BigQuery は、テーブル内のネストされたレコードをサポートしています。ネストされたレコードは単一のレコードにすることも、繰り返し値を格納することもできます。このページでは、Looker で BigQuery のネストされたデータを使用する方法の概要について説明します。
ネストされたレコードのメリット
分散データセットのスキャン時にネストされたレコードを使用する利点は、次のとおりです。
- ネストされたレコードは結合不要です。つまり、クエリごとに追加データを再結合する必要がある場合よりも計算が高速で、スキャンするデータの量が大幅に少なくなります。
- ネストされた構造は基本的に事前結合されたテーブルです。BigQuery データは列に保存されるため、ネストされた列を参照しない場合、クエリに追加の費用は発生しません。ネストされた列を参照する場合、ロジックはコロケーション結合と同じです。
- ネストされた構造では、横長の非正規化テーブルの場合に必要となるデータの繰り返しが回避されます。つまり、5 つの都市に住んだことがある人の場合、横長の非正規化テーブルではすべての情報が 5 行で記載されます(住んでいる都市ごとに 1 行ずつ)。ネストされた構造では、5 都市の配列が 1 行に含まれ、必要に応じてネスト解除できるため、繰り返しの情報は 1 行にのみ記載されます。
LookML でのネストされたレコードの操作
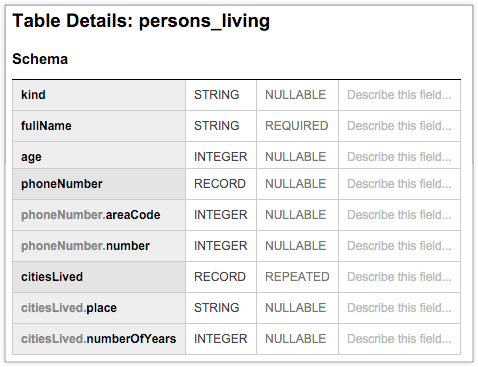
次の BigQuery テーブル persons_living には、fullName、age、phoneNumber、citiesLived などのサンプル ユーザーデータと、各列のデータ型とモードを格納する一般的なスキーマが表示されています。このスキーマは、citiesLived 列の値が繰り返され、複数の都市に住んでいるユーザーがいることを示しています。
次の例は、前述のスキーマから作成できる Explore とビューの LookML です。ビューは persons、persons_cities_lived、persons_phone_number の 3 つあります。Explore は、ネストされていないテーブルで記述された Explore と同じように表示されます。
注: 次の例では、すべてのコンポーネント(ビューと Explore)が 1 つのコードブロックで記述されていますが、ビューは個々のビューファイルに配置し、Explore と connection: 仕様はモデルファイルに配置することをおすすめします。
-- model file
connection: "bigquery_publicdata_standard_sql"
explore: persons {
# Repeated nested object
join: persons_cities_lived {
view_label: "Persons: Cities Lived:"
sql: LEFT JOIN UNNEST(persons.citiesLived) as persons_cities_lived ;;
relationship: one_to_many
}
# Non repeated nested object
join: persons_phone_number {
view_label: "Persons: Phone:"
sql: LEFT JOIN UNNEST([${persons.phoneNumber}]) as persons_phone_number ;;
relationship: one_to_one
}
}
-- view files
view: persons {
sql_table_name: bigquery-samples.nested.persons_living ;;
dimension: id {
primary_key: yes
sql: ${TABLE}.fullName ;;
}
dimension: fullName {label: "Full Name"}
dimension: kind {}
dimension: age {type:number}
dimension: citiesLived {hidden:yes}
dimension: phoneNumber {hidden:yes}
measure: average_age {
type: average
sql: ${age} ;;
drill_fields: [fullName,age]
}
measure: count {
type: count
drill_fields: [fullName, cities_lived.place_count, age]
}
}
view: persons_phone_number {
dimension: areaCode {label: "Area Code"}
dimension: number {}
}
view: persons_cities_lived {
dimension: id {
primary_key: yes
sql: CONCAT(CAST(${persons.fullName} AS STRING),'|', CAST(${place} AS STRING)) ;;
}
dimension: place {}
dimension: numberOfYears {
label: "Number Of Years"
type: number
}
measure: place_count {
type: count
drill_fields: [place, persons.count]
}
measure: total_years {
type: sum
sql: ${numberOfYears} ;;
drill_fields: [persons.fullName, persons.age, place, numberOfYears]
}
}
次のセクションでは、LookML でネストされたデータを操作するための各コンポーネントについて詳しく説明します。
ビュー
ネストされたレコードは、それぞれビューとして記述されます。たとえば、phoneNumber ビューでは、レコードに表示されるディメンションが宣言されます。
view: persons_phone_number {
dimension: areaCode {label: "Area Code"}
dimension: number {}
}
persons_cities_lived ビューはより複雑です。LookML の例に示すように、レコードに表示されるディメンション(numberOfYears と place)を定義しますが、いくつかの指標を定義することもできます。measure と drill_fields は、これらのデータがそれぞれ別のテーブルに存在するかのように、通常どおり定義されます。唯一の違いは、集計値が正しく計算されるように、id を primary_key として宣言することです。
view: persons_cities_lived {
dimension: id {
primary_key: yes
sql: CONCAT(CAST(${persons.fullName} AS STRING),'|', CAST(${place} AS STRING)) ;;
}
dimension: place {}
dimension: numberOfYears {
label: "Number Of Years"
type: number
}
measure: place_count {
type: count
drill_fields: [place, persons.count]
}
measure: total_years {
type: sum
sql: ${numberOfYears} ;;
drill_fields: [persons.fullName, persons.age, place, numberOfYears]
}
}
レコードの宣言
サブレコードを含むビュー(この場合は persons)で、レコードを宣言する必要があります。これらは、結合を作成するときに使用されます。データを調べるときにはこれらの LookML フィールドは必要ないため、hidden パラメータで非表示にできます。
view: persons {
...
dimension: citiesLived {
hidden:yes
}
dimension: phoneNumber {
hidden:yes
}
...
}
結合
BigQuery のネストされたレコードは、STRUCT 要素の配列です。sql_on パラメータで結合するのではなく、結合関係がテーブルに組み込まれます。この場合、sql: 結合パラメータを使用して、UNNEST 演算子を使用できます。この違いを除けば、STRUCT 要素の配列のネスト解除は、テーブルの結合とまったく同じです。
繰り返しでないレコードの場合は、STRUCT を使用します。角かっこで囲むと STRUCT 要素の配列に変換できます。一見すると不思議に感じるかもしれませんが、パフォーマンスが損なわれることはありません。また、これによって処理がわかりやすく整理されます。
explore: persons {
# Repeated nested object
join: persons_cities_lived {
view_label: "Persons: Cities Lived:"
sql: LEFT JOIN UNNEST(persons.citiesLived) as persons_cities_lived ;;
relationship: one_to_many
}
# Non repeated nested object
join: persons_phone_number {
view_label: "Persons: Phone:"
sql: LEFT JOIN UNNEST([${persons.phoneNumber}]) as persons_phone_number ;;
relationship: one_to_one
}
}
各行に一意のキーがない配列の結合
データの中に識別可能な自然キーや、ETL プロセスで作成されるサロゲートキーを含めることが最善ですが、常に可能であるとは限りません。たとえば、一部の配列に、行の相対的な一意のキーがない場合があります。このような場合、結合構文で WITH OFFSET を使用すると役に立ちます。
たとえば、複数の都市(シカゴ、デンバー、サンフランシスコなど)に住んだことのある人物を表す列は、複数回読み込まれる可能性があります。各都市での在職期間を区別するために日付などの識別可能な自然キーが提供されていないと、ネストされていない行に主キーを作成することは困難です。そこで WITH OFFSET を使用すると、ネストされていない行ごとに相対行番号(0、1、2、3)を指定できます。この方法では、ネストされていない行に一意のキーが保証されます。
explore: persons {
# Repeated nested Object
join: persons_cities_lived {
view_label: "Persons: Cities Lived:"
sql: LEFT JOIN UNNEST(persons.citiesLived) as persons_cities_lived WITH OFFSET as person_cities_lived_offset;;
relationship: one_to_many
}
}
view: persons_cities_lived {
dimension: id {
primary_key: yes
sql: CONCAT(CAST(${persons.fullName} AS STRING),'|', CAST(${offset} AS STRING)) ;;
}
dimension: offset {
type: number
sql: person_cities_lived_offset;;
}
}
単純な繰り返し値
BigQuery のネストされたデータは、整数や文字列などの単純な値にすることもできます。単純な繰り返し値の配列をネスト解除するには、上記のように UNNEST 演算子を使用します。
次の例では、指定した整数の配列(unresolved_skus)がネスト解除されます。
explore: impressions {
join: impressions_unresolved_sku {
sql: LEFT JOIN UNNEST(unresolved_skus) AS impressions_unresolved_sku ;;
relationship: one_to_many
}
}
view: impressions_unresolved_sku {
dimension: sku {
type: string
sql: ${TABLE} ;;
}
}
整数の配列 unresolved_skus の sql パラメータは、${TABLE} で表されます。これは、explore でネスト解除される値のテーブル自体を直接参照します。