Com o treinamento e a extração de modelos personalizados, é possível criar seu próprio modelo projetado especificamente para seus documentos sem usar a IA generativa. É ideal se você não quiser usar a IA generativa e quiser controlar todos os aspectos do modelo treinado.
Configuração do conjunto de dados
Um conjunto de dados de documentos é necessário para treinar, aprimorar o treinamento ou avaliar uma versão do processador. Os processadores da Document AI aprendem com exemplos, assim como os humanos. O conjunto de dados alimenta a estabilidade do processador em termos de desempenho.Conjunto de dados de treinamento
Para melhorar o modelo e a acurácia dele, treine um conjunto de dados nos seus documentos. O modelo é composto de documentos com informações empíricas. Você precisa de pelo menos três documentos para treinar um novo modelo.Conjunto de dados de teste
O conjunto de dados de teste é o que o modelo usa para gerar uma pontuação F1 (acurácia). Ele é composto por documentos com informações empíricas. Para saber com que frequência o modelo está certo, as informações empíricas são usadas para comparar as previsões do modelo (campos extraídos do modelo) com as respostas corretas. O conjunto de dados de teste precisa ter pelo menos três documentos.Antes de começar
Se ainda não tiver feito isso, ative o faturamento e a API Document AI.
Criar e avaliar um modelo personalizado
Comece criando e avaliando um processador personalizado.
Crie um processador e defina os campos que você quer extrair. Isso é importante porque afeta a qualidade da extração.
Defina o local do conjunto de dados: selecione a pasta de opção padrão Gerenciado pelo Google. Isso pode ser feito automaticamente logo após a criação do processador.
Acesse a guia Build e selecione Importar documentos com a rotulagem automática ativada (consulte Rotulagem automática com o modelo básico). É necessário ter no mínimo 10 documentos no conjunto de treinamento e 10 no conjunto de teste para treinar um modelo personalizado.
Treinar modelo:
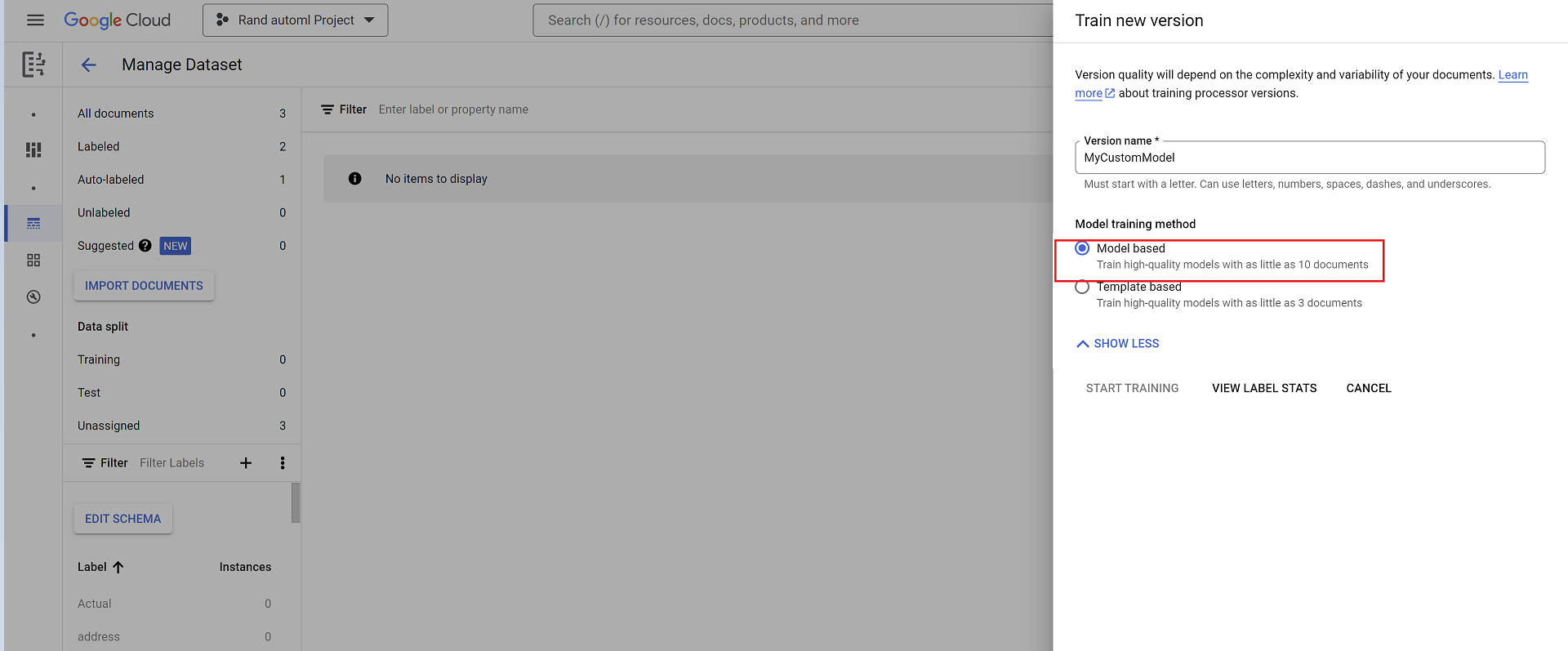
- Selecione Treinar nova versão e nomeie a versão do processador.
- Acesse Mostrar opções avançadas e selecione a opção Baseado em modelo.
Avaliação:
- Acesse Avaliar e testar, selecione a versão que você acabou de treinar e clique em Ver avaliação completa.
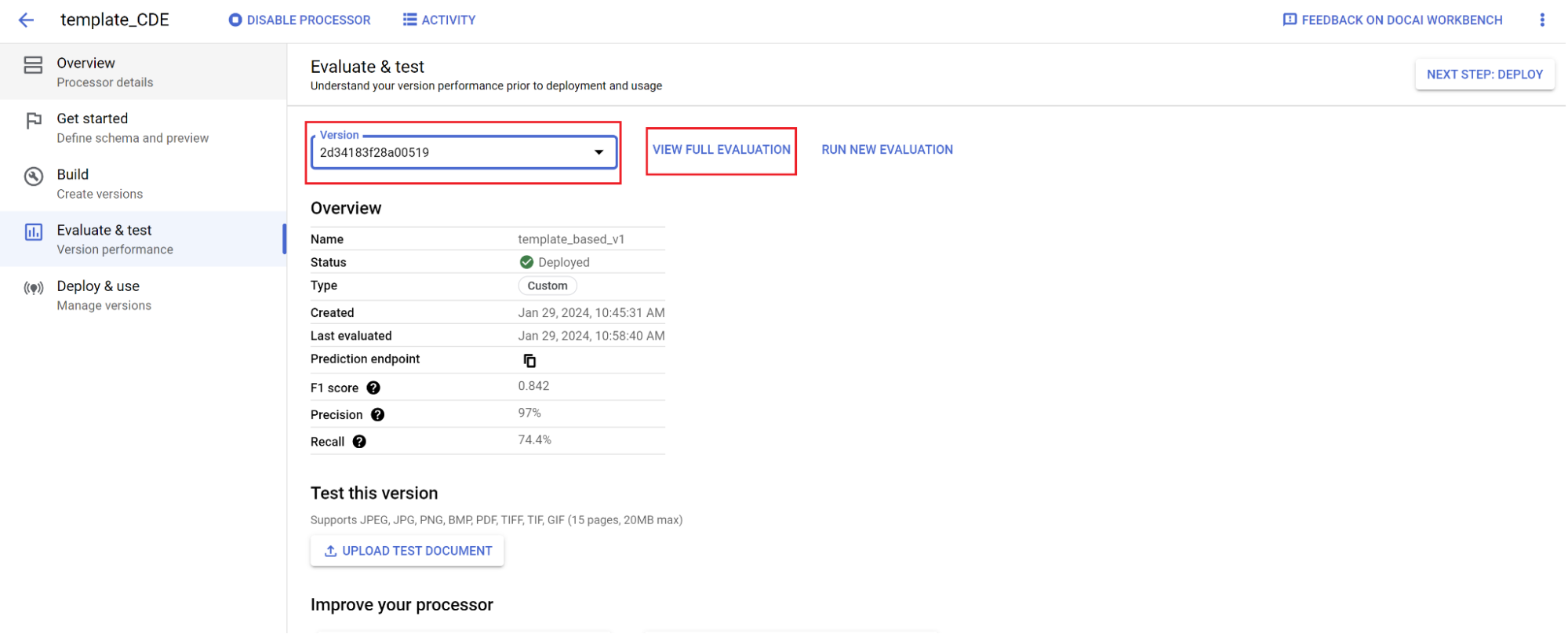
- Agora você vê métricas como f1, precisão e recall para todo o documento e cada campo.
- Decida se a performance atende às suas metas de produção. Se não atender, reavalie os conjuntos de treinamento e teste, geralmente adicionando documentos ao conjunto de teste de treinamento que não são analisados corretamente.
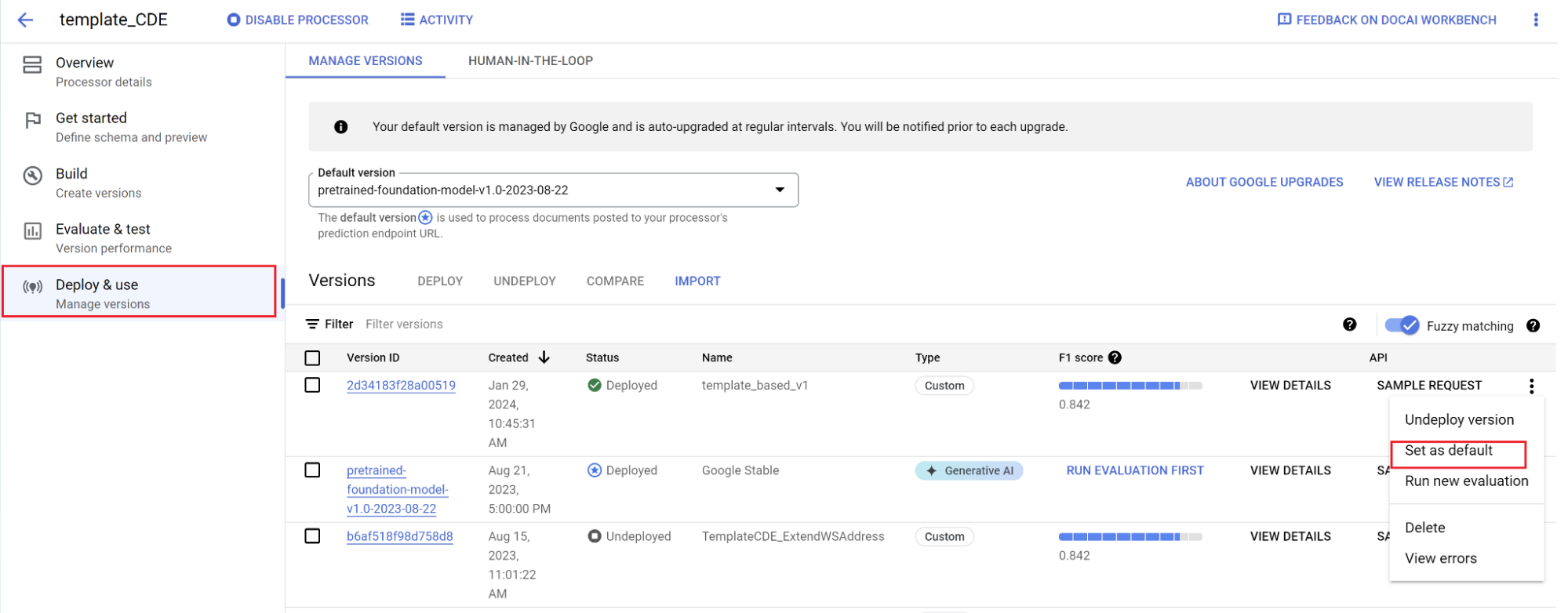
Defina uma nova versão como padrão.
- Acesse Gerenciar versões.
- Navegue até o menu e selecione Definir como padrão.
O modelo foi implantado, e os documentos enviados a esse processador agora usam sua versão personalizada. Você quer avaliar o desempenho do modelo para verificar se ele precisa de mais treinamento.
Referência de avaliação
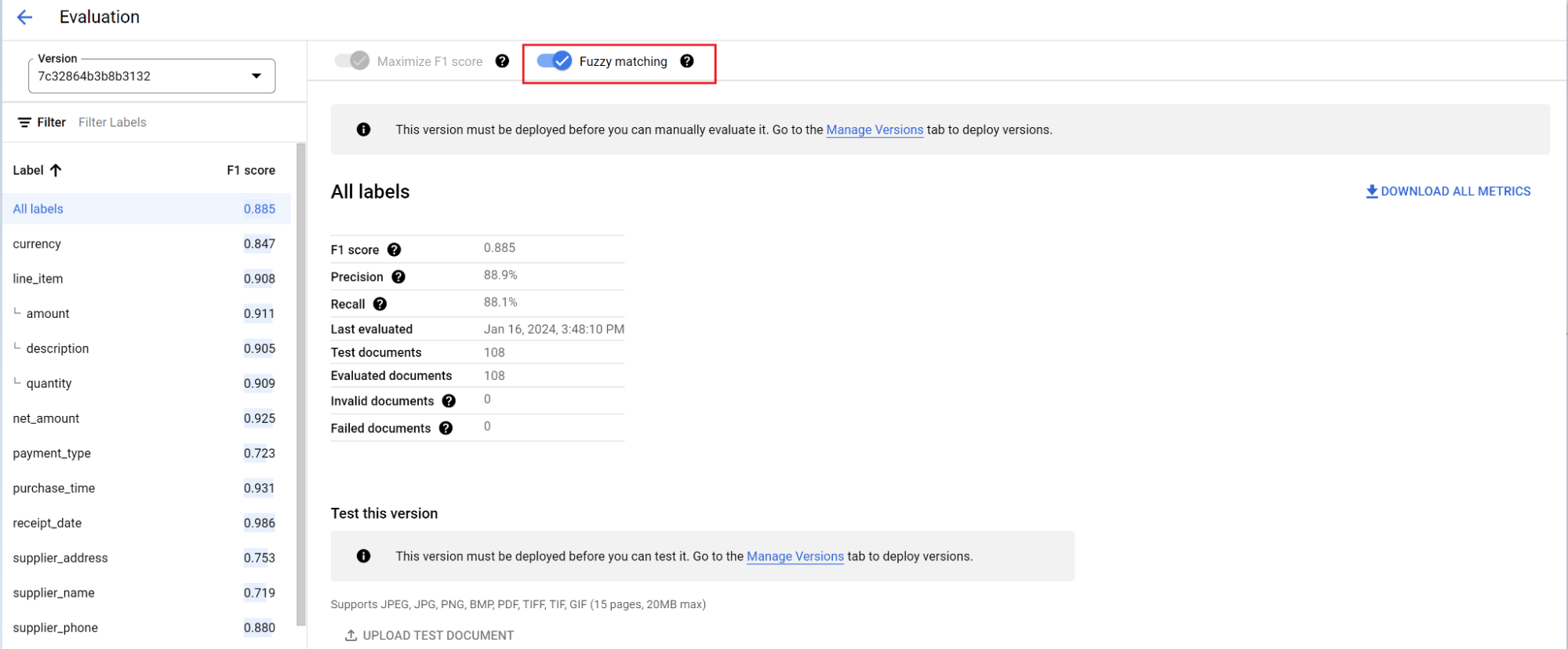
O mecanismo de avaliação pode fazer correspondência exata ou aproximada. Para uma correspondência exata, o valor extraído precisa corresponder exatamente à verdade fundamental ou é contado como uma falha.
As extrações de correspondência aproximada que tinham pequenas diferenças, como o uso de maiúsculas e minúsculas, ainda são consideradas uma correspondência. Isso pode ser mudado na tela Avaliação.
Identificação automática com o modelo de fundação
O modelo de fundação extrai campos com precisão para diversos tipos de documentos, mas também é possível fornecer mais dados de treinamento para melhorar a acurácia do modelo em estruturas de documentos específicas.
A Document AI usa os nomes de rótulo que você define e as anotações anteriores para rotular documentos em grande escala com a rotulagem automática.
- Depois de criar um processador personalizado, acesse a guia Começar.
- Selecione Criar novo campo.
- Dê um nome descritivo e preencha o campo de descrição. A descrição da propriedade permite fornecer mais contexto, insights e conhecimento prévio para cada entidade para melhorar a acurácia e o desempenho da extração.
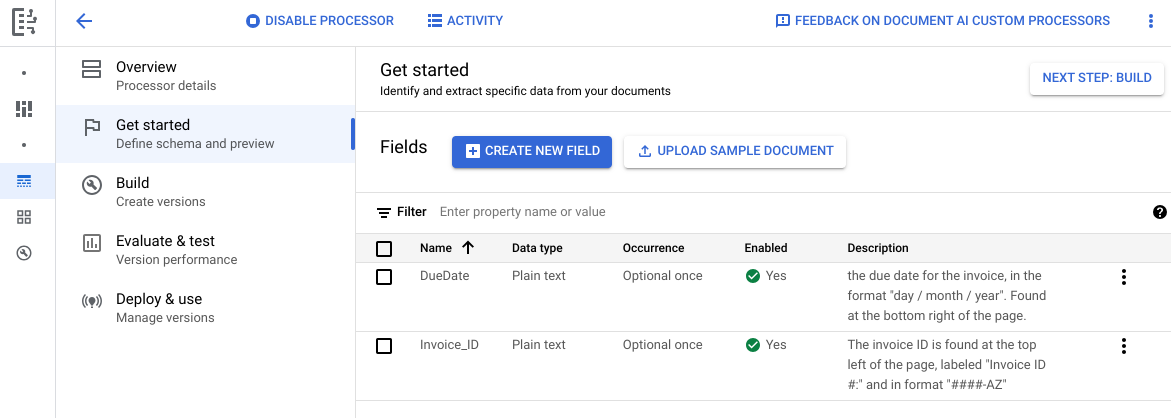
Acesse a guia Build e selecione Importar documentos.
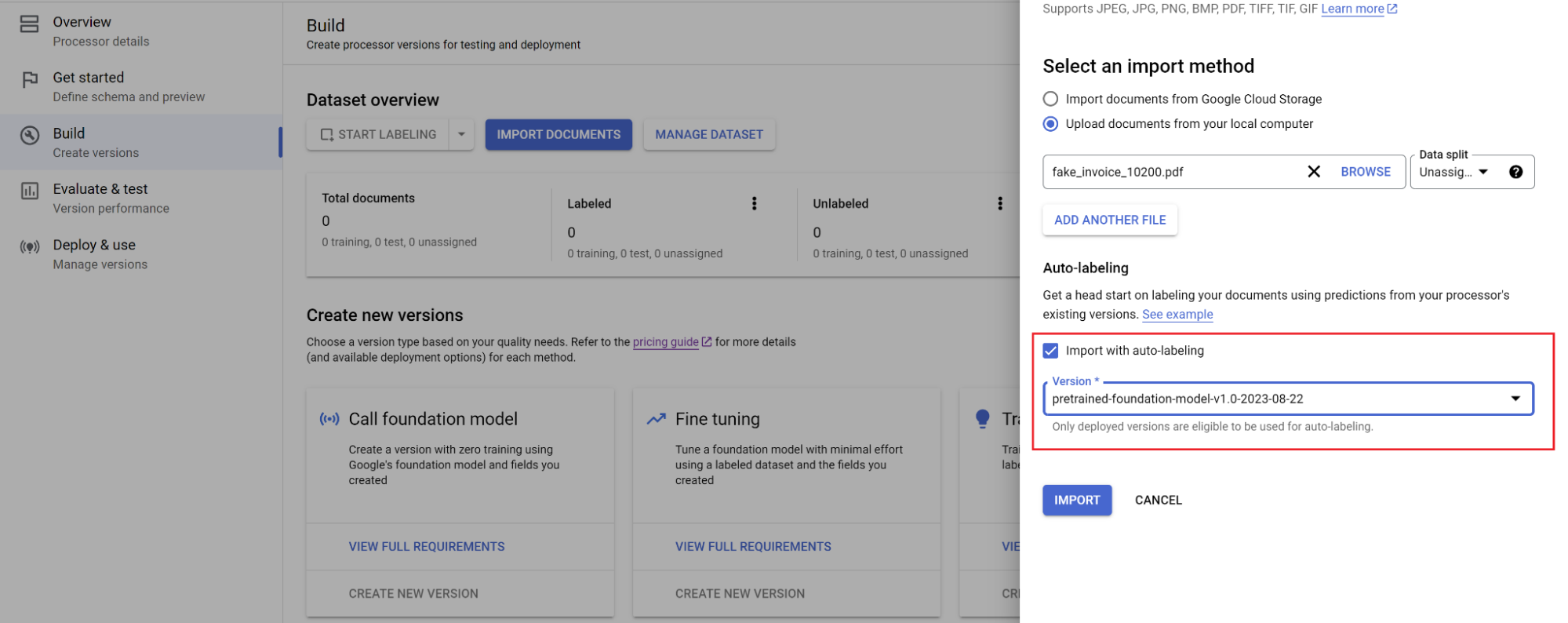
Selecione o caminho dos documentos e em qual conjunto eles serão importados. Marque a caixa de rotulagem automática e selecione o modelo de fundação.
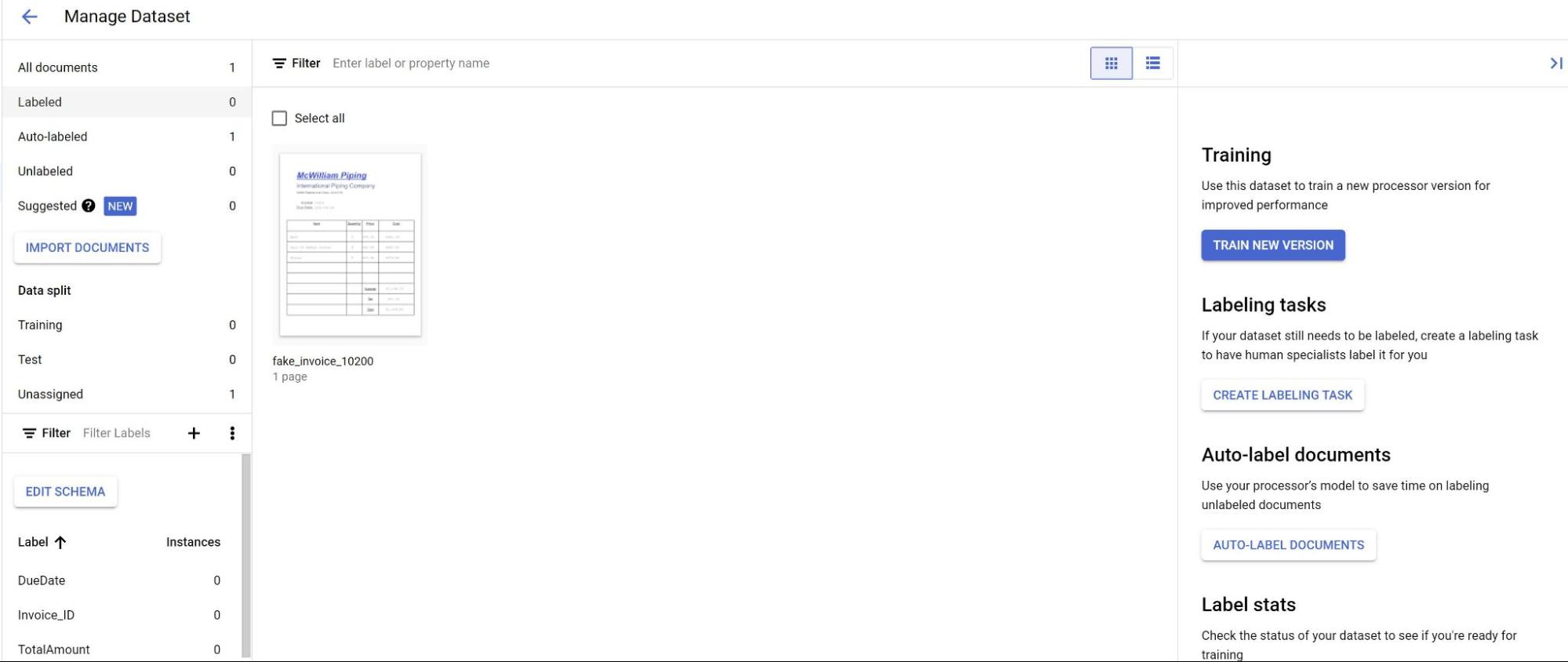
Na guia Build, selecione Gerenciar conjunto de dados. Os documentos importados vão aparecer. Selecione um dos seus documentos.
Agora as previsões do modelo aparecem destacadas em roxo.
- Revise cada rótulo previsto pelo modelo e verifique se está correto. Se houver campos ausentes, adicione-os também.
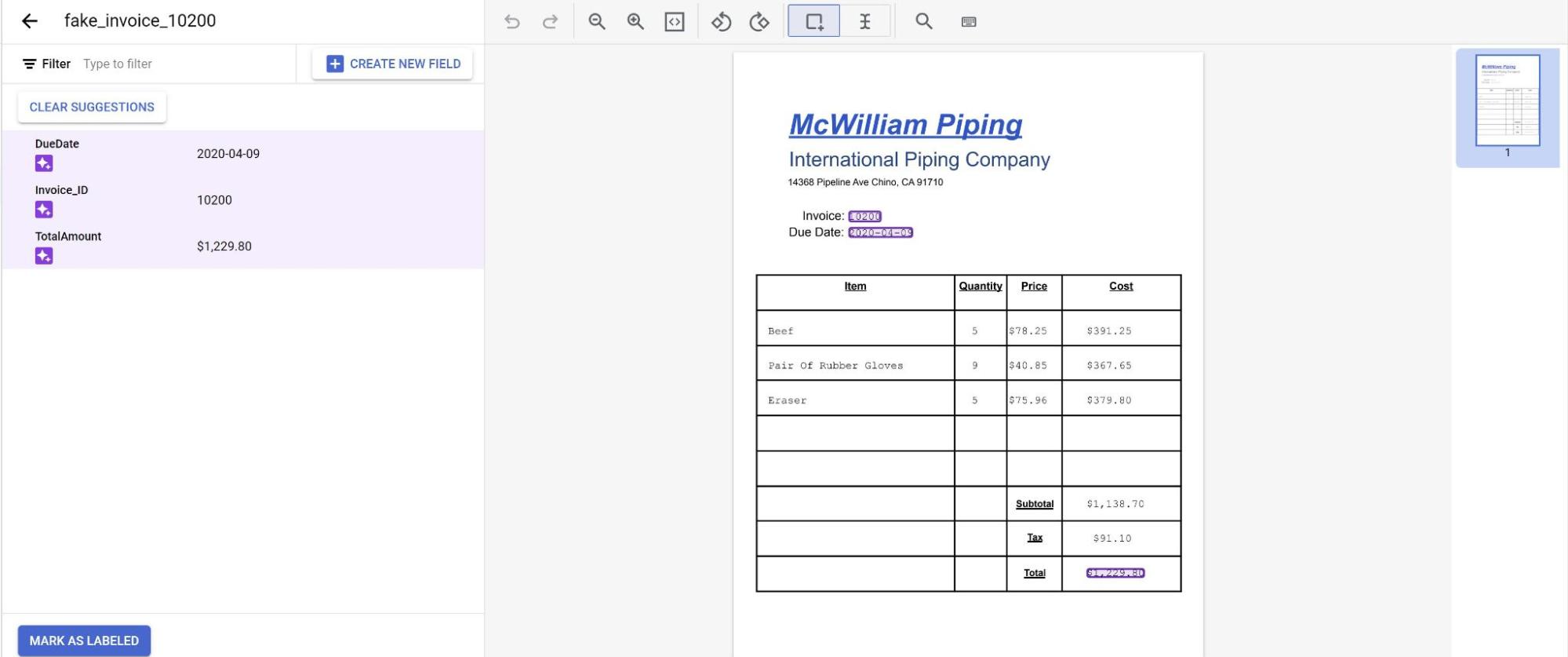
- Depois que o documento for revisado, selecione Marcar como rotulado. O documento está pronto para ser usado pelo modelo. Verifique se o documento está no conjunto de Teste ou Treinamento.