The schema registry provides repositories of schemas shared by multiple applications. Previously, without a schema registry, teams might depend on informal agreements—such as verbal understandings, shared documents not programmatically enforced, or wiki pages—to define the message format and how to serialize and deserialize messages. The schema registry ensures consistent message encoding and decoding.
This document provides an overview of the schema registry feature for Managed Service for Apache Kafka, its components, and the basic workflow.
Understand schemas
Imagine you're building an application that tracks customer orders. You might
use a Kafka topic called customer_orders to transmit messages containing
information about each order. A typical order message might include the
following fields of information:
Order ID
Customer name
Product name
Quantity
Price
To ensure these messages are structured consistently, you can define a schema. Here's an example in Apache Avro format:
{
"type": "record",
"name": "Order",
"namespace": "com.example",
"fields": [
{"name": "orderId", "type": "string"},
{"name": "customerName", "type": "string"},
{"name": "productName", "type": "string"},
{"name": "quantity", "type": "int"},
{"name": "price", "type": "double"}
]
}
Here's the same example in Protocol Buffer format.
syntax = "proto3";
package com.example;
option java_multiple_files = true; // Optional: Recommended for Java users
option java_package = "com.example"; // Optional: Explicit Java package
message Order {
string orderId = 1;
string customerName = 2;
string productName = 3;
int32 quantity = 4; // Avro int maps to Protobuf int32
double price = 5;
}
This schema is a blueprint for a message. It tells you that an
order message has five fields: an order ID, a customer name, a product name, a
quantity, and a price. It also specifies the data type of each field.
If a consumer client receives a binary message encoded with this schema, it
must know exactly how to interpret it. To make this possible, the producer
stores the order schema in a schema registry and passes an identifier of the
schema along with the message. As long as a consumer of the message knows which
registry was used, it can retrieve the same schema and decode the message.
Assume that you want to add a field, orderDate, to your order messages. You
would create a new version of the order schema and register it under the same
subject. This lets you track the evolution of your schema over time.
Adding a field is a forwards-compatible change. This means consumers using
older schema versions (without orderDate) can still read and process messages
produced with the new schema. The new field is ignored.
Backwards-compatibility for the schema registry means a consumer application configured with a new schema version can read data produced with a previous schema.
In this example, the initial order schema would be version 1. When you add
the orderDate field, you create version 2 of the order schema. Both versions
are stored under the same subject, letting you manage schema updates without
breaking existing applications that might still rely on version 1.
Here's a top-down view of a sample schema registry called
schema_registry_test organized by context, subject, and
schema version:
customer_supportcontextordersubjectV1version (includes orderId, customerName, productName, quantity, price)V2version (adds orderDate to V1)
What is a schema
Apache Kafka messages consist of byte strings. Without a defined structure, consumer applications must coordinate directly with producer applications to understand how to interpret these bytes.
A schema provides a formal description of the data within a message. It defines the fields and their data types such as string, integer, or boolean, and any nested structures.
Managed Service for Apache Kafka supports schemas in the following formats:
Protocol Buffers (Protobuf)
The schema registry API doesn't support JSON.
The schema registry feature integrated within Managed Service for Apache Kafka lets you create, manage, and use these schemas with your Kafka clients. The schema registry implements the Confluent Schema Registry REST API, which is compatible with existing Apache Kafka applications and common client libraries.
Schema registry organization
The schema registry uses a hierarchical structure to organize schemas.
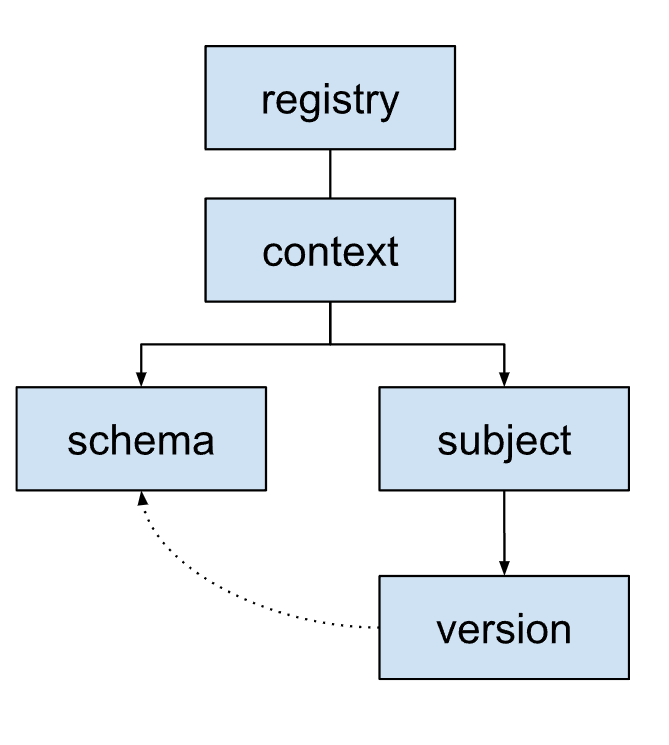
Schema: the structure and data types of a message. Each schema is identified by a schema ID. This ID is used by applications to retrieve the schema.
Subject: a logical container for different versions of a schema. Subjects manage how schemas evolve over time using compatibility rules. Each subject typically corresponds to a Kafka topic or record object.
Version: when business logic requires changes to a message structure, create and register a new schema version under the relevant subject.
Each version references a specific schema. Versions of different subjects can reference the same schema if the underlying schema happens to be the same.
Context: a high-level grouping or namespace for subjects. Contexts allow different teams or applications to use the same subject name without conflicts within the same schema registry.
A schema registry can have multiple contexts. It always contains a default context identified as
., which is where schemas and subjects go when no other context identifier is specified.A context can contain multiple subjects.
Registry: the top-level container for the entire schema ecosystem. It stores and manages all schemas, subjects, versions, and contexts.
Schema registry workflow
To follow the workflow described in this section, you can try the quickstart at Produce Avro messages with the schema registry.
Serializers and deserializers in your Kafka clients interact with the schema registry to ensure messages conform to a defined schema. Here's a typical workflow for a schema registry in Managed Service for Apache Kafka:
Initialize your producer application with a specific schema specified as an Avro-generated class and configure it to use a particular schema registry and serializer library.
Configure a consumer client to use a corresponding deserializer library and the same schema registry.
At runtime, the client passes the message object into the
producer.sendmethod and the Kafka client library uses the configured serializer to convert this record into the Avro-encoded bytes.The serializer determines a subject name for the schema based on a configured subject name strategy within the client library. It then uses this subject name in a request to the schema registry to retrieve the ID of the schema. For more information, see Subject naming strategies.
If the schema does not exist in the registry under that subject name, the client can be configured to register the schema, in which case it receives the newly assigned ID.
Avoid this configuration in production environments.
The producer sends the serialized message with the schema ID to the appropriate topic of a Kafka broker.
The Kafka broker stores the byte array representation of your message in a topic.
The consumer application receives the message.
The deserializer retrieves the schema with this ID from the schema registry.
The deserializer parses the message for the consumer application.
Limitations
The following features are not supported by the schema registry:
Schema formats:
- JSON schema format.
Schema modes:
READONLY_OVERRIDEschema mode.
Schema configuration values:
NormalizeandAliasconfiguration values.
API methods:
- The
ModifySchemaTagsmethod (/subjects/{subject}/versions/{version}/tags). - The
GetLatestWithMetadatamethod (/subjects/{subject}/metadata). - The
ListSchemasmethod (/schemas). - The
DeleteSchemaModemethod. - For the
GetVersionmethod: theformat,deleted, andfindTagsparameters. - For the
CreateVersionmethod: themetadata,ruleSet,schemaTagsToAdd, andschemaTagsToRemoveparameters. - For the
UpdateSchemaModemethod: theforceparameter. - For the
GetSchemaModemethod: thedefaultToGlobalparameter. - For the
GetSchemamethod: theWorkspaceMaxIdandfindTagsparameters. - For the
ListVersionsmethod: thedeletedOnlyparameter. - For the
ListSubjectsmethod: thedeletedOnlyparameter.
- The