Halaman ini menjelaskan alasan dan cara menggunakan fitur
MLTransform
untuk menyiapkan data Anda dalam melatih model machine learning (ML). Dengan menggabungkan beberapa transformasi pemrosesan data dalam satu class, MLTransform menyederhanakan proses penerapan operasi pemrosesan data ML Apache Beam ke alur kerja Anda.
Untuk mengetahui informasi tentang penggunaan MLTransform untuk tugas pembuatan embedding, lihat Membuat embedding dengan MLTransform.
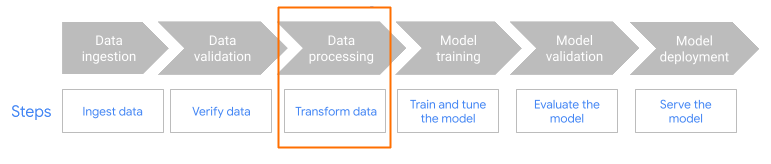
MLTransform dalam langkah praproses alur kerja.
Manfaat
Class MLTransform memberikan manfaat berikut:
- Transformasikan data Anda tanpa perlu menulis kode yang kompleks atau mengelola library yang mendasarinya.
- Rangkai beberapa jenis operasi pemrosesan secara efisien dengan satu antarmuka.
Buat embedding yang dapat Anda gunakan untuk mengirim data ke database vektor atau untuk menjalankan inferensi.
Untuk mengetahui informasi selengkapnya tentang pembuatan embedding, lihat Membuat embedding dengan MLTransform.
Dukungan dan batasan
Class MLTransform memiliki batasan berikut:
- Tersedia untuk pipeline yang menggunakan Apache Beam Python SDK versi 2.53.0 dan yang lebih baru.
- Pipeline harus menggunakan jendela default.
Transformasi pemrosesan data yang menggunakan TFT:
- Mendukung Python 3.9, 3.10, 3.11.
- Mendukung pipeline batch.
Kasus penggunaan
Notebook contoh menunjukkan cara menggunakan MLTransform untuk kasus penggunaan khusus penyematan.
- Saya ingin menghitung kosakata dari set data
- Menghitung kosakata unik dari set data, lalu memetakan setiap kata atau token ke indeks bilangan bulat yang berbeda. Gunakan transformasi ini untuk mengubah data tekstual menjadi representasi numerik untuk tugas machine learning.
- Saya ingin menskalakan data saya untuk melatih model ML saya
- Menskalakan data agar Anda dapat menggunakannya untuk melatih model ML. Class
Apache Beam
MLTransformmencakup beberapa transformasi penskalaan data.
Untuk mengetahui daftar lengkap transformasi yang tersedia, lihat Transformasi dalam dokumentasi Apache Beam.
Menggunakan MLTransform
Untuk menggunakan class MLTransform guna memproses data, sertakan kode berikut dalam pipeline Anda:
import apache_beam as beam
from apache_beam.ml.transforms.base import MLTransform
from apache_beam.ml.transforms.tft import TRANSFORM_NAME
import tempfile
data = [
{
DATA
},
]
artifact_location = gs://BUCKET_NAME
TRANSFORM_FUNCTION_NAME = TRANSFORM_NAME(columns=['x'])
with beam.Pipeline() as p:
transformed_data = (
p
| beam.Create(data)
| MLTransform(write_artifact_location=artifact_location).with_transform(
TRANSFORM_FUNCTION_NAME)
| beam.Map(print))
Ganti nilai berikut:
TRANSFORM_NAME: nama transformasi yang akan digunakanBCUKET_NAME: nama bucket Cloud Storage AndaDATA: data input yang akan ditransformasiTRANSFORM_FUNCTION_NAME: nama yang Anda tetapkan ke fungsi transformasi dalam kode Anda
Langkah berikutnya
- Untuk mengetahui detail selengkapnya tentang
MLTransform, lihat Memproses data dalam dokumentasi Apache Beam. - Untuk contoh lainnya, lihat
MLTransformuntuk pemrosesan data di katalog transformasi Apache Beam. - Jalankan notebook interaktif di Colab.