This page explains why and how to use the MLTransform feature to prepare
your data for training machine learning (ML) models. Specifically, this page
shows you how to process data by generating embeddings using MLTransform.
By
combining multiple data processing transforms in one class, MLTransform
streamlines the process of applying Apache Beam ML data processing
operations to your workflow.
MLTransform in the preprocessing step of the workflow.
Embeddings overview
Embeddings are essential for modern semantic search and Retrieval Augmented Generation (RAG) applications. Embeddings let systems understand and interact with information on a deeper, more conceptual level. In semantic search, embeddings transform queries and documents into vector representations. These representations capture their underlying meaning and relationships. Consequently, this lets you find relevant results even when keywords don't directly match. This is a significant leap beyond standard keyword-based search. You can also use embeddings for product recommendations. This includes multimodal searches that use images and text, log analytics, and for tasks such as deduplication.
Within RAG, embeddings play a crucial role in retrieving the most relevant context from a knowledge base to ground the responses of large language models (LLMs). By embedding both the user's query and the chunks of information in the knowledge base, RAG systems can efficiently identify and retrieve the most semantically similar pieces. This semantic matching ensures that the LLM has access to the necessary information to generate accurate and informative answers.
Ingest and process data for embeddings
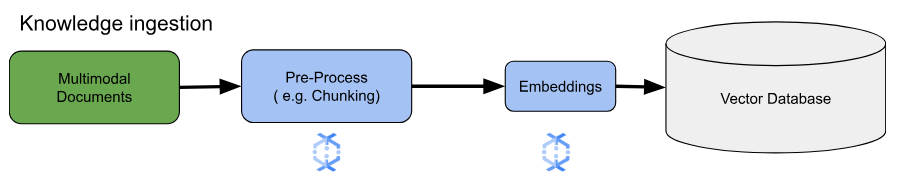
For core embedding use cases, the key consideration is how to ingest and process knowledge. This ingestion can be either in a batch or streaming manner. The source of this knowledge can vary widely. For example, this information can come from files stored in Cloud Storage, or can come from streaming sources like Pub/Sub or Google Cloud Managed Service for Apache Kafka.
For streaming sources, the data itself might be the raw content (for example, plain text) or URIs pointing to documents. Regardless of the source, the first stage typically involves preprocessing the information. For raw text, this might be minimal, such as basic data cleaning. However, for larger documents or more complex content, a crucial step is chunking. Chunking involves breaking down the source material into smaller, manageable units. The optimal chunking strategy isn't standardized and depends on the specific data and application. Platforms like Dataflow offer built-in capabilities to handle diverse chunking needs, simplifying this essential preprocessing stage.
Benefits
The MLTransform class provides the following benefits:
- Generate embeddings that you can use to push data into vector databases or to run inference.
- Transform your data without writing complex code or managing underlying libraries.
- Efficiently chain multiple types of processing operations with one interface.
Support and limitations
The MLTransform class has the following limitations:
- Available for pipelines that use the Apache Beam Python SDK versions 2.53.0 and later.
- Pipelines must use default windows.
Text embedding transforms:
- Support Python 3.8, 3.9, 3.10, 3.11, and 3.12.
- Support both batch and streaming pipelines.
- Support the Vertex AI text-embeddings API and the Hugging Face Sentence Transformers module.
Use cases
The example notebooks demonstrate how to use MLTransform for specific use
cases.
- I want to generate text embeddings for my LLM by using Vertex AI
- Use the Apache Beam
MLTransformclass with the Vertex AI text-embeddings API to generate text embeddings. Text embeddings are a way to represent text as numerical vectors, which is necessary for many natural language processing (NLP) tasks. - I want to generate text embeddings for my LLM by using Hugging Face
- Use the Apache Beam
MLTransformclass with Hugging Face Hub models to generate text embeddings. The Hugging FaceSentenceTransformersframework uses Python to generate sentence, text, and image embeddings. - I want to generate text embeddings and ingest them into AlloyDB for PostgreSQL
- Use Apache Beam, specifically its
MLTransformclass with Hugging Face Hub models to generate text embeddings. Then, use theVectorDatabaseWriteTransformto load these embeddings and associated metadata into AlloyDB for PostgreSQL. This notebook demonstrates building scalable batch and streaming Beam data pipelines for populating an AlloyDB for PostgreSQL vector database. This includes handling data from various sources like Pub/Sub or existing database tables, making custom schemas, and updating data. - I want to generate text embeddings and ingest them into BigQuery
- Use the Apache Beam
MLTransformclass with Hugging Face Hub models to generate text embeddings from application data, such as a product catalog. The Apache BeamHuggingfaceTextEmbeddingstransform is used for this. This transform uses the Hugging Face SentenceTransformers framework, which provides models for generating sentence and text embeddings. These generated embeddings and their metadata are then ingested into BigQuery using the Apache BeamVectorDatabaseWriteTransform. The notebook further demonstrates vector similarity searches in BigQuery using the Enrichment transform.
For a full list of available transforms, see Transforms in the Apache Beam documentation.
Use MLTransform for embedding generation
To use the MLTransform class to chunk information and generate embeddings,
include the following code in your pipeline:
def create_chunk(product: Dict[str, Any]) -> Chunk:
return Chunk(
content=Content(
text=f"{product['name']}: {product['description']}"
),
id=product['id'], # Use product ID as chunk ID
metadata=product, # Store all product info in metadata
)
[...]
with beam.Pipeline() as p:
_ = (
p
| 'Create Products' >> beam.Create(products)
| 'Convert to Chunks' >> beam.Map(create_chunk)
| 'Generate Embeddings' >> MLTransform(
write_artifact_location=tempfile.mkdtemp())
.with_transform(huggingface_embedder)
| 'Write to AlloyDB' >> VectorDatabaseWriteTransform(alloydb_config)
)
The previous example creates a single chunk per element, but you can also use LangChain for to create chunks instead:
splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=20)
provider = beam.ml.rag.chunking.langchain.LangChainChunker(
document_field='content', metadata_fields=[], text_splitter=splitter)
with beam.Pipeline() as p:
_ = (
p
| 'Create Products' >> beam.io.textio.ReadFromText(products)
| 'Convert to Chunks' >> provider.get_ptransform_for_processing()
What's next
- Read the blog post "How to enable real time semantic search and RAG applications with Dataflow ML".
- For more details about
MLTransform, see Preprocess data in the Apache Beam documentation. - For more examples, see
MLTransformfor data processing in the Apache Beam transform catalog. - Run an interactive notebook in Colab.