JupyterLab ノートブックと Apache Beam インタラクティブ ランナーを使用すると、REPL(Read-Eval-Print Loop)ワークフローで、パイプラインを反復的に開発し、パイプライン グラフを検査し、個々の PCollection を解析できます。JupyterLab ノートブックで Apache Beam インタラクティブ ランナーを使用する方法を示すチュートリアルについては、Apache Beam ノートブックでの開発をご覧ください。
このページでは、Apache Beam ノートブックで使用できる高度な機能について詳しく説明します。
ノートブック管理のクラスタ上のインタラクティブな FlinkRunner
ノートブックから本番環境サイズのデータをインタラクティブに操作するには、いくつかの汎用的なパイプライン オプションとともに FlinkRunner を使用することで、ノートブック セッションに対して長期的な Dataproc クラスタを管理し、Apache Beam パイプラインを分散して実行するように指示できます。
前提条件
この機能を使用するには:
- Dataproc API を有効にします。
- Dataproc のノートブック インスタンスを実行するサービス アカウントに管理者または編集者のロールを付与します。
- Apache Beam SDK バージョン 2.40.0 以降を含むノートブック カーネルを使用します。
構成
少なくとも次の設定が必要になります。
# Set a Cloud Storage bucket to cache source recording and PCollections.
# By default, the cache is on the notebook instance itself, but that does not
# apply to the distributed execution scenario.
ib.options.cache_root = 'gs://<BUCKET_NAME>/flink'
# Define an InteractiveRunner that uses the FlinkRunner under the hood.
interactive_flink_runner = InteractiveRunner(underlying_runner=FlinkRunner())
options = PipelineOptions()
# Instruct the notebook that Google Cloud is used to run the FlinkRunner.
cloud_options = options.view_as(GoogleCloudOptions)
cloud_options.project = 'PROJECT_ID'
明示的なプロビジョニング(省略可)
次のオプションを追加できます。
# Change this if the pipeline needs to run in a different region
# than the default, 'us-central1'. For example, to set it to 'us-west1':
cloud_options.region = 'us-west1'
# Explicitly provision the notebook-managed cluster.
worker_options = options.view_as(WorkerOptions)
# Provision 40 workers to run the pipeline.
worker_options.num_workers=40
# Use the default subnetwork.
worker_options.subnetwork='default'
# Choose the machine type for the workers.
worker_options.machine_type='n1-highmem-8'
# When working with non-official Apache Beam releases, such as Apache Beam built from source
# code, configure the environment to use a compatible released SDK container.
# If needed, build a custom container and use it. For more information, see:
# https://beam.apache.org/documentation/runtime/environments/
options.view_as(PortableOptions).environment_config = 'apache/beam_python3.7_sdk:2.41.0 or LOCATION.pkg.dev/PROJECT_ID/REPOSITORY/your_custom_container'
使用方法
# The parallelism is applied to each step, so if your pipeline has 10 steps, you
# end up having 10 * 10 = 100 tasks scheduled, which can be run in parallel.
options.view_as(FlinkRunnerOptions).parallelism = 10
p_word_count = beam.Pipeline(interactive_flink_runner, options=options)
word_counts = (
p_word_count
| 'read' >> ReadWordsFromText('gs://apache-beam-samples/shakespeare/kinglear.txt')
| 'count' >> beam.combiners.Count.PerElement())
# The notebook session automatically starts and manages a cluster to run
# your pipelines with the FlinkRunner.
ib.show(word_counts)
# Interactively adjust the parallelism.
options.view_as(FlinkRunnerOptions).parallelism = 150
# The BigQuery read needs a Cloud Storage bucket as a temporary location.
options.view_as(GoogleCloudOptions).temp_location = ib.options.cache_root
p_bq = beam.Pipeline(runner=interactive_flink_runner, options=options)
delays_by_airline = (
p_bq
| 'Read Dataset from BigQuery' >> beam.io.ReadFromBigQuery(
project=project, use_standard_sql=True,
query=('SELECT airline, arrival_delay '
'FROM `bigquery-samples.airline_ontime_data.flights` '
'WHERE date >= "2010-01-01"'))
| 'Rebalance Data to TM Slots' >> beam.Reshuffle(num_buckets=1000)
| 'Extract Delay Info' >> beam.Map(
lambda e: (e['airline'], e['arrival_delay'] > 0))
| 'Filter Delayed' >> beam.Filter(lambda e: e[1])
| 'Count Delayed Flights Per Airline' >> beam.combiners.Count.PerKey())
# This step reuses the existing cluster.
ib.collect(delays_by_airline)
# Describe the cluster running the pipelines.
# You can access the Flink dashboard from the printed link.
ib.clusters.describe()
# Cleans up all long-lasting clusters managed by the notebook session.
ib.clusters.cleanup(force=True)
ノートブック管理のクラスタ
- パイプライン オプションを指定しない場合、デフォルトでは、インタラクティブな Apache Beam は最後に使用されたクラスタを再利用して、
FlinkRunnerでパイプラインを実行します。- この動作は回避できます。たとえば、ノートブックにホストされていない FlinkRunner を使用して同じノートブック セッションで別のパイプラインを実行するには、
ib.clusters.set_default_cluster(None)を実行します。
- この動作は回避できます。たとえば、ノートブックにホストされていない FlinkRunner を使用して同じノートブック セッションで別のパイプラインを実行するには、
- 既存の Dataproc クラスタにマッピングされたプロジェクト、リージョン、プロビジョニング構成を使用する新しいパイプラインをインスタンス化する場合、Dataflow はクラスタを再利用します(直近に使用されたクラスタが使用されない可能性もあります)。
- ただし、プロビジョニングの変更(クラスタのサイズ変更など)が行われるたびに、必要な変更を有効にするために新しいクラスタが作成されます。クラスタのサイズを変更する場合は、クラウド リソースが枯渇しないように、
ib.clusters.cleanup(pipeline)を使用して不要なクラスタをクリーンアップします。 - Flink
master_urlが指定されていて、これがノートブック セッションによって管理されているクラスタに属している場合、Dataflow はマネージド クラスタを再利用します。master_urlがノートブック セッションで不明な場合、ユーザーのセルフホスト型のFlinkRunnerが必要であることを意味します。ノートブックは明示的な指示がない限り何も実行しません。
トラブルシューティング
このセクションでは、ノートブック管理のクラスタで使用するインタラクティブ FlinkRunner のトラブルシューティングとデバッグに役立つ情報を提供します。
Flink IOException: ネットワーク バッファの数が不足している
わかりやすくするために、Flink ネットワーク バッファ構成は公開されていません。
ジョブグラフが複雑すぎたり、並列処理の設定が高すぎると、並列処理によりステップのカーディナリティが大きくなりすぎるため、並行してスケジュールされるタスクが多くなり、実行に失敗する場合があります。
インタラクティブな実行速度を向上させるには、次のヒントを参考にしてください。
- 検査する
PCollectionだけを変数に割り当てる。 PCollectionsを 1 つずつ検査する。- 高ファンアウト変換後にリシャッフルを使用する。
- データサイズに基づいて並列処理を調整する(小さいほど高速になる場合があります)。
データの検査に時間がかかりすぎる
Flink ダッシュボードで、実行中のジョブを確認します。処理中のデータは単一のマシン上に存在し、シャッフルされないため、数百のタスクが完了して 1 つだけタスクが残っているステップが表示されることがあります。
次のような高度なファンアウト変換の後に必ず再シャッフルを使用してください。
- ファイルから行を読み取る
- BigQuery テーブルから行を読み取る
再シャッフルを行わないと、ファンアウト データは常に同じワーカーで実行され、並列処理を利用できません。
ワーカーの数はどのくらい必要か
原則として、Flink クラスタには vCPU の数にワーカー スロット数を掛けた値が割り当てられます。たとえば、40 個の n1-highmem-8 ワーカーがある場合、Flink クラスタは最大 320 個のスロット(8 × 40)になります。
ワーカーは、何千ものタスクを並列にスケジュールする数百の並列処理を読み取り、マッピング、結合を行うジョブを管理できます。
ストリーミングへの対応
ストリーミング パイプラインは現在、ノートブック管理クラスタでのインタラクティブな Flink と互換性がありません。
Beam SQL と beam_sql マジック
Beam SQL では、SQL ステートメントを使用して、制限付きと制限なしの PCollections をクエリできます。Apache Beam ノートブックで作業している場合は、IPython カスタム マジック beam_sql を使用して、パイプラインの開発を高速化できます。
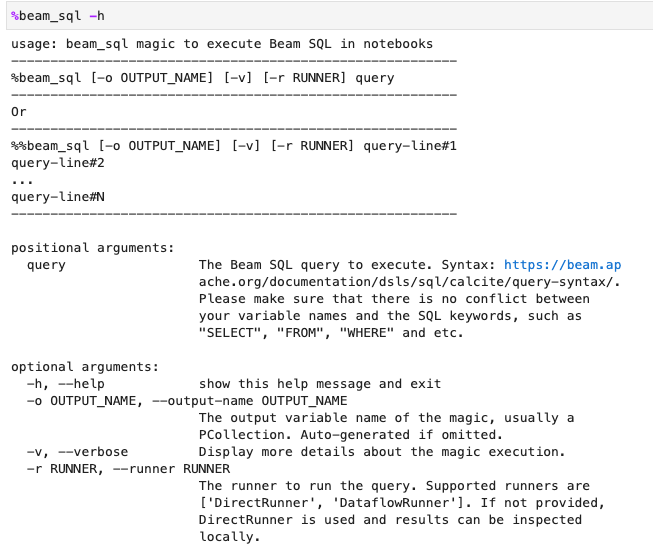
-h または --help オプションを使用して、beam_sql マジックの使用方法を確認できます。
定数値から PCollection を作成できます。

複数の PCollections を結合できます。

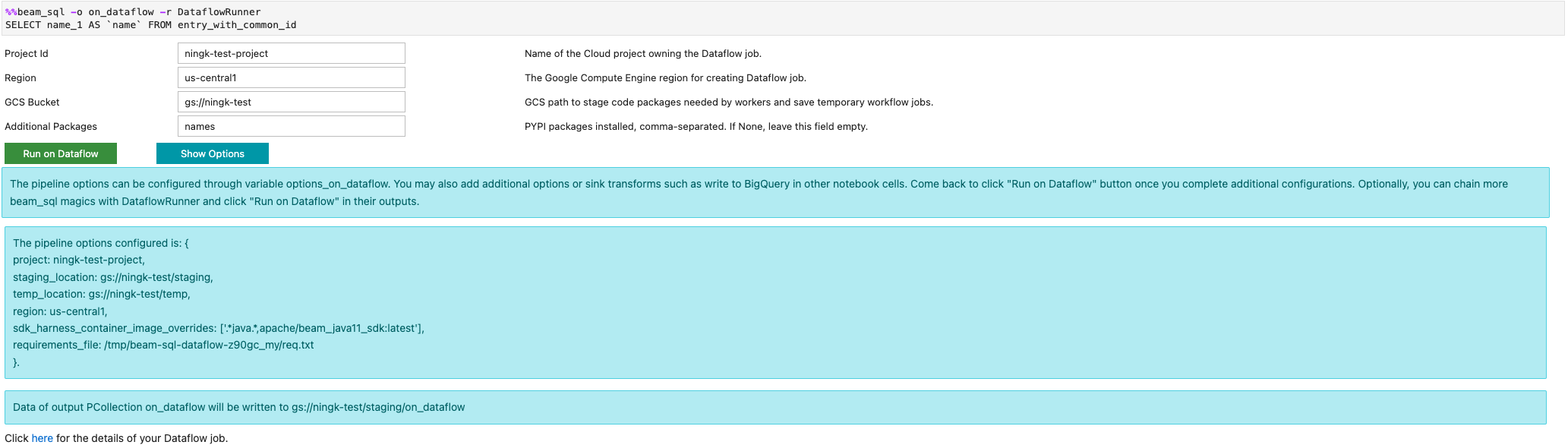
-r DataflowRunner または --runner DataflowRunner オプションを指定して Dataflow ジョブを起動できます。
詳細については、ノートブックの Apache Beam SQL のサンプル ノートブックをご覧ください。
JIT コンパイラと GPU を使用して高速化する
numba や GPU などのライブラリを使用して、Python コードと Apache Beam パイプラインを高速化できます。nvidia-tesla-t4 GPU を使用して作成した Apache Beam ノートブック インスタンスで GPU を実行するには、numba.cuda.jit を使用して Python コードをコンパイルします。必要に応じて、CPU での実行を高速化するために、numba.jit または numba.njit を使用して Python コードをマシンコードにコンパイルします。
次の例では、GPU で処理する DoFn を作成します。
class Sampler(beam.DoFn):
def __init__(self, blocks=80, threads_per_block=64):
# Uses only 1 cuda grid with below config.
self.blocks = blocks
self.threads_per_block = threads_per_block
def setup(self):
import numpy as np
# An array on host as the prototype of arrays on GPU to
# hold accumulated sub count of points in the circle.
self.h_acc = np.zeros(
self.threads_per_block * self.blocks, dtype=np.float32)
def process(self, element: Tuple[int, int]):
from numba import cuda
from numba.cuda.random import create_xoroshiro128p_states
from numba.cuda.random import xoroshiro128p_uniform_float32
@cuda.jit
def gpu_monte_carlo_pi_sampler(rng_states, sub_sample_size, acc):
"""Uses GPU to sample random values and accumulates the sub count
of values within a circle of radius 1.
"""
pos = cuda.grid(1)
if pos < acc.shape[0]:
sub_acc = 0
for i in range(sub_sample_size):
x = xoroshiro128p_uniform_float32(rng_states, pos)
y = xoroshiro128p_uniform_float32(rng_states, pos)
if (x * x + y * y) <= 1.0:
sub_acc += 1
acc[pos] = sub_acc
rng_seed, sample_size = element
d_acc = cuda.to_device(self.h_acc)
sample_size_per_thread = sample_size // self.h_acc.shape[0]
rng_states = create_xoroshiro128p_states(self.h_acc.shape[0], seed=rng_seed)
gpu_monte_carlo_pi_sampler[self.blocks, self.threads_per_block](
rng_states, sample_size_per_thread, d_acc)
yield d_acc.copy_to_host()
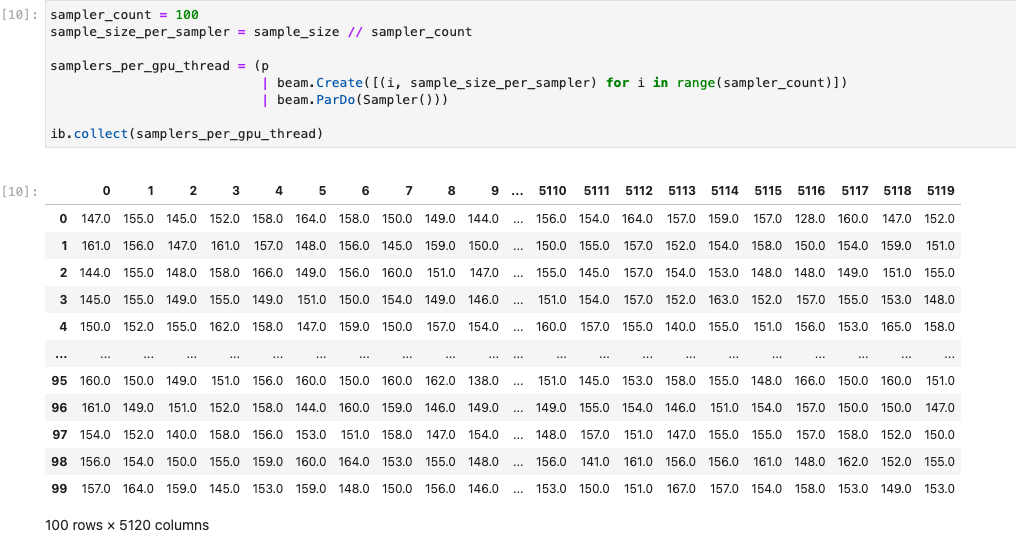
次の図は、GPU 上で実行されるノートブックを示しています。
詳細については、サンプル ノートブックの Apache Beam で GPU を使用するをご覧ください。
カスタム コンテナをビルドする
ほとんどの場合、パイプラインで追加の Python 依存関係や実行可能ファイルが不要な場合、Apache Beam で自動的に正式なコンテナ イメージを使用して、ユーザー定義コードを実行できます。これらのイメージには一般的な Python モジュールが数多く付属しているため、ビルドしたり、明示的に指定する必要はありません。
追加の Python の依存関係や、Python 以外の依存関係が存在することもあります。このようなシナリオでは、カスタム コンテナをビルドして、Flink クラスタで実行できるようにします。カスタム コンテナを使用するメリットは次のとおりです。
- 連続的またはインタラクティブな実行の設定時間が短縮される
- 安定した構成と依存関係
- 柔軟性の向上: Python の以外の依存関係も設定できます。
コンテナのビルドプロセスは面倒ですが、ノートブックでは、次の使用パターンですべてを行うことができます。
ローカル ワークスペースを作成する
まず、Jupyter ホーム ディレクトリの下にローカル作業ディレクトリを作成します。
!mkdir -p /home/jupyter/.flink
Python 依存関係を準備する
次に、追加の Python 依存関係をすべてインストールして、要件ファイルにエクスポートします。
%pip install dep_a
%pip install dep_b
...
%%writefile ノートブック マジックを使用して、要件ファイルを明示的に作成できます。
%%writefile /home/jupyter/.flink/requirements.txt
dep_a
dep_b
...
また、すべてのローカル依存関係を要件ファイルに固定することもできます。このオプションでは、意図しない依存関係が発生する可能性があります。
%pip freeze > /home/jupyter/.flink/requirements.txt
Python 以外の依存関係を準備する
Python 以外の依存関係をすべてワークスペースにコピーします。Python 以外の依存関係がない場合は、この手順をスキップします。
!cp /path/to/your-dep /home/jupyter/.flink/your-dep
...
Dockerfile を作成する
%%writefile ノートブック マジックを使用して、Dockerfile を作成します。例:
%%writefile /home/jupyter/.flink/Dockerfile
FROM apache/beam_python3.7_sdk:2.40.0
COPY requirements.txt /tmp/requirements.txt
COPY your_dep /tmp/your_dep
...
RUN python -m pip install -r /tmp/requirements.txt
このサンプル コンテナは、Python 3.7 をベースとする Apache Beam SDK バージョン 2.40.0 のイメージを使用し、your_dep ファイルを追加して、追加の Python 依存関係をインストールします。この Dockerfile をテンプレートとして使用し、ユースケースに合わせて編集します。
Apache Beam パイプラインで Python 以外の依存関係を参照する場合は、COPY の宛先を使用します。たとえば、/tmp/your_dep は your_dep ファイルのパスです。
Cloud Build を使用して Artifact Registry にコンテナ イメージをビルドする
Cloud Build サービスと Artifact Registry サービスを有効にします(まだ有効になっていない場合)。
!gcloud services enable cloudbuild.googleapis.com !gcloud services enable artifactregistry.googleapis.comアーティファクトをアップロードできるように、Artifact Registry リポジトリを作成します。各リポジトリには、サポートされている単一の形式のアーティファクトを含めることができます。
すべてのリポジトリのコンテンツは、 Google-owned and Google-managed encryption keys または顧客管理の暗号鍵を使用して暗号化されます。Artifact Registry ではGoogle-owned and Google-managed encryption keys がデフォルトで使用されるため、このオプションの構成は不要です。
少なくとも、リポジトリに対する Artifact Registry 書き込みアクセス権が必要です。
次のコマンドを実行して新しいリポジトリを作成します。このコマンドは
--asyncフラグを使用します。実行中のオペレーションの完了を待たずにすぐに戻ります。gcloud artifacts repositories create REPOSITORY \ --repository-format=docker \ --location=LOCATION \ --async次の値を置き換えます。
- REPOSITORY: リポジトリの名前。プロジェクト内のリポジトリのロケーションごとに、リポジトリ名は一意でなければなりません。
- LOCATION: リポジトリのロケーション。
イメージを push または pull する前に、Artifact Registry に対するリクエストを認証するように Docker を構成します。Docker リポジトリの認証を設定するには、次のコマンドを実行します。
gcloud auth configure-docker LOCATION-docker.pkg.devこのコマンドにより、Docker 構成が更新されます。これで、 Google Cloud プロジェクトの Artifact Registry に接続して、イメージを push できるようになりました。
Cloud Build を使用してコンテナ イメージをビルドし、Artifact Registry に保存します。
!cd /home/jupyter/.flink \ && gcloud builds submit \ --tag LOCATION.pkg.dev/PROJECT_ID/REPOSITORY/flink:latest \ --timeout=20mPROJECT_IDは、プロジェクトのプロジェクト ID に置き換えます。
カスタム コンテナを使用する
ランナーに応じて、カスタム コンテナはさまざまな目的に使用できます。
Apache Beam コンテナの一般的な使用方法については、以下をご覧ください。
Dataflow コンテナの使用方法については、以下をご覧ください。
外部 IP アドレスを無効にする
Apache Beam ノートブック インスタンスを作成する場合は、セキュリティを強化するために外部 IP アドレスを無効にします。ノートブック インスタンスは、Artifact Registry などの一部のパブリック インターネット リソースをダウンロードする必要があるため、最初に外部 IP アドレスを持たない新しい VPC ネットワークを作成する必要があります。次に、この VPC ネットワーク用に Cloud NAT ゲートウェイを作成します。Cloud NAT の詳細については、Cloud NAT のドキュメントをご覧ください。VPC ネットワークと Cloud NAT ゲートウェイを使用して、外部 IP アドレスを有効にせずに、必要なパブリック インターネット リソースにアクセスします。