Document AI te permite entrenar versiones nuevas del procesador con tus propios datos de entrenamiento y evaluar la calidad de la versión del procesador con tus propios datos de prueba.
Esto es útil cuando deseas usar un procesador personalizado. Existe un procesador de Document AI para tu tipo de documento, pero puedes entrenar una versión personalizada para satisfacer tus necesidades.
Por lo general, el entrenamiento y la evaluación se realizan en conjunto para iterar hacia una versión del procesador utilizable y de alta calidad.
Document AI
Document AI te permite crear tu propio extractor personalizado, que extrae entidades de documentos de un tipo particular, por ejemplo, los elementos de un menú o el nombre y la información de contacto de un currículum.
A diferencia de otros procesadores, los procesadores personalizados no incluyen versiones de procesador preentrenadas y, por lo tanto, no pueden procesar documentos hasta que entrenes una versión desde cero.
Para comenzar a usar Document AI, consulta Crea tu propio procesador personalizado.
Cómo enriquecer un procesador
Puedes entrenar nuevas versiones del procesador para mejorar la precisión en tus datos, extraer campos personalizados adicionales de tus documentos y agregar compatibilidad con idiomas nuevos.
El entrenamiento ascendente funciona aplicando el aprendizaje por transferencia en las versiones de procesadores entrenados previamente de Google y, por lo general, requiere menos datos que el entrenamiento desde cero.
Para comenzar, consulta Enriquece un procesador previamente entrenado.
Procesadores compatibles
No todos los procesadores especializados admiten el entrenamiento de actualización. Estos son los procesadores que admiten el entrenamiento de la CPU.
Consideraciones y recomendaciones sobre los datos
La calidad y la cantidad de tus datos determinan la calidad del entrenamiento, el reentrenamiento y la evaluación.
Obtener un conjunto de documentos representativos del mundo real y proporcionar suficientes etiquetas de alta calidad suele ser la parte del proceso que requiere más tiempo y recursos.
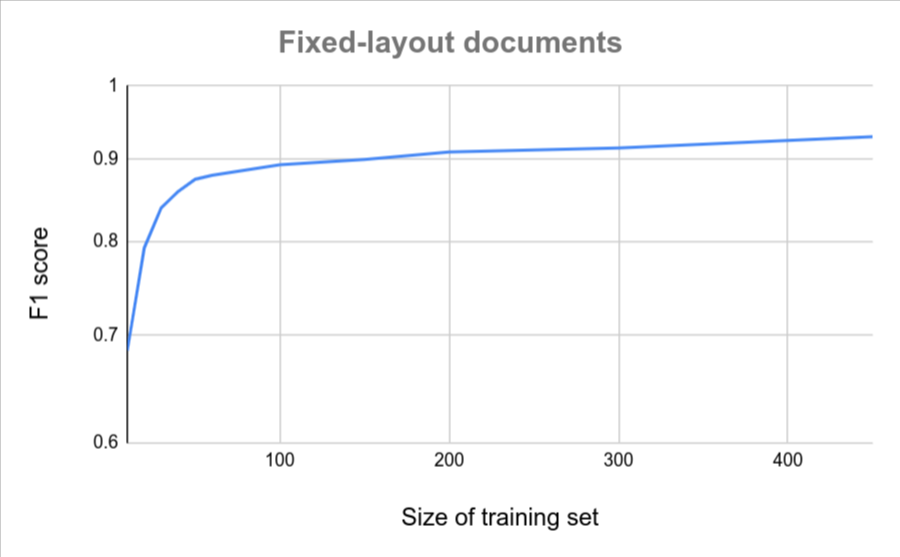
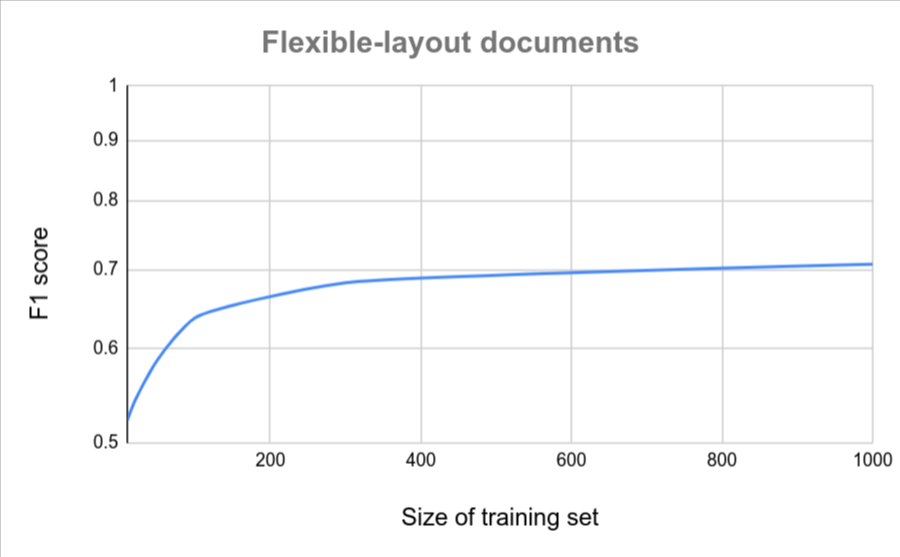
Cantidad de documentos
Si todos tus documentos tienen un formato similar (por ejemplo, un formulario fijo con muy poca variación), se requieren menos documentos para lograr la precisión. Cuanto mayor sea la variación, más documentos se requerirán.
En los siguientes gráficos, se proporciona una estimación aproximada de la cantidad de documentos que se requieren para que un extractor de documentos personalizado alcance una puntuación de calidad determinada.
| Poca variación | Variación alta |
|---|---|
 |
 |
Etiquetado de datos
Considera tus opciones para etiquetar documentos y asegúrate de tener suficientes recursos para anotar los documentos de tu conjunto de datos.
Entrena modelos
Los procesadores de extractores personalizados pueden usar diferentes tipos de modelos según el caso de uso específico y los datos de entrenamiento disponibles.
- Modelo personalizado: Es un modelo que usa datos de entrenamiento etiquetados.
- Basados en plantillas: Documentos con un diseño fijo.
- Basado en modelos: documentos con cierta variación de diseño
- Modelo de IA generativa: Se basa en modelos de base previamente entrenados que requieren un entrenamiento adicional mínimo.
En la siguiente tabla, se ilustran los casos de uso que corresponden a cada tipo de modelo.
| Modelo personalizado | IA generativa | ||
|---|---|---|---|
| Basado en plantillas | Basado en modelos | ||
| Variación del diseño | Ninguno | De baja a media | Alta |
| Cantidad de texto de formato libre (por ejemplo, párrafos en un contrato) | Baja | Bajo | Alta |
| Cantidad de datos de entrenamiento necesarios | Baja | Alta | Baja |
| Precisión con datos de entrenamiento limitados | Superior | Inferior | Superior |
Aprende a ajustar un procesador con descripciones de propiedades.
Cuándo usar otro procesador
Estas son algunas situaciones en las que te recomendamos considerar otras opciones además de Document AI Workbench o adaptar tu flujo de trabajo.
- Document AI Workbench no admite ciertos formatos de entrada basados en texto (.txt, .html, .docx, .md, etcétera). Considera otras ofertas de procesamiento de lenguaje prediseñadas o personalizadas en Google Cloud, como la API de Cloud Natural Language.
- El esquema del Extractor de documentos personalizado admite hasta 150 etiquetas de entidades. Si tu lógica empresarial requiere más de 150 entidades en la definición del esquema, considera entrenar varios procesadores, cada uno orientado a un subconjunto de entidades.
Cómo entrenar un procesador
Si suponemos que ya creaste un procesador que admite el entrenamiento o el enriquecimiento y etiquetaste tu conjunto de datos, puedes entrenar una nueva versión del procesador desde cero. También puedes enriquecer una versión existente del procesador.
Entrena la versión del procesador
IU web
En la consola de Google Cloud , ve a la pestaña Entrenar del procesador.
Haz clic en Editar esquema para abrir la página Administrar etiquetas. Verifica las etiquetas del procesador.
Las etiquetas que están habilitadas en el momento del entrenamiento determinan las entidades que extrae la nueva versión del procesador. Si una etiqueta está inactiva en el esquema, la versión del procesador no la extraerá, incluso si los documentos están etiquetados.
En la pestaña Train, haz clic en View Label Stats y verifica tu conjunto de datos de entrenamiento y de prueba. Los documentos etiquetados automáticamente, sin etiquetar o sin asignar se excluyen del entrenamiento y la evaluación.
Haz clic en Entrenar una versión nueva.
El Nombre de la versión define el campo
namedeprocessorVersion.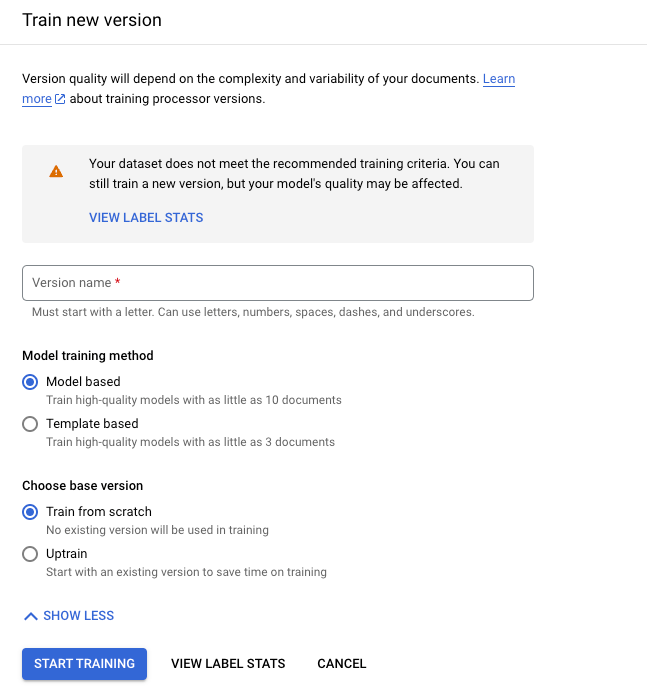
Haz clic en Comenzar entrenamiento y espera a que se entrene y evalúe la nueva versión del procesador.
Puedes supervisar el progreso del entrenamiento en la pestaña Administrar versiones:
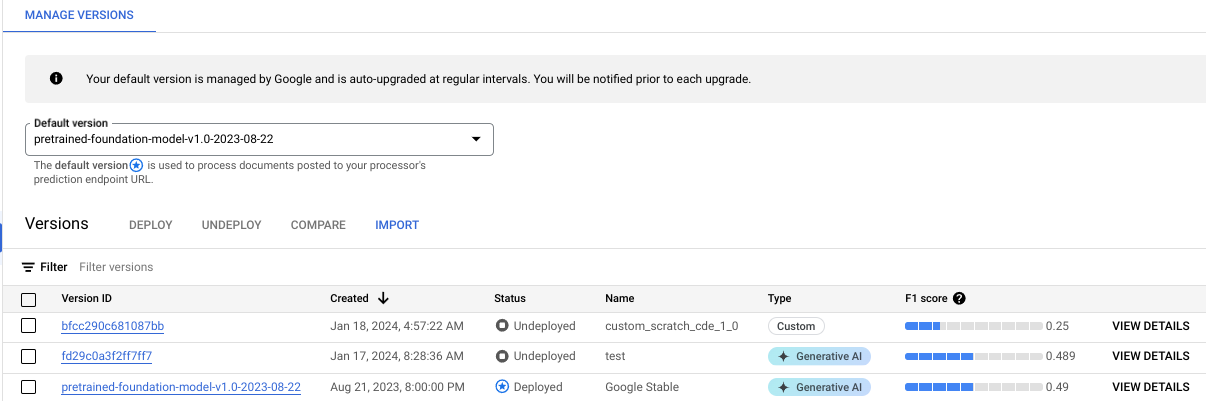
Haz clic en la pestaña Evalúa y prueba para ver el rendimiento de la nueva versión del procesador en el conjunto de datos de prueba. Para obtener más información, consulta Evalúa la versión del procesador.
Python
Para obtener más información, consulta la documentación de referencia de la API de Document AI Python.
Para autenticarte en Document AI, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Implementa y usa la versión del procesador
Puedes implementar y administrar tus versiones de procesador como cualquier otra versión de procesador. Para obtener más información, consulta Administra versiones de procesadores.
Una vez implementado, puedes enviar una solicitud de procesamiento a tu procesador personalizado.
Cómo inhabilitar o borrar un procesador
Si ya no quieres usar un procesador, puedes inhabilitarlo o borrarlo. Si inhabilitas un procesador, puedes volver a habilitarlo. Si borras un procesador, no podrás recuperarlo.
En el panel Document AI de la izquierda, haz clic en Mis procesadores.
Haz clic en los puntos verticales a la derecha del nombre del procesador. Haz clic en Inhabilitar procesador o Borrar procesador.
Para obtener más información, consulta Administra versiones de procesadores.
Encriptación de los datos de entrenamiento
Los datos de entrenamiento de Document AI se guardan en Cloud Storage y se pueden encriptar con claves de encriptación administradas por el cliente si es necesario.
Eliminación de datos de entrenamiento
Después de que se completa un trabajo de entrenamiento de Document AI, todos los datos de entrenamiento guardados en Cloud Storage vencen después de un período de retención de dos días. Las actividades posteriores de eliminación de datos respetan el proceso descrito en Eliminación de datos en Google Cloud.
Precios
No hay costos de capacitación ni de actualización de la capacitación. Pagas por el alojamiento y la predicción. Para obtener más información, consulta Precios de Document AI.