如果在云端训练模型或获取预测结果时发生错误,找出错误的原因很不容易。本页面介绍如何查找和调试在 AI Platform Training 中遇到的问题。如果您在使用机器学习框架时遇到问题,请参阅机器学习框架的文档。
命令行工具
ERROR: (gcloud) Invalid choice: 'ai-platform'.此错误意味着您需要更新 gcloud。如需更新 gcloud,请运行以下命令:
gcloud components updateERROR: (gcloud) unrecognized arguments: --framework=SCIKIT_LEARN.此错误意味着您需要更新 gcloud。如需更新 gcloud,请运行以下命令:
gcloud components updateERROR: (gcloud) unrecognized arguments: --framework=XGBOOST.此错误意味着您需要更新 gcloud。如需更新 gcloud,请运行以下命令:
gcloud components updateERROR: (gcloud) Failed to load model: Could not load the model: /tmp/model/0001/model.pkl. '\\x03'. (Error code: 0)此错误意味着使用了错误的库来导出模型。如需更正此问题,请使用正确的库重新导出模型。例如,使用
pickle库导出model.pkl格式的模型,而使用joblib库导出model.joblib格式的模型。ERROR: (gcloud.ai-platform.jobs.submit.prediction) argument --data-format: Invalid choice: 'json'.此错误表示您在提交批量预测作业时,将
json指定为--data-format标志的值。如需使用JSON数据格式,您必须提供text作为--data-format标志的值。
Python 版本
ERROR: Bad model detected with error: "Failed to load model: Could not load the
model: /tmp/model/0001/model.pkl. unsupported pickle protocol: 3. Please make
sure the model was exported using python 2. Otherwise, please specify the
correct 'python_version' parameter when deploying the model. Currently,
'python_version' accepts 2.7 and 3.5. (Error code: 0)"
此错误意味着使用 Python 3 导出的模型文件部署到了使用 Python 2.7 设置的 AI Platform Training 模型版本资源中。
如需解决此问题,请执行以下操作:
- 创建一个新的模型版本资源,并将“python_version”设置为 3.5。
- 将相同的模型文件部署到新的模型版本资源中。
找不到 virtualenv 命令
如果您在尝试激活 virtualenv 时遇到此错误,一种可行的解决方案是将包含 virtualenv 的目录添加到 $PATH 环境变量中。修改此变量可让您在使用 virtualenv 命令时无需键入其完整文件路径。
首先,通过运行以下命令来安装 virtualenv:
pip install --user --upgrade virtualenv
安装程序会提示您修改 $PATH 环境变量,并提供 virtualenv 脚本的路径。在 macOS 上,这类似于 /Users/[YOUR-USERNAME]/Library/Python/[YOUR-PYTHON-VERSION]/bin。
打开 shell 加载环境变量的文件。通常,在 macOS 中,相应的文件为 ~/.bashrc 或 ~/.bash_profile。
添加以下行,并将 [VALUES-IN-BRACKETS] 替换为适当的值:
export PATH=$PATH:/Users/[YOUR-USERNAME]/Library/Python/[YOUR-PYTHON-VERSION]/bin
最后,运行以下命令加载更新的 .bashrc(或 .bash_profile)文件:
source ~/.bashrc
使用作业日志
如需进行问题排查,最好先查看 Cloud Logging 收集的作业日志。
不同类型操作的日志
您的日志记录因操作类型而异,如以下部分所示。
训练日志
系统会记录所有训练作业。由此生成的日志包括来自训练服务和训练应用的事件。 您可以使用标准 Python 库(例如,日志记录)将日志记录事件放入应用中。AI Platform Training 会收集应用中的所有日志消息。然后,这些消息会发送到 stderr,并由 Cloud Logging 中的作业条目自动收集。
批量预测日志
系统会记录所有批量预测作业。
在线预测日志
默认情况下,您的在线预测请求不会生成日志。您可以在创建模型资源时启用 Cloud Logging:
gcloud
在运行 gcloud ai-platform models create 时添加 --enable-logging 标志。
Python
在用于调用 projects.models.create 的 Model 资源中,将 onlinePredictionLogging 设置为 True。
查找日志
您的作业日志包含您的操作引发的所有事件,包括使用分布式训练时集群中所有进程的事件。如果您正在运行分布式训练作业,则会报告主工作器进程的作业级日志。因此,如果发生错误,则对其进行问题排查的第一步通常是检查该进程的日志,以此来过滤掉集群中其他进程的已记录事件。本节中的示例显示了具体的过滤流程。
您可以通过命令行或 Google Cloud Console 的“Cloud Logging”部分过滤日志。无论采用何种方式,请根据需要在过滤条件中使用以下元数据值:
| 元数据项 | 过滤以显示符合以下条件的内容… |
|---|---|
| resource.type | 等于“cloud_ml_job”。 |
| resource.labels.job_id | 等于作业名称。 |
| resource.labels.task_name | 等于“master-replica-0”,以便仅读取主工作器的日志条目。 |
| 严重程度 | 大于或等于 ERROR(错误),以便仅读取与错误情况对应的日志条目。 |
命令行
使用 gcloud beta logging read 构建满足需求的查询。以下是一些示例:
每个示例都依赖于以下环境变量:
PROJECT="my-project-name"
JOB="my_job_name"
如果您愿意,也可以在需要的地方直接输入字符串字面量。
如需将作业日志输出到屏幕,请运行以下命令:
gcloud ai-platform jobs stream-logs $JOB
查看 gcloud ai-platform jobs stream-logs 的所有选项。
如需将主工作器的日志输出到屏幕,请运行以下命令:
gcloud beta logging read --project=${PROJECT} "resource.type=\"ml_job\" and resource.labels.job_id=${JOB} and resource.labels.task_name=\"master-replica-0\""
如需仅将主工作器的错误日志输出到屏幕,请运行以下命令:
gcloud beta logging read --project=${PROJECT} "resource.type=\"ml_job\" and resource.labels.job_id=${JOB} and resource.labels.task_name=\"master-replica-0\" and severity>=ERROR"
上述示例代表了对 AI Platform Training 训练作业的日志进行过滤的最常见情况。Cloud Logging 提供了许多强大的过滤选项,供您在需要优化搜索时使用。高级过滤文档详细描述了这些选项。
控制台
在 Google Cloud 控制台中打开 AI Platform Training 作业页面。
从作业页面的列表中选择失败的作业,以查看其详情。

- 点击查看日志,打开 Cloud Logging。
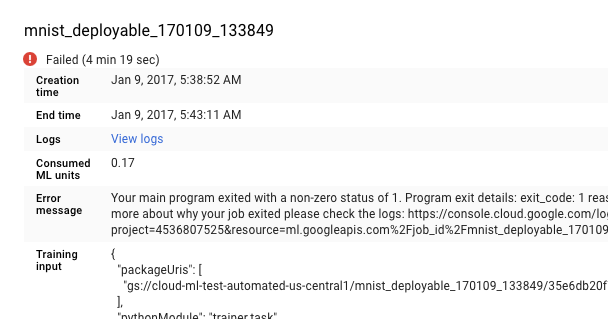
您也可以直接进入 Cloud Logging,但是这样您还要执行以下操作才能查找自己的作业:
- 展开资源选择器。
- 在资源列表中展开 Cloud ML 作业。
- 在 job_id 列表中找到作业名称(您可以在搜索框中输入作业名称的前几个字母以减少显示的作业数)。
- 展开作业条目,然后从任务列表中选择
master-replica-0。
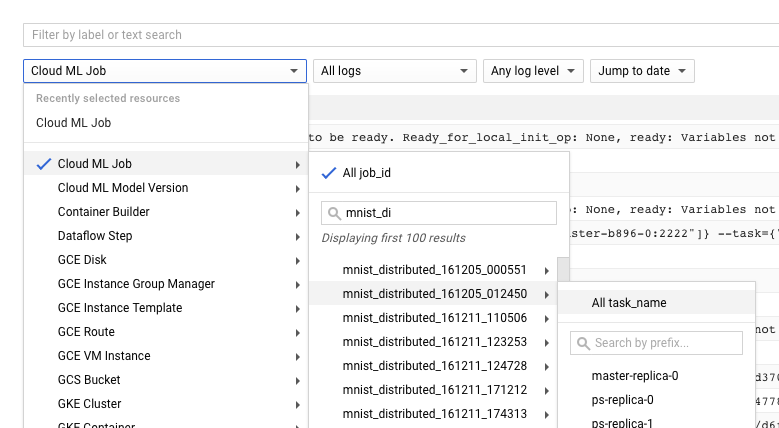
从日志中获取信息
找到作业的正确日志并将其过滤到 master-replica-0 后,您可以检查记录的事件以找到问题的根源。这涉及标准的 Python 调试过程,请谨记以下事项:
- 事件具有多个严重性级别。您可以过滤事件,以仅查看特定级别的事件,例如错误,或错误和警告。
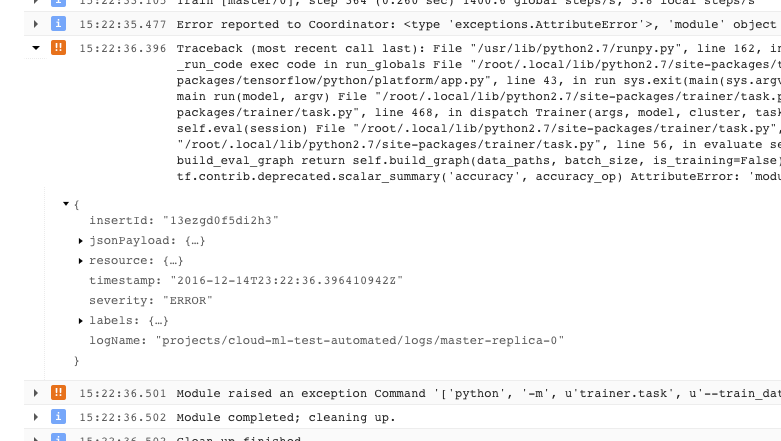
- 导致训练程序退出且显示不可恢复的错误情况(返回代码 > 0)的问题会记录一次异常(显示在堆栈轨迹的前面):
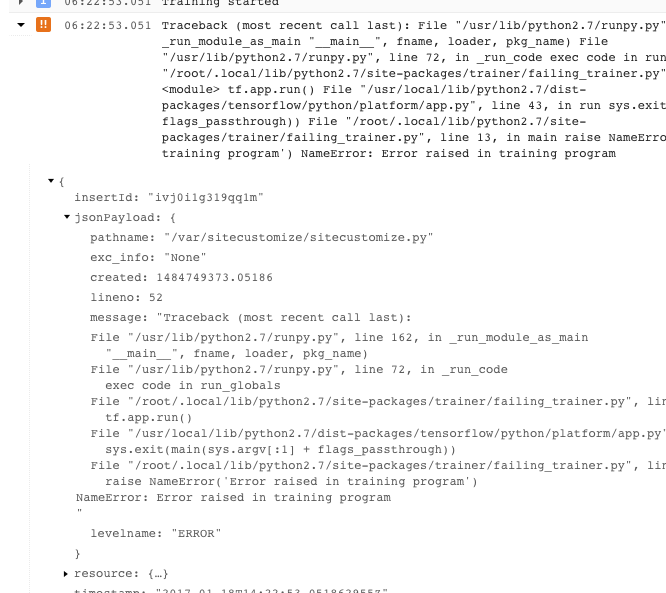
- 如需获取更多信息,您可以展开已记录的 JSON 消息中的对象(由右向箭头和列为 {...} 的内容表示)。例如,您可以展开 jsonPayload 以查看堆栈轨迹,与查看主要错误说明的方式相比,这种方式更加直观:
- 某些错误显示了可重试错误的实例。这些实例通常不包含堆栈轨迹,并且可能更难诊断。
充分利用日志记录
AI Platform Training 训练服务自动记录以下事件:
- 服务内部的状态信息。
- 您的训练程序应用发送给
stderr的消息。 - 您的训练程序应用发送给
stdout的输出文本。
遵循良好的编程做法,您可以更轻松地对训练程序应用中的错误进行问题排查:
- 将有意义的消息发送到 stderr(例如,使用日志记录)。
- 当出现问题时,找出最合乎逻辑的描述性异常。
- 向异常对象添加描述性字符串。
如需了解异常的更多信息,请参阅 Python 文档。
对训练进行问题排查
本节介绍适用于训练作业的概念和错误条件。
了解训练应用返回代码
您在云端的训练作业由训练集群的主工作器进程上运行的主程序控制:
- 如果您在单个进程(非分布式)中进行训练,则只有一个工作器,即主实例工作器。
- 您的主程序是 TensorFlow 训练应用的
__main__函数。 - AI Platform Training 的训练服务运行您的训练程序应用,直到该应用成功完成或遇到不可恢复的错误。这意味着,如果出现可重试的错误,则训练程序应用可能会重启进程。
训练服务负责管理您的进程,它根据主工作器进程的返回代码来处理程序退出事件:
| 返回代码 | 含义 | AI Platform Training 响应 |
|---|---|---|
| 0 | 成功完成 | 关闭并释放作业资源。 |
| 1 - 128 | 不可恢复的错误 | 结束作业并记录错误。 |
您无需执行任何操作,尤其是对于 __main__ 函数的返回代码。Python 会在进程成功完成时自动返回零,并在进程遇到未处理的异常时返回正代码。如果您习惯于将特定的返回代码设置到异常对象中(一种可行但不常见的做法),则只要您遵循上表中的模式,就不会干扰您的 AI Platform Training 作业。即便如此,客户端代码通常也不会直接指示可重试的错误,因为这些错误来自操作环境。
处理特定的错误条件
本部分提供有关已知会影响某些用户的某些错误条件的指导。
资源已用完
在 us-central1 区域中,对 GPU 和计算资源的需求很高。您可能会在作业日志中看到一条错误消息,该消息显示 Resources are
insufficient in region: <region>. Please try a different region.。
如需解决此问题,请尝试使用其他区域或稍后重试。
训练程序一直在运行,但没有任何进展
某些情况可能导致您的训练应用连续运行,但训练任务却没有任何进展。这可能是由于阻塞调用等待一直不可用的资源引起的。您可以通过在训练程序中配置超时间隔来缓解此问题。
为训练程序配置超时间隔
您可以在创建会话时或运行图的步骤时设置超时(以毫秒为单位),具体方法如下所示:
在创建 Session 对象时,使用 config 参数设置所需的超时间隔:
sess = tf.Session(config=tf.ConfigProto(operation_timeout_in_ms=500))使用 options 参数为 Session.run 的单个调用设置所需的超时间隔:
v = session.run(fetches, options=tf.RunOptions(timeout_in_ms=500))
如需了解详情,请参阅 TensorFlow Session 文档。
程序退出并返回 -9 的代码
如果您始终获得 -9 的退出代码,则您的训练应用使用的内存可能超过为其进程分配的内存。通过减少内存使用量以及/或者使用具有更多内存的机器类型,可以改正此错误。
- 检查您的图和训练程序应用,找出使用比预期更多内存的操作。内存使用量受数据复杂性以及计算图中操作复杂性的影响。
- 如果要增加分配给作业的内存,可能需要使用一些技巧:
- 如果您使用的是定义的容量层级,则无法在不添加更多机器的情况下增加每个机器的内存分配。您需要切换到自定义层级并自行定义集群中的机器类型。
- 每种定义的机器类型的精确配置会随时变化,但您可以进行一些粗略的比较。您可以在训练概念页面找到机器类型的比较表。
- 在测试机器类型以查看内存分配是否适当时,您可以使用单台机器或规模较小的集群来最大限度地缩减开支。
程序退出并返回 -15 的代码
通常,系统返回 -15 退出代码表示系统正在维护。这是一个可重试的错误,因此您的进程此时应该自动重启。
作业排队时间很长
如果训练作业的状态是 QUEUED 并且持续时间过长,则您可能超出了作业请求的配额。
AI Platform Training 使用先进先出规则,根据作业创建时间启动训练作业。如果您的作业正在排队,通常意味着所有项目配额都被在该作业之前提交的其他作业占用,或者队列中的第一个作业请求的机器学习单位/GPU 大于可用配额。
系统会将作业排队的原因记录在训练日志中。 请在日志中搜索类似于以下内容的消息,以查看排队原因:
This job is number 2 in the queue and requires
4.000000 ML units and 0 GPUs. The project is using 4.000000 ML units out of 4
allowed and 0 GPUs out of 10 allowed.该消息说明了作业在队列中的当前位置,以及项目的当前使用量和配额。
请注意,系统仅会按作业创建时间记录前十个作业的排队原因。
如果您经常需要提出超过分配数量的请求,则可以请求增加配额。如果您有 Premium 支持包,请联系支持部。否则,您可以通过电子邮件将您的请求发送给 AI Platform Training 反馈部门。
超出配额
如果您收到类似于“project_number 的配额不足:...”的错误消息,则您可能已超出其中一个资源配额。在控制台的 API 管理器中的 AI Platform Training 配额页面上,您可以监控资源消耗情况,还可以请求增加资源。
保存路径无效
如果您的作业退出并显示包含“使用无效保存路径 gs:// ... 调用 restore”的错误消息,则表示您可能正在使用配置不正确的 Google Cloud Storage 存储分区。
在 Google Cloud 控制台中打开 Google Cloud Storage 浏览器页面。
检查您正在使用的存储分区的默认存储类:
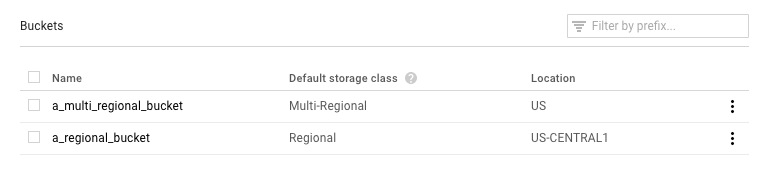
- 正确的选择应该是区域。如果是,那么就可以归结为出现其他问题。请尝试再次运行您的作业。
- 如果选择了多区域,则需要将其更改为区域,或将训练内容移至其他存储分区。对于前者,请在 Cloud Storage 文档中查找有关更改存储分区的存储类别的说明。
训练程序退出并返回 AbortedError
如果您正在运行使用 TensorFlow Supervisor 管理分布式作业的训练程序,则会出现此错误。TensorFlow 有时会在您不应停止整个作业的情况下抛出 AbortedError 异常。您可以在您的训练程序中捕获该异常并作出相应的响应。请注意,使用 AI Platform Training 运行的训练程序不支持 TensorFlow Supervisor。
排查预测问题
本部分收集了获取预测结果时遇到的一些常见问题。
处理在线预测的特定条件
本部分提供指导,帮助您了解一些已知会影响某些用户的在线预测错误情况。
完成预测所需的时间太长(30-180 秒)
在线预测太慢最常见的原因是从零开始调节处理节点数。如果您的模型会定期收到预测请求,则系统会准备好一个或多个节点以处理预测。如果您的模型长时间未处理任何预测,则该服务会将就绪节点数“下调”到零。此下调操作之后的下一个预测请求将比平时花费更多的时间来返回,因为服务必须预配节点才能处理请求。
HTTP 状态代码
如果在线预测请求发生错误,您通常会收到服务返回的 HTTP 状态代码。以下列出了一些常见的代码及其在在线预测上下文中的含义:
- 429 - 内存不足
运行模型时,处理节点内存不足。此时无法增加分配给预测节点的内存。但您可以尝试以下操作来运行模型:
- 通过以下方式缩小模型大小:
- 使用降低精确率的变量。
- 量化连续数据。
- 缩小其他输入特征的大小(例如,减少使用的词汇量)。
- 使用较小批量的实例,再次发送请求。
- 通过以下方式缩小模型大小:
- 429 - 待处理的请求太多
您的模型收到的请求数量超出其处理能力。如果您使用自动调节,则收到请求的速度要快于系统扩展的速度。
通过自动调节,您可以尝试使用指数退避算法来重新发送请求。 这样做可以给系统更多时间进行调整。
- 429 - 配额
您的 Google Cloud Platform 项目每 100 秒只能处理 10000 个请求(大约每秒 100 个)。如果您在短暂峰值中收到此错误,则通常可以使用指数退避算法进行重试,及时处理所有请求。如果您一直收到此代码,则可以请求增加配额。如需了解详情,请参阅配额页面。
- 503 - 我们的系统检测到您的计算机网络发出异常的流量
您的模型从单个 IP 收到请求的频率非常高,以致于系统怀疑遇到了拒绝服务攻击。停止发送请求一分钟,然后继续以较低的频率发送请求。
- 500 - 无法加载模型
系统无法加载您的模型。请尝试按照以下步骤操作:
- 确保训练程序正在导出正确的模型。
- 使用
gcloud ai-platform local predict命令尝试测试预测。 - 再次导出模型并重试。
预测请求中的格式化错误
以下消息都与您的预测输入有关。
- “请求正文中出现空白或格式错误/无效的 JSON”
- 该服务无法解析请求中的 JSON,或者您的请求为空。请检查您的消息,确认是否有使 JSON 无效的错误或遗漏。
- “请求正文中缺少‘实例’字段”
- 您的请求正文未遵循正确的格式。正常情况下,正文应该是一个包含名为
"instances"的单键的 JSON 对象,而此键包含所有输入实例的列表。 - 创建请求时出现 JSON 编码错误
您的请求中包含 base64 编码数据,但数据的 JSON 格式不正确。正常情况下,每个 base64 编码的字符串必须由一个包含名为
"b64"的单键的对象表示。例如:{"b64": "an_encoded_string"}当您有非 base64 编码的二进制数据时,会发生另一个 base64 错误。此时,请对数据进行编码并将其格式化如下:
{"b64": base64.b64encode(binary_data)}如需了解详细信息,请参阅格式化和编码二进制数据。
云端预测比桌面预测花费更长时间
在线预测设计为可扩缩服务,可以快速处理高速传入的预测请求。该服务针对处理所有服务请求的整合性能进行了优化。对可扩缩性的强调,导致其与在本地机器上生成少量预测有不同的性能特征。
后续步骤
- 获取支持。
- 详细了解 Google API 错误模型,尤其是
google.rpc.Code中定义的规范错误代码和 google/rpc/error_details.proto 中定义的标准错误详细信息。 - 了解如何监控您的训练作业。
- 请参阅 Cloud TPU 问题排查和常见问题解答,以便在使用 Cloud TPU 运行 AI Platform Training 时诊断和解决问题。