Você pode usar o Enterprise Document OCR como parte da Document AI para detectar e extrair texto e informações de layout de vários documentos. Com recursos configuráveis, é possível adaptar o sistema para atender a requisitos específicos de processamento de documentos.
Visão geral
É possível usar o Enterprise Document OCR para tarefas como entrada de dados com base em algoritmos ou machine learning e para melhorar e verificar a acurácia dos dados. Você também pode usar o Enterprise Document OCR para lidar com tarefas como as seguintes:
- Digitalização de texto:extraia dados de texto e layout de documentos para pesquisa, pipelines de processamento de documentos baseados em regras ou criação de modelos personalizados.
- Usar aplicativos de modelos de linguagem grandes:use a compreensão contextual dos LLMs e os recursos de extração de texto e layout da OCR para automatizar perguntas e respostas. Receba insights dos dados e simplifique os fluxos de trabalho.
- Arquivamento:digitalizar documentos em papel para texto legível por máquina e melhorar a acessibilidade.
Como escolher o melhor OCR para seu caso de uso
| Solução | Produto | Descrição | Caso de uso |
|---|---|---|---|
| Document AI | OCR de documentos corporativos | Modelo especializado para casos de uso de documentos. Os recursos avançados incluem pontuação de qualidade da imagem, dicas de idioma e correção de rotação. | Recomendado ao extrair texto de documentos. Os casos de uso incluem PDFs, documentos digitalizados como imagens ou arquivos Microsoft DocX. |
| Document AI | Complementos de OCR | Recursos premium para requisitos específicos. Compatível apenas com a versão 2.0 e mais recentes do Enterprise Document OCR. | Precisa detectar e reconhecer fórmulas matemáticas, receber informações de estilo de fonte ou ativar a extração de caixas de seleção. |
| API Cloud Vision | Detecção de texto | API REST disponível globalmente com base no modelo de OCR padrão Google Cloud . Cota padrão de 1.800 solicitações por minuto. | Casos de uso gerais de extração de texto que exigem baixa latência e alta capacidade. |
| Cloud Vision | OCR do Google Distributed Cloud (descontinuado) | Aplicativo do Google Cloud Marketplace que pode ser implantado como um contêiner em qualquer cluster do GKE usando o GKE Enterprise. | Para atender aos requisitos de residência ou compliance de dados. |
Detecção e extração
O Enterprise Document OCR pode detectar blocos, parágrafos, linhas, palavras e símbolos em PDFs e imagens, além de corrigir a distorção dos documentos para melhorar a precisão.
Atributos de detecção e extração de layout compatíveis:
| Texto impresso | Escrita à mão | Parágrafo | Bloquear | Linha | Word | No nível do símbolo | Número da página |
|---|---|---|---|---|---|---|---|
| Padrão | Padrão | Padrão | Padrão | Padrão | Padrão | Configurável | Padrão |
Os recursos configuráveis do Enterprise Document OCR incluem:
Extrair texto incorporado ou nativo de PDFs digitais:esse recurso extrai texto e símbolos exatamente como aparecem nos documentos de origem, mesmo para textos girados, tamanhos ou estilos de fonte extremos e texto parcialmente oculto.
Correção de rotação:use o Enterprise Document OCR para pré-processar imagens de documentos e corrigir problemas de rotação que podem afetar a qualidade da extração ou o processamento.
Pontuação de qualidade da imagem:receba métricas de qualidade que podem ajudar no encaminhamento de documentos. A pontuação de qualidade da imagem fornece métricas de qualidade no nível da página em oito dimensões, incluindo desfoque, presença de fontes menores do que o normal e brilho.
Especificar intervalo de páginas:especifica o intervalo de páginas em um documento de entrada para OCR. Isso economiza gastos e tempo de processamento em páginas desnecessárias.
Detecção de idioma:detecta os idiomas usados nos textos extraídos.
Dicas de idioma e escrita à mão:melhore a precisão fornecendo ao modelo de OCR uma dica de idioma ou escrita à mão com base nas características conhecidas do seu conjunto de dados.
Para saber como ativar as configurações de OCR, consulte Ativar configurações de OCR.
Complementos de OCR
O OCR de documentos corporativos oferece recursos de análise opcionais que podem ser ativados em solicitações de processamento individuais, conforme necessário.
Os seguintes recursos complementares estão disponíveis para as versões Stable
pretrained-ocr-v2.0-2023-06-02 e pretrained-ocr-v2.1-2024-08-07,
e para a versão Release Candidate pretrained-ocr-v2.1.1-2025-01-31.
- OCR de matemática: identifica e extrai fórmulas de documentos no formato LaTeX.
- Extração de caixas de seleção: detecta caixas de seleção e extrai o status delas (marcadas/desmarcadas) na resposta do Enterprise Document OCR.
- Detecção de estilo de fonte: identifica propriedades de fonte no nível da palavra, incluindo tipo, estilo, escrita à mão, peso e cor.
Para saber como ativar os complementos listados, consulte Ativar complementos de OCR.
Formatos de arquivo compatíveis
O OCR de documentos empresariais é compatível com os formatos de arquivo PDF, GIF, TIFF, JPEG, PNG, BMP e WebP. Para mais informações, consulte Arquivos compatíveis.
O Enterprise Document OCR também é compatível com arquivos DocX de até 15 páginas de forma síncrona e 30 páginas de forma assíncrona. Para fazer uma solicitação de aumento de cota (QIR), siga as etapas em Solicitar um ajuste de cota. O suporte a DocX está em pré-lançamento particular. Para solicitar acesso, entre em contato com a equipe da sua conta do Google.
Controle de versões avançado
O controle de versões avançado está em pré-lançamento. Os upgrades nos modelos de OCR de IA/ML podem levar a mudanças no comportamento do OCR. Se for necessária consistência estrita, use uma versão de modelo congelada para fixar o comportamento em um modelo de OCR legado por até 18 meses. Isso garante o mesmo resultado da função de OCR da imagem. Consulte a tabela sobre versões do processador.
Versões do processador
As seguintes versões de processador são compatíveis com esse recurso. Para mais informações, consulte Como gerenciar versões de processadores.
| ID da versão | Canal de lançamento | Descrição |
|---|---|---|
pretrained-ocr-v1.2-2022-11-10 |
Estável | Versão congelada do modelo v1.0: arquivos, configurações e binários de um snapshot de versão congelados em uma imagem de contêiner por até 18 meses. |
pretrained-ocr-v2.0-2023-06-02 |
Estável | Modelo pronto para Production especializado em casos de uso de documentos. Inclui acesso a todos os complementos de OCR. |
pretrained-ocr-v2.1-2024-08-07 |
Estável | As principais áreas de melhoria da v2.1 são: melhor reconhecimento de texto impresso, detecção mais precisa de caixas de seleção e ordem de leitura mais precisa. |
pretrained-ocr-v2.1.1-2025-01-31 |
Versão candidata | A v2.1.1 é semelhante à v2.1 e está disponível em todas as regiões, exceto: US, EU e asia-southeast1. |
Usar o Enterprise Document OCR para processar documentos
Neste guia de início rápido, apresentamos o OCR de documentos empresariais. Ele mostra como otimizar os resultados do OCR de documentos para seu fluxo de trabalho ativando ou desativando qualquer uma das configurações de OCR disponíveis.
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. quality/defect_blurryquality/defect_noisyquality/defect_darkquality/defect_faintquality/defect_text_too_smallquality/defect_document_cutoffquality/defect_text_cutoffquality/defect_glare- Ele pode retornar detecções de falsos positivos com documentos digitais sem defeitos. O recurso funciona melhor em documentos digitalizados ou fotografados.
Os defeitos de brilho são locais. A presença deles não prejudica a legibilidade geral do documento.
- Para processar apenas a segunda e a quinta páginas:
- Para processar apenas as três primeiras páginas:
- Para processar apenas as últimas quatro páginas:
Imagem detectada
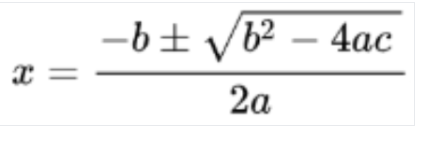
Conversão para LaTeX
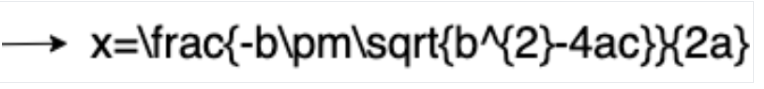
- Detecção de escrita à mão
- Estilo da fonte
- Tamanho da fonte
- Tipo da fonte
- Cor da fonte
- Espessura da fonte
- Espaçamento entre letras
- Negrito
- Itálico
- Sublinhado
- Cor do texto (RGBa)
Cor do plano de fundo (RGBa)
- A resposta da API Vision AI preenche apenas
verticespara solicitações de imagens e apenasnormalized_verticespara solicitações de PDF. A resposta da Document AI e o conversor preenchemverticesenormalized_vertices. - A resposta da API Vision AI preenche o
detected_breakno último símbolo da palavra. A resposta da API Document AI e o conversor preenchemdetected_breakna palavra e no último símbolo dela. - A resposta da API Vision AI sempre preenche os campos de símbolos. Por padrão, a resposta da Document AI não preenche os campos de símbolos. Para garantir que a resposta da Document AI e o conversor tenham os campos de símbolos preenchidos, defina o recurso
enable_symbolconforme detalhado. - LOCATION: a localização do seu processador, por exemplo:
us: Estados Unidoseu: União Europeia
- PROJECT_ID: o ID do projeto do Google Cloud .
- PROCESSOR_ID: o ID do seu processador personalizado.
- PROCESSOR_VERSION: o identificador da versão do processador. Consulte Selecionar uma versão do processador para mais informações. Por exemplo:
pretrained-TYPE-vX.X-YYYY-MM-DDstablerc
- skipHumanReview: um booleano para desativar a revisão humana. Compatível apenas com processadores human-in-the-loop.
true- ignora a revisão humanafalse: ativa a revisão humana (padrão).
- MIME_TYPE†: uma das opções válidas de tipo MIME.
- IMAGE_CONTENT†: um dos conteúdos de documento inline válidos, representado como um stream de bytes. Para representações JSON, a codificação base64 (string ASCII) dos dados da imagem binária. Essa string precisa ser semelhante à seguinte:
/9j/4QAYRXhpZgAA...9tAVx/zDQDlGxn//2Q==
- FIELD_MASK: especifica quais campos incluir na saída
Document. É uma lista separada por vírgulas de nomes de campos totalmente qualificados no formatoFieldMask.- Exemplo:
text,entities,pages.pageNumber
- Exemplo:
- Configurações de OCR
- ENABLE_NATIVE_PDF_PARSING: (booleano) extrai texto incorporado de PDFs, se disponível.
- ENABLE_IMAGE_QUALITY_SCORES: (booleano) ativa pontuações inteligentes de qualidade de documentos.
- ENABLE_SYMBOL: (booleano) inclui informações de OCR de símbolos (letras).
- DISABLE_CHARACTER_BOXES_DETECTION: (booleano) desativa o detector de caixa de caracteres no mecanismo de OCR.
- LANGUAGE_HINTS: lista de códigos de idioma BCP-47 a serem usados para OCR.
- ADVANCED_OCR_OPTIONS: uma lista de opções avançadas de OCR para ajustar ainda mais o comportamento do OCR. Os valores válidos atuais são:
legacy_layout: um algoritmo heurístico de detecção de layout, que serve como alternativa ao algoritmo atual de detecção de layout baseado em ML.
- Complementos premium de OCR
- ENABLE_SELECTION_MARK_DETECTION: (booleano) ative o detector de marca de seleção no mecanismo de OCR.
- COMPUTE_STYLE_INFO (booleano): ative o modelo de identificação de fonte e solicite o retorno das informações de estilo de fonte.
- ENABLE_MATH_OCR: (booleano) ative o modelo que pode extrair fórmulas matemáticas LaTeX.
- INDIVIDUAL_PAGES: uma lista de páginas individuais a serem processadas.
- Consulte a lista de processadores.
- Separe documentos em partes legíveis com o Layout Parser.
- Crie um classificador personalizado.
Criar um processador Enterprise Document OCR
Primeiro, crie um processador Enterprise Document OCR. Para mais informações, consulte Como criar e gerenciar processadores.
Configurações de OCR
Todas as configurações de OCR podem ser ativadas definindo os campos respectivos em ProcessOptions.ocrConfig no ProcessDocumentRequest ou BatchProcessDocumentsRequest.
Para mais informações, consulte Enviar uma solicitação de processamento.
Análise da qualidade da imagem
A análise inteligente da qualidade de documentos usa o aprendizado de máquina para avaliar a qualidade de um documento com base na legibilidade do conteúdo.
Essa avaliação de qualidade é retornada como um índice de qualidade [0, 1], em que 1 significa qualidade perfeita.
Se o Índice de qualidade detectado for menor que 0.5, uma lista de motivos de qualidade negativa (classificados por probabilidade) também será retornada.
Uma probabilidade maior que 0.5 é considerada uma detecção positiva.
Se o documento for considerado defeituoso, a API vai retornar os seguintes oito tipos de defeito:
Há algumas limitações na análise de qualidade do documento atual:
Entrada
Para ativar, defina ProcessOptions.ocrConfig.enableImageQualityScores como true na solicitação de processamento.
Esse recurso extra adiciona à chamada do processo uma latência comparável ao processamento de OCR.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"enableImageQualityScores": true
}
}
}
Saída
Os resultados da detecção de defeitos aparecem em Document.pages[].imageQualityScores[].
{
"pages": [
{
"imageQualityScores": {
"qualityScore": 0.7811847,
"detectedDefects": [
{
"type": "quality/defect_document_cutoff",
"confidence": 1.0
},
{
"type": "quality/defect_glare",
"confidence": 0.97849524
},
{
"type": "quality/defect_text_cutoff",
"confidence": 0.5
}
]
}
}
]
}
Consulte Exemplo de saída do processador para ver exemplos de saída completos.
Dicas de idioma
O processador de OCR é compatível com dicas de idioma que você define para melhorar o desempenho do mecanismo de OCR. Ao aplicar uma dica de idioma, o OCR pode otimizar para um idioma selecionado em vez de um idioma inferido.
Entrada
Para ativar, defina ProcessOptions.ocrConfig.hints[].languageHints[] com uma lista de códigos de idioma BCP-47.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"hints": {
"languageHints": ["en", "es"]
}
}
}
}
Consulte Exemplo de saída do processador para ver exemplos de saída completos.
Detecção de símbolos
Preencha os dados no nível do símbolo (ou letra individual) na resposta do documento.
Entrada
Para ativar, defina ProcessOptions.ocrConfig.enableSymbol como true na solicitação de processamento.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"enableSymbol": true
}
}
}
Saída
Se esse recurso estiver ativado, o campo Document.pages[].symbols[] será preenchido.
Consulte Exemplo de saída do processador para ver exemplos de saída completos.
Análise de PDF integrada
Extrair texto incorporado de arquivos PDF digitais. Quando ativado, se houver texto digital, o modelo de PDF digital integrado será usado automaticamente. Se houver texto não digital, o modelo óptico de OCR será usado automaticamente. O usuário recebe os dois resultados de texto mesclados.
Entrada
Para ativar, defina ProcessOptions.ocrConfig.enableNativePdfParsing como true na solicitação de processamento.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"enableNativePdfParsing": true
}
}
}
Detecção de personagem na caixa
Por padrão, o Enterprise Document OCR tem um detector ativado para melhorar a qualidade da extração de texto de caracteres que estão dentro de uma caixa. Veja um exemplo:

Se você estiver tendo problemas de qualidade do OCR com caracteres dentro de caixas, desative essa opção.
Entrada
Para desativar, defina ProcessOptions.ocrConfig.disableCharacterBoxesDetection como true na solicitação de processamento.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"disableCharacterBoxesDetection": true
}
}
}
Layout legado
Se você precisar de um algoritmo heurístico de detecção de layout, ative o layout legado, que serve como alternativa ao algoritmo atual de detecção de layout baseado em ML. Essa não é a configuração recomendada. Os clientes podem escolher o algoritmo de layout mais adequado com base no fluxo de trabalho de documentos.
Entrada
Para ativar, defina ProcessOptions.ocrConfig.advancedOcrOptions como ["legacy_layout"] na solicitação de processamento.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"advancedOcrOptions": ["legacy_layout"]
}
}
}
Especificar um intervalo de páginas
Por padrão, o OCR extrai texto e informações de layout de todas as páginas dos documentos. Você pode selecionar números ou intervalos de páginas específicos e extrair apenas o texto delas.
Há três maneiras de configurar isso no ProcessOptions:
{
"individualPageSelector": {"pages": [2, 5]}
}
{
"fromStart": 3
}
{
"fromEnd": 4
}
Na resposta, cada Document.pages[].pageNumber corresponde às mesmas páginas especificadas na solicitação.
Usos de complementos de OCR
Esses recursos opcionais de análise do Enterprise Document OCR podem ser ativados em solicitações de processamento individuais, conforme necessário.
OCR matemático
O OCR matemático detecta, reconhece e extrai fórmulas, como equações matemáticas representadas como LaTeX, além de coordenadas de caixa delimitadora.
Confira um exemplo de representação em LaTeX:
Entrada
Para ativar, defina ProcessOptions.ocrConfig.premiumFeatures.enableMathOcr como true na solicitação de processamento.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"premiumFeatures": {
"enableMathOcr": true
}
}
}
}
Saída
A saída do reconhecimento óptico de caracteres de matemática aparece em Document.pages[].visualElements[] com "type": "math_formula".
"visualElements": [
{
"layout": {
"textAnchor": {
"textSegments": [
{
"endIndex": "46"
}
]
},
"confidence": 1,
"boundingPoly": {
"normalizedVertices": [
{
"x": 0.14662756,
"y": 0.27891156
},
{
"x": 0.9032258,
"y": 0.27891156
},
{
"x": 0.9032258,
"y": 0.8027211
},
{
"x": 0.14662756,
"y": 0.8027211
}
]
},
"orientation": "PAGE_UP"
},
"type": "math_formula"
}
]
Extração de marca de seleção
Se ativado, o modelo tenta extrair todas as caixas de seleção e botões de opção no documento, além das coordenadas da caixa delimitadora.
Entrada
Para ativar, defina ProcessOptions.ocrConfig.premiumFeatures.enableSelectionMarkDetection como true na solicitação de processamento.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"premiumFeatures": {
"enableSelectionMarkDetection": true
}
}
}
}
Saída
A saída da caixa de seleção aparece em Document.pages[].visualElements[] com "type": "unfilled_checkbox" ou "type": "filled_checkbox".

"visualElements": [
{
"layout": {
"confidence": 0.89363575,
"boundingPoly": {
"vertices": [
{
"x": 11,
"y": 24
},
{
"x": 37,
"y": 24
},
{
"x": 37,
"y": 56
},
{
"x": 11,
"y": 56
}
],
"normalizedVertices": [
{
"x": 0.017488075,
"y": 0.38709676
},
{
"x": 0.05882353,
"y": 0.38709676
},
{
"x": 0.05882353,
"y": 0.9032258
},
{
"x": 0.017488075,
"y": 0.9032258
}
]
}
},
"type": "unfilled_checkbox"
},
{
"layout": {
"confidence": 0.9148201,
"boundingPoly": ...
},
"type": "filled_checkbox"
}
],
Detecção de estilo de fonte
Com a detecção de estilo de fonte ativada, o Enterprise Document OCR extrai atributos de fonte, que podem ser usados para um melhor pós-processamento.
No nível do token (palavra), os seguintes atributos são detectados:
Entrada
Para ativar, defina ProcessOptions.ocrConfig.premiumFeatures.computeStyleInfo como true na solicitação de processamento.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"premiumFeatures": {
"computeStyleInfo": true
}
}
}
}
Saída
A saída de font-style aparece em Document.pages[].tokens[].styleInfo com o tipo StyleInfo.

"tokens": [
{
"styleInfo": {
"fontSize": 3,
"pixelFontSize": 13,
"fontType": "SANS_SERIF",
"bold": true,
"fontWeight": 564,
"textColor": {
"red": 0.16862746,
"green": 0.16862746,
"blue": 0.16862746
},
"backgroundColor": {
"red": 0.98039216,
"green": 0.9882353,
"blue": 0.99215686
}
}
},
...
]
Converter objetos de documento para o formato da API Vision AI
O Document AI Toolbox inclui uma ferramenta que converte o formato Document da API Document AI para o formato AnnotateFileResponse da API Vision AI. Assim, os usuários podem comparar as respostas entre o processador de OCR de documentos e a API Vision AI. Confira um exemplo de código.
Discrepâncias conhecidas entre a resposta da API Vision AI e a resposta e o conversor da API Document AI:
Amostras de código
Os exemplos de código a seguir mostram como enviar uma solicitação de processamento ativando configurações e complementos de OCR e, em seguida, ler e imprimir os campos no terminal:
REST
Antes de usar os dados da solicitação abaixo, faça as substituições a seguir:
† Esse conteúdo também pode ser especificado usando conteúdo codificado em base64 no objeto inlineDocument.
Método HTTP e URL:
POST https://LOCATION-documentai.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process
Corpo JSON da solicitação:
{
"skipHumanReview": skipHumanReview,
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"fieldMask": "FIELD_MASK",
"processOptions": {
"ocrConfig": {
"enableNativePdfParsing": ENABLE_NATIVE_PDF_PARSING,
"enableImageQualityScores": ENABLE_IMAGE_QUALITY_SCORES,
"enableSymbol": ENABLE_SYMBOL,
"disableCharacterBoxesDetection": DISABLE_CHARACTER_BOXES_DETECTION,
"hints": {
"languageHints": [
"LANGUAGE_HINTS"
]
},
"advancedOcrOptions": ["ADVANCED_OCR_OPTIONS"],
"premiumFeatures": {
"enableSelectionMarkDetection": ENABLE_SELECTION_MARK_DETECTION,
"computeStyleInfo": COMPUTE_STYLE_INFO,
"enableMathOcr": ENABLE_MATH_OCR,
}
},
"individualPageSelector" {
"pages": [INDIVIDUAL_PAGES]
}
}
}
Para enviar a solicitação, escolha uma destas opções:
curl
Salve o corpo da solicitação em um arquivo com o nome request.json e execute o comando a seguir:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process"
PowerShell
Salve o corpo da solicitação em um arquivo com o nome request.json
e execute o comando a seguir:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION-documentai.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process" | Select-Object -Expand Content
Quando a solicitação é bem-sucedida, o servidor retorna um código de status HTTP 200 OK e a
resposta no formato JSON. O corpo da resposta contém uma instância de Document.
Python
Para mais informações, consulte a documentação de referência da API Python da Document AI.
Para autenticar na Document AI, configure o Application Default Credentials. Para mais informações, consulte Configurar a autenticação para um ambiente de desenvolvimento local.