이 페이지에서는 VMware용 Google Distributed Cloud(소프트웨어 전용)의 고가용성 옵션을 설명합니다.
핵심 기능
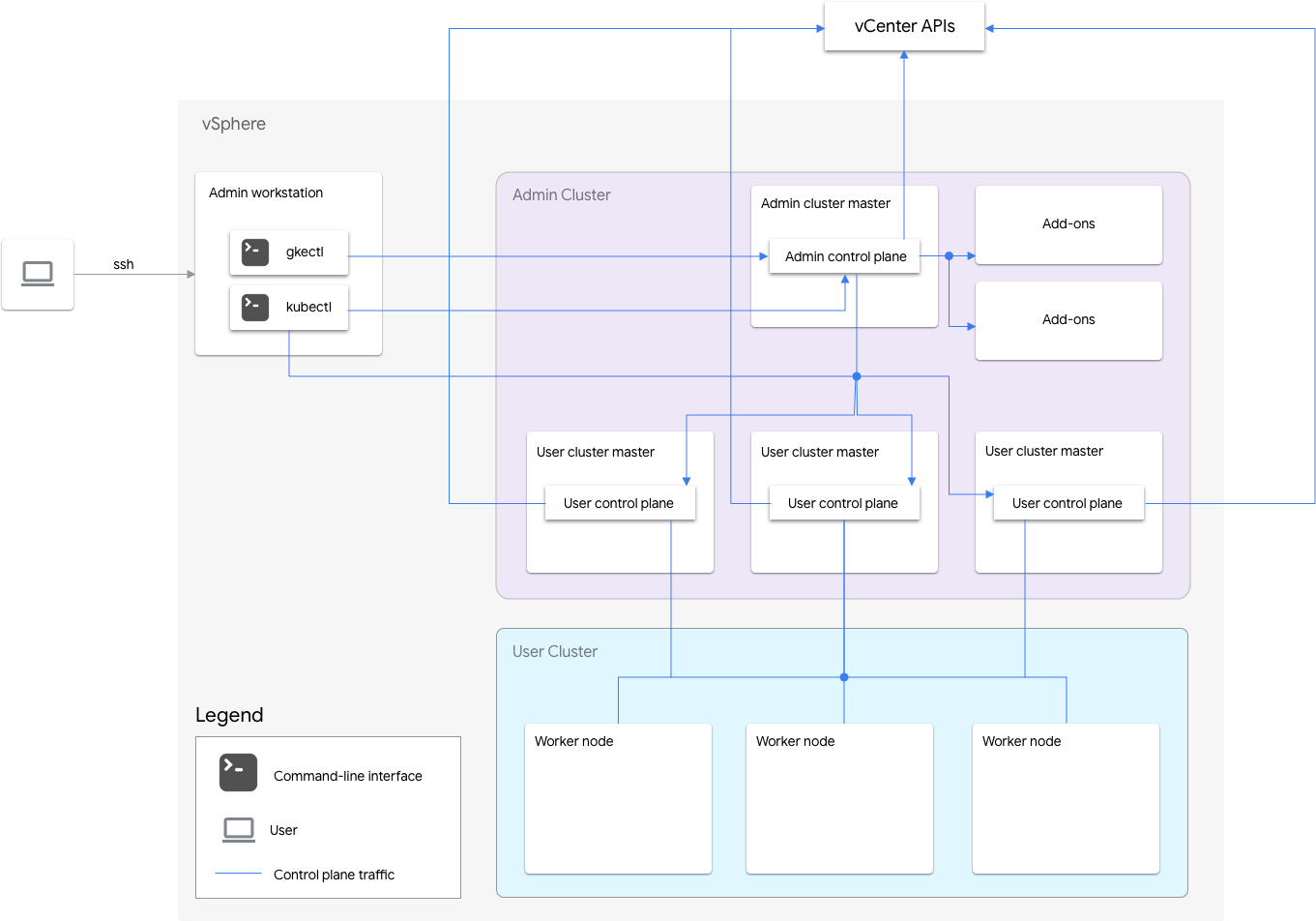
VMware용 Google Distributed Cloud의 소프트웨어 전용 설치에는 관리자 클러스터와 하나 이상의 사용자 클러스터가 포함됩니다.
관리 클러스터는 사용자 클러스터 만들기, 업데이트, 업그레이드, 삭제를 포함하여 사용자 클러스터의 수명 주기를 관리합니다. 관리 클러스터에서 관리 마스터는 사용자 마스터(관리형 사용자 클러스터의 제어 영역을 실행하는 노드) 및 부가기능 노드(관리 클러스터의 기능을 지원하는 부가기능 구성요소를 실행하는 노드)를 포함하는 관리 워커 노드를 관리합니다.
각 사용자 클러스터의 관리자 클러스터에는 비 HA 노드 1개 또는 제어 영역을 실행하는 HA 노드 3개가 있습니다. 제어 영역에는 Kubernetes API 서버, Kubernetes 스케줄러, Kubernetes 컨트롤러 관리자 및 사용자 클러스터의 몇 가지 주요 컨트롤러가 포함됩니다.
사용자 클러스터의 제어 영역 기능은 워크로드 만들기, 확장 및 축소, 종료와 같은 워크로드 작업에 중요합니다. 즉, 제어 영역이 실행 중인 워크로드와 간섭되지 않지만 제어 영역이 없으면 기존 워크로드에서 Kubernetes API 서버의 관리 기능이 손실됩니다.
컨테이너화된 워크로드 및 서비스는 사용자 클러스터 워커 노드에 배포됩니다. 모든 단일 워커 노드는 애플리케이션이 여러 워커 노드 간에 예약된 중복 포드로 배포되는 한 애플리케이션 가용성에 중요하지 않습니다.
고가용성 사용 설정
vSphere와 Google Distributed Cloud는 고가용성(HA)에 기여하는 다양한 기능을 제공합니다.
vSphere HA 및 vMotion
Google Distributed Cloud 클러스터를 호스팅하는 vCenter 클러스터에서 다음 두 기능을 사용 설정하는 것이 좋습니다.
이러한 기능은 ESXi 호스트가 실패할 경우 가용성 및 복구를 향상시킵니다.
vCenter HA는 클러스터로 구성된 여러 ESXi 호스트를 사용하여 서비스 중단을 빠르게 복구하고 가상 머신에서 실행되는 애플리케이션에 대해 비용 효율적인 HA를 제공합니다. 추가 호스트를 사용하여 vCenter 클러스터를 프로비저닝하고 Host Failure Response를 Restart VMs로 설정하여 vSphere HA 호스트 모니터링을 사용 설정하는 것이 좋습니다. 그런 다음 ESXi 호스트 장애 발생 시 다른 사용 가능한 호스트에서 VM이 자동으로 다시 시작될 수 있습니다.
vMotion을 사용하면 한 ESXi 호스트에서 다른 호스트로 VM을 다운타임 없이 실시간 마이그레이션할 수 있습니다. 예정된 호스트 유지보수의 경우 vMotion 라이브 마이그레이션을 사용하여 애플리케이션 다운타임을 완전히 방지하고 비즈니스 연속성을 보장할 수 있습니다.
관리자 클러스터
Google Distributed Cloud는 고가용성(HA) 관리자 클러스터 만들기를 지원합니다. HA 관리자 클러스터에는 제어 영역 구성요소를 실행하는 3개의 노드가 있습니다. 요구사항 및 제한사항에 관한 자세한 내용은 고가용성 관리자 클러스터를 참조하세요.
관리자 클러스터 제어 영역을 사용할 수 없는 경우에도 기존 사용자 클러스터 기능이나 사용자 클러스터에서 실행되는 워크로드에는 아무런 영향이 없습니다.
관리자 클러스터에는 두 개의 부가기능 노드가 있습니다. 하나가 다운되어도 다른 클러스터는 관리자 클러스터 작업을 수행할 수 있습니다. Google Distributed Cloud는 중복화를 위해 kube-dns와 같은 중요한 부가기능 서비스를 두 부가기능 노드에 분산합니다.
관리자 클러스터 구성 파일에서 antiAffinityGroups.enabled를 true로 설정하면 Google Distributed Cloud는 부가기능 노드에 대한 vSphere DRS 안티-어피니티 규칙을 자동으로 생성하고 HA를 위해 두 개의 물리적 호스트에 분산됩니다.
사용자 클러스터
사용자 클러스터 구성 파일에서 masterNode.replicas를 3로 설정하여 사용자 클러스터에 HA를 사용 설정할 수 있습니다. 사용자 클러스터에 Controlplane V2가 사용 설정되었으면(권장) 3개의 제어 영역 노드가 사용자 클러스터에서 실행됩니다.
기존 HA kubeception 사용자 클러스터는 관리자 클러스터에서 3개의 제어 영역 노드를 실행합니다. 각 제어 영역 노드도 etcd 복제본을 실행합니다. 하나의 제어 영역이 실행 중이고 etcd 쿼럼이 있는 한 사용자 클러스터가 계속 작동합니다. etcd 쿼럼은 세 개의 etcd 복제본 중 두 개가 작동해야 합니다.
관리자 클러스터 구성 파일에서 antiAffinityGroups.enabled를 true로 설정하면 Google Distributed Cloud는 사용자 클러스터 제어 영역을 실행하는 세 노드에 대한 vSphere DRS 안티-어피니티 규칙을 자동으로 생성합니다.
이 경우 VM이 3개의 물리적 호스트에 분산됩니다.
또한 Google Distributed Cloud는 사용자 클러스터의 워커 노드에 vSphere DRS 안티-어피니티 규칙을 만들어 3개 이상의 물리적 호스트에 노드를 분산시킵니다. 여러 DRS 안티어피니티 규칙은 노드 수에 따라 사용자 클러스터 노드 풀별로 사용됩니다. 이렇게 하면 호스트 수가 사용자 클러스터 노드 풀의 VM 수보다 적더라도 워커 노드가 실행할 호스트를 찾을 수 있습니다. vCenter 클러스터에 추가 물리적 호스트를 포함하는 것이 좋습니다. 또한 DRS를 완전히 자동화하도록 구성합니다. 이렇게 하면 호스트를 사용할 수 없게 되므로 VM의 안티어피니티 규칙을 위반하지 않고 다른 사용 가능한 호스트에서 VM을 자동으로 다시 시작할 수 있습니다.
Google Distributed Cloud는 특수 노드 라벨인 onprem.gke.io/failure-domain-name을 유지하고 이 값은 기본 ESXi 호스트 이름으로 설정됩니다. 고가용성을 원하는 사용자 애플리케이션은 이 라벨을 사용하여 podAntiAffinity 규칙을 topologyKey로 설정하여 애플리케이션 포드가 물리적 호스트는 물론 서로 다른 VM에 분산되도록 할 수 있습니다.
또한 다른 Datastore 및 특수 노드 라벨을 사용해서 사용자 클러스터에 대해 여러 노드 풀을 구성할 수 있습니다. 마찬가지로 이 특수 노드 라벨을 사용하여 podAntiAffinity 규칙을 topologyKey로 설정하면 Datastore 실패 시 고가용성을 확보할 수 있습니다.
사용자 워크로드에 대한 HA를 사용하려면 사용자 클러스터가 nodePools.replicas에 원하는 수의 사용자 클러스터 워커 노드가 실행 중인지 확인할 수 있는 충분한 수의 복제본을 가지고 있는지 확인하세요.
관리자 클러스터 및 사용자 클러스터에 별도의 Datastore를 사용하여 오류를 격리할 수 있습니다.
부하 분산기
고가용성에 사용할 수 있는 부하 분산기에는 다음 두 가지 유형이 있습니다.
번들 MetalLB 분산기
번들 MetalLB 부하 분산기의 경우 enableLoadBalancer: true인 노드가 두 개 이상 있으면 HA를 확보할 수 있습니다.
MetalLB는 서비스를 부하 분산기 노드에 배포하지만 단일 서비스의 경우 해당 서비스의 모든 트래픽을 처리하는 리더 노드가 하나뿐입니다.
클러스터 업그레이드 중에 부하 분산기 노드가 업그레이드되면 다운타임이 발생합니다. MetalLB의 장애 조치 중단 기간은 부하 분산기 노드 수가 증가함에 따라 증가합니다. 노드가 5개 미만이면 중단은 10초 이내입니다.
번들 Seesaw 부하 분산기
번들 Seesaw 부하 분산기의 경우 클러스터 구성 파일에서 loadBalancer.seesaw.enableHA를 true로 설정하여 HA를 사용 설정할 수 있습니다.
또한 부하 분산기 포트 그룹에서 MAC 학습, 위조 전송, 무차별 모드의 조합을 사용 설정해야 합니다.
HA를 사용하면 두 개의 부하 분산기가 활성-수동 모드로 설정됩니다. 활성 부하 분산기에 문제가 있는 경우 트래픽은 수동 부하 분산기로 장애 조치됩니다.
부하 분산기 업그레이드 중에는 다운타임이 발생합니다. 부하 분산기에 HA가 사용 설정된 경우 최대 다운타임은 2초입니다.
통합 F5 BIG-IP 부하 분산기
F5 BIG-IP 플랫폼은 애플리케이션의 보안, 가용성, 성능을 개선하는 데 도움이 되는 다양한 서비스를 제공합니다. Google Distributed Cloud의 경우 BIG-IP는 외부 액세스와 L3/4 부하 분산 서비스를 제공합니다.
재해 복구에 여러 클러스터 사용
여러 vCenter 또는 GKE Enterprise 플랫폼에 걸쳐 여러 클러스터에 애플리케이션을 배포하면 전역 가용성을 더 높이고 서비스 중단 시 영향 범위를 제한할 수 있습니다.
이 설정에서는 재해 복구를 위해 새 클러스터를 설정하는 대신 보조 데이터 센터의 기존 GKE Enterprise 클러스터를 사용합니다. 요약하면 다음과 같습니다.
보조 데이터 센터에 다른 관리자 클러스터와 사용자 클러스터를 만듭니다. 이 멀티 클러스터 아키텍처에서는 각 데이터 센터에 관리자 클러스터 두 개가 필요하며 각 관리자 클러스터는 사용자 클러스터를 실행합니다.
보조 사용자 클러스터에는 최소한의 워커 노드(3)가 있으며 상시 대기 중(항상 실행 중)입니다.
애플리케이션 배포는 구성 동기화를 사용하여 2개의 vCenter에 걸쳐 복제될 수 있으며, 선호되는 방식은 기존 애플리케이션 DevOps(CI/CD, Spinnaker) 도구 모음을 사용하는 것입니다.
재해가 발생할 경우 사용자 클러스터의 크기를 노드 수로 조정할 수 있습니다.
또한 클러스터 간 트래픽을 보조 데이터 센터로 라우팅하려면 DNS 전환이 필요합니다.