Vous pouvez utiliser Enterprise Document OCR dans Document AI pour détecter et extraire du texte et des informations de mise en page à partir de différents documents. Grâce aux fonctionnalités configurables, vous pouvez adapter le système pour répondre à des exigences spécifiques de traitement des documents.
Présentation
Vous pouvez utiliser Enterprise Document OCR pour des tâches telles que la saisie de données basée sur des algorithmes ou le machine learning, ainsi que pour améliorer et vérifier la précision des données. Vous pouvez également utiliser Enterprise Document OCR pour effectuer des tâches telles que :
- Numérisation de texte : extrayez le texte et les données de mise en page des documents pour la recherche, les pipelines de traitement de documents basés sur des règles ou la création de modèles personnalisés.
- Utiliser des applications de grands modèles de langage : utilisez la compréhension contextuelle des LLM et les capacités d'extraction de texte et de mise en page de l'OCR pour automatiser les questions et les réponses. Dégagez des insights à partir des données et simplifiez les workflows.
- Archivage : numérisez les documents papier pour les rendre lisibles par machine et améliorer leur accessibilité.
Choisir la meilleure solution OCR pour votre cas d'utilisation
| Solution | Produit | Description | Cas d'utilisation |
|---|---|---|---|
| Document AI | Enterprise Document OCR | Modèle spécialisé pour les cas d'utilisation de documents. Les fonctionnalités avancées incluent le score de qualité de l'image, les indications de langue et la correction de la rotation. | Recommandé pour extraire du texte de documents. Il peut s'agir de fichiers PDF, de documents scannés en tant qu'images ou de fichiers Microsoft DocX. |
| Document AI | Modules complémentaires OCR | Des fonctionnalités premium pour répondre à des besoins spécifiques. Compatible uniquement avec Enterprise Document OCR version 2.0 et ultérieure. | Vous devez détecter et reconnaître des formules mathématiques, recevoir des informations sur le style de police ou activer l'extraction de cases à cocher. |
| API Cloud Vision | Détection de texte | API REST disponible dans le monde entier, basée sur le modèle OCR standard Google Cloud . Quota par défaut de 1 800 requêtes par minute. | Cas d'utilisation généraux d'extraction de texte nécessitant une faible latence et une capacité élevée. |
| Cloud Vision | OCR Google Distributed Cloud (obsolète) | Application Google Cloud Marketplace qui peut être déployée en tant que conteneur sur n'importe quel cluster GKE à l'aide de GKE Enterprise. | Pour répondre aux exigences de résidence ou de conformité des données. |
Détection et extraction
Enterprise Document OCR peut détecter des blocs, des paragraphes, des lignes, des mots et des symboles dans des PDF et des images, et redresser les documents pour une meilleure précision.
Attributs de détection et d'extraction de mise en page acceptés :
| Texte imprimé | Écriture manuscrite | Paragraphe | Bloquer | Line | Éléments textuels | Au niveau des symboles | Numéro de page |
|---|---|---|---|---|---|---|---|
| Par défaut | Par défaut | Par défaut | Par défaut | Par défaut | Par défaut | Configurable | Par défaut |
Les fonctionnalités configurables d'Enterprise Document OCR sont les suivantes :
Extraire du texte intégré ou natif à partir de PDF numériques : cette fonctionnalité extrait le texte et les symboles exactement tels qu'ils apparaissent dans les documents sources, même pour les textes pivotés, les tailles ou styles de police extrêmes, et le texte partiellement masqué.
Correction de l'orientation : utilisez Enterprise Document OCR pour prétraiter les images de documents afin de corriger les problèmes d'orientation qui peuvent affecter la qualité de l'extraction ou le traitement.
Score de qualité d'image : recevez des métriques de qualité qui peuvent vous aider à acheminer les documents. Le score de qualité des images fournit des métriques de qualité au niveau de la page dans huit dimensions, y compris le flou, la présence de polices plus petites que d'habitude et l'éblouissement.
Spécifier la plage de pages : spécifie la plage de pages d'un document d'entrée pour l'OCR. Cela permet d'économiser des dépenses et du temps de traitement sur les pages inutiles.
Détection de la langue : détecte les langues utilisées dans les textes extraits.
Suggestions de langue et d'écriture manuscrite : améliorez la précision en fournissant au modèle OCR une suggestion de langue ou d'écriture manuscrite en fonction des caractéristiques connues de votre ensemble de données.
Pour savoir comment activer les configurations OCR, consultez Activer les configurations OCR.
Modules complémentaires OCR
Enterprise Document OCR propose des fonctionnalités d'analyse facultatives qui peuvent être activées sur les demandes de traitement individuelles, selon les besoins.
Les fonctionnalités complémentaires suivantes sont disponibles pour les versions pretrained-ocr-v2.0-2023-06-02 et pretrained-ocr-v2.1-2024-08-07 stables, ainsi que pour la version pretrained-ocr-v2.1.1-2025-01-31 Release Candidate.
- OCR pour les formules mathématiques : identifiez et extrayez les formules des documents au format LaTeX.
- Extraction des cases à cocher : détectez les cases à cocher et extrayez leur état (coché/décoché) dans la réponse Enterprise Document OCR.
- Détection du style de police : identifiez les propriétés de police au niveau des mots, y compris le type, le style, l'écriture manuscrite, l'épaisseur et la couleur de la police.
Pour savoir comment activer les modules complémentaires listés, consultez Activer les modules complémentaires de reconnaissance optique des caractères.
Formats de fichiers acceptés
La reconnaissance optique des caractères pour les documents d'entreprise est compatible avec les formats de fichiers PDF, GIF, TIFF, JPEG, PNG, BMP et WebP. Pour en savoir plus, consultez Fichiers acceptés.
Enterprise Document OCR est également compatible avec les fichiers DocX jusqu'à 15 pages en mode synchrone et 30 pages en mode asynchrone. Pour effectuer une demande d'augmentation de quota (DAQ), suivez les étapes décrites dans Demander un ajustement de quota. La compatibilité avec le format DocX est en version Preview privée. Pour demander l'accès, contactez l'équipe responsable de votre compte Google.
Gestion avancée des versions
La gestion avancée des versions est disponible en version bêta. Les mises à niveau des modèles OCR d'IA/ML sous-jacents peuvent entraîner des modifications du comportement de l'OCR. Si une cohérence stricte est requise, utilisez une version figée du modèle pour ancrer le comportement à un ancien modèle OCR pendant 18 mois maximum. Cela garantit le même résultat pour la fonction OCR d'image. Consultez le tableau sur les versions de l'outil de traitement.
Versions du processeur
Les versions de processeur suivantes sont compatibles avec cette fonctionnalité. Pour en savoir plus, consultez Gérer les versions de l'outil de traitement.
| ID de version | Canal de publication | Description |
|---|---|---|
pretrained-ocr-v1.2-2022-11-10 |
Stable | Version figée du modèle v1.0 : fichiers, configurations et binaires du modèle d'un instantané de version figé dans une image de conteneur pendant 18 mois maximum. |
pretrained-ocr-v2.0-2023-06-02 |
Stable | Modèle prêt pour la production, spécialisé dans les cas d'utilisation de documents. Inclut l'accès à tous les modules complémentaires OCR. |
pretrained-ocr-v2.1-2024-08-07 |
Stable | Les principaux axes d'amélioration de la version 2.1 sont les suivants : meilleure reconnaissance du texte imprimé, détection plus précise des cases à cocher et ordre de lecture plus précis. |
pretrained-ocr-v2.1.1-2025-01-31 |
Version candidate | La version 2.1.1 est semblable à la version 2.1 et est disponible dans toutes les régions, à l'exception de US, EU et asia-southeast1. |
Utiliser Enterprise Document OCR pour traiter des documents
Ce guide de démarrage rapide vous présente la reconnaissance optique des caractères pour les documents Enterprise. Il vous explique comment optimiser les résultats de la reconnaissance optique des caractères (ROC) pour les documents dans votre workflow en activant ou en désactivant l'une des configurations de ROC disponibles.
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. quality/defect_blurryquality/defect_noisyquality/defect_darkquality/defect_faintquality/defect_text_too_smallquality/defect_document_cutoffquality/defect_text_cutoffquality/defect_glare- Il peut renvoyer des faux positifs pour des documents numériques sans défaut. Cette fonctionnalité est plus efficace sur les documents numérisés ou photographiés.
Les défauts d'éblouissement sont locaux. Leur présence n'empêche pas forcément la lisibilité globale du document.
- Pour ne traiter que la deuxième et la cinquième page :
- Pour ne traiter que les trois premières pages :
- Pour ne traiter que les quatre dernières pages :
Image détectée
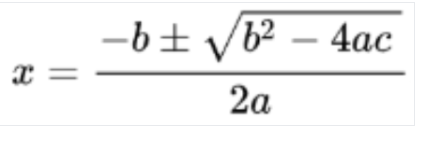
Conversion au format LaTeX
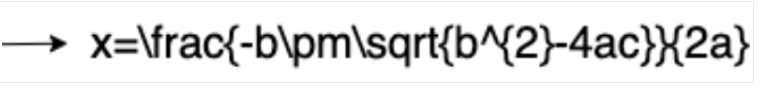
- Détection de l'écriture manuscrite
- Style de police
- Taille de police
- Type de police
- Couleur de la police
- Épaisseur de la police
- L'espacement entre les lettres
- Gras
- Italique
- Souligné
- Couleur du texte (RGBa)
Couleur d'arrière-plan (RGBa)
- La réponse de l'API Vision AI ne renseigne que
verticespour les requêtes d'images etnormalized_verticespour les requêtes de PDF. La réponse Document AI et le convertisseur remplissentverticesetnormalized_vertices. - La réponse de l'API Vision AI renseigne
detected_breakdans le dernier symbole du mot. La réponse de l'API Document AI et le convertisseur renseignentdetected_breakdans le mot et le dernier symbole du mot. - La réponse de l'API Vision AI remplit toujours les champs de symboles. Par défaut, la réponse Document AI ne renseigne pas les champs de symboles. Pour vous assurer que les champs de symboles de la réponse Document AI et du convertisseur sont renseignés, définissez la fonctionnalité
enable_symbolcomme détaillé. - LOCATION : emplacement de votre processeur, par exemple :
us: États-Uniseu: Union européenne
- PROJECT_ID : ID de votre projet Google Cloud .
- PROCESSOR_ID : ID de votre processeur personnalisé.
- PROCESSOR_VERSION : identifiant de la version du processeur. Pour en savoir plus, consultez Sélectionner une version de l'outil de traitement. Par exemple :
- .
pretrained-TYPE-vX.X-YYYY-MM-DDstablerc
- skipHumanReview : booléen permettant de désactiver l'examen manuel (compatible uniquement avec les processeurs Human-in-the-Loop).
true: l'examen manuel est ignoré.false: active l'examen manuel (valeur par défaut)
- MIME_TYPE† : l'une des options de type MIME valides.
- IMAGE_CONTENT† : contenu de document intégré valide, représenté sous forme de flux d'octets. Pour les représentations JSON, l'encodage en base64 (chaîne ASCII) de vos données d'image binaires. Cette chaîne doit ressembler à la chaîne suivante :
/9j/4QAYRXhpZgAA...9tAVx/zDQDlGxn//2Q==
- FIELD_MASK : spécifie les champs à inclure dans la sortie
Document. Il s'agit d'une liste de noms de champs complets au formatFieldMask.- Exemple :
text,entities,pages.pageNumber
- Exemple :
- Configurations de l'OCR
- ENABLE_NATIVE_PDF_PARSING : (booléen) extrait le texte intégré des PDF, le cas échéant.
- ENABLE_IMAGE_QUALITY_SCORES : (valeur booléenne) active les évaluations intelligentes de la qualité des documents.
- ENABLE_SYMBOL : (booléen) inclut les informations OCR sur les symboles (lettres).
- DISABLE_CHARACTER_BOXES_DETECTION : (booléen) désactive le détecteur de cadres de caractères dans le moteur OCR.
- LANGUAGE_HINTS : liste des codes de langue BCP-47 à utiliser pour la reconnaissance optique de caractères.
- ADVANCED_OCR_OPTIONS : liste des options OCR avancées permettant d'affiner le comportement de l'OCR. Les valeurs valides actuelles sont les suivantes :
legacy_layout: algorithme de détection de mise en page heuristique, qui sert d'alternative à l'algorithme de détection de mise en page basé sur le ML actuel.
- Modules complémentaires OCR Premium
- ENABLE_SELECTION_MARK_DETECTION : (booléen) active le détecteur de marques de sélection dans le moteur OCR.
- COMPUTE_STYLE_INFO (booléen) : active le modèle d'identification de police et renvoie les informations sur le style de police.
- ENABLE_MATH_OCR : (booléen) active le modèle pouvant extraire les formules mathématiques LaTeX.
- INDIVIDUAL_PAGES : liste des pages individuelles à traiter.
- Consultez la liste des outils de traitement.
- Séparez les documents en fragments lisibles avec l'analyseur de mise en page.
- Créez un classificateur personnalisé.
Créer un processeur Enterprise Document OCR
Commencez par créer un processeur Enterprise Document OCR. Pour en savoir plus, consultez Créer et gérer des processeurs.
Configurations OCR
Toutes les configurations OCR peuvent être activées en définissant les champs correspondants dans ProcessOptions.ocrConfig dans ProcessDocumentRequest ou BatchProcessDocumentsRequest.
Pour en savoir plus, consultez Envoyer une demande de traitement.
Analyse de la qualité des images
L'analyse intelligente de la qualité des documents utilise le machine learning pour évaluer la qualité d'un document en fonction de la lisibilité de son contenu.
Cette évaluation de la qualité est renvoyée sous la forme d'un niveau de qualité [0, 1], où 1 signifie une qualité parfaite.
Si le niveau de qualité détecté est inférieur à 0.5, une liste des raisons de mauvaise qualité (triées par probabilité) est également renvoyée.
Une probabilité supérieure à 0.5 est considérée comme une détection positive.
Si le document est considéré comme défectueux, l'API renvoie les huit types de défauts de document suivants :
L'analyse de la qualité des documents présente certaines limites :
Entrée
Pour l'activer, définissez ProcessOptions.ocrConfig.enableImageQualityScores sur true dans la demande de traitement.
Cette fonctionnalité supplémentaire ajoute une latence comparable au traitement OCR à l'appel du processus.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"enableImageQualityScores": true
}
}
}
Sortie
Les résultats de la détection des défauts s'affichent dans Document.pages[].imageQualityScores[].
{
"pages": [
{
"imageQualityScores": {
"qualityScore": 0.7811847,
"detectedDefects": [
{
"type": "quality/defect_document_cutoff",
"confidence": 1.0
},
{
"type": "quality/defect_glare",
"confidence": 0.97849524
},
{
"type": "quality/defect_text_cutoff",
"confidence": 0.5
}
]
}
}
]
}
Pour obtenir des exemples de sortie complets, consultez Exemple de sortie de processeur.
Indicateurs de langue
Le processeur de reconnaissance optique des caractères est compatible avec les indications de langue que vous définissez pour améliorer les performances du moteur de reconnaissance optique des caractères. L'application d'un indice de langue permet à la ROC d'optimiser la reconnaissance pour une langue sélectionnée au lieu d'une langue déduite.
Entrée
Pour l'activer, définissez ProcessOptions.ocrConfig.hints[].languageHints[] avec une liste de codes de langue BCP-47.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"hints": {
"languageHints": ["en", "es"]
}
}
}
}
Pour obtenir des exemples de sortie complets, consultez Exemple de sortie de processeur.
Détection des symboles
Renseigne les données au niveau du symbole (ou de la lettre individuelle) dans la réponse du document.
Entrée
Pour l'activer, définissez ProcessOptions.ocrConfig.enableSymbol sur true dans la demande de traitement.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"enableSymbol": true
}
}
}
Sortie
Si cette fonctionnalité est activée, le champ Document.pages[].symbols[] est renseigné.
Pour obtenir des exemples de sortie complets, consultez Exemple de sortie de processeur.
Analyse PDF intégrée
Extrayez le texte intégré des fichiers PDF numériques. Lorsqu'il est activé, le modèle PDF numérique intégré est automatiquement utilisé s'il existe du texte numérique. Si le texte n'est pas numérique, le modèle OCR optique est automatiquement utilisé. L'utilisateur reçoit les deux résultats textuels fusionnés.
Entrée
Pour l'activer, définissez ProcessOptions.ocrConfig.enableNativePdfParsing sur true dans la demande de traitement.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"enableNativePdfParsing": true
}
}
}
Détection de personnages dans une boîte
Par défaut, Enterprise Document OCR dispose d'un détecteur activé pour améliorer la qualité de l'extraction de texte des caractères situés dans une boîte. Voici un exemple :

Si vous rencontrez des problèmes de qualité de reconnaissance optique des caractères avec des caractères dans des cadres, vous pouvez désactiver cette option.
Entrée
Pour le désactiver, définissez ProcessOptions.ocrConfig.disableCharacterBoxesDetection sur true dans la demande de traitement.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"disableCharacterBoxesDetection": true
}
}
}
Ancienne mise en page
Si vous avez besoin d'un algorithme heuristique de détection de la mise en page, vous pouvez activer l'ancienne mise en page, qui sert d'alternative à l'algorithme actuel de détection de la mise en page basé sur le ML. Il ne s'agit pas de la configuration recommandée. Les clients peuvent choisir l'algorithme de mise en page le mieux adapté à leur flux de travail de documents.
Entrée
Pour l'activer, définissez ProcessOptions.ocrConfig.advancedOcrOptions sur ["legacy_layout"] dans la demande de traitement.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"advancedOcrOptions": ["legacy_layout"]
}
}
}
Spécifier une plage de pages
Par défaut, la reconnaissance optique des caractères extrait le texte et les informations de mise en page de toutes les pages des documents. Vous pouvez sélectionner des numéros de page ou des plages de pages spécifiques, et n'extraire le texte que de ces pages.
Il existe trois façons de configurer cela dans ProcessOptions :
{
"individualPageSelector": {"pages": [2, 5]}
}
{
"fromStart": 3
}
{
"fromEnd": 4
}
Dans la réponse, chaque Document.pages[].pageNumber correspond aux mêmes pages que celles spécifiées dans la requête.
Utilisations des modules complémentaires OCR
Ces fonctionnalités d'analyse facultatives Enterprise Document OCR peuvent être activées sur les demandes de traitement individuelles selon les besoins.
Fonction OCR mathématique
La reconnaissance optique des caractères (OCR) mathématique détecte, reconnaît et extrait les formules, telles que les équations mathématiques représentées en LaTeX, ainsi que les coordonnées du cadre de délimitation.
Voici un exemple de représentation LaTeX :
Entrée
Pour l'activer, définissez ProcessOptions.ocrConfig.premiumFeatures.enableMathOcr sur true dans la demande de traitement.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"premiumFeatures": {
"enableMathOcr": true
}
}
}
}
Sortie
Le résultat de la reconnaissance optique des caractères mathématiques s'affiche dans Document.pages[].visualElements[] avec "type": "math_formula".
"visualElements": [
{
"layout": {
"textAnchor": {
"textSegments": [
{
"endIndex": "46"
}
]
},
"confidence": 1,
"boundingPoly": {
"normalizedVertices": [
{
"x": 0.14662756,
"y": 0.27891156
},
{
"x": 0.9032258,
"y": 0.27891156
},
{
"x": 0.9032258,
"y": 0.8027211
},
{
"x": 0.14662756,
"y": 0.8027211
}
]
},
"orientation": "PAGE_UP"
},
"type": "math_formula"
}
]
Vous pouvez consulter la sortie JSON Document complète sur ce lien .
Extraction des marques de sélection
Si cette option est activée, le modèle tente d'extraire toutes les cases à cocher et tous les boutons radio du document, ainsi que les coordonnées du cadre de délimitation.
Entrée
Pour l'activer, définissez ProcessOptions.ocrConfig.premiumFeatures.enableSelectionMarkDetection sur true dans la demande de traitement.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"premiumFeatures": {
"enableSelectionMarkDetection": true
}
}
}
}
Sortie
Le résultat de la case à cocher s'affiche dans Document.pages[].visualElements[] avec "type": "unfilled_checkbox" ou "type": "filled_checkbox".

"visualElements": [
{
"layout": {
"confidence": 0.89363575,
"boundingPoly": {
"vertices": [
{
"x": 11,
"y": 24
},
{
"x": 37,
"y": 24
},
{
"x": 37,
"y": 56
},
{
"x": 11,
"y": 56
}
],
"normalizedVertices": [
{
"x": 0.017488075,
"y": 0.38709676
},
{
"x": 0.05882353,
"y": 0.38709676
},
{
"x": 0.05882353,
"y": 0.9032258
},
{
"x": 0.017488075,
"y": 0.9032258
}
]
}
},
"type": "unfilled_checkbox"
},
{
"layout": {
"confidence": 0.9148201,
"boundingPoly": ...
},
"type": "filled_checkbox"
}
],
Vous pouvez consulter la sortie JSON Document complète sur ce lien .
Détection du style de police
Lorsque la détection du style de police est activée, Enterprise Document OCR extrait les attributs de police, qui peuvent être utilisés pour un meilleur post-traitement.
Au niveau du jeton (mot), les attributs suivants sont détectés :
Entrée
Pour l'activer, définissez ProcessOptions.ocrConfig.premiumFeatures.computeStyleInfo sur true dans la demande de traitement.
{
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"processOptions": {
"ocrConfig": {
"premiumFeatures": {
"computeStyleInfo": true
}
}
}
}
Sortie
La sortie font-style s'affiche dans Document.pages[].tokens[].styleInfo avec le type StyleInfo.

"tokens": [
{
"styleInfo": {
"fontSize": 3,
"pixelFontSize": 13,
"fontType": "SANS_SERIF",
"bold": true,
"fontWeight": 564,
"textColor": {
"red": 0.16862746,
"green": 0.16862746,
"blue": 0.16862746
},
"backgroundColor": {
"red": 0.98039216,
"green": 0.9882353,
"blue": 0.99215686
}
}
},
...
]
Vous pouvez consulter la sortie JSON Document complète sur ce lien .
Convertir des objets de document au format de l'API Vision AI
La boîte à outils Document AI inclut un outil qui convertit le format Document de l'API Document AI au format AnnotateFileResponse de l'API Vision AI. Les utilisateurs peuvent ainsi comparer les réponses entre le processeur de reconnaissance optique des caractères (OCR) de documents et l'API Vision AI. Voici un exemple de code.
Voici les différences connues entre la réponse de l'API Vision AI et celle de l'API Document AI, ainsi que le convertisseur :
Exemples de code
Les exemples de code suivants montrent comment envoyer une requête de traitement permettant les configurations et les modules complémentaires OCR, puis comment lire et imprimer les champs dans le terminal :
REST
Avant d'utiliser les données de requête, effectuez les remplacements suivants :
† Ce contenu peut également être spécifié à l'aide de contenu encodé en base64 dans l'objet inlineDocument.
Méthode HTTP et URL :
POST https://LOCATION-documentai.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process
Corps JSON de la requête :
{
"skipHumanReview": skipHumanReview,
"rawDocument": {
"mimeType": "MIME_TYPE",
"content": "IMAGE_CONTENT"
},
"fieldMask": "FIELD_MASK",
"processOptions": {
"ocrConfig": {
"enableNativePdfParsing": ENABLE_NATIVE_PDF_PARSING,
"enableImageQualityScores": ENABLE_IMAGE_QUALITY_SCORES,
"enableSymbol": ENABLE_SYMBOL,
"disableCharacterBoxesDetection": DISABLE_CHARACTER_BOXES_DETECTION,
"hints": {
"languageHints": [
"LANGUAGE_HINTS"
]
},
"advancedOcrOptions": ["ADVANCED_OCR_OPTIONS"],
"premiumFeatures": {
"enableSelectionMarkDetection": ENABLE_SELECTION_MARK_DETECTION,
"computeStyleInfo": COMPUTE_STYLE_INFO,
"enableMathOcr": ENABLE_MATH_OCR,
}
},
"individualPageSelector" {
"pages": [INDIVIDUAL_PAGES]
}
}
}
Pour envoyer votre requête, choisissez l'une des options suivantes :
curl
Enregistrez le corps de la requête dans un fichier nommé request.json, puis exécutez la commande suivante :
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process"
PowerShell
Enregistrez le corps de la requête dans un fichier nommé request.json, puis exécutez la commande suivante :
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://LOCATION-documentai.googleapis.com/v1/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/processorVersions/PROCESSOR_VERSION:process" | Select-Object -Expand Content
Si la requête aboutit, le serveur renvoie un code d'état HTTP 200 OK et la réponse au format JSON. Le corps de la réponse contient une instance de Document.
Python
Pour en savoir plus, consultez la documentation de référence de l'API Document AI Python.
Pour vous authentifier auprès de Document AI, configurez les Identifiants par défaut de l'application. Pour en savoir plus, consultez Configurer l'authentification pour un environnement de développement local.