Il livello Standard di Memorystore for Redis consente di scalare le query di lettura dell'applicazione utilizzando le repliche di lettura. Questa pagina presuppone che tu abbia familiarità con le diverse funzionalità dei livelli Redis di Memorystore.
Le repliche di lettura ti consentono di scalare il carico di lavoro di lettura eseguendo query sulle repliche. Viene fornito un endpoint di lettura per semplificare la distribuzione delle query tra le repliche. Per saperne di più, consulta Scalare le letture con l'endpoint di lettura.
Per istruzioni sulla gestione di un'istanza Redis con repliche di lettura, consulta Gestire le repliche di lettura.
Casi d'uso per le repliche di lettura
L'archivio delle sessioni, la classifica, il motore di suggerimenti e altri casi d'uso richiedono che l'istanza sia a disponibilità elevata. Per questi casi d'uso ci sono molte più letture che scritture e questi casi d'uso sono generalmente in grado di tollerare alcune letture non aggiornate. In casi come questi, è opportuno sfruttare le repliche di lettura per aumentare la disponibilità e la scalabilità dell'istanza.
Comportamento delle repliche di lettura
- Per impostazione predefinita, le repliche di lettura non sono abilitate nelle istanze di livello standard.
- Una volta abilitate le repliche di lettura su un'istanza, non è più possibile disattivarle per quell'istanza.
- Le istanze di livello standard possono avere da 1 a 5 repliche di lettura.
- L'endpoint di lettura fornisce un singolo endpoint per distribuire le query tra i nodi di replica.
- Le repliche di lettura vengono gestite utilizzando la replica asincrona di Redis.
Avvertenze e limitazioni
- Le repliche di lettura sono supportate solo per le dimensioni delle istanze con nodi >= 5 GB.
- Le repliche di lettura possono essere abilitate solo sulle istanze che utilizzano Redis versione 5.0 o successiva.
- Se specifichi una zona e una zona alternativa per il provisioning dei nodi, Memorystore utilizza queste zone per il primo e il secondo nodo dell'istanza. Dopodiché, Memorystore seleziona le zone per tutti i nodi rimanenti di cui è stato eseguito il provisioning per l'istanza.
- Devi eseguire il provisioning dell'istanza con un intervallo di indirizzi IP CIDR di
/28o superiore. Sono valide dimensioni di intervallo più grandi, come/27e/26. Intervalli più piccoli come/29non sono supportati per questa funzionalità.
Architettura
Quando attivi le repliche di lettura, specifichi il numero di repliche che vuoi nell'istanza. Memorystore distribuisce automaticamente i nodi principali e le repliche di lettura tra le zone disponibili in una regione.
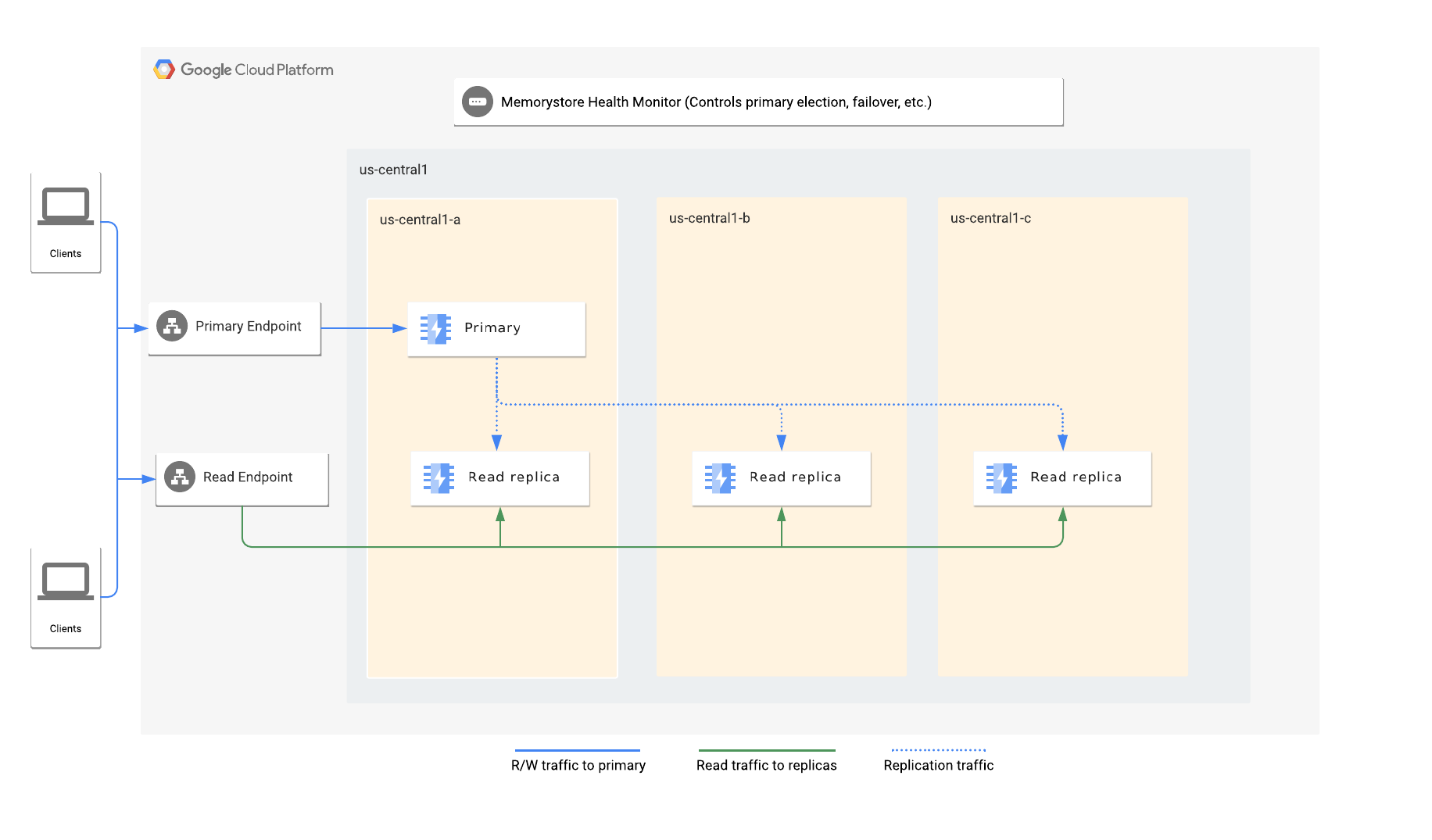
Ogni istanza ha un endpoint principale e un endpoint di lettura. L'endpoint principale indirizza sempre il traffico al nodo principale, mentre l'endpoint di lettura bilancia automaticamente il carico delle query di lettura tra le repliche disponibili.
Il servizio di monitoraggio dello stato di Memorystore for Redis monitora l'istanza ed è responsabile del rilevamento di eventuali errori del nodo principale. Sceglie una replica come nuovo nodo principale e avvia un failover automatico al nuovo nodo principale.
Failover per le istanze con repliche di lettura
Quando un database primario ha esito negativo, il servizio di monitoraggio dell'integrità di Memorystore avvia il failover e il nuovo database primario viene reso disponibile sia per le letture che per le scritture. Il failover viene generalmente completato in meno di 30 secondi.
Quando si verifica un failover, l'endpoint primario reindirizza automaticamente il traffico al nuovo primario, tuttavia, tutte le connessioni client all'endpoint primario vengono disconnesse durante un failover. Le applicazioni con logica di ripetizione della connessione si riconnetteranno automaticamente una volta che il nuovo primario sarà online. Alcune connessioni client all'endpoint di lettura vengono disconnesse anche dalla replica di lettura che viene promossa a principale durante il failover. Le connessioni alle repliche rimanenti continuano a essere gestite durante un failover. Al nuovo tentativo, le connessioni vengono reindirizzate alle nuove repliche.
Quando si verifica un failover, a causa della natura asincrona della replica, le repliche possono avere un ritardo di replica diverso. Tuttavia, la procedura di failover fa del suo meglio per eseguire il failover sulla replica con il ritardo minimo. Ciò consente di ridurre al minimo la quantità di perdita di dati e la riduzione della velocità effettiva di lettura durante un failover. La nuova istanza primaria promossa può trovarsi nella stessa zona o in una zona diversa rispetto alla precedente istanza primaria. Una replica viene selezionata come nuova primaria se si trova nella stessa zona della precedente primaria e ha il ritardo più basso. In caso contrario, una replica di una zona diversa può diventare la nuova replica principale.
Poiché la replica è asincrona, esiste sempre la possibilità di leggere dati obsoleti durante un failover. Inoltre, durante la promozione della nuova istanza principale, alcune scritture nell'istanza potrebbero andare perse. Le applicazioni devono essere in grado di gestire questo comportamento.
Redis si impegna al massimo per evitare che le altre repliche richiedano una sincronizzazione completa durante il failover, ma può succedere in rari scenari. Una sincronizzazione completa può richiedere da alcuni minuti a un'ora, a seconda della velocità di scrittura e delle dimensioni del set di dati da replicare. Durante questo periodo, le repliche sottoposte a una sincronizzazione completa non sono disponibili per le letture. Una volta completata la sincronizzazione, è possibile accedere alle repliche per le letture.
Modalità di errore per le repliche di lettura
Le istanze con repliche di lettura possono riscontrare vari errori e condizioni non integre che influiscono sull'applicazione. Il comportamento varia a seconda che l'istanza abbia una replica o due o più repliche. Questa sezione descrive alcune modalità di errore comuni e il comportamento dell'istanza in queste condizioni.
La replica non è disponibile
Quando una replica non funziona per qualsiasi motivo, viene contrassegnata come non disponibile e tutte le connessioni alla replica vengono terminate dopo un determinato timeout. Una volta recuperata la replica, le nuove connessioni vengono indirizzate alla replica ripristinata. Il tempo necessario per recuperare una replica varia a seconda della modalità di errore.
Se si verifica un errore a livello di zona, Memorystore for Redis non recupera la replica finché la zona non torna disponibile.
Errore di zona
Se la zona in cui si trova l'istanza principale non funziona, viene eseguito automaticamente il failover su una replica in un'altra zona. Se l'istanza ha una sola replica, l'endpoint di lettura non è disponibile per la durata dell'interruzione della zona. Se l'istanza ha più di una replica, le repliche al di fuori della zona interessata sono disponibili per le letture
Se la zona in cui si trova una o più repliche non funziona, queste repliche non sono disponibili per tutta la durata dell'errore della zona. Se si verifica un errore in due zone e sono presenti due o più repliche, la replica con il ritardo minore nelle zone rimanenti viene promossa a principale. Tutte le repliche rimanenti nelle zone non interessate sono disponibili per le letture.
Partizione di rete
Una partizione di rete è uno scenario in cui i nodi continuano a essere eseguiti, ma non possono raggiungere tutti i client, le zone o i nodi peer. Memorystore utilizza un sistema basato sul quorum per impedire ai nodi isolati di gestire le scritture. In caso di partizione di rete, qualsiasi primario in una partizione di minoranza viene declassato automaticamente. La partizione maggioritaria (se esiste) elegge un nuovo primario se non ne ha già uno. Le repliche isolate continuano a pubblicare le letture. Tuttavia, potrebbero diventare obsoleti se non possono essere sincronizzati dal server primario.
Per determinare se il collegamento è interrotto, monitora le metriche master_link_down_since_seconds
e offset_diff per identificare i nodi isolati.
Sincronizzazione completa
Quando una replica è troppo indietro rispetto all'istanza principale, viene attivata una sincronizzazione completa che copia un intero snapshot dall'istanza principale a una replica. Questa operazione può richiedere da pochi minuti a un'ora nel peggiore dei casi. Una sincronizzazione completa non causa un errore dell'istanza, tuttavia durante questo periodo la replica sottoposta alla sincronizzazione completa non è disponibile per le letture e l'istanza primaria registra un utilizzo di CPU e memoria più elevato.
L'endpoint principale restituisce READONLY
Le scritture nell'endpoint primario di un'istanza Memorystore for Redis con repliche di lettura potrebbero ricevere inaspettatamente errori -READONLY You can't write against a read
only replica.. Ti consigliamo di chiudere e ricreare le connessioni all'istanza. Nella maggior parte dei casi, il riavvio dell'applicazione client può risolvere il problema. Se queste opzioni non sono fattibili o il comportamento persiste, contatta il team di Google Cloud assistenza.
Scalare le letture con l'endpoint di lettura
Le repliche di lettura consentono alle applicazioni di scalare le letture leggendo dalle repliche. Le applicazioni possono connettersi alle repliche di lettura tramite l'endpoint di lettura.
Endpoint di lettura
L'endpoint di lettura è un indirizzo IP a cui si connette la tua applicazione. Bilancia uniformemente il carico delle connessioni tra le repliche nell'istanza. Le connessioni alla replica di lettura possono inviare query di lettura, ma non query di scrittura. Ogni istanza di livello standard con repliche di lettura abilitate ha un endpoint di lettura. Per istruzioni su come visualizzare l'endpoint di lettura dell'istanza, consulta Visualizzare le informazioni sulla replica di lettura per l'istanza.
Comportamento dell'endpoint di lettura
- L'endpoint di lettura distribuisce automaticamente le connessioni tra tutte le repliche disponibili. Le connessioni non sono indirizzate al primario.
- Una replica è considerata disponibile finché è in grado di gestire il traffico client. Non sono inclusi i momenti in cui una replica è in fase di sincronizzazione completa con il relativo primario.
- Una replica con un ritardo di replica elevato continua a gestire il traffico. Le applicazioni con un volume di scrittura elevato possono leggere dati obsoleti da una replica che gestisce un numero elevato di scritture.
- Se un nodo di replica diventa primario, le connessioni a quel nodo vengono terminate e le nuove connessioni vengono reindirizzate a un nuovo nodo di replica.
- Le singole connessioni alla destinazione dell'endpoint di lettura hanno come target la stessa replica per l'intera durata della connessione. Non è garantito che connessioni diverse dallo stesso host client abbiano come target lo stesso nodo di replica.
Coerenza di lettura
Le repliche di lettura vengono gestite utilizzando la replica asincrona nativa di OSS Redis. A causa della natura della replica asincrona, è possibile che la replica sia in ritardo rispetto all'istanza principale. Le applicazioni con scritture costanti che leggono anche dalla replica devono essere in grado di tollerare letture incoerenti.
Se l'applicazione richiede la coerenza "read your write", ti consigliamo di utilizzare l'endpoint principale sia per le scritture che per le letture. L'utilizzo dell'endpoint principale garantisce che le letture siano sempre indirizzate al database principale. Anche in questo caso è possibile avere letture non aggiornate dopo un failover.
L'impostazione dei TTL sulle chiavi nella chiave primaria garantisce che le chiavi scadute non vengano lette né dalla chiave primaria né dalla replica. Questo perché Redis garantisce che una chiave scaduta non possa essere letta dalla replica.
Comportamento dell'abilitazione delle repliche di lettura su un'istanza esistente
L'abilitazione delle repliche di lettura è un'operazione esclusiva, il che significa che non puoi eseguire altre modifiche all'istanza di operazione di aggiornamento nell'ambito della stessa operazione che abilita le repliche di lettura.
L'abilitazione delle repliche di lettura su un'istanza Redis esistente richiede l'allocazione di un intervallo di indirizzi IP secondari valido per il posizionamento dei nodi. Deve essere un intervallo CIDR (Classless Inter-Domain Routing) di dimensioni
/28, indipendentemente dalle dimensioni dell'intervallo di indirizzi IP esistente allocato a Memorystore for Redis.- Devi fornire l'intervallo IP aggiuntivo quando abiliti le repliche di lettura per l'istanza Redis. Puoi scegliere un intervallo specifico o lasciare che Memorystore ne selezioni automaticamente uno per te.
L'indirizzo IP di lettura/scrittura per l'istanza non cambia quando abiliti le repliche di lettura. L'indirizzo IP dell'endpoint di lettura si trova nell'intervallo originale allocato per l'istanza Memorystore, non nell'intervallo aggiuntivo che fornisci quando attivi le repliche di lettura.
Per trovare il nuovo endpoint di lettura, visualizza le informazioni sulla replica di lettura per la tua istanza dopo il completamento dell'operazione per abilitare le repliche di lettura.
Scalabilità di un'istanza
Puoi scalare il numero di repliche di lettura per l'istanza e puoi anche modificare le dimensioni del nodo:
Per istruzioni su come aggiungere e rimuovere nodi, consulta Aggiungere o rimuovere nodi di replica dall'istanza Redis.
Per istruzioni sul ridimensionamento dei nodi Redis, vedi Ridimensionare i nodi Redis.
Ti consigliamo di scalare l'istanza in un periodo di traffico di lettura e scrittura ridotto per ridurre al minimo l'impatto sull'applicazione.
L'aggiunta di una nuova replica comporta un carico aggiuntivo sull'istanza principale mentre la replica esegue una sincronizzazione completa. Quando aggiungi nodi, le connessioni esistenti non vengono interessate o trasferite. Una volta disponibile, la nuova replica inizia a ricevere connessioni dall'endpoint e a gestire le letture. La rimozione di una replica chiude tutte le connessioni attive indirizzate a quella replica. L'applicazione client deve essere configurata per riconnettersi automaticamente all'endpoint di lettura per ristabilire le connessioni alle repliche rimanenti.
Best practice
Gestione della memoria
Redis non consente alle scritture del client di superare il limite di maxmemory dell'istanza. Tuttavia, l'overhead, come la frammentazione, i buffer di replica e i comandi costosi come EVAL, può aumentare l'utilizzo della memoria oltre questo limite. In questi casi, Memorystore non riesce a scrivere finché la pressione
della memoria non viene ridotta. Per saperne di più, consulta le best practice di gestione della memoria.
Se Memorystore è in fase di esecuzione di un'operazione BGSAVE a causa di un'esportazione o di una replica di sincronizzazione completa e si verifica una condizione OOM, il processo secondario viene terminato. In questo caso, l'operazione BGSAVE non va a buon fine e il server nodo Redis rimane disponibile.
Per garantire la replica e la creazione di snapshot in qualsiasi circostanza, ti consigliamo di mantenere l'utilizzo della memoria inferiore al 50% durante operazioni importanti come l'esportazione, lo scaling e così via. Puoi attivare manualmente l'esportazione o il failover per vedere l'impatto di queste operazioni sulle prestazioni.
Gestione della CPU
Memorystore fornisce metriche sull'utilizzo della CPU e sul conteggio delle connessioni per ogni nodo. Ti consigliamo di allocare un overhead sufficiente in modo da tollerare la perdita di una singola zona di disponibilità. Il target ideale può variare in base al numero di repliche e ai pattern di utilizzo, ma un buon punto di partenza è mantenere l'utilizzo della CPU della replica al di sotto del 50%.
I singoli nodi potrebbero registrare un utilizzo elevato se i pattern di utilizzo dei client sono sbilanciati o se le operazioni di failover comportano una distribuzione sbilanciata delle connessioni. In questo caso, ti consigliamo di chiudere periodicamente le connessioni per consentire a Memorystore di ribilanciarle automaticamente. Memorystore non ribilancia le connessioni aperte.
Gestione del saldo della connessione
Ogni volta che le connessioni di un nodo vengono chiuse, i client devono riconnettersi, in genere attivando la riconnessione automatica nella libreria client di tua scelta. Quando il nodo viene reintrodotto, le connessioni esistenti non vengono reindirizzate, ma le nuove connessioni vengono indirizzate al nuovo nodo. I client possono interrompere periodicamente le connessioni per assicurarsi che siano bilanciate tra i nodi disponibili.
Gestione del ritardo della replica
È possibile che le repliche siano in ritardo, soprattutto quando la velocità di scrittura è molto elevata. In questi scenari, la replica continua a essere disponibile per le letture. In queste circostanze, le letture dalla replica possono essere obsolete e l'applicazione deve essere in grado di gestirle oppure è necessario risolvere il problema dell'elevata velocità di scrittura.
Passaggi successivi
- Scopri come gestire le repliche di lettura.
- Scopri di più sull'esportazione dei dati da un'istanza Redis.
- Scopri di più sull'alta disponibilità per Memorystore for Redis.