Es obligatorio usar un conjunto de datos etiquetado de documentos para entrenar, entrenar o evaluar una versión de procesador.
En esta página se describe cómo crear un conjunto de datos, importar documentos y definir un esquema. Para etiquetar los documentos importados, consulta Etiquetar documentos.
En esta página se presupone que ya has creado un procesador que admite entrenamiento, entrenamiento adicional o evaluación. Si tu procesador es compatible, verás la pestaña Entrenar en la consola Google Cloud .
Opciones de almacenamiento de conjuntos de datos
Puedes elegir entre dos opciones para guardar tu conjunto de datos:
- Gestionado por Google
- Ubicación personalizada de Cloud Storage
A menos que tengas requisitos especiales (por ejemplo, para mantener los documentos en un conjunto de carpetas habilitadas para CMEK), te recomendamos la opción de almacenamiento más sencilla gestionada por Google. Una vez creada la opción de almacenamiento del conjunto de datos, no se puede cambiar en el procesador.
La carpeta o subcarpeta de una ubicación de Cloud Storage personalizada debe estar vacía al principio y tratarse como de solo lectura. Si modificas manualmente su contenido, es posible que el conjunto de datos deje de ser útil y se pierda. La opción de almacenamiento gestionado por Google no conlleva este riesgo.
Sigue estos pasos para aprovisionar tu ubicación de almacenamiento.
Almacenamiento gestionado por Google (opción recomendada)
Mostrar opciones avanzadas al crear un nuevo procesador.
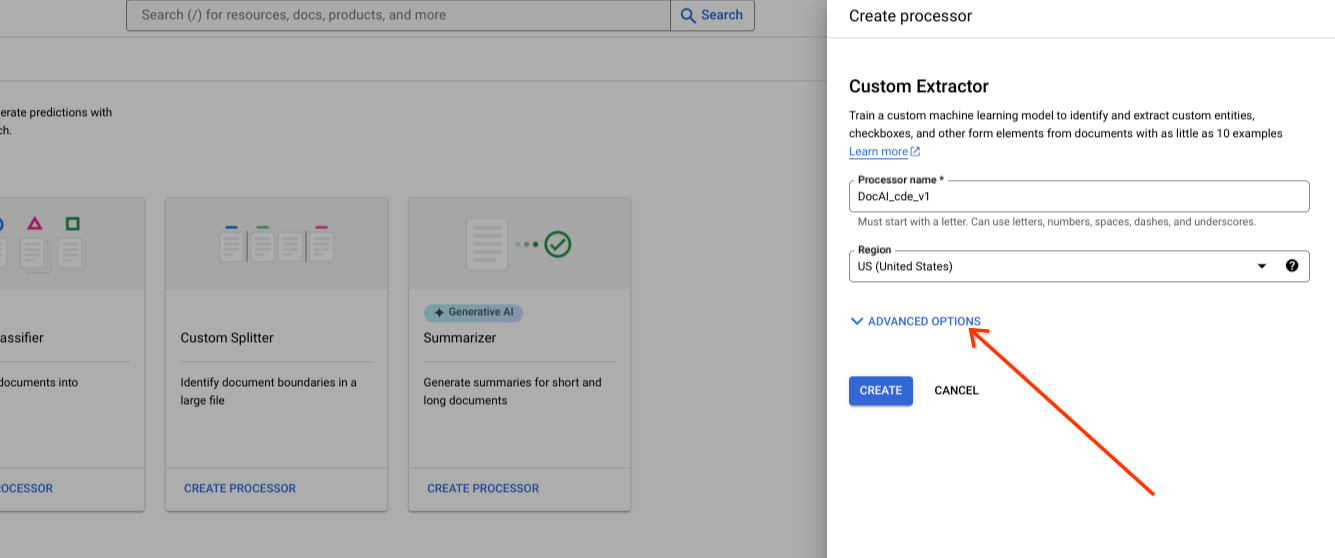
Mantén la opción de grupo de radios predeterminada Almacenamiento gestionado por Google.
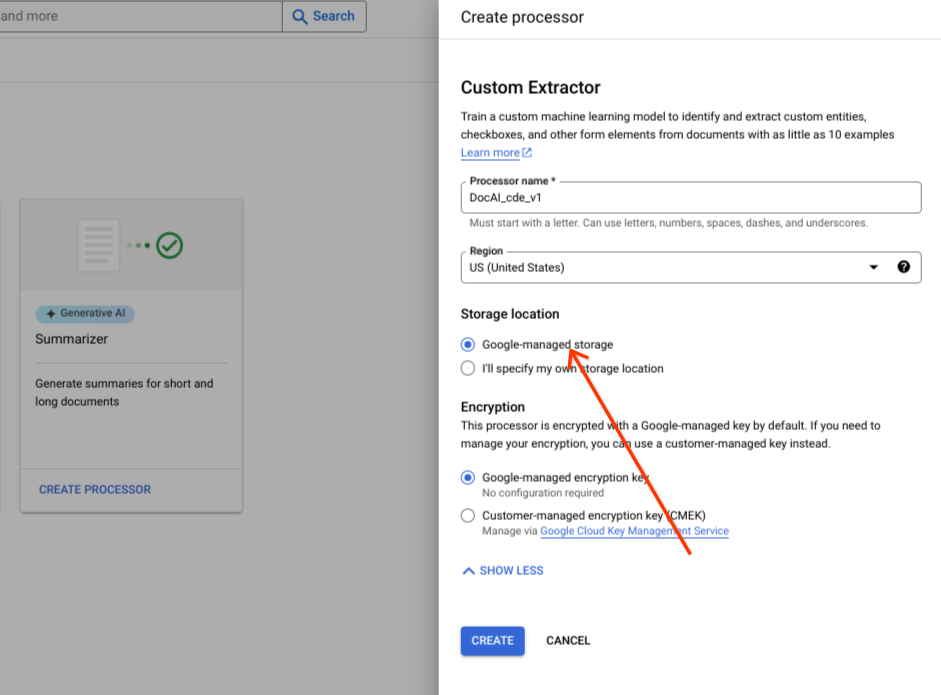
Selecciona Crear.

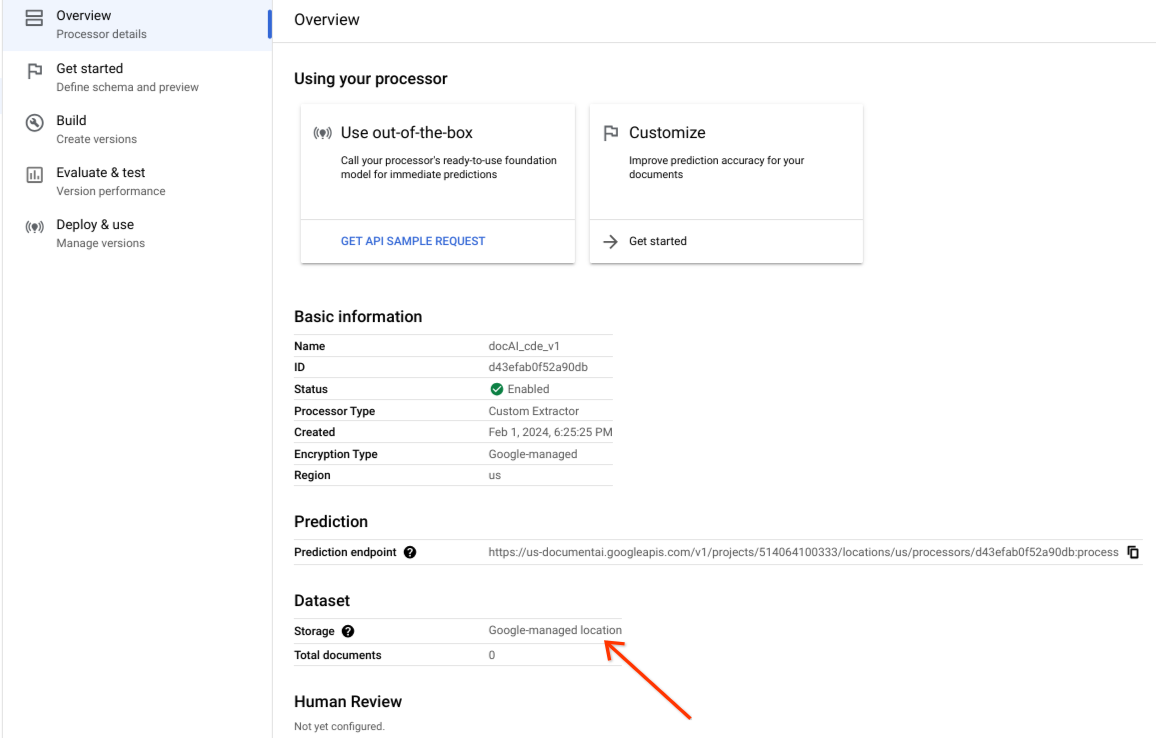
Confirma que el conjunto de datos se ha creado correctamente y que su ubicación es Ubicación gestionada por Google.
Opción de almacenamiento personalizado
Activa o desactiva las opciones avanzadas.
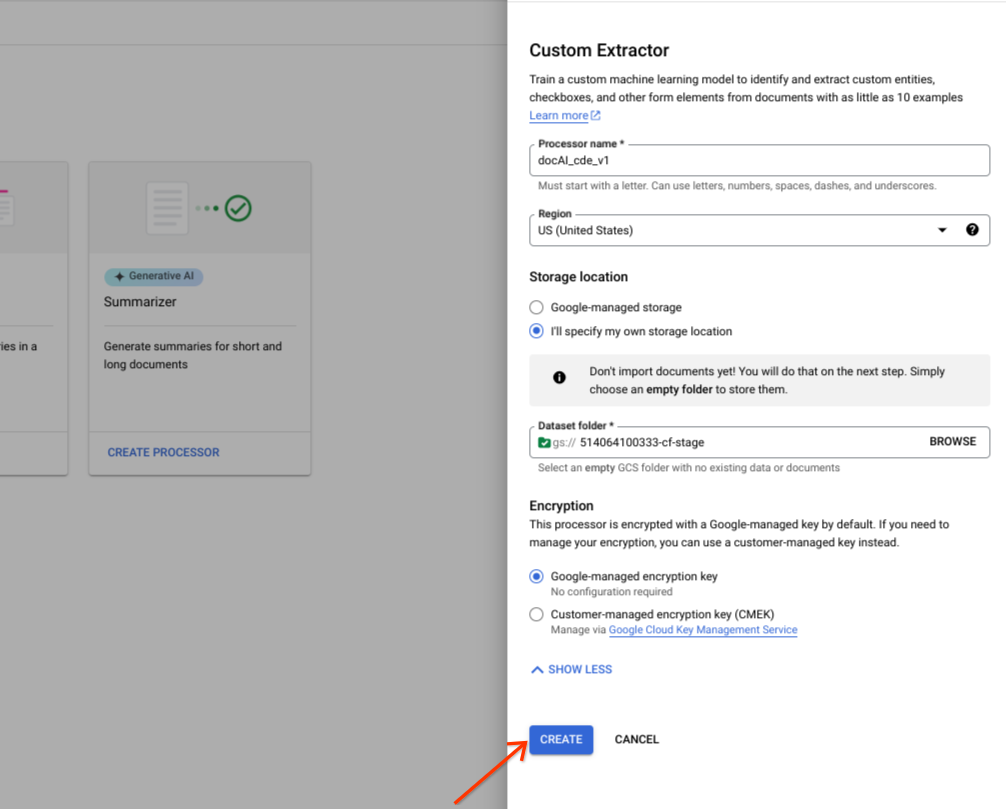
Selecciona Especificaré mi propia ubicación de almacenamiento.
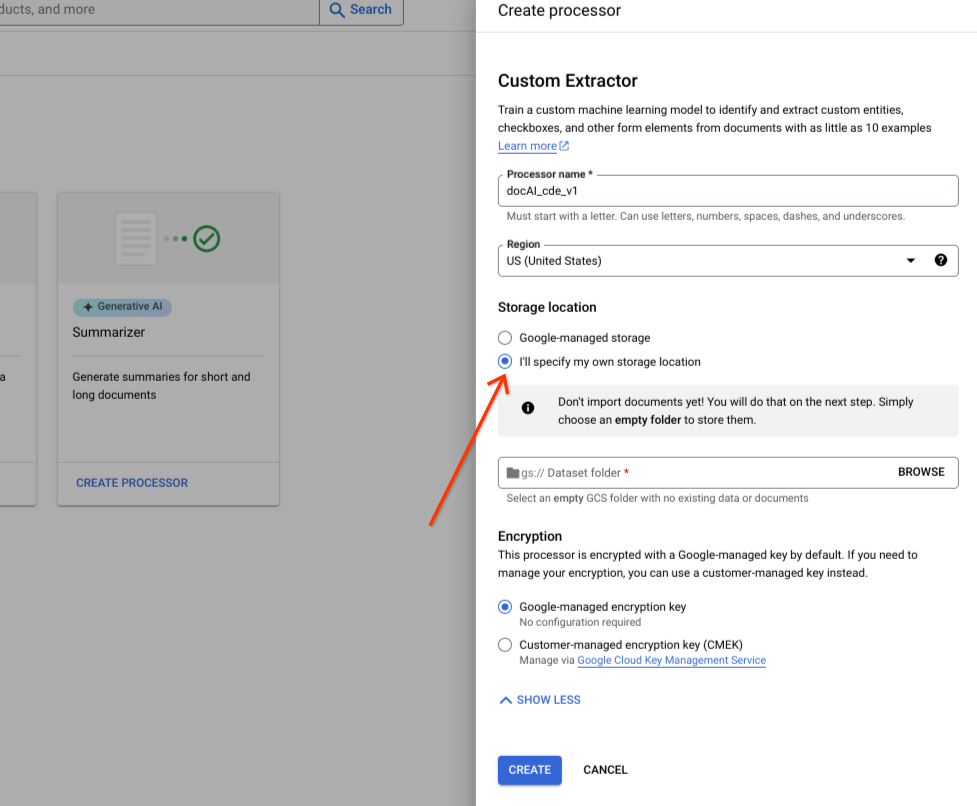
Elige una carpeta de Cloud Storage en el componente de entrada.
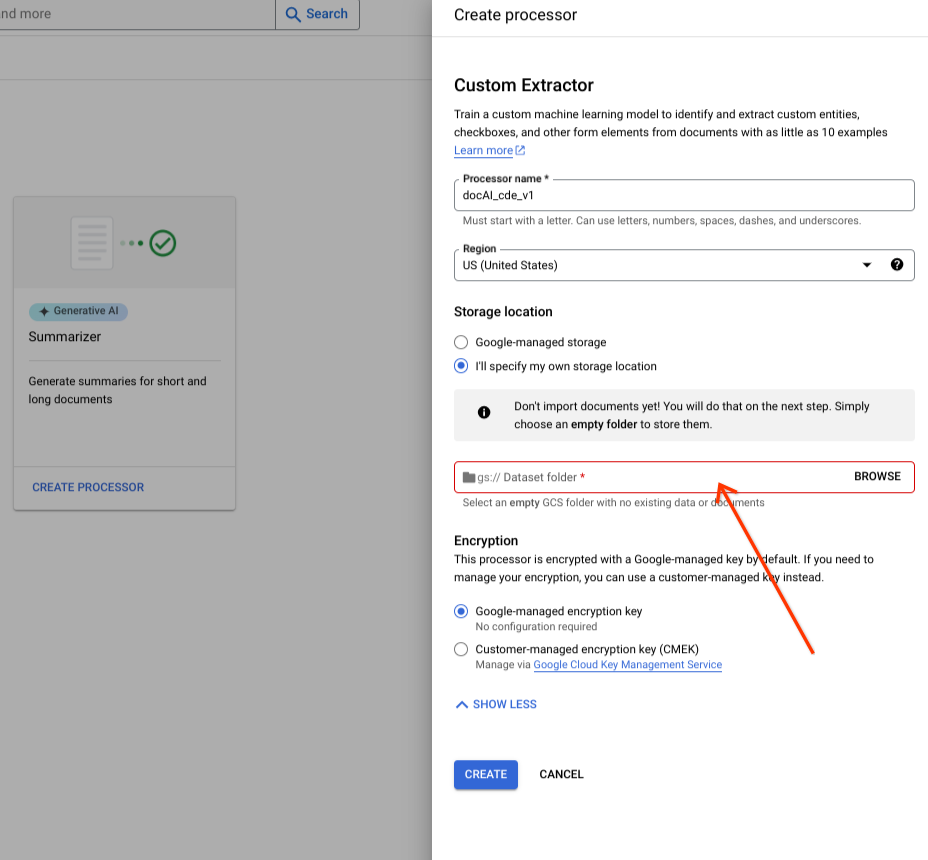
Selecciona Crear.
Operaciones de la API Dataset
En este ejemplo se muestra cómo usar el método processors.updateDataset para crear un conjunto de datos. Un recurso de conjunto de datos es un recurso singleton en un procesador, lo que significa que no hay ninguna RPC de creación de recursos. En su lugar, puedes usar el
RPC updateDataset para definir las preferencias. Document AI ofrece la opción de almacenar los documentos del conjunto de datos en un segmento de Cloud Storage que proporciones o de que Google los gestione automáticamente.
Antes de usar los datos de la solicitud, haz las siguientes sustituciones:
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID The ID of your custom processor
GCS_URI: Your Cloud Storage URI where dataset documents are stored
Segmento proporcionado
Sigue los pasos que se indican a continuación para crear una solicitud de conjunto de datos con un segmento de Cloud Storage que proporciones.
Método HTTP
PATCH https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/datasetSolicitud JSON:
{
"name":"projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset"
"gcs_managed_config" {
"gcs_prefix" {
"gcs_uri_prefix": "GCS_URI"
}
}
"spanner_indexing_config" {}
}Gestionado por Google
Si quieres crear un conjunto de datos gestionado por Google, actualiza la siguiente información:
Método HTTP
PATCH https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/datasetSolicitud JSON:
{
"name":"projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset"
"unmanaged_dataset_config": {}
"spanner_indexing_config": {}
}Para enviar tu solicitud, puedes usar Curl:
Guarda el cuerpo de la solicitud en un archivo llamado request.json. Ejecuta el comando siguiente:
CURL
curl -X PATCH \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset"Deberías recibir una respuesta JSON similar a la siguiente:
{
"name": "projects/PROJECT_ID/locations/LOCATION/operations/OPERATION_ID"
}Importar documentos
Un conjunto de datos recién creado está vacío. Para añadir documentos, selecciona Importar documentos y elige una o varias carpetas de Cloud Storage que contengan los documentos que quieras añadir al conjunto de datos.
Si tu Cloud Storage está en un proyecto Google Cloud diferente, asegúrate de conceder acceso para que Document AI pueda leer archivos de esa ubicación. En concreto, debes conceder el rol Lector de objetos de Storage al agente de servicio principal de Document AI
service-{project-id}@gcp-sa-prod-dai-core.iam.gserviceaccount.com. Para obtener más información, consulta Agentes de servicio.
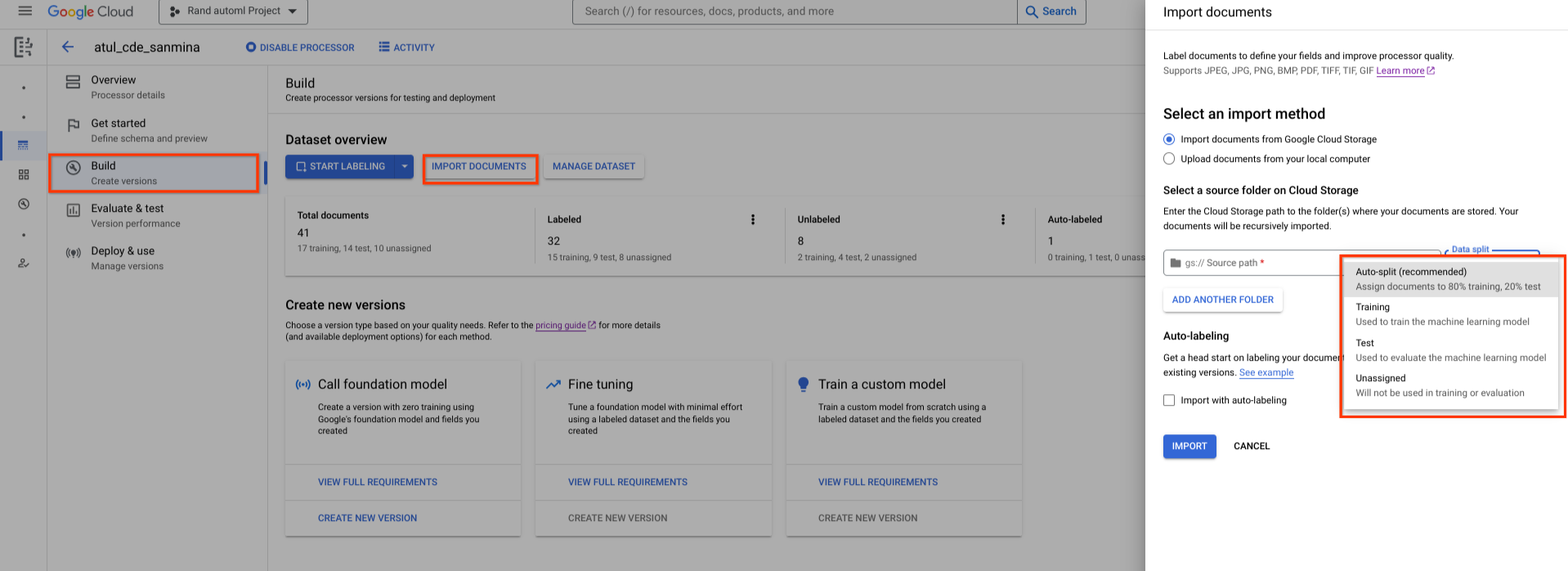
A continuación, elige una de las siguientes opciones de asignación:
- Entrenamiento: asignar al conjunto de entrenamiento.
- Prueba: asigna al conjunto de prueba.
- División automática: baraja aleatoriamente los documentos de los conjuntos de entrenamiento y de prueba.
- Sin asignar: no se usa en el entrenamiento ni en la evaluación. Puedes asignarlos manualmente más adelante.
Siempre puedes modificar las asignaciones más adelante.
Cuando seleccionas Importar, Document AI importa todos los tipos de archivo admitidos, así como los archivos JSON Document, al conjunto de datos. En el caso de los archivos JSON Document, Document AI importa el documento y convierte su entities
en instancias de etiqueta.
Document AI no modifica la carpeta de importación ni lee de ella una vez que se ha completado la importación.
Selecciona Actividad en la parte superior de la página para abrir el panel Actividad, que muestra los archivos que se han importado correctamente y los que no.
Si ya tienes una versión de tu procesador, puedes marcar la casilla Import with auto-labeling (Importar con etiquetado automático) en el cuadro de diálogo Import documents (Importar documentos). Los documentos se etiquetan automáticamente con el procesador anterior cuando se importan. No puedes entrenar ni mejorar el entrenamiento con documentos etiquetados automáticamente, ni usarlos en el conjunto de prueba, sin marcarlos como etiquetados. Después de importar documentos etiquetados automáticamente, revísalos y corrígelos manualmente. A continuación, selecciona Guardar para guardar las correcciones y marcar el documento como etiquetado. A continuación, puedes asignar los documentos según corresponda. Consulte Etiquetado automático.
Import documents RPC
En este ejemplo se muestra cómo usar el método dataset.importDocuments para importar documentos en el conjunto de datos.
Antes de usar los datos de la solicitud, haz las siguientes sustituciones:
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID: The ID of your custom processor
GCS_URI: Your Cloud Storage URI where dataset documents are stored
DATASET_TYPE: The dataset type to which you want to add documents. The value should be either `DATASET_SPLIT_TRAIN` or `DATASET_SPLIT_TEST`.
TRAINING_SPLIT_RATIO: The ratio of documents which you want to autoassign to the training set.
Conjunto de datos de entrenamiento o de prueba
Si quieres añadir documentos al conjunto de datos de entrenamiento o de prueba, sigue estos pasos:
Método HTTP
POST https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/importDocumentsSolicitud JSON:
{
"batch_documents_import_configs": {
"dataset_split": DATASET_TYPE
"batch_input_config": {
"gcs_prefix": {
"gcs_uri_prefix": GCS_URI
}
}
}
}Conjunto de datos de entrenamiento y de prueba
Si quieres dividir automáticamente los documentos entre los conjuntos de datos de entrenamiento y de prueba, sigue estos pasos:
Método HTTP
POST https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/importDocumentsSolicitud JSON:
{
"batch_documents_import_configs": {
"auto_split_config": {
"training_split_ratio": TRAINING_SPLIT_RATIO
},
"batch_input_config": {
"gcs_prefix": {
"gcs_uri_prefix": "gs://test_sbindal/pdfs-1-page/"
}
}
}
}Guarda el cuerpo de la solicitud en un archivo llamado request.json y ejecuta el siguiente comando:
CURL
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/importDocuments"Deberías recibir una respuesta JSON similar a la siguiente:
{
"name": "projects/PROJECT_ID/locations/LOCATION/operations/OPERATION_ID"
}Eliminar documentos RPC
En este ejemplo se muestra cómo usar el método dataset.batchDeleteDocuments para eliminar documentos del conjunto de datos.
Antes de usar los datos de la solicitud, haz las siguientes sustituciones:
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID: The ID of your custom processor
DOCUMENT_ID: The document ID blob returned by <code>ImportDocuments</code> request
Eliminar documentos
Método HTTP
POST https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/batchDeleteDocumentsSolicitud JSON:
{
"dataset_documents": {
"individual_document_ids": {
"document_ids": DOCUMENT_ID
}
}
}Guarda el cuerpo de la solicitud en un archivo llamado request.json y ejecuta el siguiente comando:
CURL
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/batchDeleteDocuments"Deberías recibir una respuesta JSON similar a la siguiente:
{
"name": "projects/PROJECT_ID/locations/LOCATION/operations/OPERATION_ID"
}Asignar documentos a un conjunto de entrenamiento o de prueba
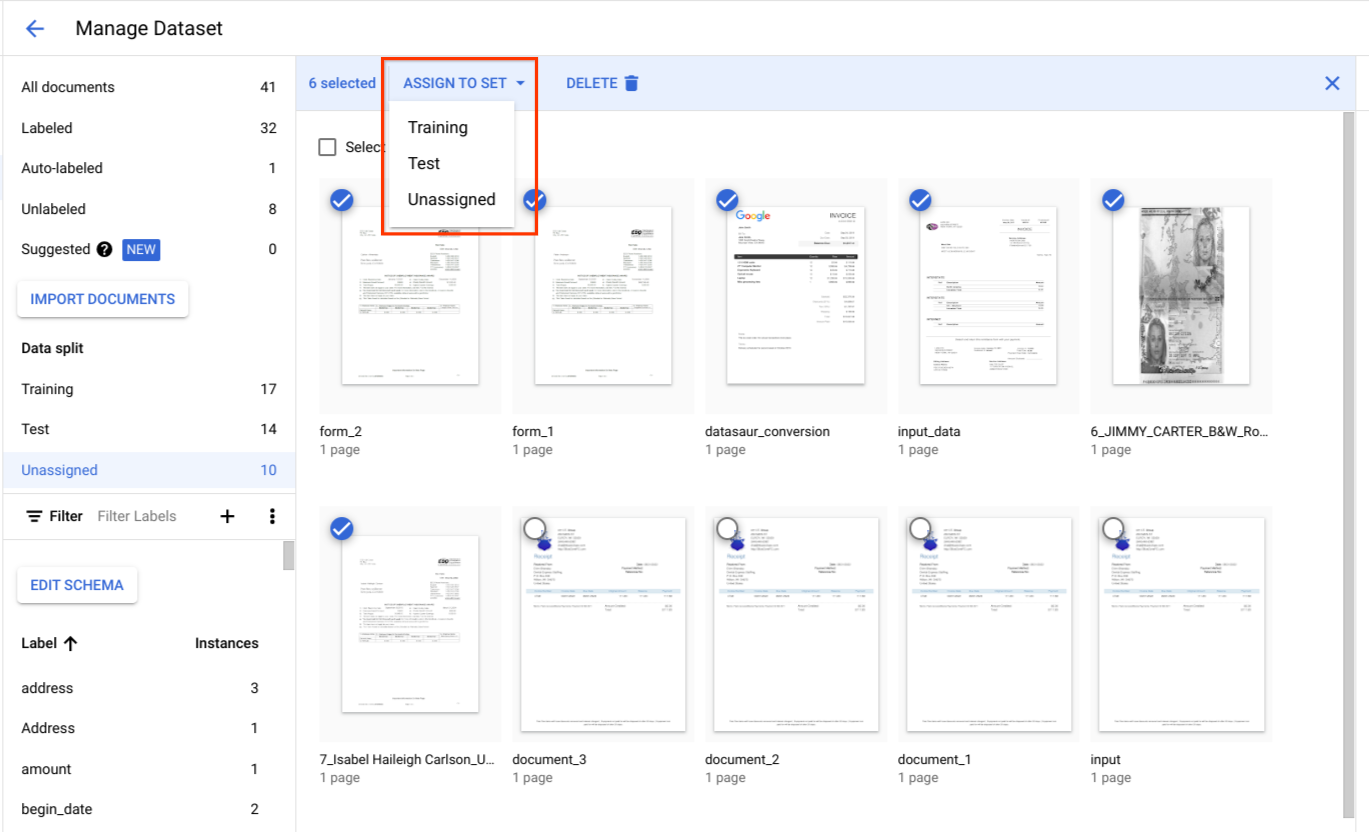
En División de datos, selecciona documentos y asígnalos al conjunto de entrenamiento, al conjunto de prueba o a la categoría Sin asignar.
Prácticas recomendadas para conjuntos de pruebas
La calidad de tu conjunto de prueba determina la calidad de tu evaluación.
El conjunto de pruebas debe crearse al principio del ciclo de desarrollo del procesador y bloquearse para que puedas monitorizar la calidad del procesador a lo largo del tiempo.
Recomendamos que el conjunto de prueba tenga al menos 100 documentos por tipo de documento. Es fundamental asegurarse de que el conjunto de pruebas sea representativo de los tipos de documentos que los clientes utilizan para el modelo que se está desarrollando.
El conjunto de pruebas debe ser representativo del tráfico de producción en términos de frecuencia. Por ejemplo, si procesa formularios W2 y espera que el 70% corresponda al año 2020 y el 30% al año 2019, aproximadamente el 70% del conjunto de prueba debe estar formado por documentos W2 del 2020. Esta composición del conjunto de pruebas asegura que se dé la importancia adecuada a cada subtipo de documento al evaluar el rendimiento del procesador. Además, si extraes nombres de personas de formularios internacionales, asegúrate de que tu conjunto de pruebas incluya formularios de todos los países a los que te diriges.
Prácticas recomendadas para el conjunto de entrenamiento
Los documentos que ya se hayan incluido en el conjunto de prueba no deben incluirse en el conjunto de entrenamiento.
A diferencia del conjunto de prueba, el conjunto de entrenamiento final no tiene que ser tan representativo del uso que hacen los clientes en cuanto a la diversidad o la frecuencia de los documentos. Algunas etiquetas son más difíciles de entrenar que otras. Por lo tanto, es posible que obtengas un mejor rendimiento si sesgas el conjunto de entrenamiento hacia esas etiquetas.
Al principio, no hay una forma sencilla de saber qué etiquetas son difíciles. Debes empezar con un conjunto de entrenamiento inicial pequeño y muestreado aleatoriamente. Para ello, sigue el mismo enfoque que se ha descrito para el conjunto de prueba. Este conjunto de entrenamiento inicial debe contener aproximadamente el 10% del número total de documentos que quieras anotar. Después, puedes evaluar de forma iterativa la calidad del procesador (buscando patrones de error específicos) y añadir más datos de entrenamiento.
Definir el esquema del procesador
Después de crear un conjunto de datos, puedes definir un esquema de procesador antes o después de importar documentos.
El procesador schema define las etiquetas, como el nombre y la dirección, que se van a extraer de tus documentos.
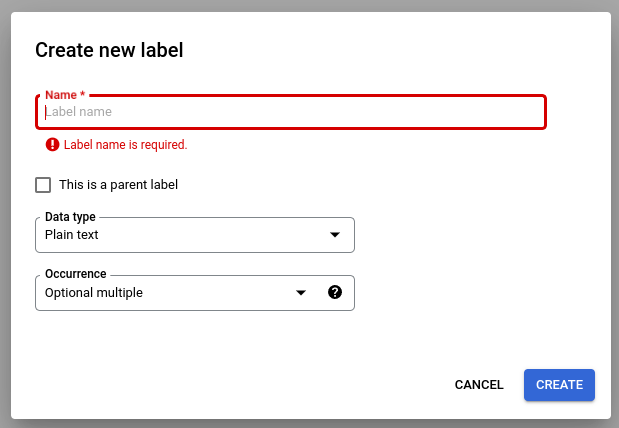
Selecciona Editar esquema y, a continuación, crea, edita, habilita e inhabilita etiquetas según sea necesario.
Cuando hayas terminado, selecciona Guardar.
Notas sobre la gestión de etiquetas de esquemas:
Una vez que se ha creado una etiqueta de esquema, no se puede editar su nombre.
Una etiqueta de esquema solo se puede editar o eliminar cuando no haya versiones de procesador entrenadas. Solo se pueden editar el tipo de datos y el tipo de ocurrencia.
Deshabilitar una etiqueta tampoco afecta a la predicción. Cuando envías una solicitud de procesamiento, la versión del procesador extrae todas las etiquetas que estaban activas en el momento del entrenamiento.
Obtener el esquema de datos
En este ejemplo se muestra cómo usar getDatasetSchema para obtener el esquema actual del conjunto de datos. DatasetSchema es un recurso singleton que se crea automáticamente al crear un recurso de conjunto de datos.
Antes de usar los datos de la solicitud, haz las siguientes sustituciones:
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID: The ID of your custom processor
Obtener el esquema de datos
Método HTTP
GET https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchemaCURL
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchema"Deberías recibir una respuesta JSON similar a la siguiente:
{
"name": "projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchema",
"documentSchema": {
"entityTypes": [
{
"name": $SCHEMA_NAME,
"baseTypes": [
"document"
],
"properties": [
{
"name": $LABEL_NAME,
"valueType": $VALUE_TYPE,
"occurrenceType": $OCCURRENCE_TYPE,
"propertyMetadata": {}
},
],
"entityTypeMetadata": {}
}
]
}
}Actualizar el esquema de un documento
En este ejemplo se muestra cómo usar dataset.updateDatasetSchema para actualizar el esquema actual. En este ejemplo se muestra un comando para actualizar el esquema del conjunto de datos de forma que tenga una etiqueta. Si quieres añadir una etiqueta, pero no eliminar ni actualizar las que ya tienes, puedes llamar a getDatasetSchema primero y hacer los cambios oportunos en su respuesta.
Antes de usar los datos de la solicitud, haz las siguientes sustituciones:
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID: The ID of your custom processor
LABEL_NAME: The label name which you want to add
LABEL_DESCRIPTION: Describe what the label represents
DATA_TYPE: The type of the label. You can specify this as string, number, currency, money, datetime, address, boolean.
OCCURRENCE_TYPE: Describes the number of times this label is expected. Pick an enum value.
Actualizar esquema
Método HTTP
PATCH https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchemaSolicitud JSON:
{
"document_schema": {
"entityTypes": [
{
"name": $SCHEMA_NAME,
"baseTypes": [
"document"
],
"properties": [
{
"name": LABEL_NAME,
"description": LABEL_DESCRIPTION,
"valueType": DATA_TYPE,
"occurrenceType": OCCURRENCE_TYPE,
"propertyMetadata": {}
},
],
"entityTypeMetadata": {}
}
]
}
}Guarda el cuerpo de la solicitud en un archivo llamado request.json y ejecuta el siguiente comando:
CURL
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchema"Elegir atributos de etiqueta
Data type (Dato)
Plain text: un valor de cadena.Number: un número entero o de punto flotante.Money: un importe de valor monetario. Cuando añada etiquetas, no incluya el símbolo de la moneda.- Cuando se extrae la entidad, se normaliza a
google.type.Money.
- Cuando se extrae la entidad, se normaliza a
Currency: símbolo de moneda.Datetime: un valor de fecha u hora.- Cuando se extrae la entidad, se normaliza al formato de texto
ISO 8601.
- Cuando se extrae la entidad, se normaliza al formato de texto
Address: una dirección de ubicación.- Cuando se extrae la entidad, se normaliza y se enriquece con EKG.
Checkbox: un valor booleanotrueofalse.Signature: valor booleanotrueofalseennormalized_value.signature_valueque indica si hay una firma. Admite los métodosderive.mention_text: un valor booleanoDetectedo un valor booleano vacío""enhas_signedque indica si hay una firma. Admite los métodosderive.normalized_value.text: un valor booleanoDetectedo un valor booleano vacío""enhas_signedque indica si hay una firma. Admite los métodosderive.normalized_value.boolean_valueno se rellena.
Método
- Cuando la entidad es
extracted, tiene los campostextAnchor,type,mentionTextypageAnchorrellenados. - Cuando la entidad es
derived, es posible que los valores derivados no estén presentes en el texto del documento. No tiene los campostextAnchorypageAnchor.pageRefs[].bounding_polyrellenados.
Ocurrencia
Elige REQUIRED si una entidad siempre debe aparecer en documentos de un tipo determinado. Elige OPTIONAL si no tienes esa expectativa.
Elige ONCE si se espera que una entidad tenga un valor, aunque el mismo valor aparezca varias veces en el mismo documento. Elige MULTIPLE si se espera que una entidad tenga varios valores.
Etiquetas superiores y secundarias
Las etiquetas de elementos que dependen unos de otros (también denominadas "entidades tabulares") se usan para etiquetar datos en una tabla. La siguiente tabla contiene 3 filas y 4 columnas.

Puedes definir estas tablas con etiquetas de elementos superiores y secundarios. En este ejemplo, la etiqueta superior line-item define una fila de la tabla.
Crear una etiqueta principal
En la página Editar esquema, selecciona Crear etiqueta.
Marca la casilla Esta es una etiqueta principal e introduce el resto de la información. La etiqueta superior debe tener una instancia de
optional_multipleorequire_multiplepara que se pueda repetir y capturar todas las filas de la tabla.Selecciona Guardar.
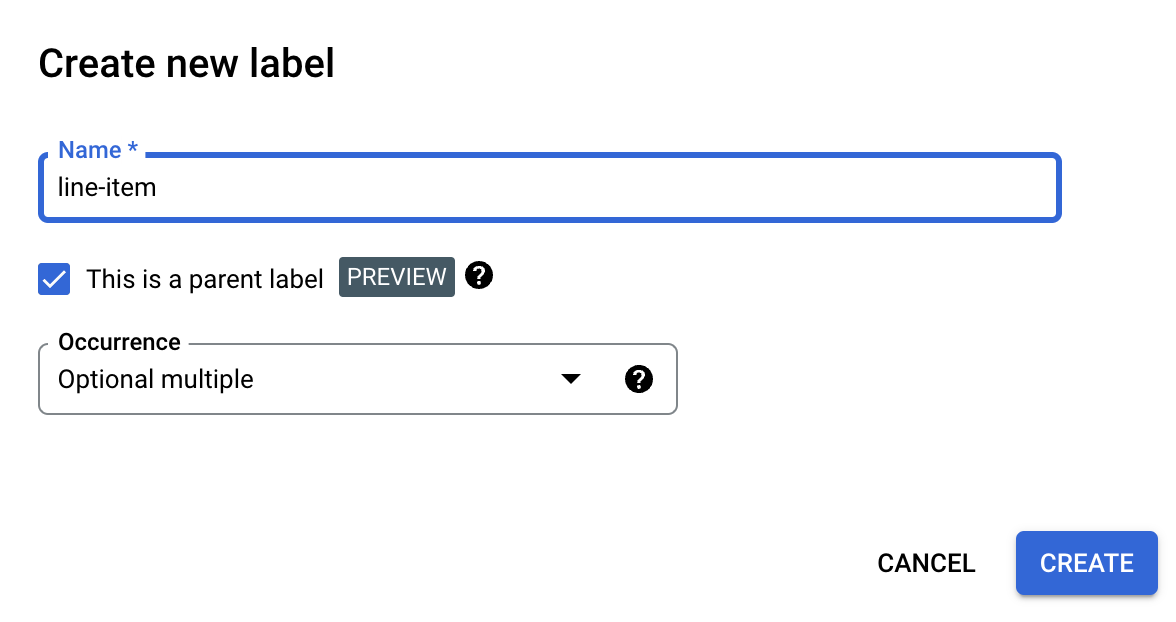
La etiqueta superior aparece en la página Editar esquema, con la opción Añadir etiqueta secundaria junto a ella.
Para crear una etiqueta secundaria, sigue estos pasos:
Junto a la etiqueta principal de la página Editar esquema, selecciona Añadir etiqueta secundaria.
Introduce la información de la etiqueta secundaria.
Selecciona Guardar.
Repite este proceso con cada etiqueta secundaria que quieras añadir.
Las etiquetas secundarias aparecen indentadas debajo de la etiqueta principal en la página Editar esquema.

Las etiquetas de elementos principales y secundarios son una función de vista previa y solo se admiten en tablas. La profundidad de anidación está limitada a 1, lo que significa que las entidades secundarias no pueden contener otras entidades secundarias.
Crear etiquetas de esquema a partir de documentos etiquetados
Crea automáticamente etiquetas de esquema importando archivos JSON Document preetiquetados.
Mientras se lleva a cabo la importación de Document, las etiquetas de esquema que se añadan se agregarán al editor de esquemas. Seleccione "Editar esquema" para verificar o cambiar el tipo de datos y el tipo de ocurrencia de las nuevas etiquetas del esquema. Una vez que lo hayas confirmado, selecciona las etiquetas de esquema y, a continuación, Habilitar.
Conjuntos de datos de ejemplo
Para ayudarte a empezar a usar Document AI Workbench, se proporcionan conjuntos de datos en un contenedor público de Cloud Storage que incluye archivos JSON de ejemplo Document etiquetados y sin etiquetar de varios tipos de documentos.
Se pueden usar para entrenar modelos o extractores personalizados en función del tipo de documento.
gs://cloud-samples-data/documentai/Custom/
gs://cloud-samples-data/documentai/Custom/1040/
gs://cloud-samples-data/documentai/Custom/Invoices/
gs://cloud-samples-data/documentai/Custom/Patents/
gs://cloud-samples-data/documentai/Custom/Procurement-Splitter/
gs://cloud-samples-data/documentai/Custom/W2-redacted/
gs://cloud-samples-data/documentai/Custom/W2/
gs://cloud-samples-data/documentai/Custom/W9/