Questa pagina mostra come utilizzare il connettore Spark Spanner per leggere i dati da Spanner utilizzando Apache Spark
Calcolo dei costi
In questo documento utilizzi i seguenti componenti fatturabili di Google Cloud:
- Dataproc
- Spanner
- Cloud Storage
Per generare una stima dei costi basata sull'utilizzo previsto,
utilizza il Calcolatore prezzi.
Prima di iniziare
Prima di eseguire il tutorial, assicurati di conoscere la versione del connettore e di avere un URI del connettore.
Come specificare l'URI del file JAR del connettore
Le versioni del connettore Spark Spanner sono elencate nel repository GitHub GoogleCloudDataproc/spark-spanner-connector.
Specifica il file JAR del connettore sostituendo le informazioni sulla versione del connettore nella seguente stringa URI:
gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jar
Il connettore è disponibile per le versioni di Spark 3.1+
Esempio della gcloud CLI:
gcloud dataproc jobs submit spark \ --jars=gs://spark-lib/spanner/spark-3.1-spanner-1.0.0.jar \ -- job-args
Prepara il database Spanner
Se non hai una tabella Spanner, puoi seguire il
tutorial per crearne una. Dopodiché avrai un ID istanza, un ID database e una tabella Singers.
Crea cluster Dataproc
Qualsiasi cluster Dataproc che utilizza il connettore richiede gli ambiti spanner o cloud-platform. I cluster Dataproc hanno l'ambito predefinito cloud-platform per l'immagine 2.1 o successive. Se utilizzi una versione precedente, puoi utilizzare la console Google Cloud, Google Cloud CLI e l'API Dataproc per creare un cluster Dataproc.
Console
- Nella console Google Cloud, apri la pagina Dataproc Crea un cluster
- Nella scheda "Gestisci la sicurezza", fai clic su "Attiva l'ambito cloud-platform per questo cluster" nella sezione "Accesso al progetto".
- Completa la compilazione o la conferma degli altri campi per la creazione del cluster, poi fai clic su "Crea".
Google Cloud CLI
gcloud dataproc clusters create CLUSTER_NAME --scopes https://www.googleapis.com/auth/cloud-platform
API
Puoi specificare GceClusterConfig.serviceAccountScopes nell'ambito di una richiesta clusters.create. Ad esempio:
"serviceAccountScopes": ["https://www.googleapis.com/auth/cloud-platform"],
Dovrai assicurarti che l'autorizzazione Spanner corrispondente sia assegnata all'account di servizio VM Dataproc. Se utilizzi Data Boost nel tutorial, consulta l'autorizzazione IAM Data Boost.
Leggere i dati da Spanner
Puoi utilizzare Scala e Python per leggere i dati da Spanner in un DataFrame Spark utilizzando l'API Spark Data Source.
Scala
- Esamina il codice e sostituisci i segnaposto [projectId], [instanceId], [databaseId] e [table] con
l'ID progetto, l'ID istanza, l'ID database e la tabella che hai creato in precedenza. L'opzione enableDataBoost attiva la funzionalità Data Boost di Spanner, che ha un impatto quasi nullo sull'istanza Spanner principale.
object singers { def main(): Unit = { /* * Remove comment if you are not running in spark-shell. * import org.apache.spark.sql.SparkSession val spark = SparkSession.builder() .appName("spark-spanner-demo") .getOrCreate() */ // Load data in from Spanner. See // https://github.com/GoogleCloudDataproc/spark-spanner-connector/blob/main/README.md#properties // for option information. val singersDF = (spark.read.format("cloud-spanner") .option("projectId", "[projectId]") .option("instanceId", "[instanceId]") .option("databaseId", "[databaseId]") .option("enableDataBoost", true) .option("table", "[table]") .load() .cache()) singersDF.createOrReplaceTempView("Singers") // Load the Singers table. val result = spark.sql("SELECT * FROM Singers") result.show() result.printSchema() } }
- Esegui il codice sul cluster
- Utilizza SSH per connetterti al nodo master del cluster Dataproc.
- Vai alla pagina
Cluster Dataproc
nella console Google Cloud, quindi fai clic sul nome del cluster
- Nella pagina >Dettagli cluster, seleziona la scheda Istanze VM. Quindi, fai clic su
SSHa destra del nome del nodo master del cluster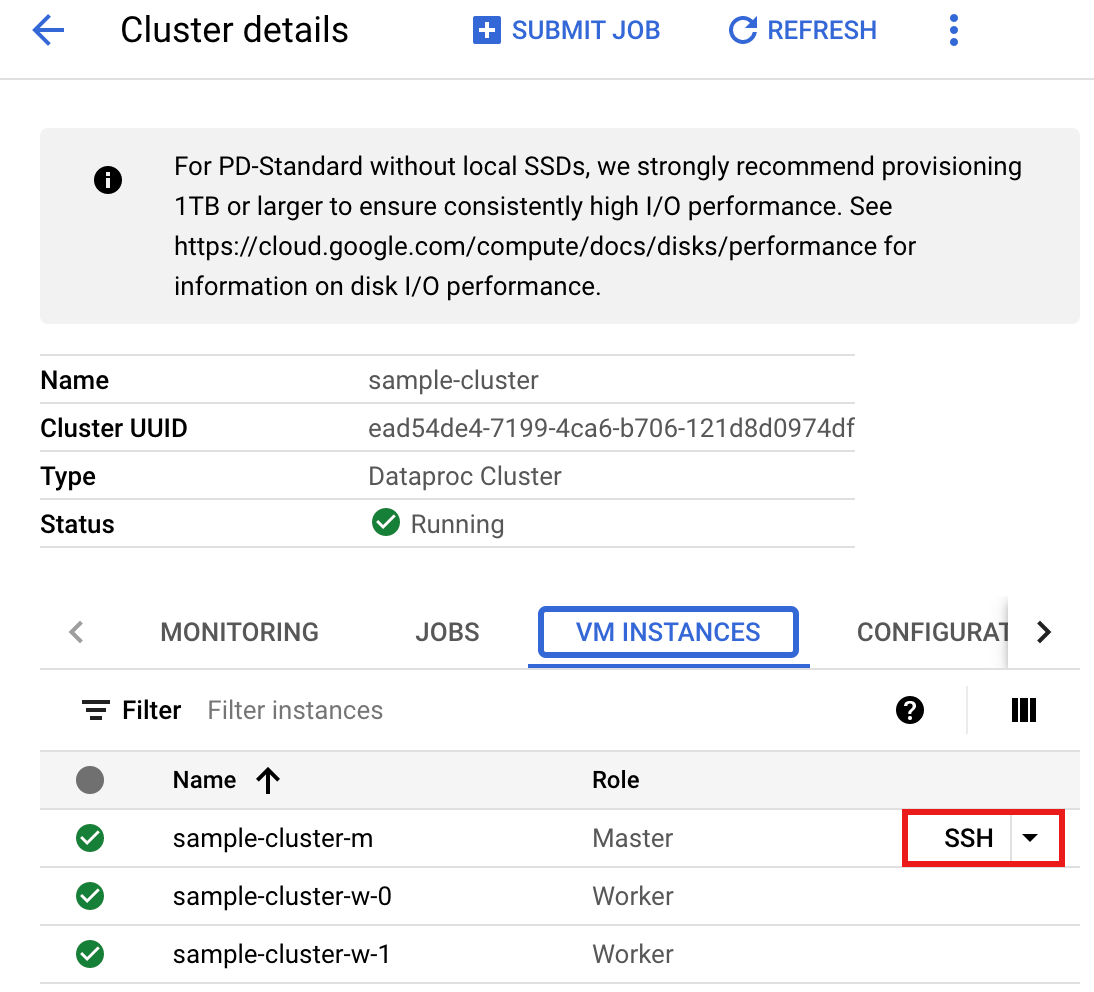
Si apre una finestra del browser nella home directory sul nodo principaleConnected, host fingerprint: ssh-rsa 2048 ... ... user@clusterName-m:~$
- Vai alla pagina
Cluster Dataproc
nella console Google Cloud, quindi fai clic sul nome del cluster
- Crea
singers.scalacon l'editor di testovi,vimonanopreinstallato, quindi incolla il codice Scala dall'elenco di codice Scalanano singers.scala
- Avvia la REPL di
spark-shell.$ spark-shell --jars=gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jar
- Esegui singers.scala con il comando
:load singers.scalaper creare la tabellaSingersdi Spanner. L'elenco di output mostra esempi dell'output di Singers.> :load singers.scala Loading singers.scala... defined object singers > singers.main() ... +--------+---------+--------+---------+-----------+ |SingerId|FirstName|LastName|BirthDate|LastUpdated| +--------+---------+--------+---------+-----------+ | 1| Marc|Richards| null| null| | 2| Catalina| Smith| null| null| | 3| Alice| Trentor| null| null| +--------+---------+--------+---------+-----------+ root |-- SingerId: long (nullable = false) |-- FirstName: string (nullable = true) |-- LastName: string (nullable = true) |-- BirthDate: date (nullable = true) |-- LastUpdated: timestamp (nullable = true)
PySpark
- Esamina il codice e sostituisci i segnaposto [projectId], [instanceId], [databaseId] e [table] con
l'ID progetto, l'ID istanza, l'ID database e la tabella che hai creato in precedenza. L'opzione enableDataBoost attiva la funzionalità Data Boost di Spanner, che ha un impatto quasi nullo sull'istanza Spanner principale.
#!/usr/bin/env python """Spanner PySpark read example.""" from pyspark.sql import SparkSession spark = SparkSession \ .builder \ .master('yarn') \ .appName('spark-spanner-demo') \ .getOrCreate() # Load data from Spanner. singers = spark.read.format('cloud-spanner') \ .option("projectId", "[projectId]") \ .option("instanceId", "[instanceId]") \ .option("databaseId", "[databaseId]") \ .option("enableDataBoost", "true") \ .option("table", "[table]") \ .load() singers.createOrReplaceTempView('Singers') # Read from Singers result = spark.sql('SELECT * FROM Singers') result.show() result.printSchema()
- Esegui il codice sul tuo cluster
- Utilizza SSH per connetterti al nodo master del cluster Dataproc.
- Vai alla pagina
Cluster Dataproc
nella console Google Cloud, quindi fai clic sul nome del cluster
- Nella pagina Dettagli cluster, seleziona la scheda Istanze VM. Quindi, fai clic su
SSHa destra del nome del nodo master del cluster
Si apre una finestra del browser nella home directory sul nodo principaleConnected, host fingerprint: ssh-rsa 2048 ... ... user@clusterName-m:~$
- Vai alla pagina
Cluster Dataproc
nella console Google Cloud, quindi fai clic sul nome del cluster
- Crea
singers.pycon l'editor di testovi,vimonanopreinstallato, quindi incolla il codice PySpark dalla lista di codice PySparknano singers.py
- Esegui singers.py con
spark-submitper creare la tabellaSingersdi Spanner.spark-submit --jars gs://spark-lib/spanner/spark-3.1-spanner-CONNECTOR_VERSION.jar singers.py
... +--------+---------+--------+---------+-----------+ |SingerId|FirstName|LastName|BirthDate|LastUpdated| +--------+---------+--------+---------+-----------+ | 1| Marc|Richards| null| null| | 2| Catalina| Smith| null| null| | 3| Alice| Trentor| null| null| +--------+---------+--------+---------+-----------+ root |-- SingerId: long (nullable = false) |-- FirstName: string (nullable = true) |-- LastName: string (nullable = true) |-- BirthDate: date (nullable = true) |-- LastUpdated: timestamp (nullable = true) only showing top 20 rows
- Utilizza SSH per connetterti al nodo master del cluster Dataproc.
Esegui la pulizia
Per eseguire la pulizia ed evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse create in questa procedura dettagliata, segui questi passaggi.
gcloud dataproc clusters stop CLUSTER_NAME gcloud dataproc clusters delete CLUSTER_NAME