Dieses Dokument bietet einen Überblick über Pipelines für verwaltete Verbindungen, über die Sie Metadaten aus Drittanbieterquellen in Dataplex Universal Catalog importieren können.
Über verwaltete Verbindungen können Sie Metadaten in großem Umfang in Dataplex Universal Catalog importieren. Eine Pipeline für verwaltete Verbindungen extrahiert Metadaten aus Ihren Datenquellen und importiert sie dann in Dataplex Universal Catalog. Bei Bedarf werden mit der Pipeline auch Dataplex Universal Catalog-Eintragsgruppen in IhremGoogle Cloud -Projekt erstellt. Sie können die Workflows orchestrieren und die Importjobs nach Bedarf planen.
Sie erstellen Ihre eigenen benutzerdefinierten Connectors, um Metadaten aus Drittanbieterquellen zu extrahieren. Sie können beispielsweise einen Connector erstellen, um Metadaten aus Quellen wie MySQL, SQL Server, Oracle, Snowflake und Databricks zu extrahieren. Eine Anleitung zum Erstellen eines benutzerdefinierten Connectors finden Sie unter Benutzerdefinierten Connector für den Metadatenimport entwickeln. Sie können auch die von der Community erstellten benutzerdefinierten Connectors verwenden, die für eine Vielzahl von Drittanbieterquellen verfügbar sind.
Eine Anleitung zum Ausführen einer Pipeline für verwaltete Verbindungen finden Sie unter Metadaten mithilfe von Workflows aus einer benutzerdefinierten Quelle importieren.
So funktionieren verwaltete Verbindungen
Das folgende Diagramm zeigt eine Pipeline für verwaltete Verbindungen.
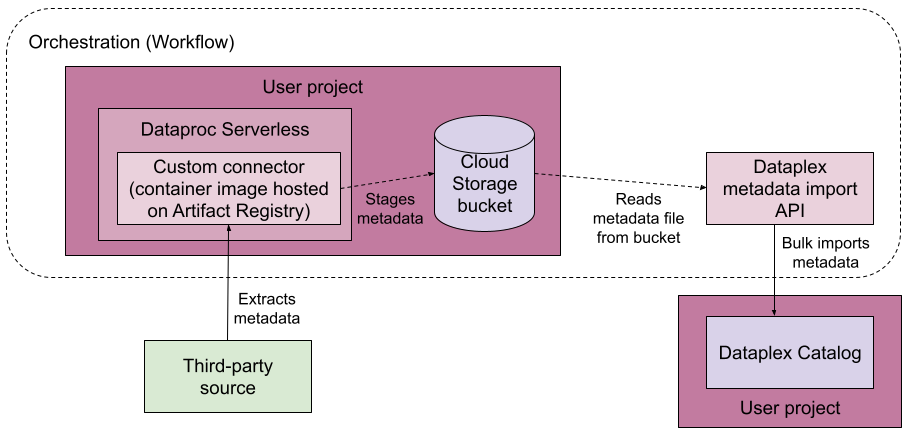
So funktionieren verwaltete Verbindungen:
Sie erstellen einen Connector für Ihre Datenquelle.
Der Connector muss ein Artifact Registry-Image sein, das auf Dataproc Serverless ausgeführt werden kann.
Sie führen die Pipeline für verwaltete Verbindungen auf der Orchestrierungsplattform Workflows aus.
Die Pipeline für verwaltete Verbindungen erledigt diese Aufgaben:
- Sie erstellt anhand Ihrer Konfiguration eine Zieleintragsgruppe, sofern diese noch nicht vorhanden ist.
- Sie führt den Connector aus. Der Connector extrahiert die Metadaten aus Ihrer Datenquelle und generiert eine Metadaten-Importdatei, die in Dataplex Universal Catalog importiert werden kann.
- Sie überwacht den Fortschritt der Metadatenextraktion.
- Sie führt einen Metadatenimportjob aus, um die Metadaten in Dataplex Universal Catalog zu importieren.
- Sie überwacht den Fortschritt des Metadatenimportjobs.
Die Pipeline für verwaltete Verbindungen nutzt Dataproc Serverless, um den Connector auszuführen, und die API-Methoden von Dataplex Universal Catalog für den Metadatenimport, um den Metadatenimportjob auszuführen.
Die Metadaten, die Sie importieren, bestehen aus Dataplex Universal Catalog-Einträgen und ihren Aspekten. Weitere Informationen zu Dataplex Universal Catalog-Metadaten finden Sie unter Data Catalog-Verwaltung im Dataplex Universal Catalog.
Von der Community erstellte benutzerdefinierte Connectors
Zum Importieren von Metadaten aus Drittanbieterquellen können Sie benutzerdefinierte Connectors verwenden, die von der Community erstellt wurden. Eine Einrichtungsanleitung und weitere Informationen zum Connector finden Sie in der README-Datei des jeweiligen Connectors.
| Datenquelle | Repository |
|---|---|
| MySQL | mysql-connector |
| Oracle | oracle-connector |
| PostgreSQL | postgresql-connector |
| Snowflake | snowflake-connector |
| SQL Server | sql-server-connector |
Nächste Schritte
- Metadaten mithilfe von Workflows aus einer benutzerdefinierten Quelle importieren
- Benutzerdefinierten Connector für den Metadatenimport entwickeln
- Metadaten mit einer benutzerdefinierten Pipeline importieren