Com a Document AI, é possível treinar novas versões de processadores usando seus próprios dados de treinamento e avaliar a qualidade da versão do processador em relação aos seus dados de teste.
Isso é útil quando você quer usar um processador personalizado. Há um processador da Document AI para seu tipo de documento, mas você pode treinar uma versão personalizada dele para atender às suas necessidades.
O treinamento e a avaliação geralmente são realizados em conjunto para iterar em direção a uma versão de processador utilizável e de alta qualidade.
Document AI
Com a Document AI, você pode criar seu próprio extrator personalizado, que extrai entidades de documentos de um tipo específico, por exemplo, os itens de um menu ou o nome e dados de contato de um currículo.
Ao contrário de outros processadores, os personalizados não vêm com versões pré-treinadas e, portanto, não podem processar documentos até que você treine uma versão do zero.
Para começar a usar a Document AI, consulte Criar seu próprio processador personalizado.
Aprimorar o treinamento de um processador
É possível atualizar novas versões do processador para melhorar a acurácia dos dados, extrair mais campos personalizados dos documentos e adicionar suporte a novos idiomas.
O up training funciona aplicando aprendizagem por transferência em versões pré-treinadas do processador do Google e geralmente exige menos dados do que o treinamento do zero.
Para começar, consulte Fazer o uptraining de um processador pré-treinado.
Processadores compatíveis
Nem todos os processadores especializados são compatíveis com o treinamento de atualização. Estes são os processadores que oferecem suporte ao treinamento.
Considerações e recomendações de dados
A qualidade e a quantidade dos seus dados determinam a qualidade do treinamento, do uptraining e da avaliação.
Obter um conjunto de documentos representativos do mundo real e fornecer rótulos de alta qualidade suficientes costuma ser a parte mais demorada e que exige mais recursos do processo.
Número de documentos
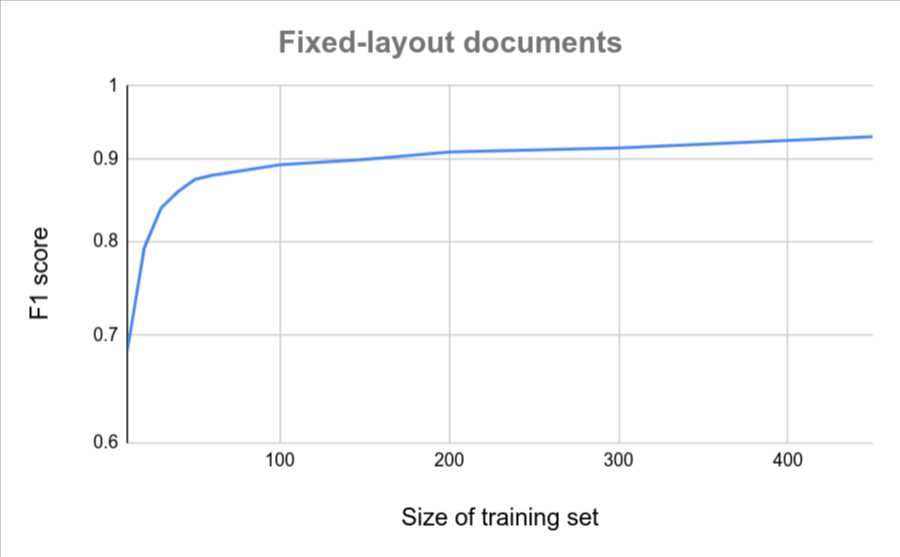
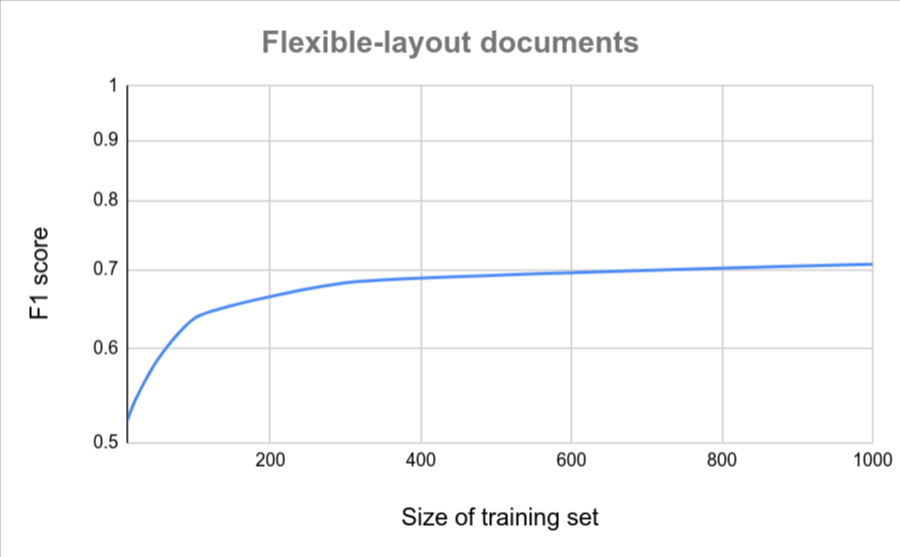
Se todos os documentos tiverem um formato semelhante (por exemplo, um formulário fixo com variação muito baixa), menos documentos serão necessários para alcançar a precisão. Quanto maior a variação, mais documentos são necessários.
Os gráficos a seguir fornecem uma estimativa aproximada do número de documentos necessários para que um extrator de documentos personalizado alcance uma pontuação de qualidade específica.
| Baixa variação | Alta variação |
|---|---|
 |
 |
Rotulagem de dados
Considere suas opções de rotulagem de documentos e verifique se você tem recursos suficientes para anotar os documentos no seu conjunto de dados.
Como treinar modelos
Os processadores de extração personalizados podem usar diferentes tipos de modelos dependendo do caso de uso específico e dos dados de treinamento disponíveis.
- Modelo personalizado: modelo que usa dados de treinamento rotulados.
- Baseado em modelo: documentos com um layout fixo.
- Baseado em modelo: documentos com alguma variação de layout.
- Modelo de IA generativa: baseado em modelos de fundação pré-treinados que exigem treinamento adicional mínimo.
A tabela a seguir ilustra quais casos de uso correspondem a cada tipo de modelo.
| Modelo personalizado | IA generativa | ||
|---|---|---|---|
| Com base em modelo | Com base no modelo | ||
| Variação de layout | Nenhum | Baixa a média | Alta |
| Quantidade de texto livre (por exemplo, parágrafos em um contrato) | Baixo | Baixo | Alta |
| Quantidade de dados de treinamento necessários | Baixo | Alta | Baixo |
| Precisão com dados de treinamento limitados | Alto | Inferior | Alto |
Saiba como ajustar um processador com descrições de propriedades.
Quando usar outro processador
Confira algumas situações em que você pode considerar opções além do Document AI Workbench ou adaptar seu fluxo de trabalho.
- Alguns formatos de entrada baseados em texto (.txt, .html, .docx, .md etc.) não são compatíveis com o Document AI Workbench. Considere outras ofertas de processamento de linguagem pré-criadas ou personalizadas em Google Cloud, como a API Cloud Natural Language.
- O esquema do extrator de documentos personalizado aceita até 150 rótulos de entidade. Se a lógica de negócios exigir mais de 150 entidades na definição do esquema, treine vários processadores, cada um segmentando um subconjunto de entidades.
Como treinar um processador
Supondo que você já tenha criado um processador compatível com treinamento ou aprimoramento e rotulado seu conjunto de dados, é possível treinar uma nova versão do processador do zero. Ou você pode aprimorar o treinamento de uma nova versão do processador com base em uma atual.
Treinar versão do processador
IU da Web
No console Google Cloud , acesse a guia Treinar do seu processador.
Clique em Editar esquema para abrir a página Gerenciar rótulos. Verifique os rótulos do processador.
Os rótulos ativados no momento do treinamento determinam as entidades que a nova versão do processador extrai. Se um rótulo estiver inativo no esquema, a versão do processador não vai extrair esse rótulo, mesmo que os documentos estejam rotulados.
Na guia Treinar, clique em Ver estatísticas de rótulos e verifique seu conjunto de teste e treinamento. Os documentos rotulados automaticamente, sem rótulo ou não atribuídos são excluídos do treinamento e da avaliação.
Clique em Treinar nova versão.
O Nome da versão define o campo
namedoprocessorVersion.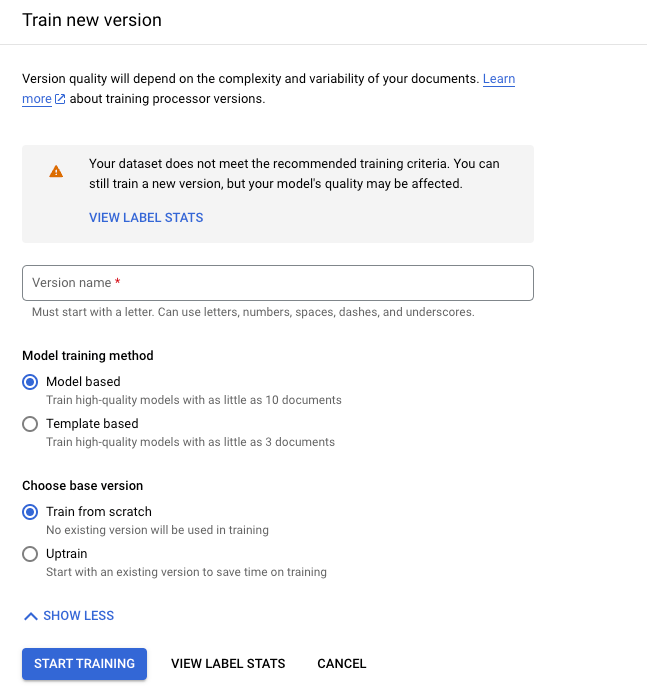
Clique em Iniciar treinamento e aguarde a nova versão do processador ser treinada e avaliada.
É possível monitorar o progresso do treinamento na guia Gerenciar versões:
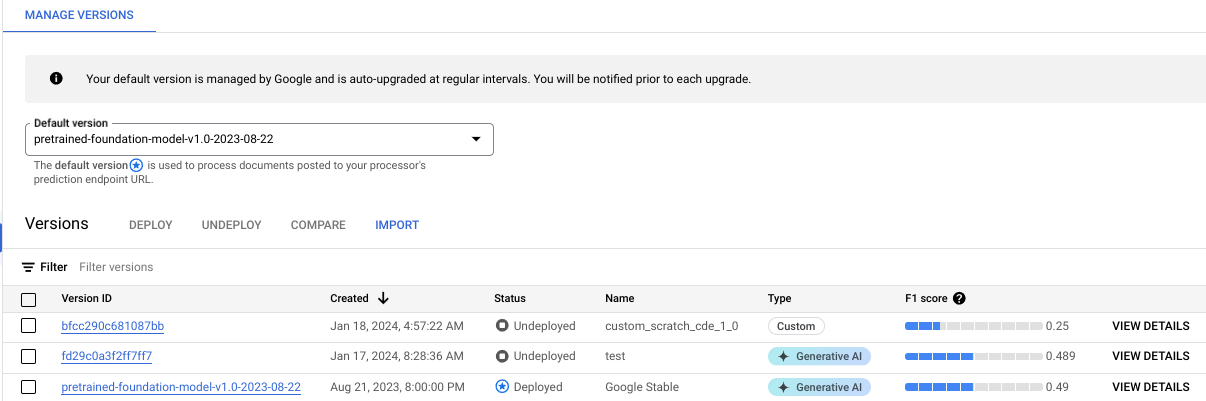
Clique na guia Avaliar e testar para conferir o desempenho da nova versão do processador no conjunto de teste. Para mais informações, consulte Avaliar versão do processador.
Python
Para mais informações, consulte a documentação de referência da API Python da Document AI.
Para autenticar na Document AI, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.
Implantar e usar a versão do processador
É possível implantar e gerenciar as versões do processador como qualquer outra versão do processador. Para mais informações, consulte Como gerenciar versões de processadores.
Depois de implantado, envie uma solicitação de processamento para o processador personalizado.
Desativar ou excluir um processador
Se você não quiser mais usar um processador, desative ou exclua. Se você desativar um processador, poderá reativá-lo. Não é possível recuperar um processador excluído.
No painel Document AI à esquerda, clique em Meus processadores.
Clique nos pontos verticais à direita do nome do processador. Clique em Desativar operador ou Excluir operador.
Para mais informações, consulte Como gerenciar versões de processadores.
Criptografia de dados de treinamento
Os dados de treinamento da Document AI são salvos no Cloud Storage e podem ser criptografados com chaves de criptografia gerenciadas pelo cliente, se necessário.
Exclusão de dados de treinamento
Depois que um job de treinamento da Document AI é concluído, todos os dados de treinamento salvos no Cloud Storage expiram após um período de armazenamento de dois dias. As atividades de exclusão de dados subsequentes respeitam o processo descrito em Exclusão de dados no Google Cloud.
Preços
Não há custo para treinamento ou reciclagem. Você paga pela hospedagem e pela previsão. Para mais informações, consulte Preços da Document AI.