自訂分割器
自訂分割器的用途是藉由識別每個邏輯文件,將複合文件 (由多個類別組成的文件) 分割成單一類別文件。舉例來說,貸款文件組合內含多個類別,例如申請資料、收入驗證和附相片的身分證件。如要使用自訂分割器處理器,您需要使用自己的文件和自訂類別,從頭開始訓練。
分割器說明和用法
您可以建立文件專屬的自訂分割器,並透過資料進行訓練和評估。這個處理器會根據使用者定義的類別集找出文件類別。完成訓練後,您可以在其他正式版文件中使用該處理器。您通常會對由不同邏輯文件類型組成的檔案使用自訂分割器,然後使用每個文件的類型識別,將文件傳送至適當的擷取處理器來擷取實體。
由於機器學習模型並非完美無缺,會有一定的錯誤率。且分割作業如果發生錯誤,通常會造成非常大的問題 (分割不當會導致兩份文件出錯,並發生擷取錯誤),因此最佳做法是一律在進行分割預測後採取專人審查步驟,接著才實際進行檔案分割作業。視業務需求而定,除了一律進行專人審查以外,還有其他替代方案:
- 在預測中使用可信度分數,決定是否要略過專人審查 (如果分數夠高)。可信度分數的門檻依據,應取決於特定可信度分數下的錯誤率歷來資料。您可以依據業務流程對於錯誤的容許程度與需求,決定是否要略過專人審查。
- 在某些用途中,系統可根據預測的類別,將分割文件直接轉送至適當的擷取器。接著,如果擷取作業不完整或可信度分數偏低,系統會隔離分割文件,並觸發原始的複合文件與分割決定,然後進行審核程序。這牽涉到複雜的工作流程需求。
在 Google Cloud 控制台建立自訂分割器
本快速入門指南說明如何使用 Document AI 建立及訓練自訂分割器,以便分割及分類採購文件。大部分文件前置作業已經完成,因此您可以專心建立自訂分割工具。
建立及使用自訂分割器的典型工作流程如下:
- 在 Document AI 中建立自訂分割器。
- 使用空白的 Cloud Storage bucket 建立資料集。
- 定義及建立處理器結構定義 (類別)。
- 匯入文件。
- 將文件指派給訓練集和測試集。
- 在 Document AI 或標籤工作中,手動為文件加上註解。
- 訓練處理器。
- 評估處理器。
- 部署處理器。
- 測試處理器。
- 使用處理器分類文件。
如果您依類別將文件儲存在不同的資料夾中,則可在匯入時指定類別,略過步驟 6。
如要直接在 Google Cloud 控制台按照逐步指南操作,請按一下「Guide me」(逐步引導):
事前準備
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. 在 Google Cloud 控制台,依序前往「Document AI」專區和「Workbench」頁面。
針對「Custom Document Splitter」(自訂文件分割器),選取
「Create processor」(建立處理器) 。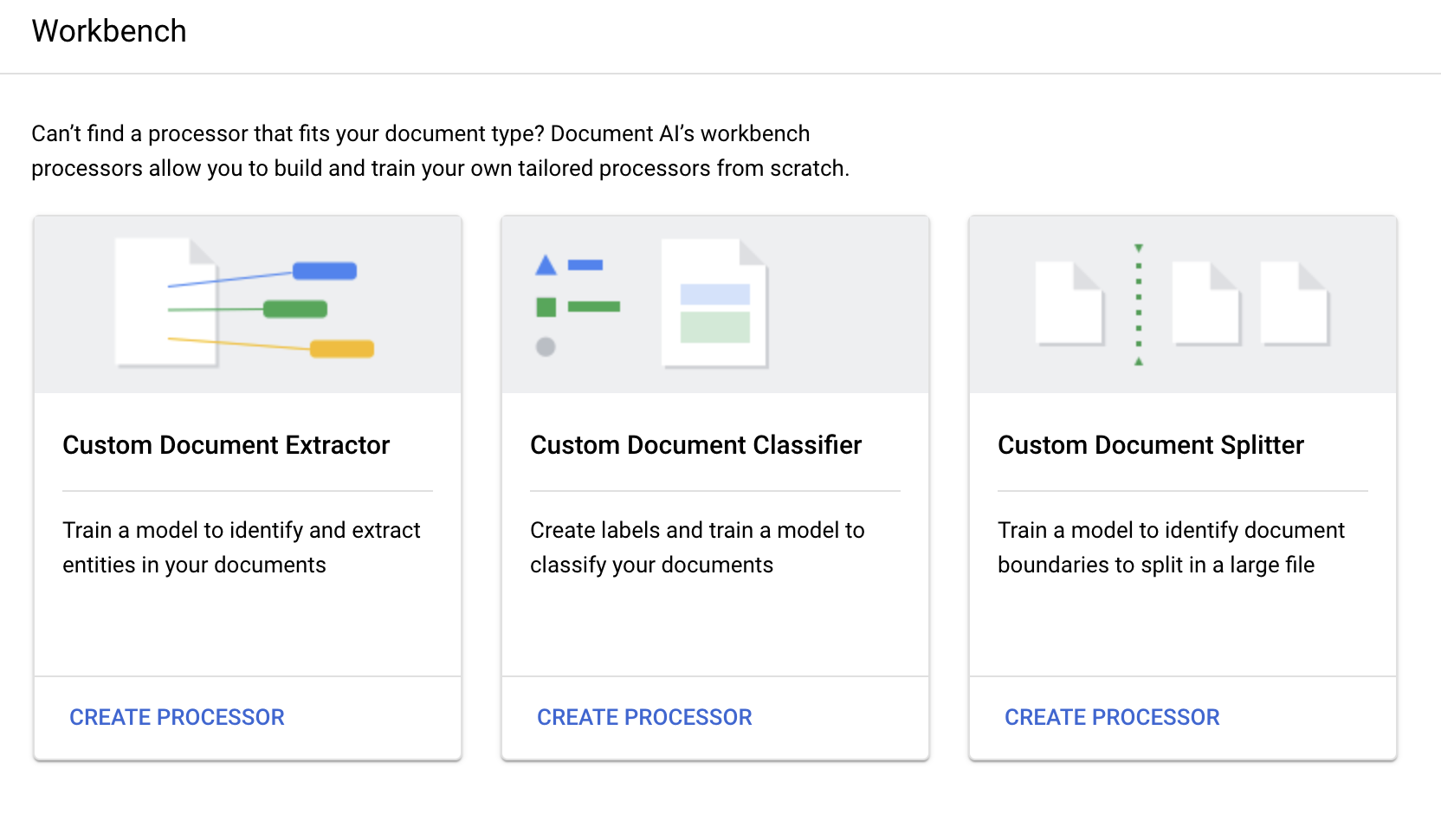
在「Create processor」(建立處理器) 選單中,輸入處理器名稱,例如
my-custom-document-splitter。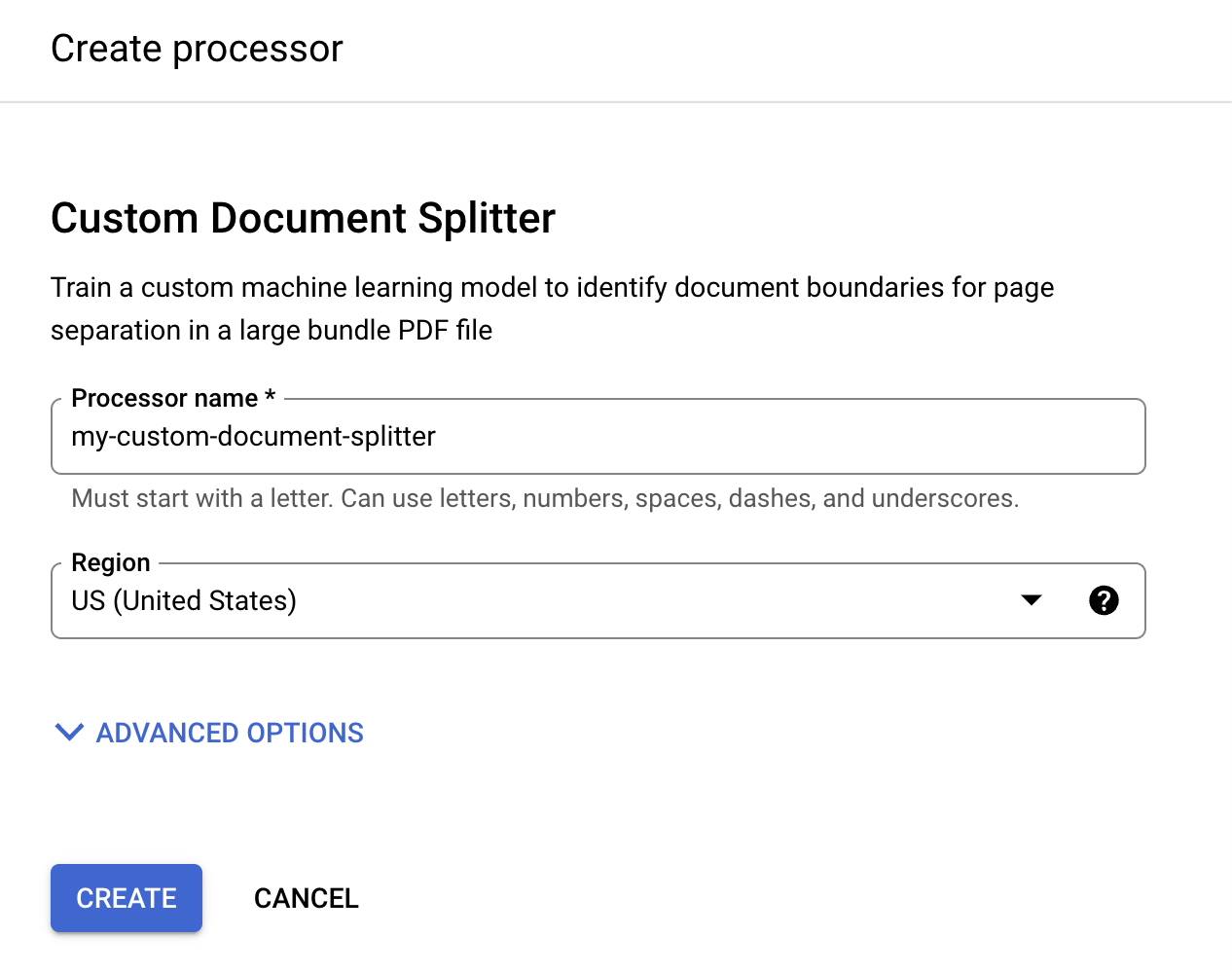
請選取最近的區域。
選取 [Create] (建立)。系統會隨即顯示「Processor Details」(處理器詳細資料) 分頁。
- 如要使用「Google-managed storage」(Google 代管的儲存空間),請選取該選項。
- 如要使用自己的儲存空間,以便使用客戶自行管理的加密金鑰 (CMEK),請選取「I’ll target your own storage location」(自行指定儲存空間位置),然後依照後續程序操作。
前往處理器的
「Train」(訓練) 分頁。選取「Set dataset location」(設定資料集位置)。系統會提示您選取或建立空白的 Cloud Storage bucket 或資料夾。
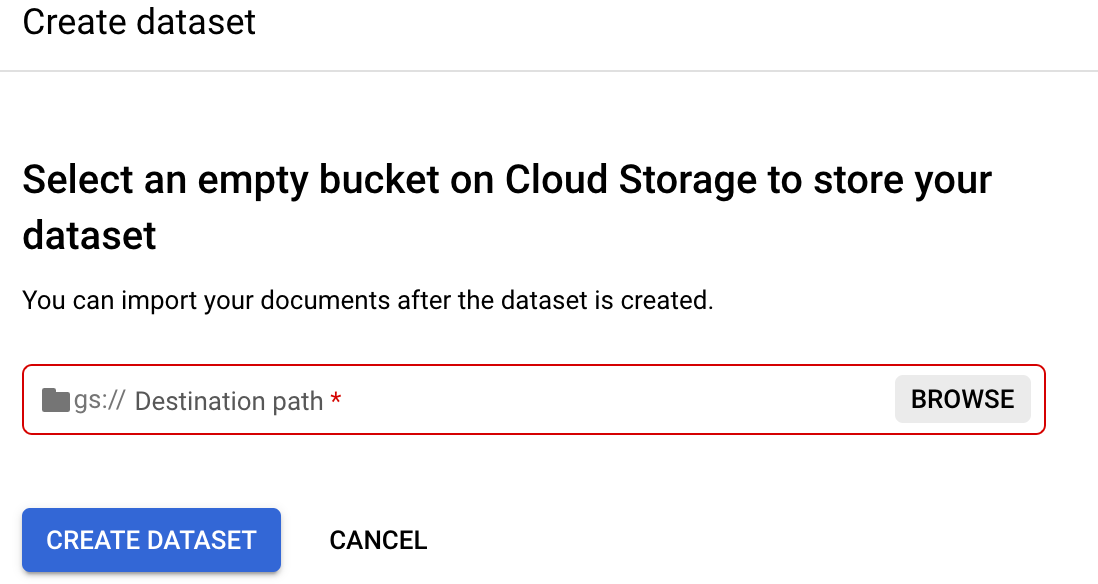
選取「Browse」(瀏覽),開啟「Select folder」(選取資料夾)。
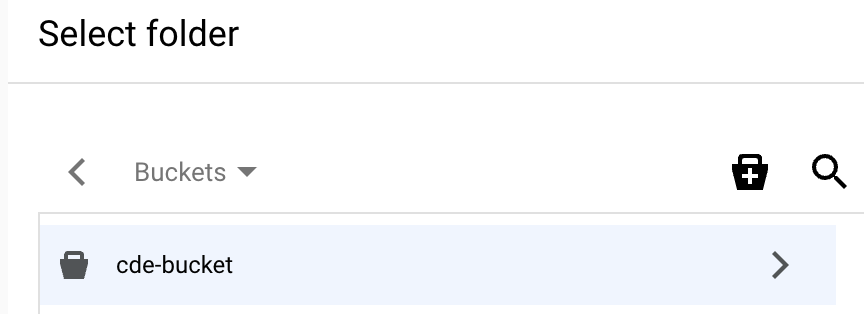
按一下「Create a new bucket」(建立新值區) 圖示,然後按照提示建立新的值區。建立值區後,畫面上會顯示該值區的「Select folder」(選取資料夾) 頁面。如要進一步瞭解如何建立 Cloud Storage bucket,請參閱 Cloud Storage bucket 相關說明。
在值區的「Select folder」(選取資料夾) 頁面中,按一下對話方塊底部的「Select」(選取) 按鈕。
在「Train」(訓練) 分頁中,點選左下方的
「Edit Schema」(編輯結構定義) 。系統隨即會開啟「Manage labels」(管理標籤) 頁面。點選
「Create label」(建立標籤) 。輸入標籤名稱。選取 [Create] (建立)。如需建立與編輯結構定義的詳細操作說明,請參閱「定義處理器結構定義」。
為處理器結構定義建立下列每個標籤。
bank_statementform_1040form_w2form_w9paystub
標籤完成後,請點選
「Save」(儲存) 。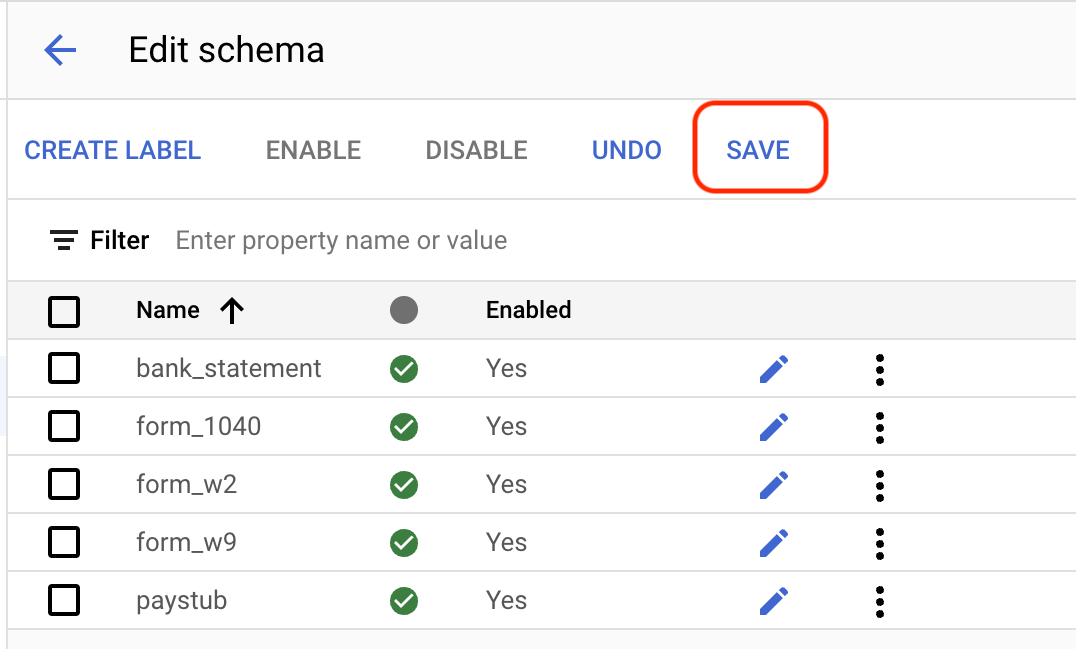
在「Train」(訓練) 分頁中,點選
「Import documents」(匯入文件) 。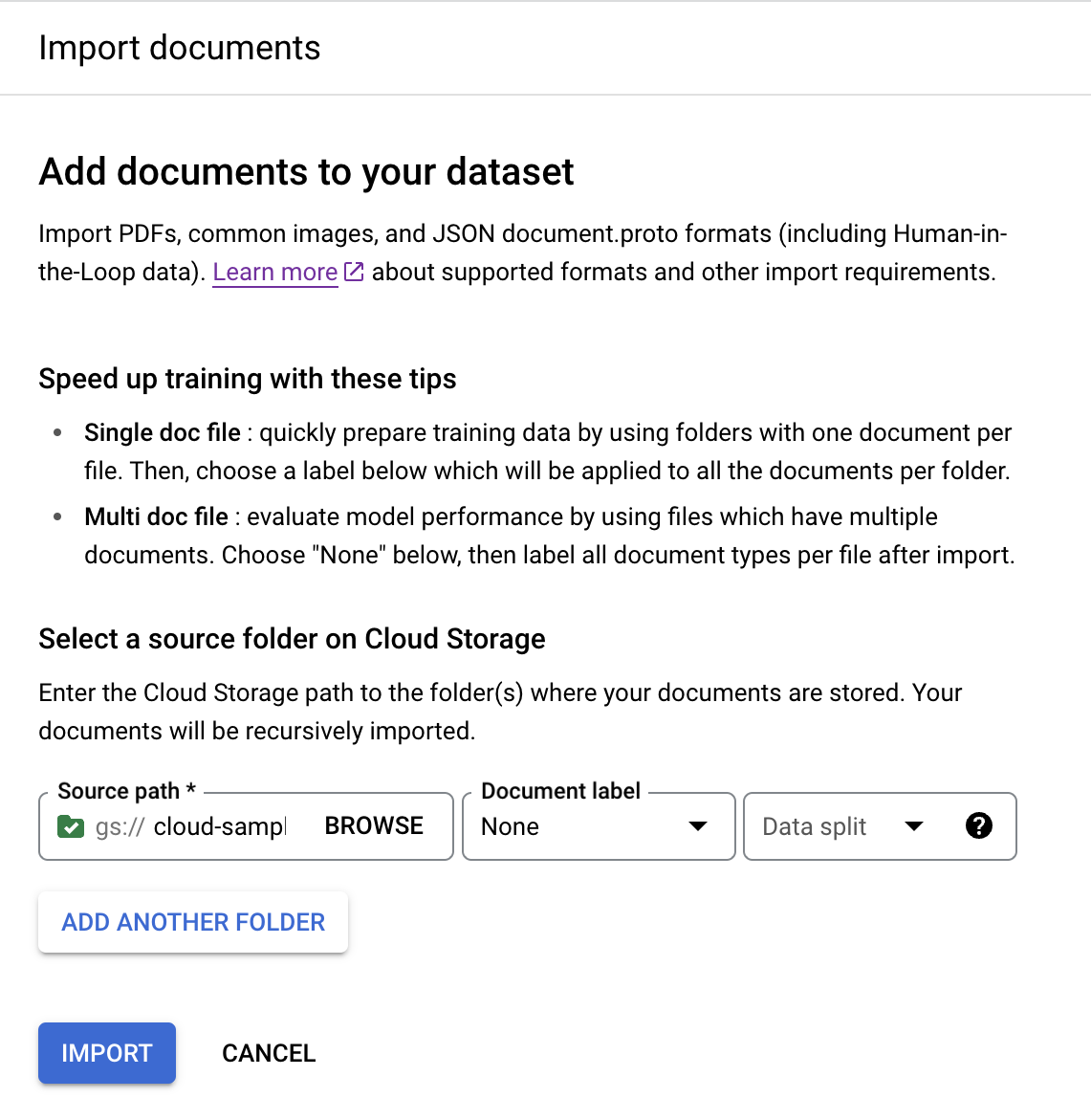
在本例中,請在
「Source path」(來源路徑) 中輸入這個路徑,這個位置有一份文件 PDF 檔。cloud-samples-data/documentai/Custom/Lending-Splitter/PDF-Unlabeled將
「文件標籤」(Document label) 設為「None」(無)。將
「Dataset split」(資料集分割) 下拉式選單設為「Unassigned」(未指派)。根據預設,這個資料夾中的文件未加上標籤,也未指派給測試集或訓練集。
點選
「Import」(匯入) 。 Document AI 會將 bucket 中的文件讀取到資料集,但不會修改匯入 bucket,也不會在匯入完成後從 bucket 讀取資料。- 按一下「Import documents」(匯入文件)。
在「Source path」(來源路徑) 中輸入下列路徑,這個值區含有未加上標籤的文件 (PDF 格式)。
cloud-samples-data/documentai/Custom/Patents/PDF-CDC-BatchLabel在「Data split」(資料分割) 清單中選取「Auto-split」(自動分割),這樣系統就會自動將文件分割為訓練集的 80% 和測試集的 20%。
在「Apply labels」(套用標籤) 區段中,選取「Choose label」(選擇標籤)。
請為這些範例文件選取「other」(其他)。
按一下「Import」(匯入),然後等待系統匯入文件。您可以先離開這個頁面,稍後再返回查看。
回到「Train」(訓練) 分頁,然後點選
某個文件 ,即可開啟「Label management」(標籤管理) 控制台。這份文件含有多個需要識別並加上標籤的頁面群組。首先,請找出分割點。在圖片檢視畫面中的第 1 頁和第 2 頁之間移動滑鼠,並點選
「+」號 。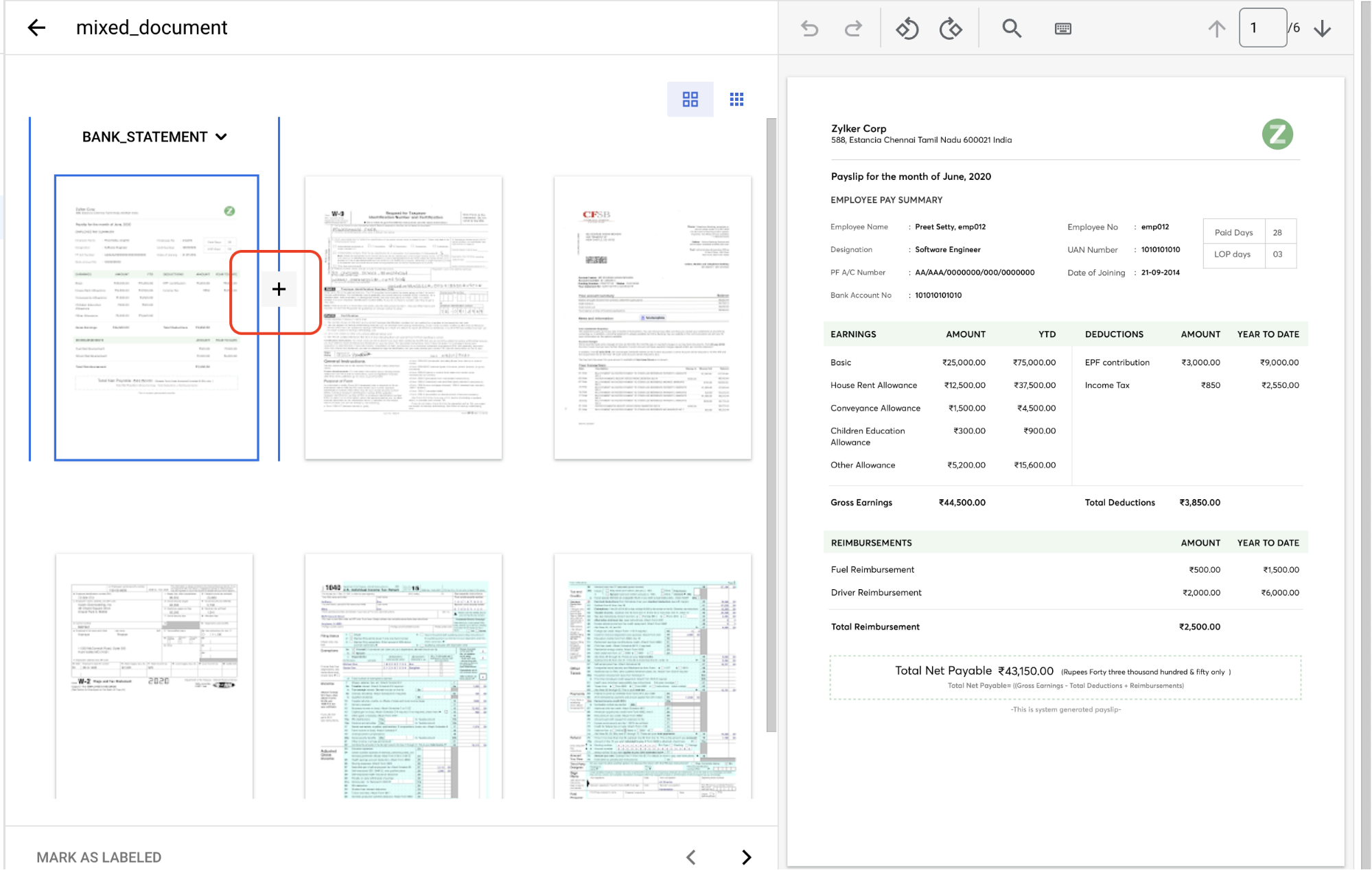
在下列頁數前建立分割點:2、3、4、5。
完成後,控制台應如下所示。
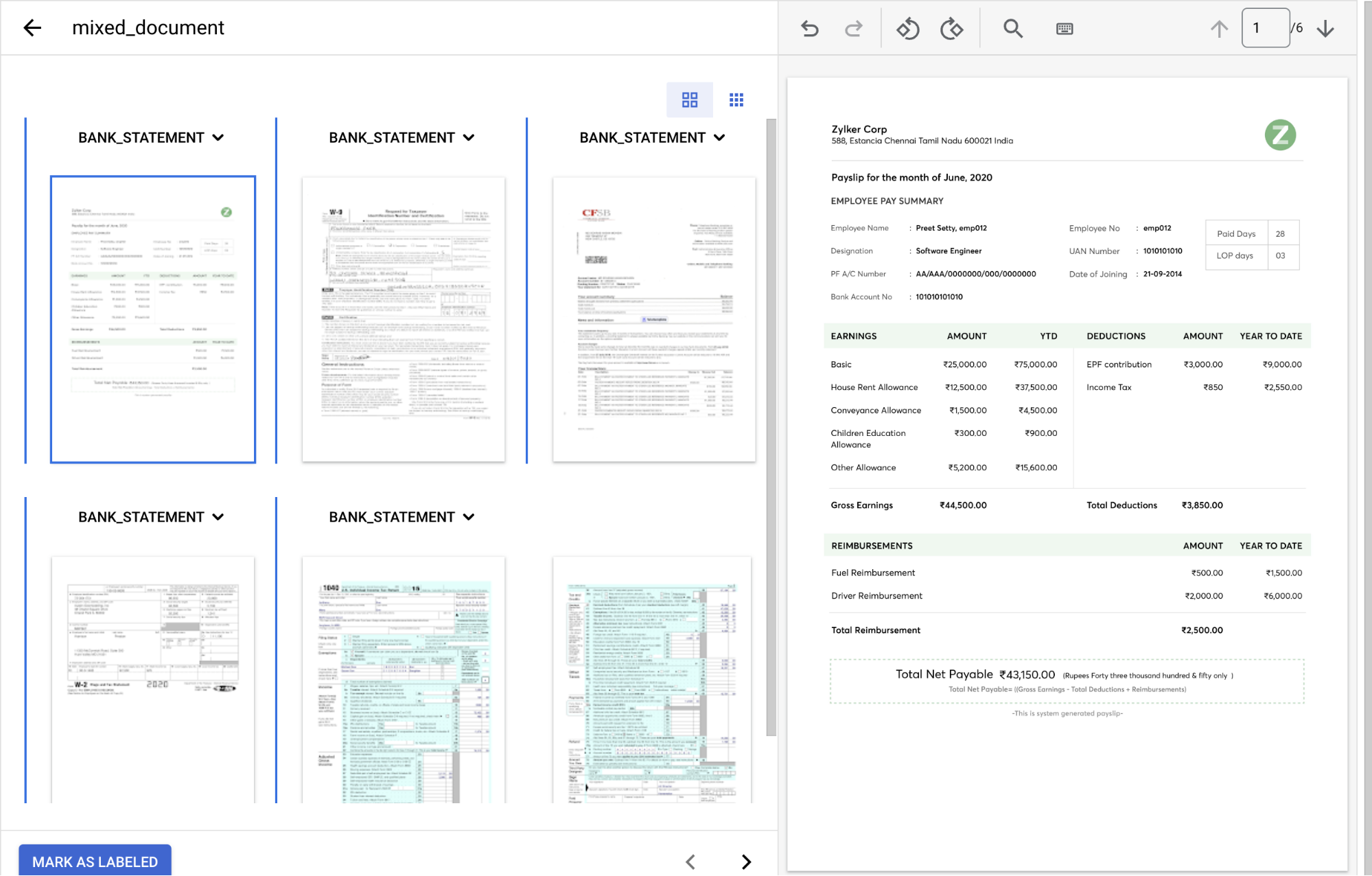
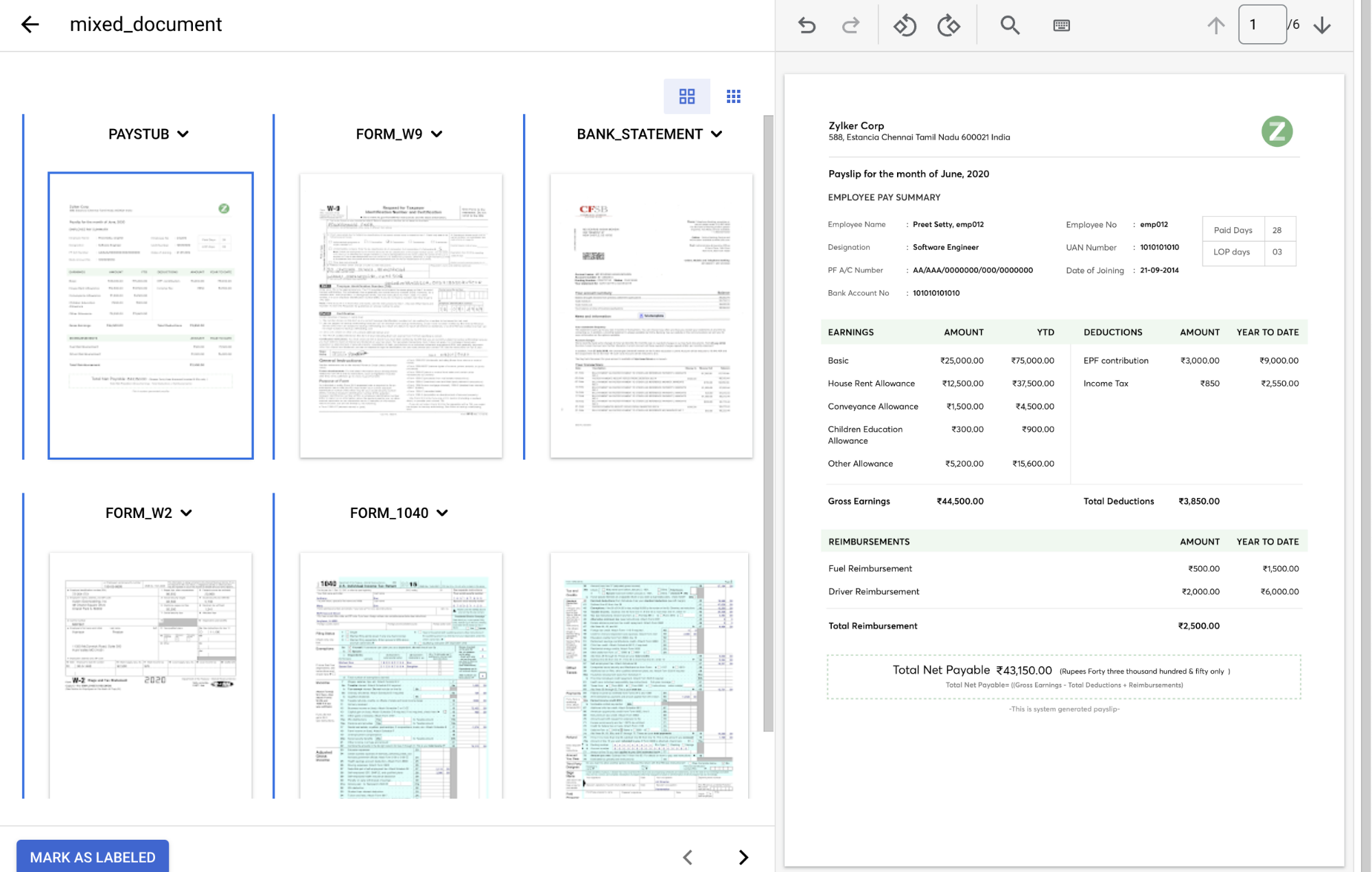
在
「Document type」(文件類型) 下拉式選單中 ,選取各個頁面群組適用的標籤。頁 文件類型 1 paystub2 form_w93 bank_statement4 form_w25 和 6 form_1040完成後,加上標籤的文件應如下所示:
完成文件註解後,請點選
「Mark as Labeled」(標示為已加上標籤) 。在「Train」(訓練) 分頁中,左側面板上會顯示有 1 份文件已加上標籤。
在「Train」(訓練) 分頁中,勾選
「Select All」(全選) 核取方塊。在
「Assign to Set」(指派給資料集) 清單中,選取「Training」(訓練)。在「Train」(訓練) 分頁中,點選
「Import documents」(匯入文件) 。在
「Source path」(來源路徑) 中輸入下列路徑。這個資料夾中有銀行對帳單的 PDF。cloud-samples-data/documentai/Custom/Lending-Splitter/PDF-CDS-BatchLabel/bank-statement將
「Document label」(文件標籤) 設為bank_statement。將
「Dataset split」(資料集分割) 選單設為「Auto-Split」(自動分割)。這樣系統就會自動將文件分割為訓練集的 80% 和測試集的 20%。點選
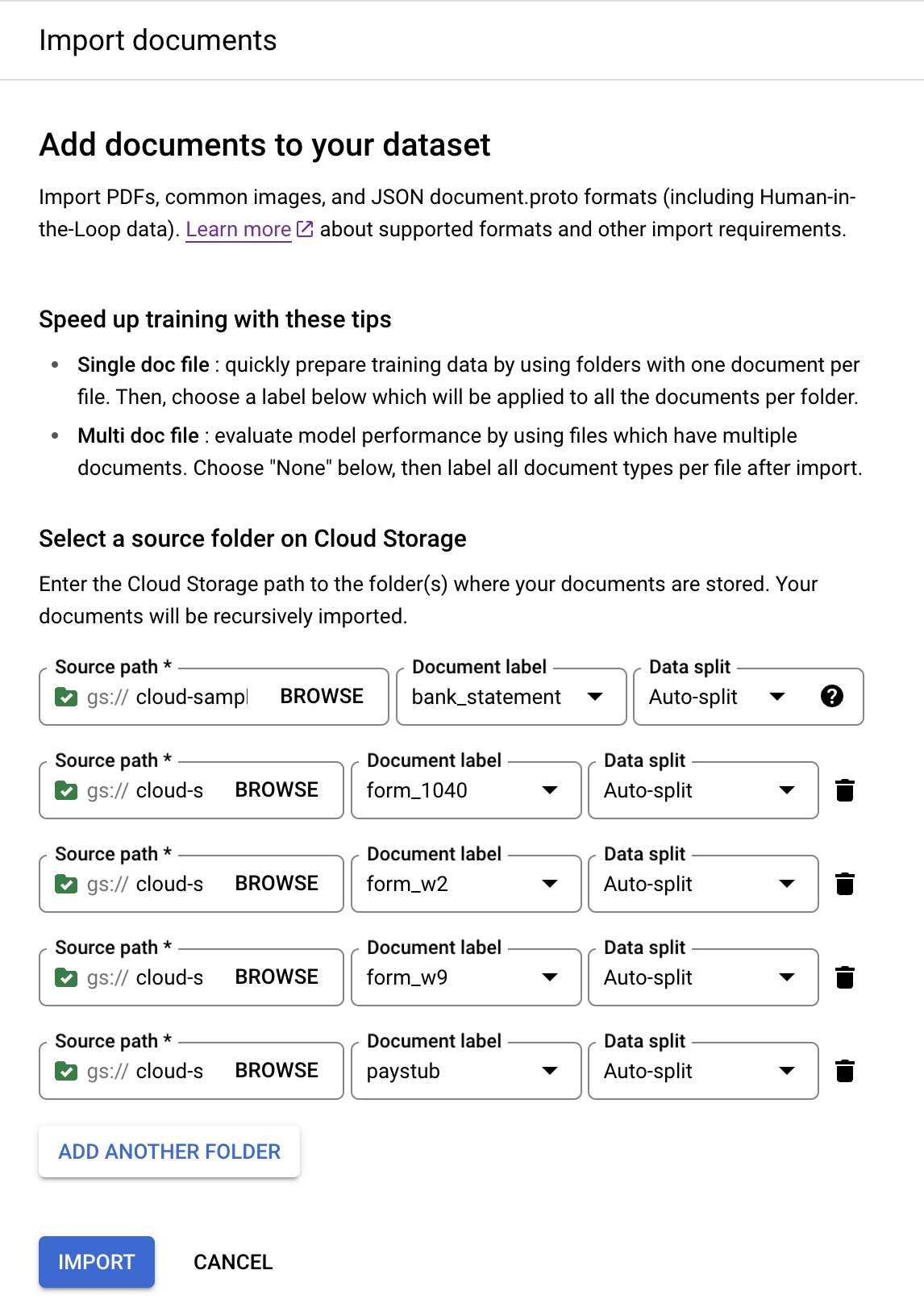
「Add Another Folder」(新增其他資料夾) 即可新增更多資料夾。重複上述步驟,並使用下列路徑和文件標籤:
bucket 路徑 文件標籤 cloud-samples-data/documentai/Custom/Lending-Splitter/PDF-CDS-BatchLabel/1040form_1040cloud-samples-data/documentai/Custom/Lending-Splitter/PDF-CDS-BatchLabel/w2form_w2cloud-samples-data/documentai/Custom/Lending-Splitter/PDF-CDS-BatchLabel/w9form_w9cloud-samples-data/documentai/Custom/Lending-Splitter/PDF-CDS-BatchLabel/paystubpaystub完成後,控制台應如下所示:
點選
「Import」(匯入) 。 匯入作業會在幾分鐘內完成。在「Train」(訓練) 分頁中,點選
「Import documents」(匯入文件) 。在
「Source path」(來源路徑) 中輸入下列路徑。cloud-samples-data/documentai/Custom/Lending-Splitter/JSON-Labeled將
「文件標籤」(Document label) 設為「None」(無)。將
「Dataset split」(資料集分割) 下拉式選單設為「Auto-Split」(自動分割)。點選
「Import」(匯入) 。點選
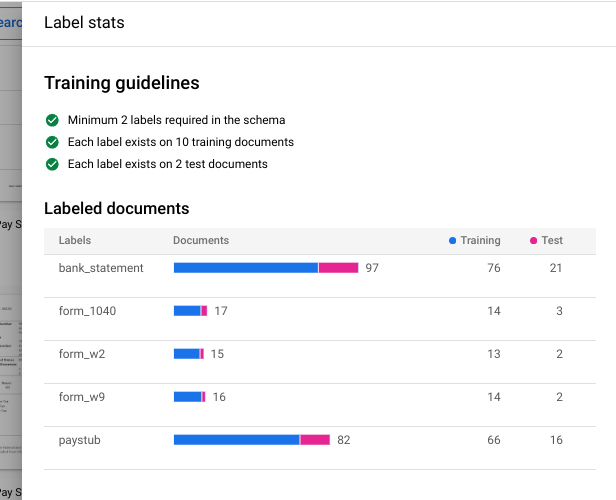
「Train New Version」(訓練新版本) 。在
「Version name」(版本名稱) 欄位中輸入這個處理器版本的名稱,例如my-cds-version-1。(選用) 點選「View Label Stats」(查看標籤統計資料) 即可看到文件標籤的相關資訊。這有助於您確定涵蓋範圍。接著點選「Close」(關閉) ,返回訓練設定頁面。
點選
「Start training」(開始訓練) 您可以在右側面板中確認狀態。訓練完成後,請前往
「Manage Versions」(管理版本) 分頁。您可以查看剛才訓練的版本詳細資料。找到您要部署的版本,點選右側的
三個垂直圓點 ,然後選取「Deploy version」(部署版本)。在彈出式視窗中選取
「Deploy」(部署) 。部署需要幾分鐘才會完成。
部署作業完成後,請前往
「Evaluate & Test」(評估與測試) 分頁。在這個頁面中,您可以查看整份文件和個別標籤的評估指標,包括 F1 分數、精確度和召回率。如要進一步瞭解評估程序和統計資料,請參閱「評估處理器」。
下載未加入先前訓練或測試的文件,以便用於評估處理器版本。如果您是使用自己的資料,可以針對這個用途保留文件。
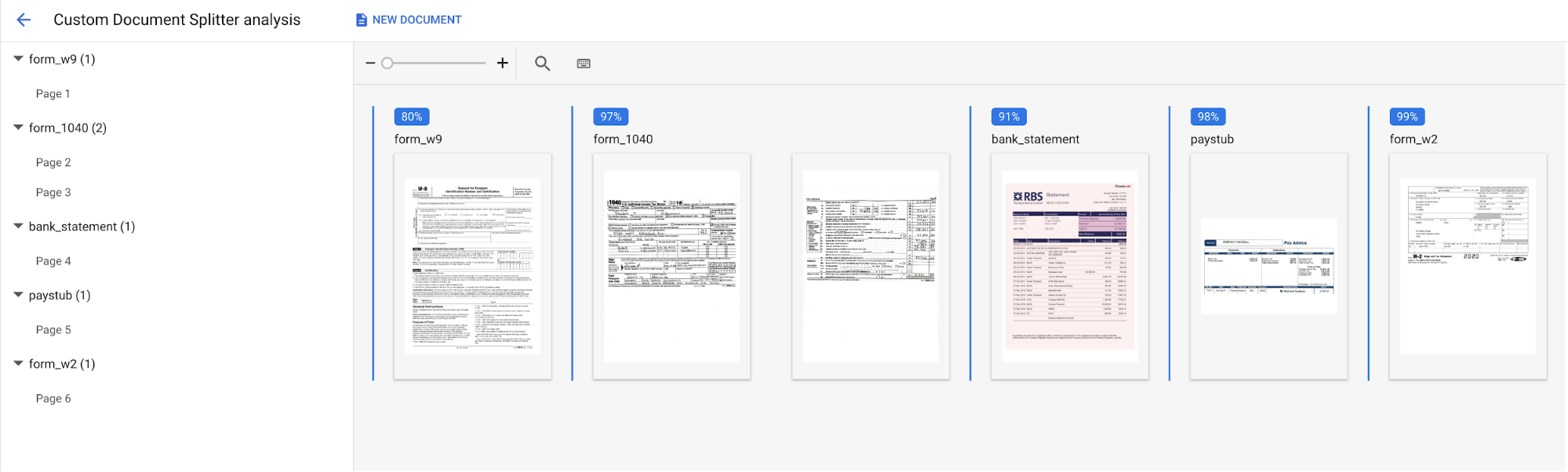
點選
「Upload Test Document」(上傳測試文件) ,然後選取剛剛下載的文件。系統隨即會開啟「Custom splitter analysis」(自訂分割器分析) 頁面。畫面輸出內容會顯示文件分割與分類的精細程度。
完成後,控制台應如下所示:
您也可以針對其他測試集或處理器版本重新執行評估作業。
在「Train」(訓練) 分頁中,點選
「Import documents」(匯入文件) 。在
「Source path」(來源路徑) 中輸入下列路徑。這個資料夾包含多種類型文件未加上標籤的 PDF。cloud-samples-data/documentai/Custom/Lending-Splitter/PDF-CDS-AutoLabel將
「文件標籤」(Document label) 設為「Auto-label」(自動標籤)。將
「Dataset split」(資料集分割) 下拉式選單設為「Auto-Split」(自動分割)。在「Auto-labeling」(自動加上標籤) 區段中,將
「Version」(版本) 設為先前訓練過的版本。- 例如:
2af620b2fd4d1fcf
- 例如:
點選
「Import」(匯入) ,然後等待系統匯入文件。如未將自動加上標籤的文件標示為已加上標籤,則無法將該文件用於訓練或測試。如要查看已自動加上標籤的文件,請前往
「Auto-labeled」(已自動加上標籤) 區段。選取第一份文件即可進入標籤控制台。
請確認標籤正確無誤,或視情況調整。
完成後,請選取
「Mark as Labeled」(標示為已加上標籤) 。為每份自動加上標籤的文件重複進行標籤驗證。
返回「Train」(訓練) 頁面,然後點選「Train New Version」(訓練新版本),將資料用於訓練。
在 Google Cloud 控制台導覽選單中,依序選取「Document AI」和「My Processors」(我的處理器)。
找到要刪除的處理器,然後點選該列中的
「More actions」(更多動作) 。選取「Delete processor」(刪除處理器),輸入處理器名稱,然後再次選取「Delete」(刪除) 來確認操作。
建立處理器
設定資料集
為了訓練這個新處理器,您必須建立具有訓練和測試資料的資料集,以協助處理器識別您要分割和分類的文件。
這個資料集需要新的位置。可以是空白的 Cloud Storage bucket 或資料夾,也可以允許 Google 代管 (內部) 位置。

為資料集建立 Cloud Storage bucket
確定目的地路徑中已填入您選取的 bucket 名稱。選取「Create dataset」(建立資料集)。 資料集最多可能需要幾分鐘才能完成。
定義處理器結構定義
您可以在將文件匯入資料集之前或之後建立處理器結構定義。結構定義提供用來為文件加上註解的標籤。
將未加上標籤的文件匯入資料集
下一步是開始將無標籤的文件匯入資料集,並為其加上標籤。建議的替代做法是匯入在資料夾中依類別整理的文件 (如有)。
如果您是使用自己的專案,可以決定如何為資料加上標籤。詳情請參閱「標籤選項」。
Document AI 自訂處理器在訓練集和測試集中至少需要 10 份文件,以及每個集合中每個標籤的 10 個例項。建議您每個組合至少加入 50 份文件,每個標籤包含 50 個例項,以獲得最佳成效。一般來說,訓練資料越多,準確率就會越高。
匯入文件時,可以選擇在匯入時就將文件指派至訓練集或測試集,也可以等到之後再指派。
如要刪除已匯入的文件,請在「Train」(訓練) 分頁中選取這些文件,然後點選「Delete」(刪除)。
如要進一步瞭解如何準備資料以進行匯入,請參閱「資料準備指南」。
選用:匯入時以批次處理的方式為文件加上標籤
您可以在匯入資料時,對位於特定目錄的所有文件加上標籤,以便節省時間。如果您的訓練用文件是在資料夾中依類別整理,可以使用「Document label」(文件標籤) 欄位來指定這些文件的類別,不必手動為每份文件加上標籤。
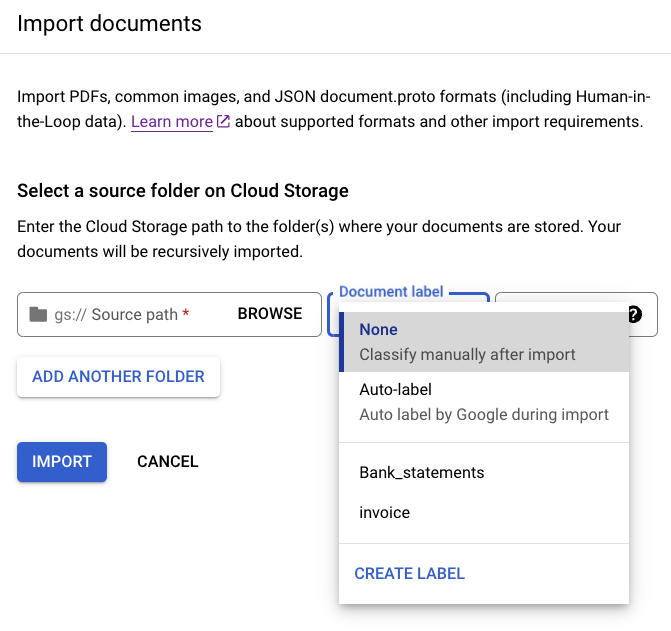
在圖片中,「Bank_statements」(銀行對帳單) 和「Invoice」(帳單) 是可選擇的已定義標籤 (文件類別)。您也可以使用 CREATE LABEL 並定義新類別。
為文件加上標籤
將文件加上標籤的作業稱為「註解」。
將加註的文件指派給訓練集
現在,您已經為這份範例文件加上標籤,可以將其指派給訓練集。
左側面板中會顯示有 1 份文件已指派給訓練集。
使用批次標籤匯入資料
接下來,您要匯入未加上標籤的 PDF 檔案,並依類型整理為不同的 Cloud Storage 資料夾。批次處理標籤會根據路徑,在匯入時指派標籤,協助節省加上標籤的時間。
匯入完成後,請在「Train」(訓練) 分頁中找到文件。
匯入預先加上標籤的資料
在本指南中,系統會以 JSON 檔案提供 Document 格式的預先加上標籤資料。
這與 Document AI 處理文件、為人機迴圈加上標籤或匯出資料集的輸出內容格式相同。
匯入完成後,請在「Train」(訓練) 分頁中找到文件。
訓練處理器
現在您已經匯入訓練和測試資料,接著可以訓練處理器。由於訓練可能需要數小時,因此在開始訓練前,請務必先確認您已使用適當的資料和標籤完成處理器設定。
部署處理器版本
評估及測試處理器
(選用) 使用自動加上標籤功能匯入資料
部署經過訓練的處理器版本後,您可以在匯入新文件時使用自動加上標籤功能,節省標籤時間。
使用處理器
您已成功建立及訓練自訂分割器處理器。
您可以管理自訂訓練的處理器版本,就像其他處理器版本一樣。詳情請參閱「管理處理器版本」。
部署完成後,您可以傳送處理要求至自訂處理器,然後比照其他分割器處理器以同樣的方式處理回應。
清除所用資源
如要避免系統向您的 Google Cloud 帳戶收取本頁所用資源的費用,請按照下列步驟操作。
請透過Google Cloud console 刪除不需要的處理器和專案,以免產生不必要的 Google Cloud 費用。
如果您建立新專案的目的在於瞭解如何使用 Document AI,且現在已不再需要該項專案,請刪除專案。
如果您使用現有的 Google Cloud 專案,請刪除稍早建立的資源,以免系統向您的帳戶收取費用。