, use the following
PromQL query. This PromQL query effectively retrieves the count of individual
messages published to a specific Pub/Sub topic within defined
time intervals. Replace the placeholder values for $PROJECT_NAME and
$TOPIC_ID with your actual project and topic identifiers.
sum by (topic_id) (
increase({
"__name__"="pubsub.googleapis.com/topic/message_sizes_count",
"monitored_resource"="pubsub_topic",
"project_id"="$PROJECT_NAME",
"topic_id"="$TOPIC_ID"
}[${__interval}])
)
For better visualization, especially for daily metrics, consider the following:
View your data over a longer period to provide more context for daily trends.
Use bar charts to represent daily message counts.
What's next
To create an alert for a specific metric, see Managing metric-based alerting policies.
To learn more about using PromQL to build monitoring charts, see Use the code editor for PromQL.
To learn more about API resources for the Monitoring API, such as metrics, monitored resources, monitored-resource groups, and alerting policies, see API Resources.