Dank der Portabilität von AlloyDB Omni können Sie die Software in vielen Umgebungen ausführen, darunter:
- Rechenzentren
- Laptops
- Cloudbasierte VM-Instanzen
Anwendungsfälle für AlloyDB Omni
AlloyDB Omni eignet sich gut für die folgenden Szenarien:
- Sie benötigen eine skalierbare und leistungsstarke Version von PostgreSQL, können aber aufgrund von behördlichen oder datenschutzrechtlichen Anforderungen keine Datenbank in der Cloud ausführen.
- Sie benötigen eine Datenbank, die auch dann weiter ausgeführt wird, wenn sie nicht mit dem Internet verbunden ist.
- Um die Latenz zu minimieren, sollten Sie Ihre Datenbank geografisch so nah wie möglich an Ihren Nutzern platzieren.
- Sie möchten von einer Legacy-Datenbank migrieren, ohne eine vollständige Cloud-Migration durchzuführen.
AlloyDB Omni enthält keine AlloyDB for PostgreSQL-Funktionen, die auf dem Betrieb in Google Cloudbasieren. Wenn Sie Ihr Projekt auf die vollständig verwalteten Skalierungs-, Sicherheits- und Verfügbarkeitsfunktionen von AlloyDB for PostgreSQL upgraden möchten, können Sie Ihre AlloyDB Omni-Daten in einen AlloyDB for PostgreSQL-Cluster migrieren. Das funktioniert genauso wie bei jedem anderen anfänglichen Datenimport.
Wichtige Features
- Ein PostgreSQL-kompatibler Datenbankserver.
- Unterstützung für AlloyDB AI, mit der Sie generative KI-Anwendungen für Unternehmen mit Ihren Betriebsdaten erstellen können.
- Integrationen mit dem Google Cloud KI-Ökosystem, einschließlich Vertex AI Model Garden und Open-Source-Tools für generative KI.
Unterstützung für Autopilot-Funktionen aus AlloyDB for PostgreSQL inGoogle Cloud , mit denen sich AlloyDB Omni selbst verwalten und optimieren kann.
AlloyDB Omni unterstützt beispielsweise die automatische Arbeitsspeicherverwaltung und adaptives Autovacuum für veraltete Daten.
Ein Indexberater, der häufig ausgeführte Abfragen analysiert und neue Indexe für eine bessere Abfrageleistung empfiehlt.
Die spaltenbasierte AlloyDB-Engine, die häufig abgefragte Daten in einem speicherinternen Spaltenformat speichert, um die Leistung von Business Intelligence, Berichten sowie Arbeitslasten von hybriden transaktionsorientierten und analytischen Verarbeitungen (HTAP) zu verbessern.
In unseren Leistungstests sind Transaktionsarbeitslasten in AlloyDB Omni mehr als doppelt so schnell und analytische Abfragen bis zu 100-mal schneller als in Standard-PostgreSQL.
Funktionsweise von AlloyDB Omni
Sie können AlloyDB Omni als eigenständigen Server oder als Teil einer Kubernetes-Umgebung installieren.
AlloyDB Omni wird in einem Docker-Container ausgeführt, den Sie in Ihrer eigenen Umgebung installieren. Wir empfehlen, AlloyDB Omni auf einem Linux-System mit SSD-Speicher und mindestens 8 GB Arbeitsspeicher pro CPU auszuführen.
Der AlloyDB Omni Kubernetes-Operator ist eine Erweiterung der Kubernetes API, mit der Sie AlloyDB Omni in den meisten CNCF-kompatiblen Kubernetes-Umgebungen ausführen können. Weitere Informationen finden Sie unter AlloyDB Omni auf Kubernetes installieren.
Ihre Anwendungen stellen eine Verbindung zu Ihrer AlloyDB Omni-Installation her und kommunizieren mit ihr, genau wie Anwendungen eine Verbindung zu einem Standard-PostgreSQL-Datenbankserver herstellen und mit ihm kommunizieren. Die Nutzerzugriffssteuerung basiert ebenfalls auf PostgreSQL-Standards.
Von der Protokollierung über die Bereinigung bis hin zur spaltenorientierten Engine können Sie das Datenbankverhalten von AlloyDB Omni mit Datenbank-Flags konfigurieren.
Vorteile der Ausführung von AlloyDB Omni als Container
Google stellt AlloyDB Omni als Container bereit, den Sie mit Containerlaufzeiten wie Docker und Podman ausführen können. Container bieten folgende operative Vorteile:
- Transparente Verwaltung von Abhängigkeiten: Alle erforderlichen Abhängigkeiten sind im Container gebündelt und werden von Google getestet, um sicherzustellen, dass sie vollständig mit AlloyDB Omni kompatibel sind.
- Portierbarkeit: AlloyDB Omni funktioniert in allen Umgebungen konsistent.
- Sicherheitsisolation: Sie legen fest, worauf der AlloyDB Omni-Container auf dem Hostcomputer zugreifen kann.
- Ressourcenverwaltung: Sie können die Menge an Rechenressourcen definieren, die der AlloyDB Omni-Container verwenden soll.
- Nahtloses Patchen und Upgraden: Wenn Sie einen Container patchen möchten, müssen Sie nur das vorhandene Image durch ein neues ersetzen.
Datensicherung und Wiederherstellung im Notfall
AlloyDB Omni bietet ein System für kontinuierliche Sicherung und Wiederherstellung, mit dem Sie einen neuen Datenbankcluster basierend auf einem beliebigen Zeitpunkt innerhalb eines anpassbaren Aufbewahrungszeitraums erstellen können. So können Sie sich schnell von Datenverlusten erholen.
Außerdem kann AlloyDB Omni vollständige Sicherungen der Daten Ihres Datenbankclusters erstellen und speichern, entweder auf Anfrage oder in regelmäßigen Abständen. Sie können jederzeit eine Sicherung in einem AlloyDB Omni-Datenbankcluster wiederherstellen, der alle Daten aus dem ursprünglichen Datenbankcluster zum Zeitpunkt der Erstellung der Sicherung enthält.
Weitere Informationen finden Sie unter AlloyDB Omni sichern und wiederherstellen.
Als weitere Methode zur Notfallwiederherstellung können Sie die Replikation über Rechenzentren hinweg erreichen, indem Sie sekundäre Datenbankcluster in separaten Rechenzentren erstellen. AlloyDB Omni streamt Daten asynchron von einem bestimmten primären Datenbankcluster zu jedem seiner sekundären Cluster. Bei Bedarf können Sie einen sekundären Datenbankcluster in einen primären AlloyDB Omni-Datenbankcluster hochstufen.
Weitere Informationen finden Sie unter Rechenzentrumsübergreifende Replikation.
AlloyDB Omni-VM-Komponenten
AlloyDB Omni auf VM besteht aus zwei Gruppen von Architekturkomponenten: PostgreSQL-Komponenten mit AlloyDB for PostgreSQL-Erweiterungen und AlloyDB for PostgreSQL-Komponenten. Im folgenden Diagramm sind beide Gruppen von Komponenten, die Infrastrukturschicht, in der sie sich auf einer VM oder einem Server befinden, und die zugehörigen Funktionen dargestellt, die für jede Komponente zu erwarten sind.
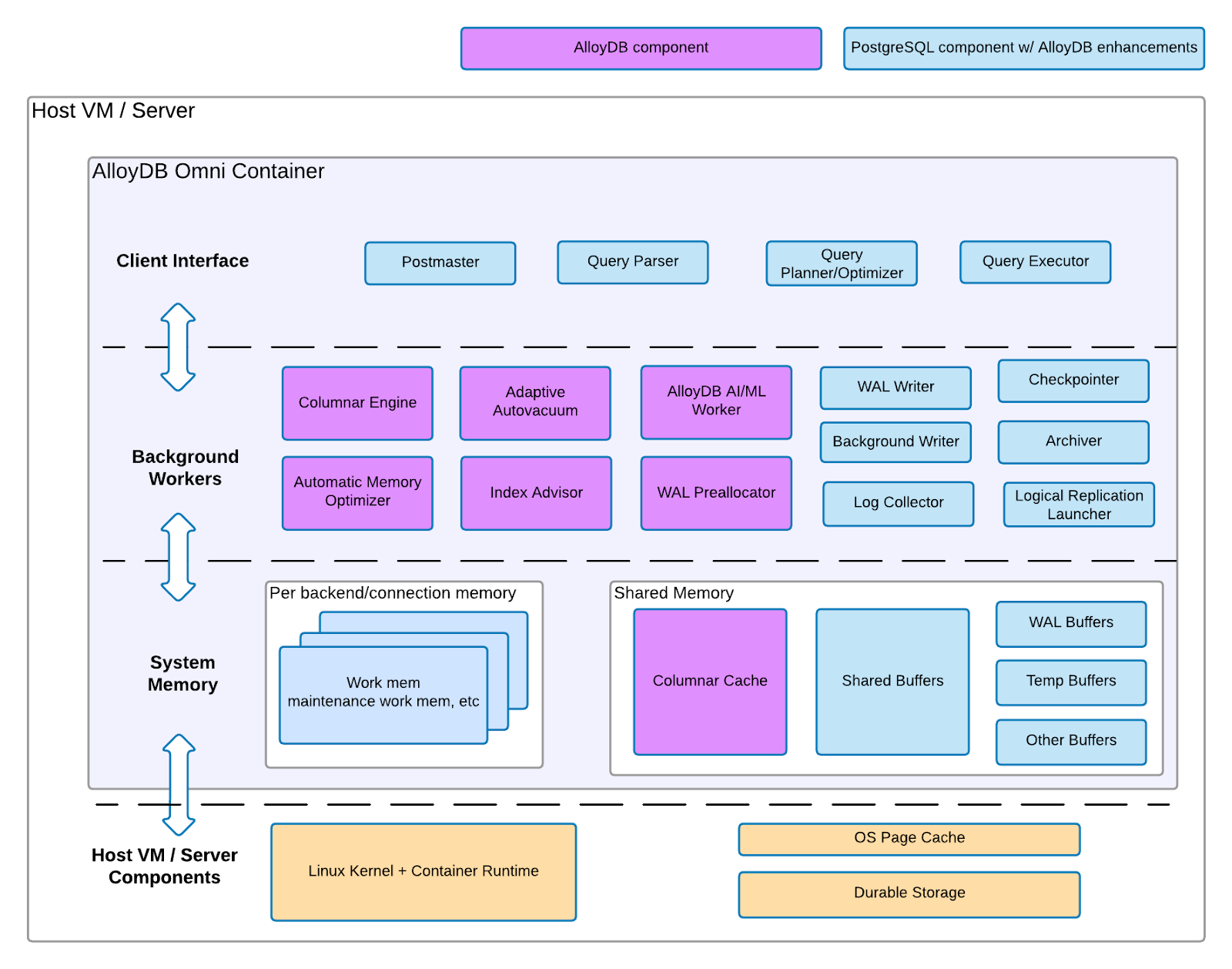
Abbildung 1. AlloyDB Omni-Architektur
Datenbankmodul
In diesem Dokument wird die Datenbankarchitektur in AlloyDB Omni in einem Container beschrieben. In diesem Dokument wird davon ausgegangen, dass Sie mit PostgreSQL vertraut sind.
Ein Datenbankmodul führt die folgenden Aufgaben aus:
- Übersetzt eine Anfrage von einem Client in einen ausführbaren Plan
- Die Daten werden gefunden, die zur Beantwortung der Anfrage erforderlich sind.
- Führt alle erforderlichen Filter-, Sortier- und Aggregationsvorgänge aus.
- Gibt die Ergebnisse an den Client zurück
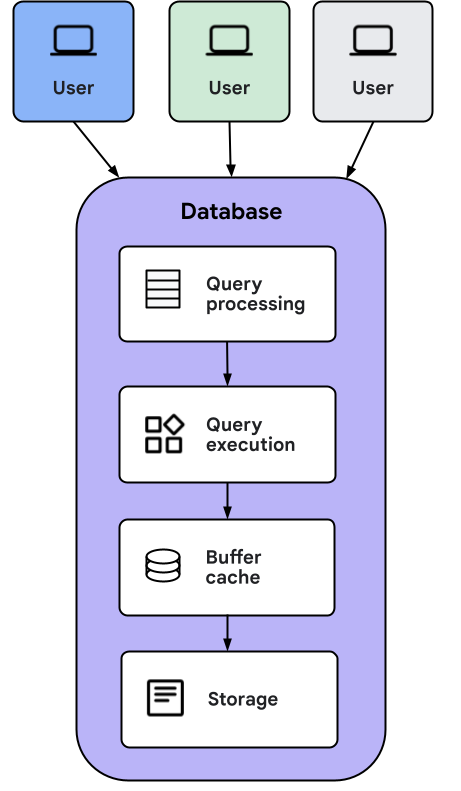
Wenn die Clientanwendung eine Anfrage an AlloyDB Omni sendet, passiert Folgendes:
- In der Ebene für die Abfrageverarbeitung wird die Abfrage in einen Ausführungsplan umgewandelt, der an die Ebene für die Abfrageausführung gesendet wird.
- In der Ebene für die Ausführung von Abfragen werden die Vorgänge ausgeführt, die zum Berechnen der Antwort auf die Abfrage erforderlich sind.
- Während der Ausführung können Daten aus dem Puffer-Cache oder direkt aus dem Speicher geladen werden. Wenn die Daten aus dem Speicher geladen werden, werden sie für die zukünftige Verwendung im Cache gespeichert.
Zu den Ressourcen, die bei der Verarbeitung der Anfrage des Clients verwendet werden, gehören CPU, Arbeitsspeicher, E/A, Netzwerk und Synchronisierungspunkte wie Datenbanksperren. Bei der Leistungsoptimierung soll die Ressourcennutzung in jedem Schritt der Abfrageausführung optimiert werden.
Das Ziel einer leistungsstarken Datenbank-Engine ist es, auf eine Abfrage mit den geringstmöglichen Ressourcen zu reagieren. Dazu sind ein gutes Datenmodell und ein gutes Abfragedesign erforderlich.
- Wie können Abfragen beantwortet werden, ohne dass auf zu viele Daten zugegriffen werden muss?
- Welche Indexe sind erforderlich, um den Suchraum und die E/A zu reduzieren?
- Zum Sortieren von Daten sind CPU- und bei großen Datasets häufig auch Festplattenzugriffe erforderlich. Wie lässt sich das Sortieren von Daten vermeiden?
Datenspeicher
In AlloyDB Omni werden Daten auf Seiten mit fester Größe gespeichert, die im zugrunde liegenden Dateisystem gespeichert werden. Wenn für eine Abfrage auf Daten zugegriffen werden muss, prüft AlloyDB Omni zuerst den Pufferpool. Wenn die Seite(n) mit den erforderlichen Daten nicht im Pufferpool gefunden werden, liest AlloyDB Omni die erforderlichen Seiten aus dem Dateisystem. Der Zugriff auf Daten aus dem Pufferpool ist deutlich schneller als das Lesen aus dem Dateisystem. Daher ist es wichtig, die Größe des Pufferpools für die Datenmenge zu maximieren, auf die eine Anwendung zugreift.
Ressourcenverwaltung
AlloyDB Omni verwendet dynamische Arbeitsspeicherverwaltung, damit der Pufferpool je nach Arbeitsspeicheranforderungen des Systems dynamisch innerhalb der konfigurierten Grenzen wachsen und schrumpfen kann. Daher ist es nicht erforderlich, die Größe des Pufferpools anzupassen. Bei der Diagnose von Leistungsproblemen sollten Sie zuerst die Trefferrate des Pufferpools und die Leseraten berücksichtigen, um festzustellen, ob Ihre Anwendung vom Pufferpool profitiert. Wenn nicht, bedeutet das, dass der Datensatz der Anwendung nicht in den Pufferpool passt. Sie sollten dann in Erwägung ziehen, die Größe der Maschine zu ändern und eine größere Maschine mit mehr Speicher zu verwenden.
Für das Abrufen, Filtern, Aggregieren, Sortieren und Projizieren von Daten sind CPU-Ressourcen auf dem Datenbankserver erforderlich. Um die für diesen Prozess erforderliche Menge an CPU-Ressourcen zu reduzieren, sollten Sie die Menge der Daten minimieren, die bearbeitet werden müssen. Überwachen Sie die CPU-Auslastung auf dem Datenbankserver, um sicherzustellen, dass die Auslastung im Steady State bei etwa 70 % liegt. Dieser Betrag lässt genügend Spielraum auf dem Server für Spitzen in der Auslastung oder Änderungen bei den Zugriffsmustern im Laufe der Zeit. Wenn die Auslastung sich 100% nähert, entsteht durch die Prozessplanung und den Kontextwechsel zusätzlicher Aufwand. Außerdem können Engpässe in anderen Teilen des Systems auftreten. Eine hohe CPU-Auslastung ist ein weiterer wichtiger Messwert, der bei Entscheidungen über Maschinenspezifikationen berücksichtigt werden sollte.
Eingabe-/Ausgabevorgänge pro Sekunde (IOPS) sind ein wichtiger Faktor für die Leistung von Datenbankanwendungen. Sie geben an, wie viele Eingabe- oder Ausgabevorgänge pro Sekunde das zugrunde liegende Speichergerät für die Datenbank ausführen kann. Um die IOPS-Grenzwerte des Datenbankspeichers nicht zu überschreiten, sollten Sie die Lese- und Schreibvorgänge für den Speicher minimieren, indem Sie die Datenmenge maximieren, die in den Pufferpool passt.
Spaltenbasierte Engine
Die spaltenbasierte Engine beschleunigt die Verarbeitung von SQL-Abfrage für Scans, Joins und Aggregate durch die folgenden Komponenten:
Spaltenorientierter In-Memory-Speicher: Enthält Tabellen- und materialisierte Ansichtsdaten für ausgewählte Spalten in einem spaltenorientierten Format. Standardmäßig belegt der Spaltenspeicher 1 GB des verfügbaren Arbeitsspeichers. Wenn Sie die Menge an Arbeitsspeicher ändern möchten, die vom Spaltenspeicher verwendet werden kann, legen Sie den Parameter
google_columnar_engine.memory_size_in_mbin derpostgresql.conffest, die von Ihrer AlloyDB Omni-Instanz verwendet wird.Weitere Informationen zum Ändern des Parameters finden Sie unter Konfigurationsparameter ändern.
Spaltenbasierte Abfrageplanung und Ausführungs-Engine: Unterstützt die Verwendung des Spaltenspeichers in Abfragen.
Automatische Speicherverwaltung
Der automatische Speichermanager überwacht und optimiert den Speicherverbrauch einer gesamten AlloyDB Omni-Instanz kontinuierlich. Wenn Sie Ihre Arbeitslasten ausführen, passt dieses Modul die Größe des gemeinsam genutzten Puffer-Cache basierend auf dem Arbeitsspeicherbedarf an. Standardmäßig legt der automatische Arbeitsspeicher-Manager die Obergrenze auf 80 % des Systemspeichers fest und weist 10% des Systemspeichers für den Cache mit gemeinsam genutzten Puffern zu.
Wenn Sie die Obergrenze für die Größe des freigegebenen Puffer-Cache ändern möchten, legen Sie den Parameter shared_buffers in der postgresql.conf fest, die von Ihrer AlloyDB Omni-Instanz verwendet wird.
Weitere Informationen finden Sie unter Automatische Speicherverwaltung.
Adaptives Autovakuum
Das adaptive Autovakuum analysiert Vorgänge basierend auf der Arbeitslast der Datenbank und passt die Häufigkeit des Staubsaugens automatisch an. Durch diese automatische Anpassung kann die Datenbank mit maximaler Leistung ausgeführt werden, auch wenn sich die Arbeitslast ändert, ohne dass der VACUUM-Prozess eingreift.
Adaptive Autovacuum verwendet die folgenden Faktoren, um die Häufigkeit und Intensität von Vacuum-Vorgängen zu bestimmen:
- Größe der Datenbank
- Anzahl der fehlerhaften Tupel in der Datenbank
- Alter der Daten in der Datenbank
- Anzahl der Transaktionen pro Sekunde im Vergleich zur geschätzten VACUUM-Geschwindigkeit
Das adaptive Autovacuum bietet folgende Vorteile:
- Dynamische Verwaltung von VACUUM-Ressourcen: Anstelle eines festen Kostenlimits verwendet AlloyDB Omni Echtzeit-Ressourcenstatistiken, um die VACUUM-Worker anzupassen. Wenn das System ausgelastet ist, werden der Vakuumprozess und die zugehörige Ressourcennutzung gedrosselt. Wenn genügend Arbeitsspeicher verfügbar ist, wird zusätzlicher Arbeitsspeicher für
maintenance_work_memzugewiesen, um die End-to-End-Vakuumzeit zu verkürzen. - Dynamisches XID-Throttling: Der Fortschritt des Staubsaugens und die Geschwindigkeit des Verbrauchs von Transaktions-IDs werden automatisch und kontinuierlich überwacht. Wenn das Risiko eines Transaktions-ID-Wraparounds erkannt wird, verlangsamt AlloyDB Omni Transaktionen, um die ID-Nutzung zu drosseln. Außerdem weist AlloyDB Omni den Vacuum-Workern mehr Ressourcen zu, um die Tabellen zu verarbeiten, die das Vorrücken und Freigeben des Transaktions-ID-Bereichs blockieren. Während dieses Vorgangs wird die Gesamtzahl der Transaktionen pro Sekunde reduziert, bis die Transaktions-IDs in einem sicheren Bereich sind (beobachtbar als Sitzungen, die auf
AdaptiveVacuumNewXidDelaywarten). Wenn das Alter der Transaktions-ID zunimmt, wird die Anzahl der Vacuum-Worker dynamisch erhöht. - Effizientes Bereinigen für größere Tabellen: Die standardmäßige PostgreSQL-Logik, die entscheidet, wann eine Tabelle bereinigt werden soll, basiert auf tabellenspezifischen Statistiken, die in
pg_stat_all_tablesgespeichert sind. Diese enthalten das Verhältnis von inaktiven Tupeln. Diese Logik funktioniert für kleine Tabellen, ist aber möglicherweise nicht effizient für größere, häufig aktualisierte Tabellen. AlloyDB Omni bietet einen aktualisierten Scanmechanismus, der dazu beiträgt, dass Autovacuum häufiger ausgelöst wird. Bei diesem Scanmechanismus werden Teile großer Tabellen gescannt und inaktive Tupel effizienter entfernt als bei der standardmäßigen PostgreSQL-Logik. - Warnmeldungen protokollieren: In AlloyDB Omni werden VACUUM-Blocker wie lang andauernde Transaktionen, vorbereitete Transaktionen oder Replikations-Slots, deren Ziele verloren gegangen sind, erkannt und Warnungen werden in den PostgreSQL-Logs registriert, damit Sie Probleme rechtzeitig beheben können.
KI-/ML-Worker
In AlloyDB Omni bietet der AI/ML-Hintergrundworker alle Funktionen, die zum direkten Aufrufen von Vertex AI-Modellen aus der Datenbank erforderlich sind. Der KI/ML-Worker wird als Prozess mit dem Namen omni ml worker ausgeführt.
Weitere Informationen finden Sie unter Generative KI-Anwendungen mit AlloyDB AI erstellen.
Nächste Schritte
- Weitere Informationen zu Download- und Installationsoptionen für AlloyDB Omni
- Führen Sie eine Kurzanleitung aus, um AlloyDB Omni auf einer VM zu installieren.
- Führen Sie eine Einzelinstanzinstallation von AlloyDB Omni auf einer beliebigen Linux-VM durch.
- Informationen zum Installieren von AlloyDB Omni auf Kubernetes