Meta との統合
このページでは、Cortex Framework Data Foundation のマーケティング ワークロードのデータソースとして Meta(Facebook と Instagram 広告)からデータを取得するために必要な構成について説明します。
Meta は、いくつかの人気のあるオンライン プラットフォームを所有するテクノロジー企業です。Cortex Framework は、Instagram と Facebook の広告データを統合して分析し、他のデータソースと組み合わせて、AI を使用してより詳細な分析情報を取得し、マーケティング戦略を最適化します。
次の図は、Cortex Framework Data Foundation のマーケティング ワークロードで Meta マーケティング データを利用できる仕組みを示しています。

構成ファイル
config.json ファイルでは、さまざまなワークロードからデータを転送するためにデータソースに接続するために必要な設定を構成します。このファイルには、Meta の次のパラメータが含まれています。
"marketing": {
"deployMeta": true,
"Meta": {
"deployCDC": true,
"datasets": {
"cdc": "",
"raw": "",
"reporting": "REPORTING_Meta"
}
}
}
次の表に、各マーケティング パラメータの値を示します。
| パラメータ | 意味 | デフォルト値 | 説明 |
marketing.deployMeta
|
Meta をデプロイする | true
|
Meta のデータソースのデプロイを実行します。 |
marketing.Meta.deployCDC
|
Meta の CDC スクリプトをデプロイする | true
|
Meta CDC 処理スクリプトを生成して、Cloud Composer で DAG として実行します。 |
marketing.Meta.datasets.cdc
|
Meta の CDC データセット | Meta の CDC データセット。 | |
marketing.Meta.datasets.raw
|
Meta の元データセット | Meta の元のデータセット。 | |
marketing.Meta.datasets.reporting
|
Meta のレポート データセット | "REPORTING_Meta"
|
Meta のレポート データセット。 |
データモデル
このセクションでは、エンティティ関係図(ERD)を使用して Meta のデータモデルについて説明します。
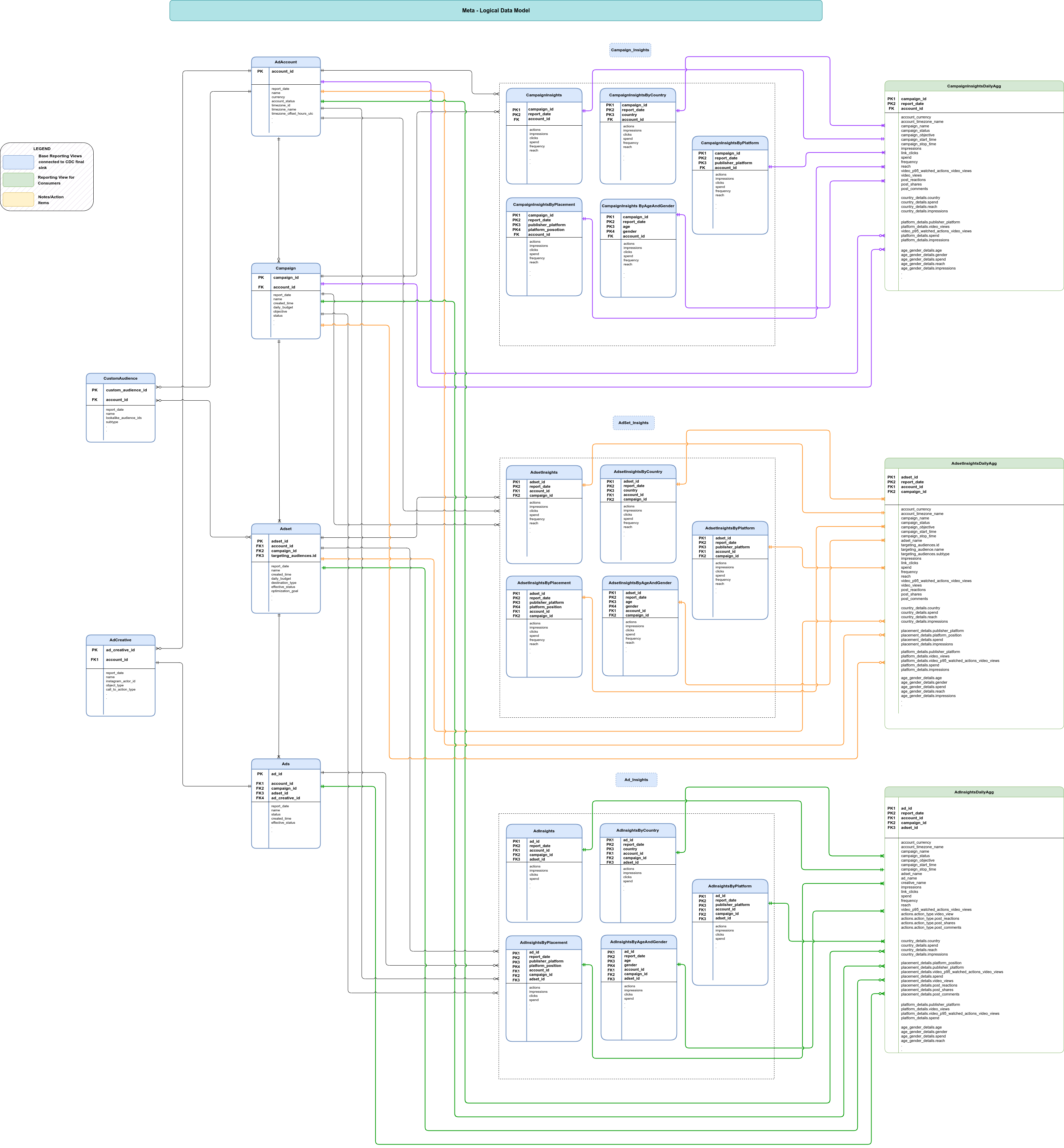
ベースビュー
これらは ERD の青色のオブジェクトであり、複雑なデータ構造を展開するために最小限の変換を加えた CDC テーブルのビューです。スクリプトは src/marketing/src/Meta/src/reporting/ddls にあります。
レポートビュー
これらは ERD の緑色のオブジェクトであり、集計指標を含むレポートビューです。スクリプトは src/marketing/src/Meta/src/reporting/ddls にあります。
API 接続
Cortex Framework for Meta のインジェスト テンプレートは、Meta Marketing API を使用して、レポート属性と指標を取得します。現在のテンプレートでは バージョン v21.0 が使用されています。
Meta は、Marketing API をクエリする際に動的レート制限を適用します。レート制限に達すると、ソースから未加工への取り込み DAG が正常に完了しないことがあります。その場合、ログに関連するエラー メッセージが表示され、DAG の次回の実行時に不足しているデータが遡及的に読み込まれます。
Meta Marketing API には、ベーシックと標準の 2 つのアクセス階層があります。スタンダード ティアでは上限が大幅に引き上げられているため、ソースから未加工への取り込みを頻繁に使用する場合は、スタンダード ティアを使用することをおすすめします。これらの上限と、より高いアクセス階層を取得する方法について詳しくは、Meta のドキュメントをご覧ください。
スタンダード ティアを利用している場合は、src/Meta/src/raw/pipelines/config.ini の next_request_delay_sec 設定の値を下げて、読み込み時間を短縮できます。
API アクセスとアクセス トークン
Meta から Cortex Framework にデータを正常に移行するには、Meta Business Manager と Developer Console で次の手順を行う必要があります。
- 使用するアプリを特定します。ビジネス アカウントに接続されている新しいアプリを作成できます。アプリが
Businessタイプであることを確認します。 - アプリの権限を設定します。アプリでトークンを作成するには、アプリに管理者として割り当てられている必要があります。アプリロールのドキュメントをご覧ください。関連するアセット(アカウント)をアプリに割り当ててください。
アクセス トークンを作成します。Meta Marketing API にアクセスするにはアクセス トークンが必要です。アクセス トークンは常にアプリとユーザーに関連付けられます。トークンは、システム ユーザーまたは独自のログインを使用して作成できます。
- 管理システム ユーザーを作成します。
- トークンを生成します。トークンはページを離れると再取得できなくなるため、生成後すぐにメモしておいてください。
- サポートされているオブジェクトにアクセスするには、トークンに
ads_read権限とbusiness_management権限を付与します。
Cloud Composer のドキュメントに沿って、Cloud Composer で Secret Manager を有効にします。次に、
cortex_meta_access_tokenという名前のシークレットを作成し、前の手順で生成したトークンをコンテンツとして保存します。
データの更新頻度と遅延
一般に、Cortex Framework データソースのデータの更新頻度は、アップストリーム接続で許可される内容と DAG 実行の頻度によって制限されます。アップストリームの頻度、リソースの制約、ビジネスニーズに合わせて DAG の実行頻度を調整します。
Meta Marketing API では、ほとんどのデータ(コンバージョンを除く)をほぼリアルタイムで利用できます。ただし、イベント発生から 28 日以内に調整される場合があります。
Cloud Composer 接続の権限
Cloud Composer で次の接続を作成します。詳細については、Airflow 接続を管理するドキュメントをご覧ください。
| 接続名 | 目的 |
meta_raw_dataflow
|
Meta Marketing API > BigQuery 元データセット |
meta_cdc_bq
|
元データセット > CDC データセットの転送の場合 |
meta_reporting_bq
|
CDC データセットの場合 > レポート データセットの転送 |
Cloud Composer サービス アカウントの権限
Cloud Composer で使用されるサービス アカウントに Dataflow 権限を付与します(meta_raw_dataflow 接続で構成されているように)。Dataflow のドキュメントの手順をご覧ください。サービス アカウントには Secret Manager Secret Accessor 権限も必要です。詳細については、アクセス制御のドキュメントをご覧ください。
リクエスト パラメータ
ディレクトリ src/Meta/config/request_parameters には、Meta Marketing API から抽出されたエンティティごとに API リクエスト仕様ファイルが含まれています。各リクエスト ファイルには、Meta Marketing API から取得するフィールドのリストが含まれます。このリストは、1 行に 1 つのフィールドが含まれます。詳しくは、Meta Marketing API リファレンスをご覧ください。
取り込み設定
src/Meta/config/ingestion_settings.yaml ファイルの設定を使用して、Source to Raw データ パイプラインと Raw to CDC データ パイプラインを制御します。このセクションでは、各データ パイプラインのパラメータについて説明します。
ソースから未加工テーブル
このセクションには、API によって取得されるエンティティとその方法を制御するエントリがあります。各エントリは 1 つの Meta Marketing API エンティティに対応しています。この構成に基づいて、Cortex Framework は、Dataflow パイプラインを実行して Meta Marketing API を使用してデータを取得する Airflow DAG を作成します。
ファイル src/Meta/src/raw/pipelines/config.ini は、Cloud Composer DAG の一部動作と Meta Marketing API の使用方法を制御します。ファイル内の各パラメータの説明を確認します。
次のパラメータは、各エントリの Source to Raw の設定を制御します。
| パラメータ | 説明 |
base_table
|
フェッチされたデータが保存されている元データセット内のテーブル(例: customer)。 |
load_frequency
|
この DAG が実行されて Meta からデータを取得する頻度。使用可能な値の詳細については、Airflow のドキュメントをご覧ください。 |
object_endpoint
|
API エンドポイント パス(/{account_id}/campaigns エンドポイントの場合は campaigns など)。 |
entity_type
|
テーブルのタイプ(fact、dimension、addaccount) のいずれか)。 |
object_id_column
|
このテーブルの一意のレコードを形成する列(カンマ区切り)。entity_type が fact の場合にのみ必要です。 |
breakdowns
|
省略可: 分析情報エンドポイントの分類列(カンマ区切り)。entity_type が fact の場合にのみ適用されます。 |
action_breakdowns
|
省略可: 分析情報エンドポイントのアクションの内訳列(カンマ区切り)。entity_type が fact の場合にのみ適用されます。 |
partition_details
|
省略可: パフォーマンスを考慮してこのテーブルをパーティショニングする場合。詳細については、テーブル パーティションをご覧ください。 |
cluster_details
|
省略可: パフォーマンスを考慮してこのテーブルをクラスタ化する場合は、詳細については、クラスタ設定をご覧ください。 |
元のテーブルから CDC テーブル
このセクションでは、Raw テーブルから CDC テーブルにデータが移動される方法を制御するエントリについて説明します。各エントリは元のテーブルに対応しています(これは、前述の Meta API エンティティに対応しています)。
次のパラメータは、各エントリの Raw to CDC の設定を制御します。
| パラメータ | 説明 |
base_table
|
元データが複製されたテーブル。CDC データセット内の同じ名前のテーブルには、CDC 変換後の元データが保存されます(例: campaign_insights)。 |
row_identifiers
|
このテーブルの一意のレコードを形成する列(カンマ区切り)。 |
load_frequency
|
このエンティティの DAG が実行され、CDC テーブルにデータが入力される頻度。使用可能な値の詳細については、Airflow のドキュメントをご覧ください。 |
partition_details
|
省略可: パフォーマンスを考慮してこのテーブルをパーティショニングする場合。詳細については、テーブル パーティションをご覧ください。 |
cluster_details
|
省略可: パフォーマンスを考慮してこのテーブルをクラスタ化する場合は、詳細については、クラスタ設定をご覧ください。 |
CDC テーブルのスキーマ
Meta の場合、すべてのフィールドは未加工レイヤに文字列形式で保存されます。CDC レイヤでは、プリミティブ型は関連するビジネス データ型に変換され、すべての複合型は BigQuery JSON 形式で保存されます。
この変換を有効にするには、ディレクトリ src/Meta/config/table_schema に、raw_to_cdc_tables セクションで指定されたエンティティごとに 1 つのスキーマ ファイルを含めます。このファイルには、各 BigQueryraw テーブルを CDC テーブルに適切に変換する方法が記載されています。
各スキーマ ファイルには、次の 3 つの列があります。
SourceField: このエンティティの元のテーブルのフィールド名。TargetField: このエンティティの CDC テーブル内の列名。DataType: 各 CDC テーブル フィールドのデータ型。
レポート設定
Cortex が Meta 最終レポートレイヤ用にデータを生成する方法は、レポート設定ファイル(src/Meta/config/reporting_settings.yaml)を使用して構成および制御できます。このファイルは、レポートレイヤの BigQuery オブジェクト(テーブル、ビュー、関数、ストアド プロシージャ)の生成方法を制御します。
詳細については、レポート設定ファイルのカスタマイズをご覧ください。
次のステップ
- その他のデータソースとワークロードの詳細については、データソースとワークロードをご覧ください。
- 本番環境にデプロイする手順の詳細については、Cortex Framework Data Foundation のデプロイの前提条件をご覧ください。