本页介绍了 Memorystore for Valkey 的架构如何支持并提供高可用性 (HA)。本页面还介绍了有助于提高实例性能和稳定性的推荐配置。
高可用性
Memorystore for Valkey 基于高可用性架构构建,您的客户端可以直接访问受管理的 Memorystore for Valkey 节点。客户端通过连接到各个端点来完成此操作,如连接到 Memorystore for Valkey 实例中所述。
直接连接到分片具有以下优势:
直连可避免中间跃点,从而最大限度缩短客户端与 Valkey 节点之间的往返时间(客户端延迟时间)。
在启用集群模式的情况下,直接连接可避免任何单点故障,因为每个分片都设计为可独立发生故障。例如,如果来自多个客户端的流量使某个槽(键空间块)过载,分片故障会将影响限制在负责为该槽提供服务的分片上。
建议的配置
我们建议您创建高可用性多可用区实例,而不是单可用区实例,因为前者可提供更高的可靠性。不过,如果您选择预配没有副本的实例,我们建议您选择单可用区实例。如需了解详情,请参阅如果实例不使用副本,请选择单可用区实例。
如需为实例启用高可用性,您必须为每个分片预配至少 1 个副本节点。您可以在创建实例时执行此操作,也可以扩缩副本数量,使每个分片至少有 1 个副本。在计划内维护和意外分片故障期间,副本可提供自动故障切换。
您应根据客户端最佳实践中的指南配置客户端。使用推荐的最佳实践可让您的客户自动处理实例的以下事项,而不会造成任何停机时间:
角色(自动故障切换)
端点(节点替换)
与启用集群模式相关的 slot 分配变更(消费者横向扩缩)
副本
高可用性 Memorystore for Valkey 实例是区域级资源。Memorystore for Valkey 会将分片的主虚拟机和副本虚拟机分布在多个可用区中,以防可用区发生服务中断。Memorystore for Valkey 支持每个节点具有 0-5 个副本的实例。
您可以使用副本来提高读取吞吐量,但可能会导致数据过时。
- 集群模式已启用:使用
READONLY命令建立连接,以便客户端从副本读取数据。 - 已停用集群模式:连接到读取器端点,以连接到任何可用的副本。
已启用集群模式的实例规格
以下图表展示了启用集群模式的实例的形状:
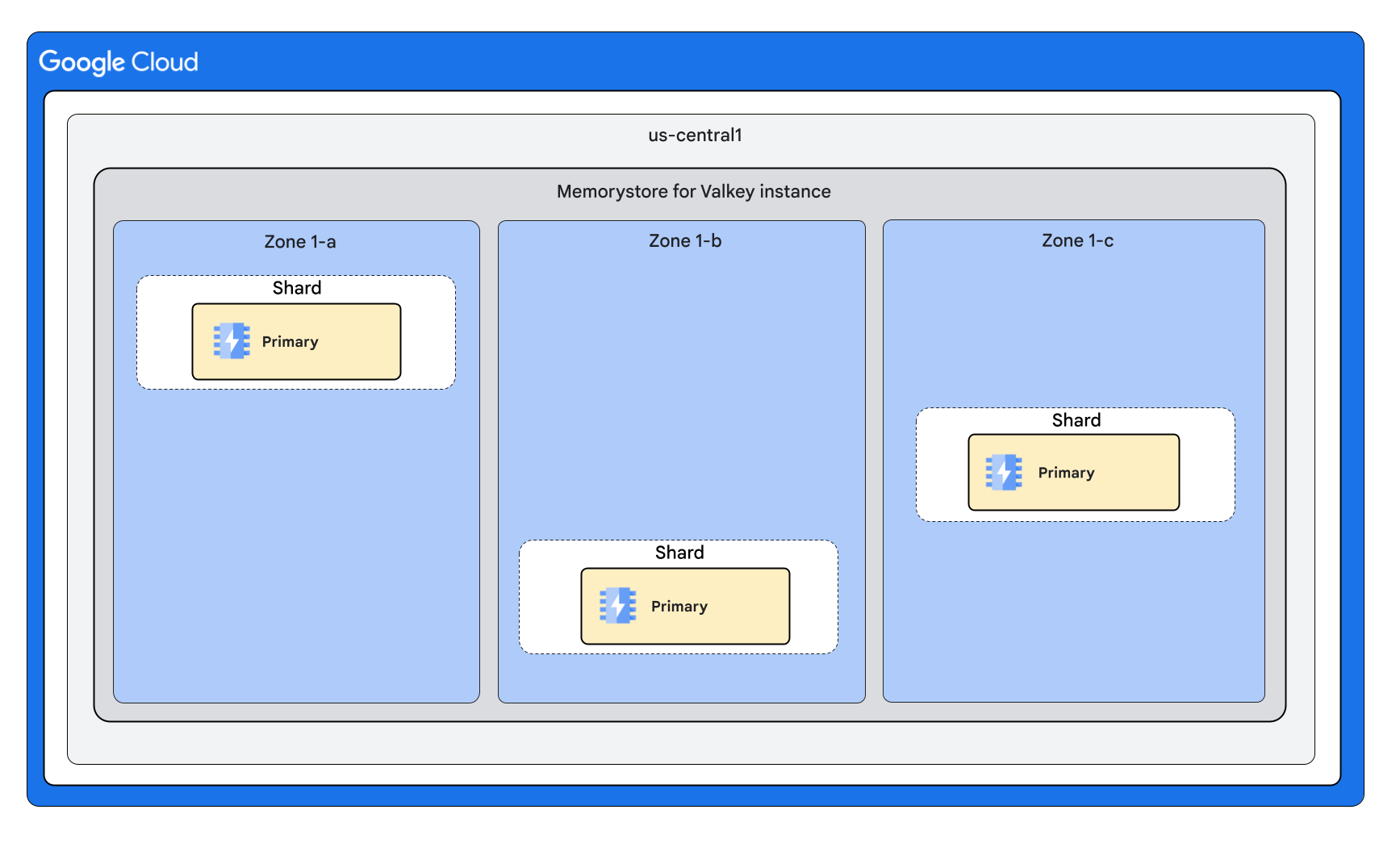
实例形状,包含 3 个分片,每个节点 0 个副本
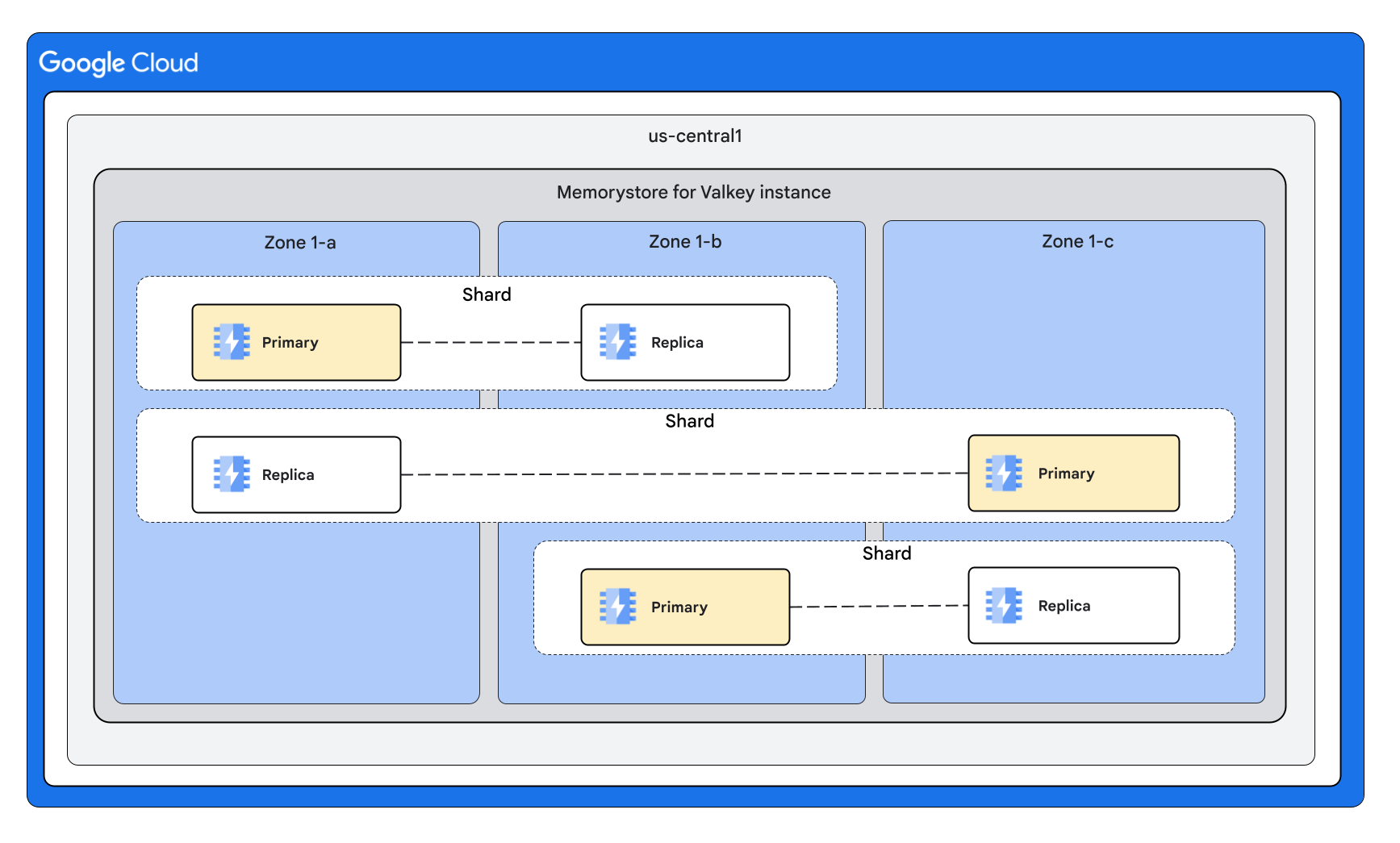
实例配置:3 个分片,每个节点 1 个副本
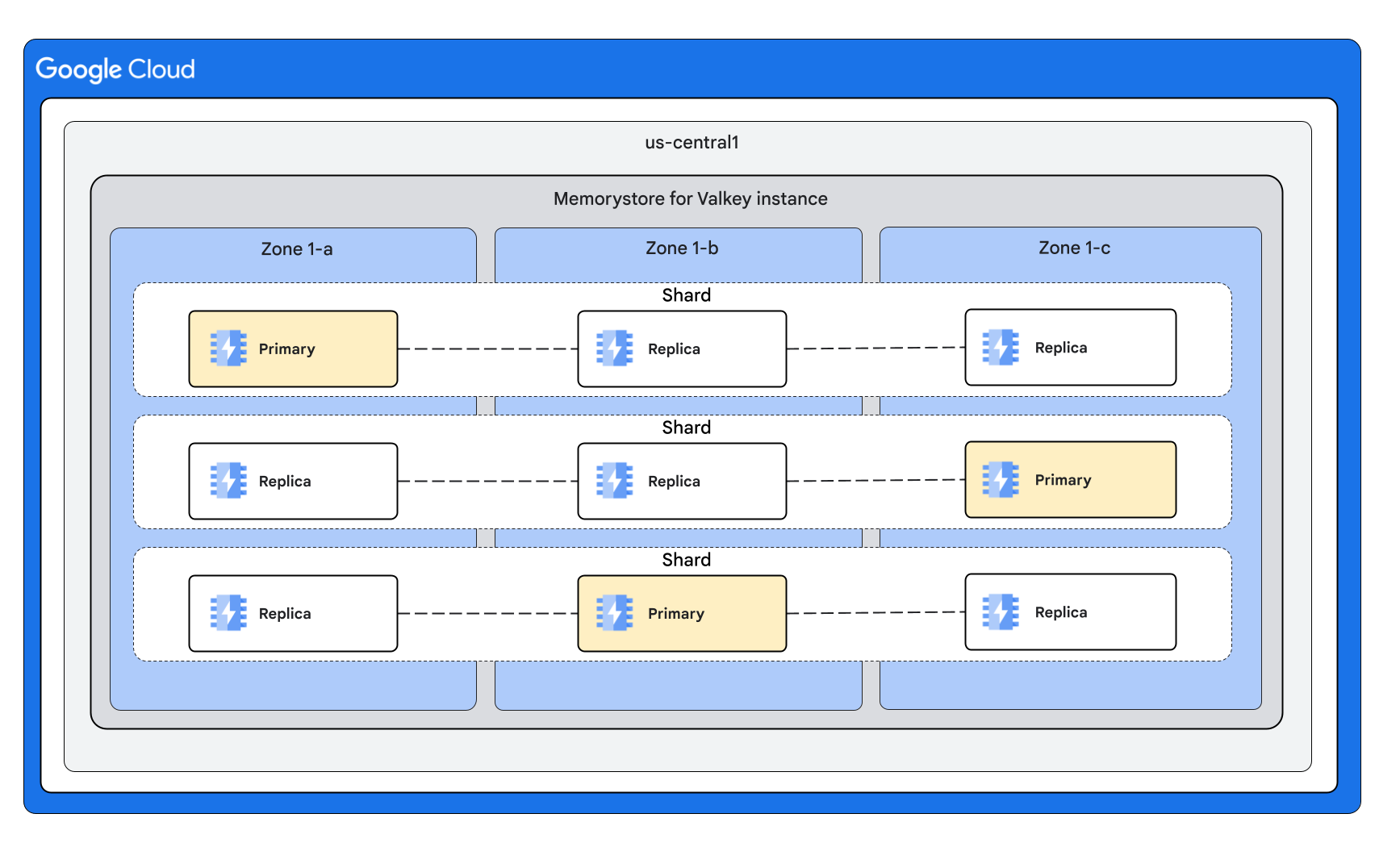
实例形状:包含 3 个分片,每个节点有多个副本
已停用集群模式的实例配置
下图展示了已停用集群模式的实例的形状:
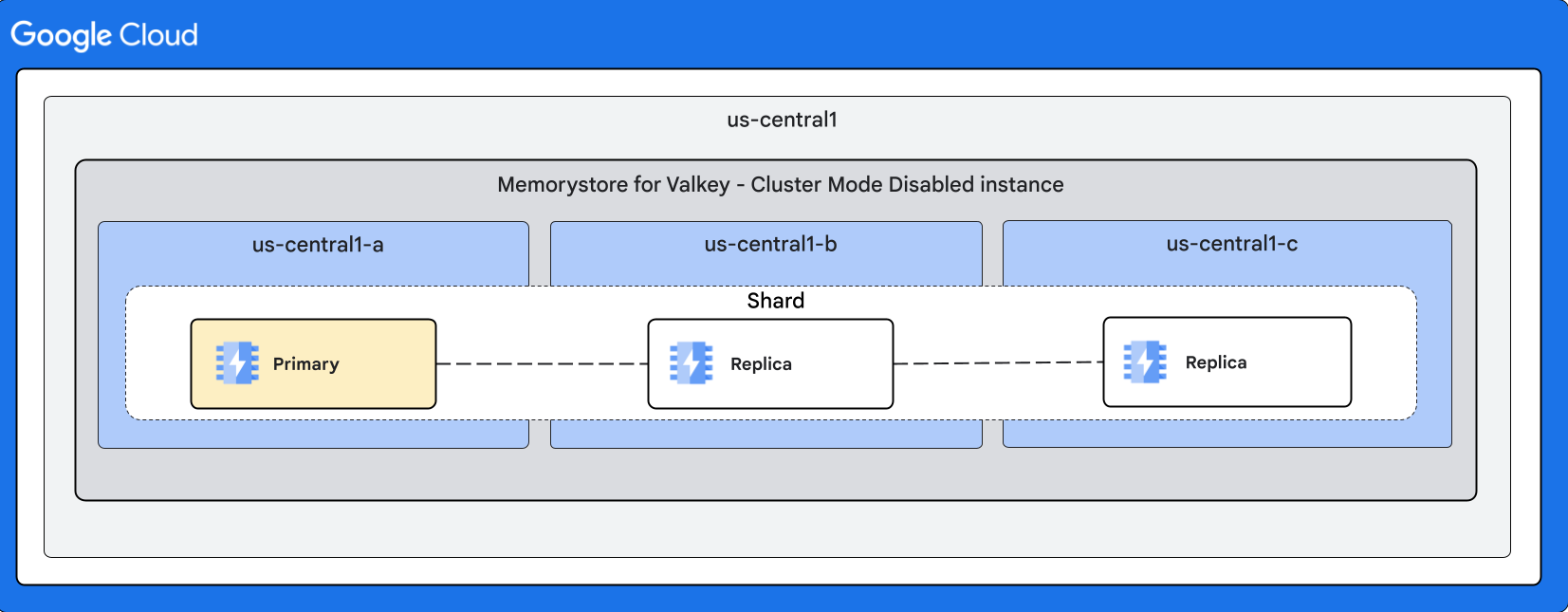
具有多个副本的实例形状
自动故障切换
由于维护或主节点的意外故障,分片内可能会发生自动故障切换。在故障切换期间,副本会被提升为主实例。您可以明确配置副本。该服务还可以在内部维护期间临时预配额外的副本,以避免任何停机时间。
自动故障转移可防止在维护更新期间丢失数据。如需详细了解维护期间的自动故障切换行为,请参阅维护期间的自动故障切换行为。
故障切换和节点修复时长
对于主节点进程崩溃或硬件故障等意外事件,自动故障切换可能需要数十秒的时间。在此期间,系统会检测到故障,并选择一个副本作为新的主实例。
节点修复可能需要几分钟的时间,以便服务替换故障节点。所有主节点和副本节点都是如此。对于非高可用性实例(未预配副本),修复发生故障的主节点也需要几分钟的时间。
在发生意外故障切换期间,客户端的行为
客户端连接可能会重置,具体取决于故障的性质。自动恢复后,应使用指数退避重试连接,以避免主节点和副本节点过载。
使用副本提高读取吞吐量的客户端应做好准备,在故障节点自动替换之前,容量可能会暂时下降。
丢失的写入
在因意外故障而导致的故障切换期间,由于 Valkey 复制协议的异步特性,已确认的写入可能会丢失。
客户端应用可以利用 Valkey WAIT 命令来提高实际数据安全性。
单个可用区中断对键空间的影响
本部分介绍了单个可用区中断对 Memorystore for Valkey 实例的影响。
多可用区实例
HA 实例:如果某个可用区发生服务中断,整个键空间可用于读取和写入,但由于某些读取副本不可用,因此读取容量会减少。我们强烈建议您超额预配集群容量,以便在极少数的单可用区中断事件发生时,实例有足够的读取容量。服务中断结束后,受影响可用区中的副本会恢复,并且集群的读取容量会恢复到配置的值。如需了解详情,请参阅构建可伸缩且可靠的应用时应遵循的模式。
非高可用性实例(无副本):如果某个可用区发生服务中断,则在该受影响的可用区中预配的键空间部分会进行数据刷新,并且在服务中断期间无法进行写入或读取。中断结束后,受影响可用区中的主节点会恢复,集群的容量也会恢复到配置的值。
单可用区实例
- HA 实例和非 HA 实例:如果实例所在的可用区发生服务中断,集群将不可用,并且数据会被清空。如果其他可用区发生服务中断,集群会继续处理读取和写入请求。
最佳做法
本部分介绍了高可用性和副本方面的最佳实践。
添加副本
添加副本需要 RDB 快照。RDB 快照使用进程派生和写入时复制机制来拍摄节点数据快照。根据对节点的写入模式,随着写入所触及的页面被复制,节点的已用内存会增加。内存占用空间可能高达节点中数据大小的两倍。
为确保节点有足够的内存来完成快照,请将 maxmemory 保留或设置为节点容量的 80%,以便为开销预留 20%。除了监控快照之外,此内存开销还有助于您管理工作负载,以便成功创建快照。此外,在添加副本时,请尽可能降低写入流量。如需了解详情,请参阅监控实例的内存用量。