Mit Sammlungen den Überblick behalten
Sie können Inhalte basierend auf Ihren Einstellungen speichern und kategorisieren.
Mit Dataplex Universal Catalog-Datenqualitätsaufgaben können Sie Datenqualitätsprüfungen für Tabellen in BigQuery und Cloud Storage definieren und ausführen. Mit Dataplex Universal Catalog-Datenqualitätsaufgaben können Sie auch regelmäßige Datenkontrollen in BigQuery-Umgebungen anwenden.
Zeitpunkt der Erstellung von Datenqualitätsaufgaben in Dataplex Universal Catalog
Dataplex Universal Catalog-Datenqualitätsaufgaben können Ihnen bei Folgendem helfen:
Validieren Sie Daten als Teil einer Datenproduktionspipeline.
Überprüfen Sie regelmäßig die Qualität der Datasets im Hinblick auf Ihre Erwartungen.
Erstellen Sie Datenqualitätsberichte für rechtliche Anforderungen.
Vorteile
Anpassbare Spezifikationen. Sie können die hochflexible YAML-Syntax zum Deklarieren von Datenqualitätsregeln verwenden.
Serverlose Implementierung. Dataplex Universal Catalog erfordert keine Infrastruktureinrichtung.
Nullkopie und automatischer Push-down. YAML-Prüfungen werden in SQL konvertiert und an BigQuery übertragen, sodass keine Datenkopie entsteht.
Planbare Prüfungen der Datenqualität. Sie können Datenqualitätsprüfungen über den serverlosen Planer in Dataplex Universal Catalog planen oder die Dataplex API über externe Planer wie Cloud Composer für die Pipelineintegration verwenden.
Verwaltete Erfahrung. Dataplex Universal Catalog verwendet eine Open-Source-Datenqualitäts-Engine, CloudDQ, um Datenqualitätsprüfungen auszuführen. Dataplex Universal Catalog bietet jedoch eine nahtlos verwaltete Lösung für die Durchführung Ihrer Datenqualitätsprüfungen.
Funktionsweise von Datenqualitätsaufgaben
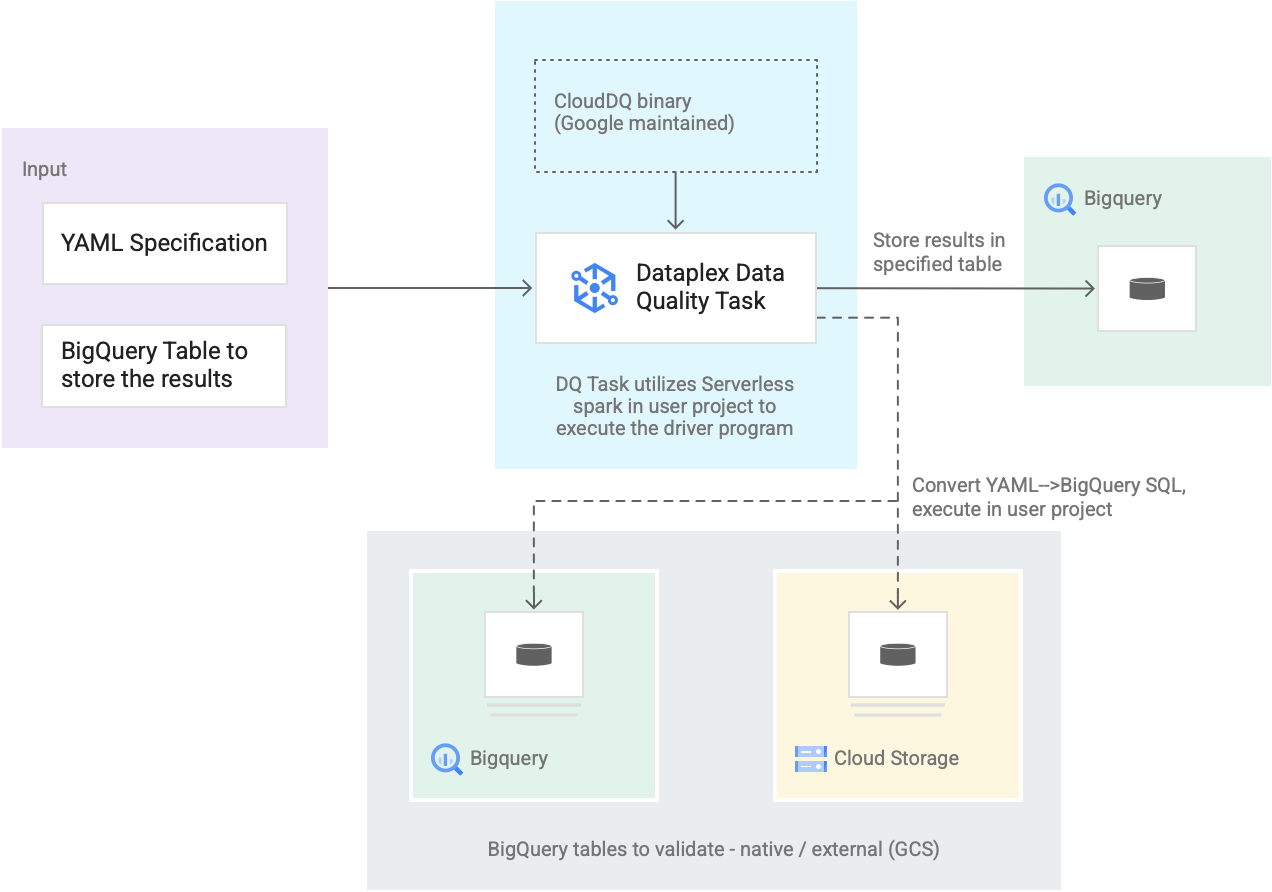
Das folgende Diagramm zeigt, wie Datenqualitätsaufgaben in Dataplex Universal Catalog funktionieren:
Eingabe von Nutzern
YAML-Spezifikation: Eine oder mehrere YAML-Dateien, die Regeln zur Datenqualität anhand der Spezifikationssyntax definieren. Sie speichern die YAML-Dateien in einem Cloud Storage-Bucket in Ihrem Projekt. Nutzer können mehrere Regeln gleichzeitig ausführen. Diese Regeln können auf verschiedene BigQuery-Tabellen angewendet werden, einschließlich Tabellen in verschiedenen Datasets oder Google Cloud-Projekten. Die Spezifikation unterstützt inkrementelle Ausführungen nur für die Validierung neuer Daten. Informationen zum Erstellen einer YAML-Spezifikation finden Sie unter Spezifikationsdatei erstellen.
BigQuery-Ergebnistabelle: Eine benutzerdefinierte Tabelle, in der die Ergebnisse der Datenqualitätsvalidierung gespeichert werden. Das Google Cloud -Projekt, in dem sich diese Tabelle befindet, kann ein anderes Projekt sein als das Projekt, in dem die Dataplex Universal Catalog-Datenqualitätsaufgabe verwendet wird.
Zu validierende Tabellen
Innerhalb der YAML-Spezifikation müssen Sie angeben, welche Tabellen Sie für welche Regeln validieren möchten. Dies wird auch als Regelbindung bezeichnet. Die Tabellen können native BigQuery-Tabellen oder externe BigQuery-Tabellen in Cloud Storage sein. Mit der YAML-Spezifikation können Sie Tabellen innerhalb oder außerhalb einer Dataplex Universal Catalog-Zone angeben.
BigQuery- und Cloud Storage-Tabellen, die in einer einzelnen Ausführung validiert werden, können zu verschiedenen Projekten gehören.
Dataplex Universal Catalog-Datenqualitätsaufgabe: Eine Dataplex Universal Catalog-Datenqualitätsaufgabe wird mit einer vordefinierten, verwalteten CloudDQ-PySpark-Binärdatei konfiguriert und verwendet die YAML-Spezifikation und die BigQuery-Ergebnistabelle als Eingabe. Ähnlich wie andere Dataplex Universal Catalog-Aufgaben wird die Dataplex Universal Catalog-Datenqualitätsaufgabe in einer serverlosen Spark-Umgebung ausgeführt, konvertiert die YAML-Spezifikation in BigQuery-Abfragen und führt diese Abfragen dann auf den Tabellen aus, die in der Spezifikationsdatei definiert sind.
Preise
Beim Ausführen von Datenqualitätsaufgaben in Dataplex Universal Catalog werden Ihnen die Nutzung von BigQuery und Dataproc Serverless (Batches) in Rechnung gestellt.
Die Dataplex Universal Catalog-Datenqualitätsaufgabe konvertiert die Spezifikationsdatei in BigQuery-Abfragen und führt sie im Nutzerprojekt aus. Siehe BigQuery-Preise.
Für die Verwendung von Dataplex Universal Catalog zum Organisieren von Daten oder die Verwendung des serverlosen Planers in Dataplex Universal Catalog zum Planen von Datenqualitätsprüfungen fallen keine Gebühren an. Dataplex Universal Catalog-Preise
[[["Leicht verständlich","easyToUnderstand","thumb-up"],["Mein Problem wurde gelöst","solvedMyProblem","thumb-up"],["Sonstiges","otherUp","thumb-up"]],[["Schwer verständlich","hardToUnderstand","thumb-down"],["Informationen oder Beispielcode falsch","incorrectInformationOrSampleCode","thumb-down"],["Benötigte Informationen/Beispiele nicht gefunden","missingTheInformationSamplesINeed","thumb-down"],["Problem mit der Übersetzung","translationIssue","thumb-down"],["Sonstiges","otherDown","thumb-down"]],["Zuletzt aktualisiert: 2025-09-05 (UTC)."],[[["\u003cp\u003eDataplex data quality tasks enable users to define and execute data quality checks on tables in BigQuery and Cloud Storage, also allowing for the implementation of regular data controls in BigQuery environments.\u003c/p\u003e\n"],["\u003cp\u003eThese tasks offer benefits such as customizable rule specifications using YAML syntax, a serverless implementation, zero-copy and automatic pushdown for efficiency, and the ability to schedule checks.\u003c/p\u003e\n"],["\u003cp\u003eThe tasks use a YAML specification to define data quality rules and can validate tables both inside and outside of Dataplex zones, as well as across different projects.\u003c/p\u003e\n"],["\u003cp\u003eUsers can store validation results in a specified BigQuery table, which can be in a different project than the one where the Dataplex task runs.\u003c/p\u003e\n"],["\u003cp\u003eDataplex uses the open source CloudDQ for data quality checks, though users are provided a managed experience, and cost is based on BigQuery and Dataproc Serverless (Batches) usage.\u003c/p\u003e\n"]]],[],null,["# Data quality tasks overview\n\n| **Caution:** Dataplex Universal Catalog data quality tasks is a legacy offering based on open source software. We recommend that you start using the latest built-in [Automatic data quality](/dataplex/docs/auto-data-quality-overview) offering.\n\nDataplex Universal Catalog data quality tasks let you define and run\ndata quality checks across tables in BigQuery and\nCloud Storage. Dataplex Universal Catalog data quality tasks also let you\napply regular data controls in BigQuery environments.\n\nWhen to create Dataplex Universal Catalog data quality tasks\n------------------------------------------------------------\n\nDataplex Universal Catalog data quality tasks can help you with the following:\n\n- Validate data as part of a data production pipeline.\n- Routinely monitor the quality of datasets against your expectations.\n- Build data quality reports for regulatory requirements.\n\nBenefits\n--------\n\n- **Customizable specifications.** You can use the highly flexible YAML syntax to declare your data quality rules.\n- **Serverless implementation.** Dataplex Universal Catalog does not need any infrastructure setup.\n- **Zero-copy and automatic pushdown.** YAML checks are converted to SQL and pushed down to BigQuery, resulting in no data copy.\n- **Schedulable data quality checks.** You can schedule data quality checks through the serverless scheduler in Dataplex Universal Catalog, or use the Dataplex API through external schedulers like Cloud Composer for pipeline integration.\n- **Managed experience.** Dataplex Universal Catalog uses an open source data quality engine, [CloudDQ](https://github.com/GoogleCloudPlatform/cloud-data-quality), to run data quality checks. However, Dataplex Universal Catalog provides a seamless managed experience for performing your data quality checks.\n\nHow data quality tasks work\n---------------------------\n\nThe following diagram shows how Dataplex Universal Catalog data quality tasks work:\n\n- **Input from users**\n - **YAML specification** : A set of one or more YAML files that define data quality rules based on the specification syntax. You store the YAML files in a Cloud Storage bucket in your project. Users can run multiple rules simultaneously, and those rules can be applied to different BigQuery tables, including tables across different datasets or Google Cloud projects. The specification supports incremental runs for only validating new data. To create a YAML specification, see [Create a specification file](/dataplex/docs/check-data-quality#create-a-specification-file).\n - **BigQuery result table**: A user-specified table where the data quality validation results are stored. The Google Cloud project in which this table resides can be a different project than the one in which the Dataplex Universal Catalog data quality task is used.\n- **Tables to validate**\n - Within the YAML specification, you need to specify which tables you want to validate for which rules, also known as a *rule binding*. The tables can be BigQuery native tables or BigQuery external tables in Cloud Storage. The YAML specification lets you specify tables inside or outside a Dataplex Universal Catalog zone.\n - BigQuery and Cloud Storage tables that are validated in a single run can belong to different projects.\n- **Dataplex Universal Catalog data quality task** : A Dataplex Universal Catalog data quality task is configured with a prebuilt, maintained CloudDQ PySpark binary and takes the YAML specification and BigQuery result table as the input. Similar to other [Dataplex Universal Catalog tasks](/dataplex/docs/schedule-custom-spark-tasks), the Dataplex Universal Catalog data quality task runs on a serverless Spark environment, converts the YAML specification to BigQuery queries, and then runs those queries on the tables that are defined in the specification file.\n\nPricing\n-------\n\nWhen you run Dataplex Universal Catalog data quality tasks, you are charged for\nBigQuery and Dataproc Serverless (Batches) usage.\n\n- The Dataplex Universal Catalog data quality task converts the specification file\n to BigQuery queries and runs them in the user project. See\n [BigQuery pricing](/bigquery/pricing).\n\n- Dataplex Universal Catalog uses Spark to run the prebuilt, Google-maintained [open source CloudDQ](https://github.com/GoogleCloudPlatform/cloud-data-quality)\n driver program to convert user specification to BigQuery\n queries. See [Dataproc Serverless pricing](/dataproc-serverless/pricing).\n\nThere are no charges for using Dataplex Universal Catalog to organize data or using the serverless\nscheduler in Dataplex Universal Catalog to schedule data quality checks. See\n[Dataplex Universal Catalog pricing](/dataplex/pricing).\n\nWhat's next\n-----------\n\n- [Create Dataplex Universal Catalog data quality checks](/dataplex/docs/check-data-quality)."]]