1단계: 워크로드 설정
이 페이지에서는 Cortex Framework의 핵심인 데이터 기반을 설정하는 초기 단계를 안내합니다. BigQuery 스토리지 기반으로 구축된 데이터 파운데이션은 다양한 소스의 수신 데이터를 정리합니다. 이렇게 정리된 데이터는 분석과 AI 개발에서의 적용을 간소화합니다.
데이터 통합 설정
Cortex Framework 내에서 데이터를 효율적으로 정리하고 사용하는 청사진 역할을 하는 몇 가지 주요 매개변수를 정의하여 시작하세요. 이러한 매개변수는 특정 워크로드, 선택한 데이터 흐름, 통합 메커니즘에 따라 달라질 수 있습니다. 다음 다이어그램은 Cortex Framework 데이터 기반 내의 데이터 통합을 간략하게 보여줍니다.

Cortex Framework 내에서 효율적이고 효과적인 데이터 활용을 위해 배포 전에 다음 매개변수를 정의합니다.
프로젝트
- 소스 프로젝트: 원시 데이터가 있는 프로젝트입니다. 데이터를 저장하고 배포 프로세스를 실행하려면 Google Cloud 프로젝트가 하나 이상 필요합니다.
- 타겟 프로젝트 (선택사항): Cortex Framework Data Foundation이 처리된 데이터 모델을 저장하는 프로젝트입니다. 필요에 따라 소스 프로젝트와 동일하거나 다른 프로젝트일 수 있습니다.
각 워크로드에 별도의 프로젝트 및 데이터 세트가 필요하다면(예: SAP용 소스 및 타겟 프로젝트 세트와 Salesforce용 타겟 및 소스 프로젝트 세트가 다른 경우) 각 워크로드에 별도의 배포를 실행하세요. 자세한 내용은 선택사항 단계 섹션의 액세스 권한을 분리하기 위해 다른 프로젝트 사용을 참고하세요.
데이터 모델
- 모델 배포: 모든 워크로드에 모델을 배포해야 하는지 아니면 모델 세트 하나 (예: SAP, Salesforce, Meta)에만 배포해야 하는지 선택합니다. 자세한 내용은 사용 가능한 데이터 소스 및 워크로드를 참고하세요.
BigQuery 데이터 세트
- 소스 데이터 세트 (원시): 소스 데이터가 복제되거나 테스트 데이터가 생성되는 BigQuery 데이터 세트입니다. 데이터 소스별로 데이터 세트를 별도로 사용하는 것이 좋습니다. 예를 들어 SAP용 원시 데이터 세트 하나와 Google Ads용 원시 데이터 세트 하나가 있습니다. 이 데이터 세트는 소스 프로젝트에 속합니다.
- CDC 데이터 세트: CDC 처리 데이터가 최신 사용 가능한 레코드를 저장하는 BigQuery 데이터 세트입니다. 일부 워크로드에서는 필드 이름 매핑이 허용됩니다. 각 소스에 대해 별도의 CDC 데이터 세트를 사용하는 것이 좋습니다. 예를 들어 SAP용 CDC 데이터 세트 하나와 Salesforce용 CDC 데이터 세트 하나가 있습니다. 이 데이터 세트는 소스 프로젝트에 속합니다.
- 타겟 보고 데이터 세트: 데이터 파운데이션 사전 정의 데이터 모델이 배포되는 BigQuery 데이터 세트입니다. 소스별로 별도의 보고 데이터 세트를 사용하는 것이 좋습니다. 예를 들어 SAP용 보고 데이터 세트 하나와 Salesforce용 보고 데이터 세트 하나를 만들 수 있습니다. 이 데이터 세트는 배포 중에 자동으로 생성됩니다(없는 경우). 이 데이터 세트는 대상 프로젝트에 속합니다.
- K9 데이터 세트 사전 처리:
time측정기준과 같은 교차 워크로드 재사용 가능한 DAG 구성요소를 배포할 수 있는 BigQuery 데이터 세트입니다. 수정하지 않는 한 워크로드는 이 데이터 세트에 종속됩니다. 이 데이터 세트는 배포 중에 자동으로 생성됩니다(없는 경우). 이 데이터 세트는 소스 프로젝트에 속합니다. - 후처리 K9 데이터 세트: 교차 워크로드 보고 및 추가 외부 소스 DAG (예: Google 트렌드 수집)를 배포할 수 있는 BigQuery 데이터 세트입니다. 이 데이터 세트는 배포 중에 자동으로 생성됩니다(없는 경우). 이 데이터 세트는 대상 프로젝트에 속합니다.
선택사항: 샘플 데이터 생성
Cortex Framework는 자체 데이터에 액세스할 수 없거나, 데이터를 설정할 복제 도구가 없거나, Cortex Framework의 작동 방식을 확인하려는 경우 샘플 데이터와 테이블을 생성할 수 있습니다. 하지만 CDC 및 원시 데이터 세트를 미리 만들고 식별해야 합니다.
다음 안내에 따라 데이터 소스별로 원시 데이터와 CDC를 위한 BigQuery 데이터 세트를 만듭니다.
콘솔
Google Cloud 콘솔에서 BigQuery 페이지를 엽니다.
탐색기 패널에서 데이터 세트를 만들 프로젝트를 선택합니다.
작업 옵션을 펼치고 데이터 세트 만들기를 클릭합니다.
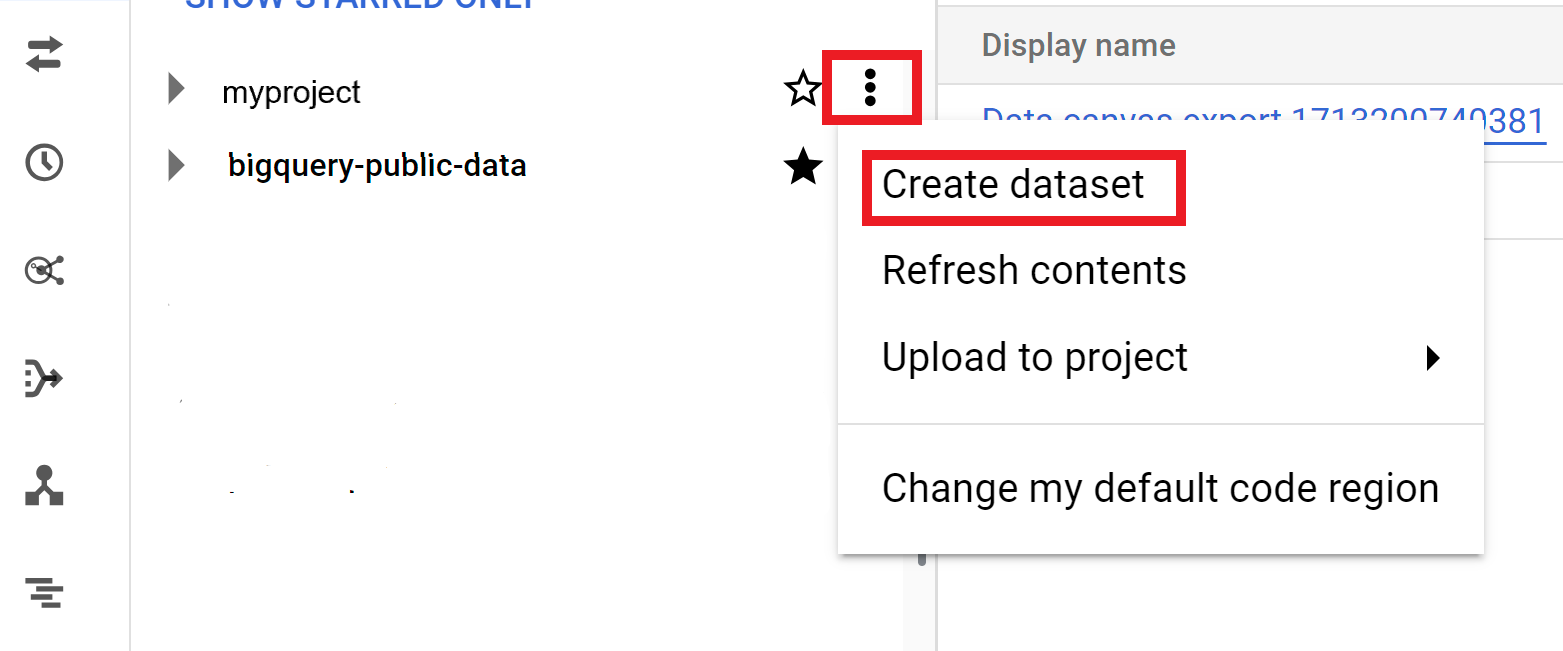
데이터 세트 만들기 페이지에서 다음을 실행합니다.
- 데이터 세트 ID에 고유한 데이터 세트 이름을 입력합니다.
위치 유형에서 데이터 세트의 지리적 위치를 선택합니다. 데이터 세트가 생성된 후에는 위치를 변경할 수 없습니다.
선택사항. 데이터 세트의 맞춤설정에 관한 자세한 내용은 데이터 세트 만들기: 콘솔을 참고하세요.
데이터 세트 만들기를 클릭합니다.
BigQuery
다음 명령어를 복사하여 원시 데이터의 새 데이터 세트를 만듭니다.
bq --location= LOCATION mk -d SOURCE_PROJECT: DATASET_RAW다음을 바꿉니다.
LOCATION을 데이터 세트의 위치로 바꿉니다.SOURCE_PROJECT를 소스 프로젝트 ID로 바꿉니다.DATASET_RAW을 원시 데이터의 데이터 세트 이름으로 바꿉니다. 예를 들면CORTEX_SFDC_RAW입니다.
다음 명령어를 복사하여 CDC 데이터의 새 데이터 세트를 만듭니다.
bq --location=LOCATION mk -d SOURCE_PROJECT: DATASET_CDC다음을 바꿉니다.
LOCATION을 데이터 세트의 위치로 바꿉니다.SOURCE_PROJECT를 소스 프로젝트 ID로 바꿉니다.DATASET_CDC를 CDC 데이터의 데이터 세트 이름으로 바꿉니다. 예를 들면CORTEX_SFDC_CDC입니다.
다음 명령어를 사용하여 데이터 세트가 생성되었는지 확인합니다.
bq ls선택사항. 데이터 세트 만들기에 대한 자세한 내용은 데이터 세트 만들기를 참고하세요.
다음 단계
이 단계를 완료한 후 다음 배포 단계로 이동합니다.