La respuesta a una solicitud de procesamiento contiene un objeto Document que incluye toda la información que se conoce sobre el documento procesado, incluida toda la información estructurada que Document AI ha podido extraer.
En esta página se explica el diseño del objeto Document mediante documentos de ejemplo y, a continuación, se asignan aspectos de los resultados del OCR a los elementos específicos del JSON del objeto Document.
También proporciona bibliotecas de cliente, ejemplos de código y ejemplos de código del SDK de Document AI Toolbox.
Estos ejemplos de código usan el procesamiento online, pero el análisis del objeto Document funciona igual en el procesamiento por lotes.
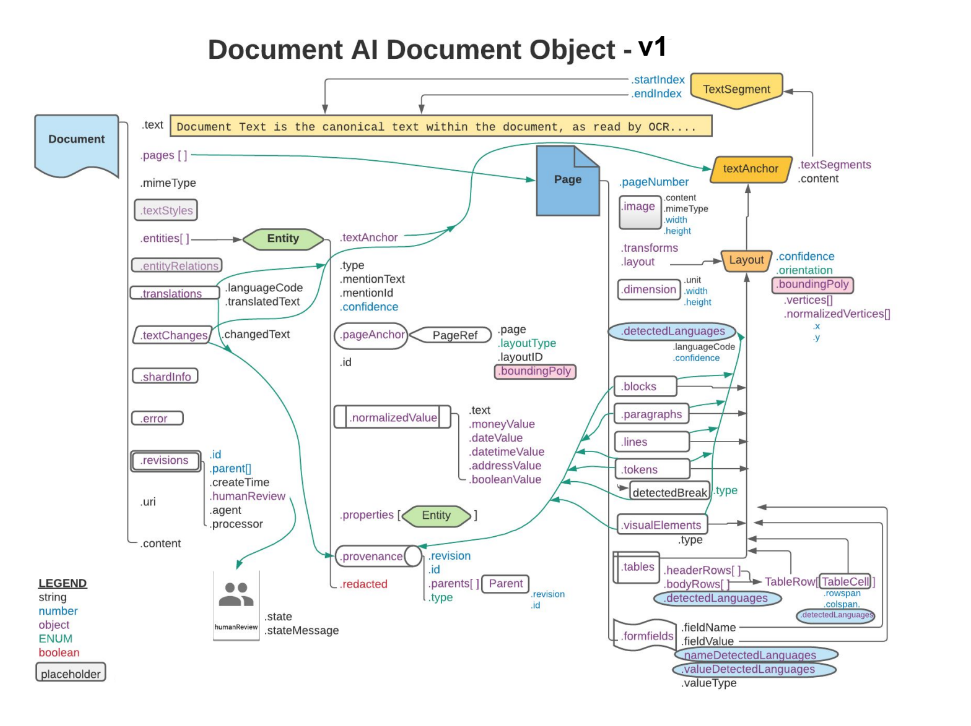
Los rectángulos y las flechas naranjas y azules representan que al menos un campo de los objetos conectados es .layout o detectedLanguage, respectivamente. El diagrama usa la notación de pata de gallina.
Usa un visor o una utilidad de edición de JSON diseñados específicamente para expandir o contraer elementos. Revisar el JSON sin formato en una utilidad de texto sin formato es ineficiente.
Texto, diseño y niveles de calidad
Aquí tienes un documento de texto de ejemplo:

Este es el objeto de documento completo devuelto por el procesador Enterprise Document OCR:
Este resultado de OCR también se incluye siempre en el resultado del procesador de Document AI, ya que los procesadores ejecutan el OCR. Utiliza los datos de OCR que ya existen, por lo que puede introducir datos JSON de este tipo en los procesadores de Document AI mediante la opción de documento insertado.
image=None, # all our samples pass this var
mime_type="application/json",
inline_document=document_response # pass OCR output to CDE input - undocumented
Estos son algunos de los campos importantes:
Texto sin formato
El campo text contiene el texto que reconoce Document AI.
Este texto no contiene ninguna estructura de diseño que no sean espacios, tabulaciones y
saltos de línea. Este es el único campo que almacena la información textual de un documento y sirve como fuente de información veraz del texto del documento. Otros campos pueden hacer referencia a partes del campo de texto por posición (startIndex y endIndex).
{
text: "Sample Document\nHeading 1\nLorem ipsum dolor sit amet, ..."
}
Tamaño de página e idiomas
Cada page del objeto de documento corresponde a una página física del documento de muestra. La salida JSON de ejemplo contiene una página porque es una sola imagen PNG.
{
"pages:" [
{
"pageNumber": 1,
"dimension": {
"width": 679.0,
"height": 460.0,
"unit": "pixels"
},
}
]
}
- El campo
pages[].detectedLanguages[]contiene los idiomas detectados en una página determinada, junto con la puntuación de confianza.
{
"pages": [
{
"detectedLanguages": [
{
"confidence": 0.98009938,
"languageCode": "en"
},
{
"confidence": 0.01990064,
"languageCode": "und"
}
]
}
]
}
Datos de OCR
El OCR de Document AI detecta texto con varios niveles de granularidad u organización en la página, como bloques de texto, párrafos, tokens y símbolos (el nivel de símbolo es opcional si se configura para que genere datos a nivel de símbolo). Todos estos son miembros del objeto de página.
Cada elemento tiene un layout correspondiente que describe su posición y su texto. Los elementos visuales que no son texto (como las casillas de verificación) también están a nivel de página.
{
"pages": [
{
"paragraphs": [
{
"layout": {
"textAnchor": {
"textSegments": [
{
"endIndex": "16"
}
]
},
"confidence": 0.9939527,
"boundingPoly": {
"vertices": [ ... ],
"normalizedVertices": [ ... ]
},
"orientation": "PAGE_UP"
}
}
]
}
]
}
El texto sin formato se hace referencia en el objeto textAnchor
que se indexa en la cadena de texto principal con startIndex y endIndex.
En el caso de
boundingPoly, la esquina superior izquierda de la página es el origen(0,0). Los valores de X positivos están a la derecha y los valores de Y positivos están hacia abajo.El objeto
verticesusa las mismas coordenadas que la imagen original, mientras quenormalizedVerticesestá en el intervalo[0,1]. Hay una matriz de transformación que indica las medidas de corrección de la inclinación y otros atributos de la normalización de la imagen.
- Para dibujar un
boundingPoly, dibuja segmentos de línea de un vértice al siguiente. A continuación, cierra el polígono trazando un segmento de línea desde el último vértice hasta el primero. El elemento orientation del diseño indica si el texto se ha girado en relación con la página.
Para ayudarte a visualizar la estructura del documento, en las siguientes imágenes se dibujan polígonos envolventes de page.paragraphs, page.lines y page.tokens.
Párrafos

Líneas

Tokens

Bloques

El procesador Enterprise Document OCR puede evaluar la calidad de un documento en función de su legibilidad.
- Debes definir el campo
processOptions.ocrConfig.enableImageQualityScoresentruepara obtener estos datos en la respuesta de la API.
Esta evaluación de la calidad es un nivel de calidad en [0, 1], donde 1 significa una calidad perfecta.
El nivel de calidad se devuelve en el campo Page.imageQualityScores.
Todos los defectos detectados se muestran como quality/defect_* y se ordenan de forma descendente según el valor de confianza.
Aquí tienes un PDF que está demasiado oscuro y borroso para leerlo cómodamente:
A continuación, se muestra la información sobre la calidad del documento devuelta por el procesador Enterprise Document OCR:
{
"pages": [
{
"imageQualityScores": {
"qualityScore": 0.7811847,
"detectedDefects": [
{
"type": "quality/defect_document_cutoff",
"confidence": 1.0
},
{
"type": "quality/defect_glare",
"confidence": 0.97849524
},
{
"type": "quality/defect_text_cutoff",
"confidence": 0.5
}
]
}
}
]
}
Códigos de ejemplo
En los siguientes ejemplos de código se muestra cómo enviar una solicitud de procesamiento y, a continuación, leer e imprimir los campos en la terminal:
Java
Para obtener más información, consulta la documentación de referencia de la API Java de Document AI.
Para autenticarte en Document AI, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
Node.js
Para obtener más información, consulta la documentación de referencia de la API Node.js de Document AI.
Para autenticarte en Document AI, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
Python
Para obtener más información, consulta la documentación de referencia de la API Python de Document AI.
Para autenticarte en Document AI, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
Formularios y tablas
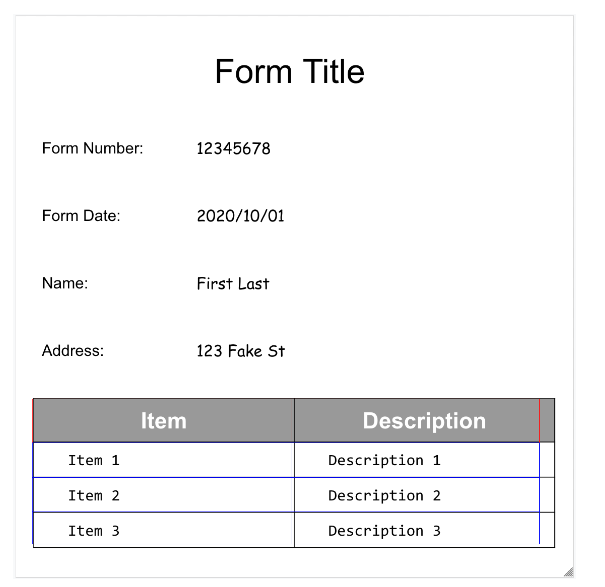
Aquí tienes un formulario de ejemplo:

A continuación se muestra el objeto de documento completo devuelto por Form Parser:
Estos son algunos de los campos importantes:
El analizador de formularios puede detectar FormFields
en la página. Cada campo de formulario tiene un nombre y un valor. También se denominan pares clave-valor (KVP). Ten en cuenta que los pares clave-valor son diferentes de las entidades (de esquema) de otros extractores:
Se configuran los nombres de las entidades. Las claves de los pares clave-valor son literalmente el texto de la clave del documento.
{
"pages:" [
{
"formFields": [
{
"fieldName": { ... },
"fieldValue": { ... }
}
]
}
]
}
- Document AI también puede detectar
Tablesen la página.
{
"pages:" [
{
"tables": [
{
"layout": { ... },
"headerRows": [
{
"cells": [
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
},
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
}
]
}
],
"bodyRows": [
{
"cells": [
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
},
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
}
]
}
]
}
]
}
]
}
La extracción de tablas de Form Parser solo reconoce las tablas convencionales, es decir, las que no tienen celdas que abarcan filas o columnas. Por lo tanto, rowSpan y colSpan siempre son 1.
A partir de la versión
pretrained-form-parser-v2.0-2022-11-10del procesador, Form Parser también puede reconocer entidades genéricas. Para obtener más información, consulta Analizador de formularios.Para ayudarte a visualizar la estructura del documento, en las siguientes imágenes se dibujan polígonos envolventes para
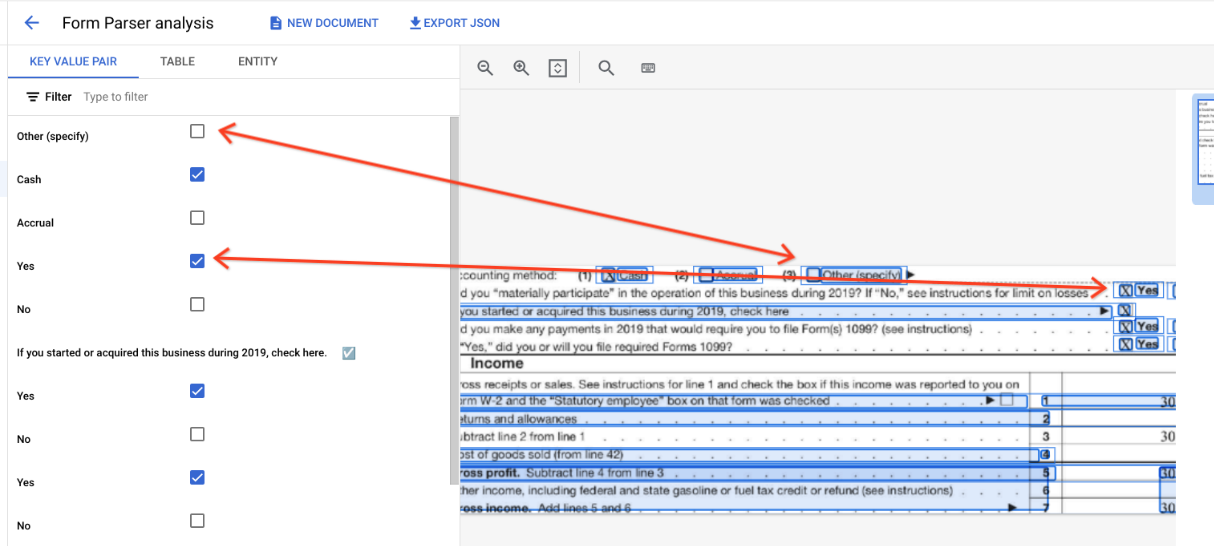
page.formFieldsypage.tables.Casillas de verificación en tablas. Form Parser puede digitalizar casillas de verificación de imágenes y PDFs como pares clave-valor. Proporcionar un ejemplo de digitalización de casillas de verificación como par clave-valor.

Fuera de las tablas, las casillas se representan como elementos visuales en el analizador de formularios. Se resaltan los cuadrados con marcas de verificación en la interfaz de usuario y el carácter unicode ✓ en el JSON.
"pages:" [
{
"tables": [
{
"layout": { ... },
"headerRows": [
{
"cells": [
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
},
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
}
]
}
],
"bodyRows": [
{
"cells": [
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
},
{
"layout": { ... },
"rowSpan": 1,
"colSpan": 1
}
]
}
]
}
]
}
]
}
En las tablas, las casillas de verificación aparecen como caracteres Unicode, como ✓ (marcada) o ☐ (desmarcada).
Las casillas marcadas tienen el valor filled_checkbox:
under pages > x > formFields > x > fieldValue > valueType.. Las casillas sin marcar tienen el valor unfilled_checkbox.
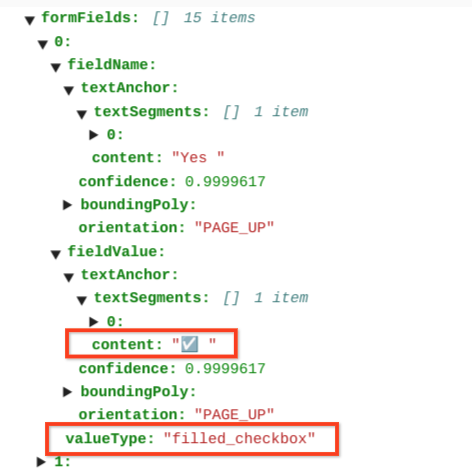
Los campos de contenido muestran el valor del contenido de la casilla, resaltado con ✓, en la ruta pages>formFields>x>fieldValue>textAnchor>content.
Para ayudarte a visualizar la estructura del documento, en las siguientes imágenes se dibujan polígonos de contorno para page.formFields y page.tables.
Campos del formulario
Tablas
Códigos de ejemplo
En los siguientes ejemplos de código se muestra cómo enviar una solicitud de procesamiento y, a continuación, leer e imprimir los campos en la terminal:
Java
Para obtener más información, consulta la documentación de referencia de la API Java de Document AI.
Para autenticarte en Document AI, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
Node.js
Para obtener más información, consulta la documentación de referencia de la API Node.js de Document AI.
Para autenticarte en Document AI, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
Python
Para obtener más información, consulta la documentación de referencia de la API Python de Document AI.
Para autenticarte en Document AI, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
Entidades, entidades anidadas y valores normalizados
Muchos de los procesadores especializados extraen datos estructurados basados en un esquema bien definido. Por ejemplo, el analizador de facturas
detecta campos específicos, como invoice_date y supplier_name. Aquí tienes una factura de muestra:
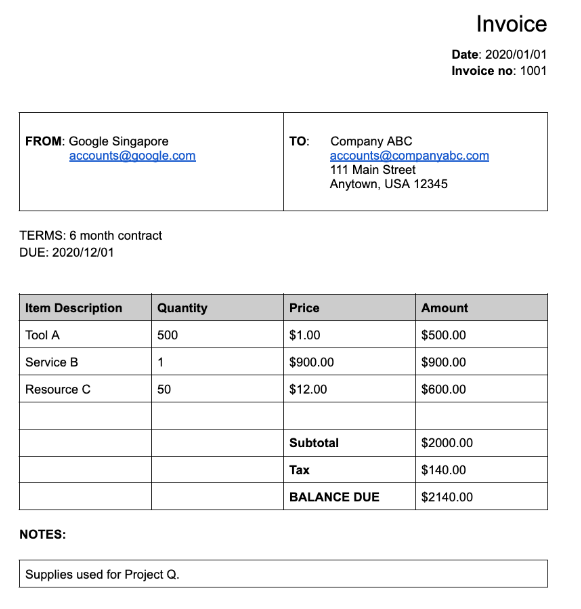
Aquí tienes el objeto de documento completo devuelto por el analizador de facturas:
Estos son algunos de los elementos importantes del objeto document:
Campos detectados:
Entitiescontiene los campos que el procesador ha podido detectar. Por ejemplo,invoice_date:{ "entities": [ { "textAnchor": { "textSegments": [ { "startIndex": "14", "endIndex": "24" } ], "content": "2020/01/01" }, "type": "invoice_date", "confidence": 0.9938466, "pageAnchor": { ... }, "id": "2", "normalizedValue": { "text": "2020-01-01", "dateValue": { "year": 2020, "month": 1, "day": 1 } } } ] }En algunos campos, el procesador también normaliza el valor. En este ejemplo, la fecha se ha normalizado de
2020/01/01a2020-01-01.Normalización: en muchos campos específicos admitidos, el procesador también normaliza el valor y devuelve un
entity. El camponormalizedValuese añade al campo extraído sin procesar que se obtiene a través deltextAnchorde cada entidad. Por lo tanto, normaliza el texto literal, lo que a menudo divide el valor de texto en subcampos. Por ejemplo, la fecha 1 de septiembre del 2024 se representaría de la siguiente manera:
normalizedValue": {
"text": "2020-09-01",
"dateValue": {
"year": 2024,
"month": 9,
"day": 1
}
En este ejemplo, la fecha se ha normalizado de 2020/01/01 a 2020-01-01, un formato estandarizado para reducir el posprocesamiento y permitir la conversión al formato elegido.
Las direcciones también se normalizan a menudo, lo que desglosa los elementos de la dirección en campos individuales. Los números se normalizan con un número entero o de coma flotante como normalizedValue.
- Enriquecimiento: algunos procesadores y campos también admiten el enriquecimiento.
Por ejemplo, el
supplier_nameoriginal del documentoGoogle Singaporese ha normalizado con respecto a Enterprise Knowledge Graph y ahora esGoogle Asia Pacific, Singapore. También puedes observar que, como el gráfico de conocimiento empresarial contiene información sobre Google, Document AI infiere elsupplier_addressaunque no esté presente en el documento de muestra.
{
"entities": [
{
"textAnchor": {
"textSegments": [ ... ],
"content": "Google Singapore"
},
"type": "supplier_name",
"confidence": 0.39170802,
"pageAnchor": { ... },
"id": "12",
"normalizedValue": {
"text": "Google Asia Pacific, Singapore"
}
},
{
"type": "supplier_address",
"id": "17",
"normalizedValue": {
"text": "70 Pasir Panjang Rd #03-71 Mapletree Business City II Singapore 117371",
"addressValue": {
"regionCode": "SG",
"languageCode": "en-US",
"postalCode": "117371",
"addressLines": [
"70 Pasir Panjang Rd",
"#03-71 Mapletree Business City II"
]
}
}
}
]
}
Campos anidados: para crear un esquema (campos) anidado, primero debes declarar una entidad como principal y, a continuación, crear entidades secundarias en la entidad principal. La respuesta de análisis del elemento principal incluye los campos secundarios en el elemento
propertiesdel campo principal. En el siguiente ejemplo,line_itemes un campo principal que tiene dos campos secundarios:line_item/descriptionyline_item/quantity.{ "entities": [ { "textAnchor": { ... }, "type": "line_item", "confidence": 1.0, "pageAnchor": { ... }, "id": "19", "properties": [ { "textAnchor": { "textSegments": [ ... ], "content": "Tool A" }, "type": "line_item/description", "confidence": 0.3461604, "pageAnchor": { ... }, "id": "20" }, { "textAnchor": { "textSegments": [ ... ], "content": "500" }, "type": "line_item/quantity", "confidence": 0.8077843, "pageAnchor": { ... }, "id": "21", "normalizedValue": { "text": "500" } } ] } ] }
Los siguientes analizadores sí lo hacen:
- Extraer (extractor personalizado)
- Versión antigua
- Analizador de extractos bancarios
- Análisis de gastos
- Análisis de facturas
- Analizador de nóminas
- Analizador de formularios W‐2
Códigos de ejemplo
En los siguientes ejemplos de código se muestra cómo enviar una solicitud de procesamiento y, a continuación, leer e imprimir los campos de un procesador especializado en la terminal:
Java
Para obtener más información, consulta la documentación de referencia de la API Java de Document AI.
Para autenticarte en Document AI, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
Node.js
Para obtener más información, consulta la documentación de referencia de la API Node.js de Document AI.
Para autenticarte en Document AI, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
Python
Para obtener más información, consulta la documentación de referencia de la API Python de Document AI.
Para autenticarte en Document AI, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
Extractor de documentos personalizado
El procesador Extractor de documentos personalizado puede extraer entidades personalizadas de documentos que no tengan un procesador preentrenado disponible. Para ello, puedes entrenar un modelo personalizado o usar modelos fundacionales de IA generativa para extraer entidades con nombre sin necesidad de entrenamiento. Para obtener más información, consulta el artículo Crear un extractor de documentos personalizado en la consola.
- Si entrenas un modelo personalizado, el procesador se puede usar exactamente igual que un procesador de extracción de entidades preentrenado.
- Si usas un modelo fundacional, puedes crear una versión de procesador para extraer entidades específicas de cada solicitud o configurarlo en función de cada solicitud.
Para obtener información sobre la estructura de salida, consulta Entidades, entidades anidadas y valores normalizados.
Códigos de ejemplo
Si usas un modelo personalizado o has creado una versión de procesador con un modelo base, utiliza los ejemplos de código de extracción de entidades.
En el siguiente código de ejemplo se muestra cómo configurar entidades específicas para un extractor de documentos personalizado de un modelo básico por solicitud e imprimir las entidades extraídas:
Python
Para obtener más información, consulta la documentación de referencia de la API Python de Document AI.
Para autenticarte en Document AI, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
Creación de resúmenes
El procesador Summarizer usa modelos básicos de IA generativa para resumir el texto extraído de un documento. La longitud y el formato de la respuesta se pueden personalizar de las siguientes formas:
- Longitud
BRIEF: un breve resumen de una o dos frasesMODERATE: un resumen de un párrafoCOMPREHENSIVE: la opción más larga disponible
- Formato
Puedes crear una versión del procesador para una duración y un formato específicos, o bien configurarla por solicitud.
El texto resumido aparece en Document.entities.normalizedValue.text. Puedes consultar un archivo JSON de salida de ejemplo completo en Ejemplo de salida de procesador.
Para obtener más información, consulta Crear un resumidor de documentos en la consola.
Códigos de ejemplo
En el siguiente ejemplo de código se muestra cómo configurar una longitud y un formato específicos en una solicitud de procesamiento e imprimir el texto resumido:
Python
Para obtener más información, consulta la documentación de referencia de la API Python de Document AI.
Para autenticarte en Document AI, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
División y clasificación
Aquí tienes un PDF compuesto de 10 páginas que contiene diferentes tipos de documentos y formularios:
A continuación se muestra el objeto de documento completo devuelto por el clasificador y separador de documentos de préstamo:
Cada documento que detecta el separador se representa mediante un entity. Por ejemplo:
{
"entities": [
{
"textAnchor": {
"textSegments": [
{
"startIndex": "13936",
"endIndex": "21108"
}
]
},
"type": "1040se_2020",
"confidence": 0.76257163,
"pageAnchor": {
"pageRefs": [
{
"page": "6"
},
{
"page": "7"
}
]
}
}
]
}
Entity.pageAnchorindica que este documento tiene 2 páginas. Ten en cuenta quepageRefs[].pagese basa en cero y es el índice del campodocument.pages[].Entity.typeespecifica que este documento es un formulario 1040 del Anexo SE. Para ver una lista completa de los tipos de documentos que se pueden identificar, consulta Tipos de documentos identificados en la documentación del procesador.
Para obtener más información, consulta Comportamiento de los separadores de documentos.
Códigos de ejemplo
Los divisores identifican los límites de las páginas, pero no dividen el documento de entrada. Puedes usar Document AI Toolbox para dividir físicamente un archivo PDF usando los límites de las páginas. En los siguientes ejemplos de código se imprimen los intervalos de páginas sin dividir el PDF:
Java
Para obtener más información, consulta la documentación de referencia de la API Java de Document AI.
Para autenticarte en Document AI, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
Node.js
Para obtener más información, consulta la documentación de referencia de la API Node.js de Document AI.
Para autenticarte en Document AI, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
Python
Para obtener más información, consulta la documentación de referencia de la API Python de Document AI.
Para autenticarte en Document AI, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
Document procesado.
Python
Para obtener más información, consulta la documentación de referencia de la API Python de Document AI.
Para autenticarte en Document AI, configura las credenciales predeterminadas de la aplicación. Para obtener más información, consulta el artículo Configurar la autenticación en un entorno de desarrollo local.
Caja de herramientas de Document AI
Document AI Toolbox es un SDK para Python que proporciona funciones de utilidad para gestionar, manipular y extraer información de la respuesta del documento.
Crea un objeto de documento "envoltorio" a partir de una respuesta de documento procesado de archivos JSON en Cloud Storage, archivos JSON locales o la salida directamente del método process_document().
Puede realizar las siguientes acciones:
- Combina archivos JSON
Documentfragmentados del procesamiento por lotes en un solo documento "envuelto". - Exporta los fragmentos como un archivo
Documentunificado. -
Obtener el resultado de
Documentde: - Accede al texto de
Pages,Lines,Paragraphs,FormFieldsyTablessin gestionar informaciónLayout. - Busca un
Pagesque contenga una cadena de destino o que coincida con una expresión regular. - Busca
FormFieldspor su nombre. - Buscar
Entitiespor tipo. - Convierte
Tablesen un dataframe de Pandas o en un archivo CSV. - Inserta
EntitiesyFormFieldsen una tabla de BigQuery. - Dividir un archivo PDF en función de la salida de un procesador de división o clasificación.
- Extrae la imagen
Entitiesde losDocumentcuadros delimitadores. -
Convertir
Documentsa formatos de uso habitual y viceversa:- API Cloud Vision
AnnotateFileResponse - hOCR
- Formatos de procesamiento de documentos de terceros
- API Cloud Vision
- Crea lotes de documentos para procesarlos desde una carpeta de Cloud Storage.
Códigos de ejemplo
En los siguientes ejemplos de código se muestra cómo usar Document AI Toolbox.