本頁說明 Google Distributed Cloud (僅限軟體) 中 VMware 的高可用性選項。
核心功能
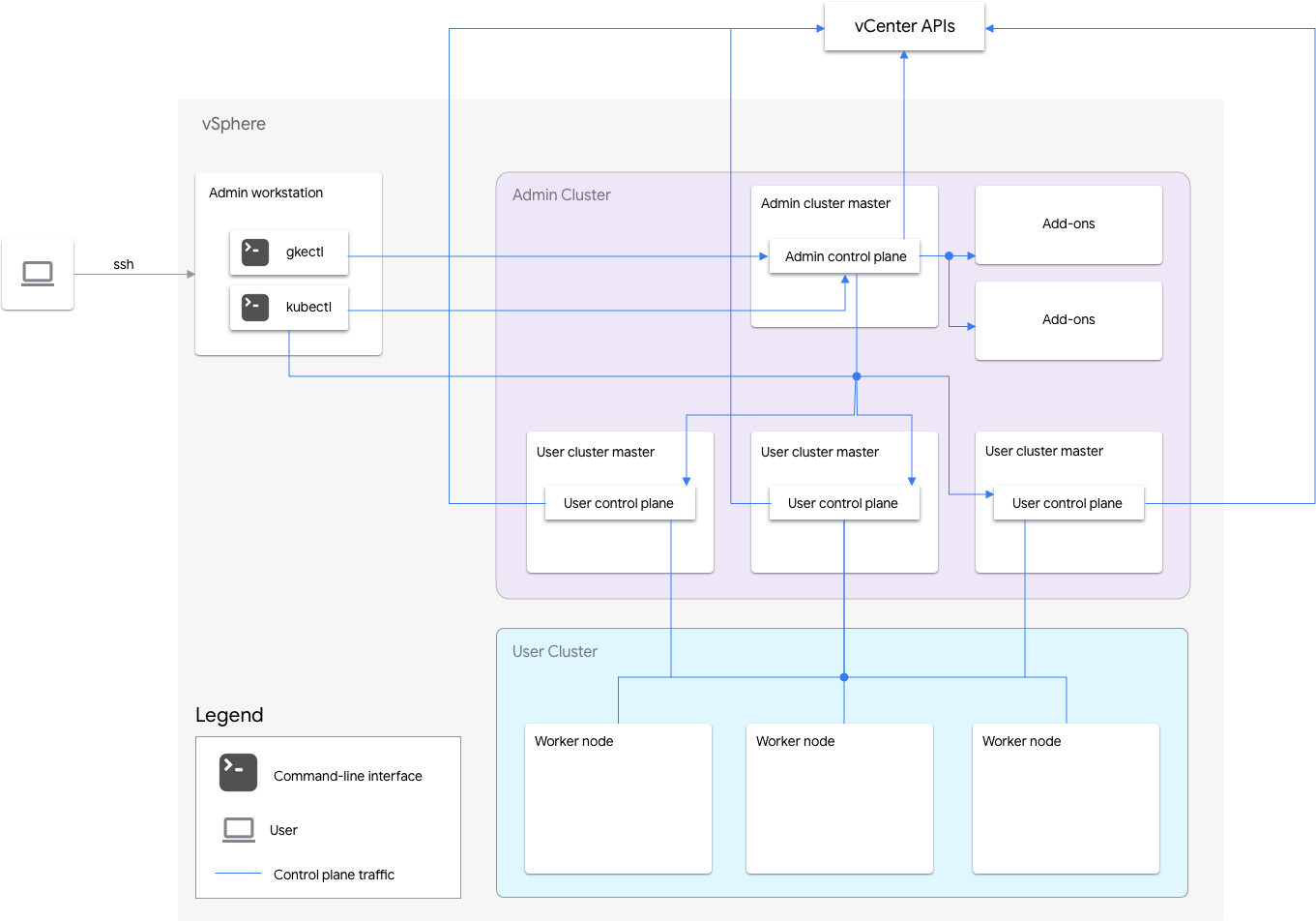
安裝於 VMware 的 Google Distributed Cloud (僅限軟體) 包含一個管理員叢集和一或多個使用者叢集。
管理員叢集會管理使用者叢集的生命週期,包括建立、更新、升級及刪除使用者叢集。在管理員叢集中,管理員主節點會管理管理員工作站節點,包括使用者主節點 (執行受管理使用者叢集控制層的節點) 和外掛程式節點 (執行支援管理員叢集功能的外掛程式元件的節點)。
以每個使用者叢集來說,管理員叢集有一個非高可用性節點,或三個高可用性節點,用來執行控制層。控制層包括 Kubernetes API 伺服器、Kubernetes 排程器、Kubernetes 控制器管理工具,以及使用者叢集的數個重要控制器。
使用者叢集的控制層可用性對於工作負載作業至關重要,例如建立、擴大/縮小及終止工作負載。換句話說,控制層中斷不會干擾執行中的工作負載,但如果控制層不存在,現有工作負載就會失去 Kubernetes API 伺服器的管理功能。
容器化工作負載和服務會部署在使用者叢集工作站節點中。只要應用程式部署時,在多個工作站節點上排程了備援 Pod,任何單一工作站節點都不應對應用程式可用性至關重要。
啟用高可用性
vSphere 和 Google Distributed Cloud 提供多項功能,有助於實現高可用性 (HA)。
vSphere HA 和 vMotion
建議您在代管 Google Distributed Cloud 叢集的 vCenter 叢集中啟用下列兩項功能:
如果 ESXi 主機發生故障,這些功能可提升可用性和復原能力。
vCenter HA 會使用設定為叢集的多部 ESXi 主機,從中斷事件快速復原,並為在虛擬機器中執行的應用程式提供具成本效益的高可用性。建議您為 vCenter 叢集佈建額外主機,並啟用 vSphere HA 主機監控,將 Host Failure Response 設為 Restart VMs。如果 ESXi 主機故障,系統就會在其他可用主機上自動重新啟動 VM。
vMotion 可讓您將 VM 從一台 ESXi 主機即時遷移至另一台主機,完全不會造成停機。對於預先規劃的主機維護作業,您可以使用 vMotion 即時遷移功能,完全避免應用程式停機,確保業務持續性。
管理員叢集
Google Distributed Cloud 支援建立高可用性 (HA) 管理員叢集。高可用性管理員叢集有三個節點,可執行控制層元件。 如要瞭解相關規定和限制,請參閱「高可用性管理員叢集」。
請注意,管理員叢集控制層無法使用,不會影響現有的使用者叢集功能,也不會影響使用者叢集中執行的任何工作負載。
管理員叢集中有兩個外掛程式節點。如果其中一個發生故障,另一個仍可處理管理員叢集作業。為確保備援能力,Google Distributed Cloud 會將 kube-dns 等重要附加元件服務分散到兩個附加元件節點。
如果您在管理員叢集設定檔中將 antiAffinityGroups.enabled 設為 true,Google Distributed Cloud 會自動為外掛程式節點建立 vSphere DRS 反相依性規則,使節點分散於兩個實體主機,以確保高可用性。
使用者叢集
如要為使用者叢集啟用 HA,請在使用者叢集設定檔中將 masterNode.replicas 設為 3。如果使用者叢集已啟用Controlplane V2 (建議),則 3 個控制層節點會在使用者叢集中執行。未啟用 Controlplane V2 的舊版 HA 使用者叢集會在管理員叢集中執行三個控制層節點。每個控制層節點也會執行 etcd 副本。只要有一個控制層正在執行,且 etcd 仲裁正常運作,使用者叢集就會繼續運作。etcd 仲裁需要三個 etcd 副本中的兩個正常運作。
如果您在管理員叢集設定檔中將 antiAffinityGroups.enabled 設為 true,Google Distributed Cloud 會自動為執行使用者叢集控制層的三個節點建立 vSphere DRS 反親和性規則。這會導致這些 VM 分散在三部實體主機上。
Google Distributed Cloud 也會為使用者叢集中的工作站節點建立 vSphere DRS 反相依性規則,使這些節點分散於至少三個實體主機上。每個使用者叢集節點集區會根據節點數量,使用多個 DRS 反親和性規則。即使主機數量少於使用者叢集節點集區中的 VM 數量,這項設定也能確保工作站節點可以找到要執行的主機。建議您在 vCenter 叢集中加入額外的實體主機。此外,請將 DRS 設定為全自動,這樣一來,如果主機無法使用,DRS 就能在其他可用主機上自動重新啟動 VM,且不會違反 VM 的反相依性規則。
Google Distributed Cloud 會維護特殊的節點標籤 onprem.gke.io/failure-domain-name,其值會設為基礎 ESXi 主機名稱。如要確保應用程式 Pod 分散在不同 VM 和實體主機上,需要高可用性的使用者應用程式可以設定 podAntiAffinity 規則,並將這個標籤設為 topologyKey。您也可以為使用者叢集設定多個節點集區,這些集區具有不同的資料存放區和特殊節點標籤。同樣地,您可以設定podAntiAffinity
規則,並將該特殊節點標籤設為 topologyKey,以便在資料存放區發生故障時,達到更高的可用性。
如要確保使用者工作負載具備高可用性,請確認使用者叢集在 nodePools.replicas 下有足夠的副本數量,確保使用者叢集工作站節點的數量符合需求,且處於執行狀態。
您可以為管理員叢集和使用者叢集使用不同的資料儲存區,以隔離故障。
負載平衡器
您可以使用兩種負載平衡器來確保高可用性。
套裝組合 MetalLB 負載平衡器
如要使用套裝組合 MetalLB 負載平衡器,請確保有多個節點具有 enableLoadBalancer: true,即可實現高可用性。
MetalLB 會將服務分配到負載平衡器節點上,但對於單一服務,只有一個領導節點會處理該服務的所有流量。
升級叢集時,負載平衡器節點會暫停運作一段時間。隨著負載平衡器節點數量增加,MetalLB 的容錯移轉中斷時間也會變長。如果節點少於 5 個,中斷時間會在 10 秒內。
手動平衡負載
透過手動負載平衡,您可以設定 Google Distributed Cloud 使用您選擇的負載平衡器,例如 F5 BIG-IP 或 Citrix。您是在負載平衡器上設定高可用性,而不是在 Google Distributed Cloud 中設定。
使用多個叢集進行災難復原
跨多個 vCenter 伺服器在多個叢集中部署應用程式,可提高全球可用性,並在發生中斷時限制影響範圍。
這項設定會使用次要資料中心內的現有叢集進行災害復原,而不是設定新叢集。以下是達成這個目標的簡要摘要:
在次要資料中心建立另一個管理員叢集和使用者叢集。 在這個多叢集架構中,我們要求使用者在每個資料中心都有兩個管理員叢集,且每個管理員叢集都會執行使用者叢集。
次要使用者叢集的工作站節點數量最少為三個,且為熱待機 (一律處於執行狀態)。
您可以使用 Config Sync,在兩個 vCenter 中複製應用程式部署作業,或使用現有的應用程式 DevOps (CI/CD、Spinnaker) 工具鍊,這是較好的做法。
發生災害時,使用者叢集可以調整大小,達到節點數量。
此外,還需要進行 DNS 切換,將叢集之間的流量導向次要資料中心。