Después de entrenar un modelo, AutoML Translation usa elementos del conjunto TEST para evaluar la calidad y exactitud del modelo nuevo. AutoML Translation expresa la calidad del modelo mediante su puntuación BLEU (Subcomité de evaluación bilingüe), que indica el grado de similitud del texto candidato con respecto a los textos de referencia, con valores cercanos a uno que representa textos más similares.
La puntuación BLEU proporciona una evaluación general de la calidad del modelo. También puedes evaluar la salida del modelo para elementos de datos específicos mediante la exportación del conjunto de PRUEBA con las predicciones del modelo. Los datos exportados incluyen el texto de referencia (del conjunto de datos original) y el texto candidato del modelo.
Usa estos datos para evaluar la preparación de tu modelo. Si no estás satisfecho con el nivel de calidad, considera agregar más pares de oraciones de entrenamiento (y más diversos). Una opción es agregar más pares de oraciones. Usa el vínculo Agregar archivos en la barra de título. Una vez que agregaste archivos, entrena un modelo nuevo; para eso, haz clic en el botón Entrenar modelo nuevo en la página Entrenar. Repite este proceso hasta que alcances un nivel de calidad lo suficientemente alto.
Obtener la evaluación del modelo
IU web
Abre la IU de AutoML Translation y haz clic en el ícono de la bombilla junto a Modelos en la barra de navegación izquierda. Se muestran los modelos disponibles. Para cada modelo, se incluye la siguiente información: Conjunto de datos (Dataset), a partir del cual se entrenó el modelo; Idioma fuente (Source); Idioma objetivo (Target); Modelo base (Base model), que se usa para entrenar el modelo.
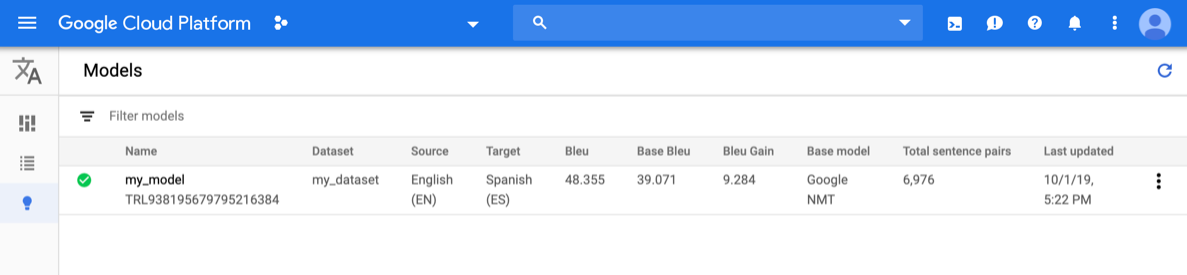
Para ver los modelos de un proyecto diferente, selecciónalo de la lista desplegable en la parte superior derecha de la barra de título.
Haz clic en la fila del modelo que deseas evaluar.
Se abrirá la pestaña Predecir (Predict).
Aquí, puedes probar tu modelo y ver los resultados tanto del modelo personalizado como del modelo base con el que entrenabas.
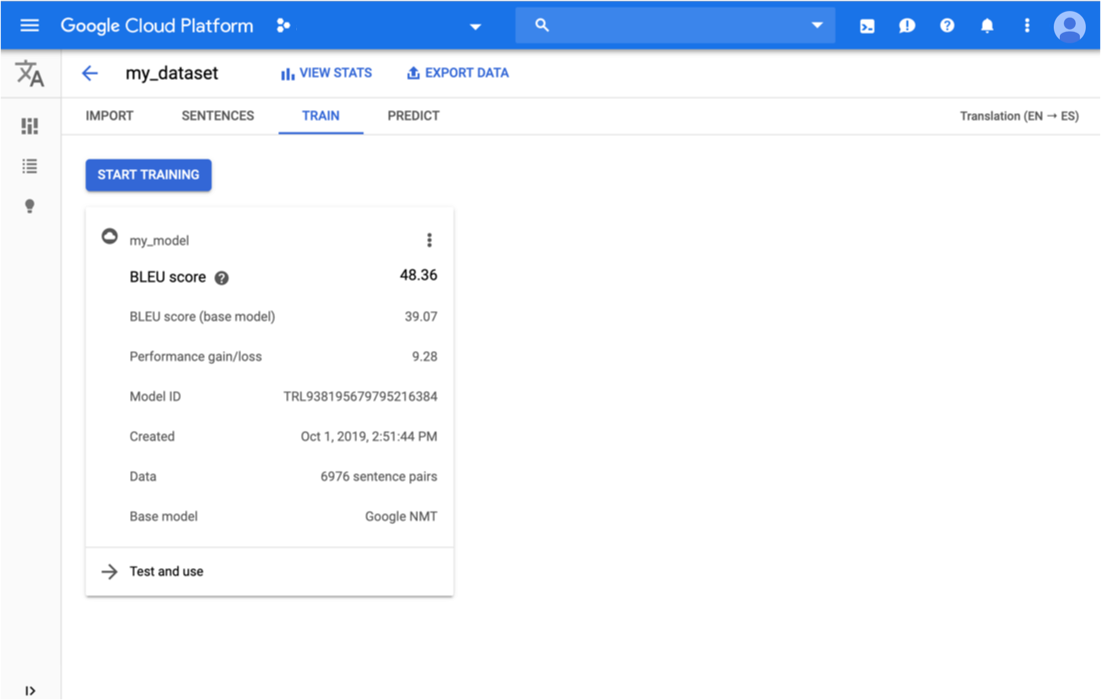
Haz clic en la pestaña Entrenar (Train) justo debajo de la barra de título.
Cuando se completa el entrenamiento del modelo, AutoML Translation muestra sus métricas de evaluación.
REST
Antes de usar cualquiera de los datos de solicitud a continuación, realiza los siguientes reemplazos:
- model-name: el nombre completo de tu modelo. Incluye el nombre y la ubicación del proyecto. El nombre de un modelo es similar al siguiente ejemplo:
projects/project-id/locations/us-central1/models/model-id. - project-id: el ID de tu proyecto de Google Cloud Platform
Método HTTP y URL:
GET https://automl.googleapis.com/v1/model-name/modelEvaluations
Para enviar tu solicitud, expande una de estas opciones:
Deberías recibir una respuesta JSON similar a la que se muestra a continuación:
{
"modelEvaluation": [
{
"name": "projects/project-number/locations/us-central1/models/model-id/modelEvaluations/evaluation-id",
"createTime": "2019-10-02T00:20:30.972732Z",
"evaluatedExampleCount": 872,
"translationEvaluationMetrics": {
"bleuScore": 48.355409502983093,
"baseBleuScore": 39.071375131607056
}
}
]
}
Go
Para obtener información sobre cómo instalar y usar la biblioteca cliente de AutoML Translation, consulta las bibliotecas cliente de AutoML Translation. Si quieres obtener más información, consulta la documentación de referencia de la API de AutoML Translation Go.
Para autenticarte en AutoML Translation, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Java
Para obtener información sobre cómo instalar y usar la biblioteca cliente de AutoML Translation, consulta las bibliotecas cliente de AutoML Translation. Si quieres obtener más información, consulta la documentación de referencia de la API de AutoML Translation Java.
Para autenticarte en AutoML Translation, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Node.js
Para obtener información sobre cómo instalar y usar la biblioteca cliente de AutoML Translation, consulta las bibliotecas cliente de AutoML Translation. Si quieres obtener más información, consulta la documentación de referencia de la API de AutoML Translation Node.js.
Para autenticarte en AutoML Translation, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Python
Para obtener información sobre cómo instalar y usar la biblioteca cliente de AutoML Translation, consulta las bibliotecas cliente de AutoML Translation. Si quieres obtener más información, consulta la documentación de referencia de la API de AutoML Translation Python.
Para autenticarte en AutoML Translation, configura las credenciales predeterminadas de la aplicación. Si deseas obtener más información, consulta Configura la autenticación para un entorno de desarrollo local.
Lenguajes adicionales
C#: Sigue las Instrucciones de configuración de C# en la página de bibliotecas cliente y, luego, visita la Documentación de referencia de AutoML Translation para .NET.
PHP: Sigue las Instrucciones de configuración de PHP en la página de bibliotecas cliente y, luego, visita la Documentación de referencia de AutoML Translation para PHP.
Ruby: Sigue las Instrucciones de configuración de Ruby en la página de bibliotecas cliente y, luego, visita la Documentación de referencia de AutoML Translation para Ruby.
Exporta datos de prueba con las predicciones de modelo
Después de entrenar un modelo, AutoML Translation usa elementos del conjunto TEST para evaluar la calidad y exactitud del modelo nuevo. Desde la consola de AutoML Translation, puedes exportar el conjunto TEST para ver cómo se compara el resultado del modelo con el texto de referencia del conjunto de datos original. AutoML Translation guarda un archivo TSV en tu bucket de Google Cloud Storage, donde cada fila tiene este formato:
Source sentence tab Reference translation tab Model candidate translation
IU web
Abre la página consola de AutoML Translation y haz clic en el ícono de la bombilla a la izquierda de “Modelos” en la barra de navegación izquierda para ver los modelos disponibles.
Para ver los modelos de un proyecto diferente, selecciónalo de la lista desplegable en la parte superior derecha de la barra de título.
Selecciona el modelo.
Haz clic en el botón Exportar datos en la barra de título.
Ingresa la ruta de acceso completa al bucket de Google Cloud Storage donde quieres guardar el archivo .tsv exportado.
Debes usar un bucket asociado con el proyecto actual.
Selecciona el modelo cuyos datos de PRUEBA quieres exportar.
La lista desplegable Conjunto de prueba con predicciones de modelo enumera los modelos entrenados mediante el mismo conjunto de datos de entrada.
Haz clic en Exportar.
AutoML Translation escribe un archivo llamado model-name
_evaluated.tsven el depósito de Google Cloud Storage especificado.
Evalúa y compara modelos mediante el uso de un conjunto de prueba nuevo
En la consola de AutoML Translation, puedes volver a evaluar los modelos existentes mediante un nuevo conjunto de datos de prueba. En una sola evaluación, puedes incluir hasta 5 modelos diferentes y, luego, comparar sus resultados.
Sube los datos de prueba a Cloud Storage como un archivo de valores separados por tabulaciones (.tsv) o como un archivo de Intercambio de memorias de traducción (.tmx).
AutoML Translation evalúa tus modelos con el conjunto de prueba y, luego, produce puntuaciones de evaluación. De forma opcional, puedes guardar los resultados para cada modelo como un archivo .tsv en un bucket de Cloud Storage, en el que cada fila tiene el siguiente formato:
Source sentence tab Model candidate translation tab Reference translation
IU web
Abre la consola de AutoML Translation y haz clic en Modelos en el panel de navegación izquierdo para ver los modelos disponibles.
Para ver los de un proyecto diferente, selecciónalo de la lista desplegable en la parte superior derecha de la barra de título.
Selecciona uno de los modelos que deseas evaluar.
Haz clic en la pestaña Evaluar que se encuentra justo debajo de la barra de título.
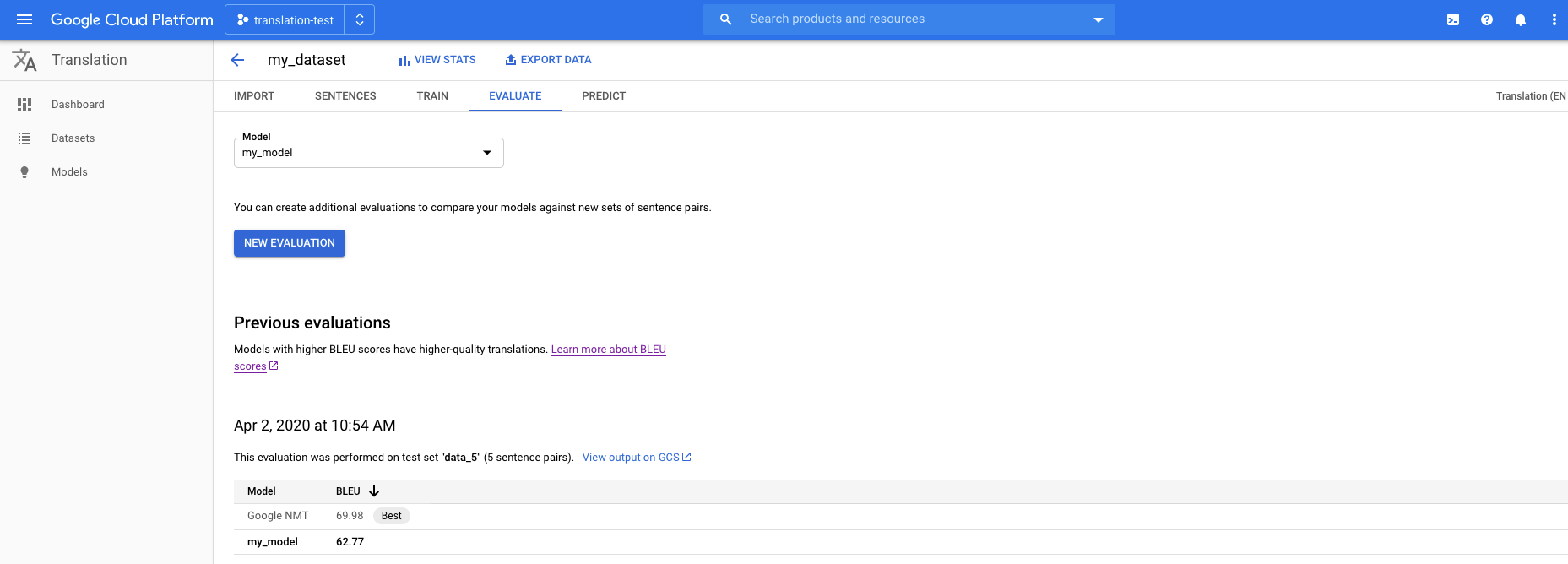
En la pestaña Evaluar, haz clic en Nueva evaluación.
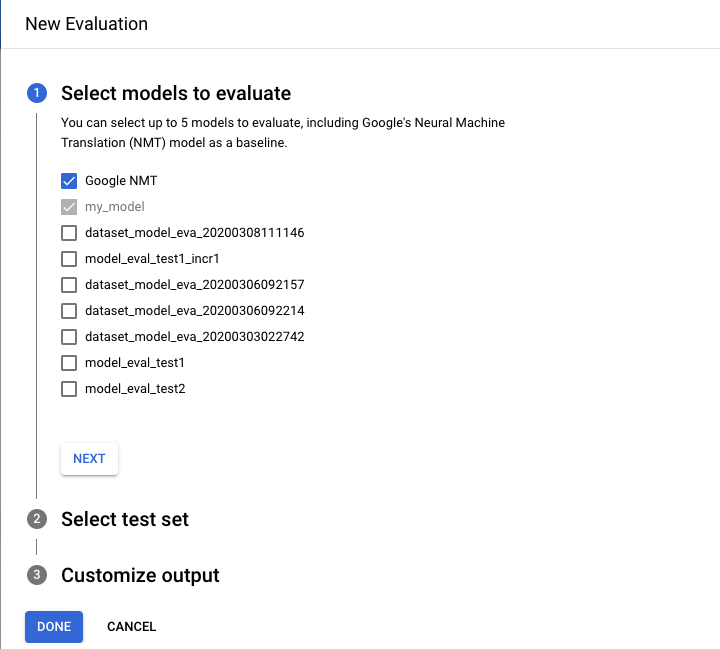
- Selecciona los modelos que deseas evaluar y comparar. Se debe seleccionar el modelo actual y Google NMT se selecciona de forma predeterminada; puedes anular esta selección.
- Especifica un nombre para el Nombre del conjunto de prueba a fin de distinguirlo de otras evaluaciones y, luego, selecciona el conjunto de prueba nuevo de Cloud Storage.
- Si deseas exportar las predicciones que se basan en tu conjunto de prueba, especifica un depósito de Cloud Storage en el que se almacenarán los resultados (se aplican precios estándar por tasa de caracteres).
Haz clic en Listo.
AutoML Translation presenta las puntuaciones de evaluación en un formato de tabla en la consola después de realizar la evaluación. Solo puede ejecutar una evaluación a la vez. Si especificaste un bucket para almacenar resultados de predicciones, AutoML Translation escribe archivos llamados model-name_test-set-name
.tsven el bucket.
Comprende la puntuación BLEU
BLEU (BiLingual Evaluation Understudy) es una métrica para evaluar de forma automática el texto traducido automáticamente. La puntuación BLEU es un número entre cero y uno que mide la similitud del texto traducido de manera automática con un conjunto de traducciones de referencia de alta calidad. Un valor de 0 significa que la traducción automática de salida no se superpone con la traducción de referencia (calidad baja), mientras que un valor de 1 significa que se superpone perfectamente con las traducciones de referencia (calidad alta).
Se ha demostrado que las puntuaciones BLEU se correlacionan adecuadamente con el criterio humano de la calidad de la traducción. Ten en cuenta que incluso los traductores humanos no logran la puntuación perfecta de 1.0.
AutoML expresa las puntuaciones BLEU como un porcentaje en vez de como un decimal entre 0 y 1.
Interpretación
No se recomienda intentar comparar las puntuaciones BLEU en diferentes idiomas y contenidos. Incluso la comparación de puntuaciones BLEU para el mismo contenido, pero con diferentes números de traducciones de referencia puede ser altamente engañosa.
Sin embargo, como una mera indicación, la siguiente interpretación de puntuaciones BLEU (expresadas como porcentajes antes de que como decimales) podría ser útil.
| Puntuación BLEU | Interpretación |
|---|---|
| < 10 | Casi inútil |
| 10 - 19 | Difícil de capar la esencia |
| 20 - 29 | La esencia es clara, pero tiene errores gramaticales significativos |
| 30 - 40 | Comprensible por buenas traducciones |
| 40 - 50 | Traducciones de alta calidad |
| 50 - 60 | Traducciones de calidad muy alta, adecuadas y fluidas |
| > 60 | Calidad generalmente mejor que la humana |
El gradiente de color a continuación se puede usar como una interpretación de la puntuación BLEU de escala general:

Los detalles matemáticos
Matemáticamente, la puntuación BLEU se define como:
con
\[ precision_i = \dfrac{\sum_{\text{snt}\in\text{Cand-Corpus}}\sum_{i\in\text{snt}}\min(m^i_{cand}, m^i_{ref})} {w_t^i = \sum_{\text{snt'}\in\text{Cand-Corpus}}\sum_{i'\in\text{snt'}} m^{i'}_{cand}} \]
En el ejemplo anterior, se ilustra lo siguiente:
- \(m_{cand}^i\hphantom{xi}\) es el recuento de i-grama en el candidato que coincide con la traducción de referencia.
- \(m_{ref}^i\hphantom{xxx}\) es la cantidad de i-gramas en la traducción de referencia.
- \(w_t^i\hphantom{m_{max}}\) es la cantidad total de i-gramas en la traducción candidata
La fórmula consta dos partes: la penalización por brevedad y la superposición de n-grama.
Penalización por brevedad
La penalización por brevedad penaliza las traducciones generadas que son demasiado cortas en comparación con la longitud de referencia más cercana con una disminución exponencial. La penalización por brevedad compensa el hecho de que la puntuación BLEU no tiene un término de recuperación.Superposición de n-grama
La superposición de n-grama cuenta cuántos unigramas, bigramas, trigramas y cuatro-gramas (i=1,…, 4 ) coinciden con su contraparte de n-grama en las traducciones de referencia. Este término actúa como una métrica de precisión. Los unigramas explican la adecuación, mientras que los n-gramas más largos explican la fluidez de la traducción. Para evitar el recuento excesivo, los recuentos del n-grama se acortan al recuento máximo del n-grama que aparece en la referencia (\(m_{ref}^n\)).
Ejemplos
Calculando \(precision_1\)
Considera esta oración de referencia y traducción candidata:
Referencia: the cat is on the mat
Candidato: the the the cat mat
El primer paso es contar las ocurrencias de cada unigrama en la referencia y en el candidato. Ten en cuenta que la métrica BLEU distingue mayúsculas de minúsculas.
| Unigrama | \(m_{cand}^i\hphantom{xi}\) | \(m_{ref}^i\hphantom{xxx}\) | \(\min(m^i_{cand}, m^i_{ref})\) |
|---|---|---|---|
the |
3 | 2 | 2 |
cat |
1 | 1 | 1 |
is |
0 | 1 | 0 |
on |
0 | 1 | 0 |
mat |
1 | 1 | 1 |
El número total de unigramas en el candidato (\(w_t^1\)) es 5, por lo que \(precision_1\) = (2 + 1 + 1)/5 = 0.8.
Calcula la puntuación BLEU
Referencia: The NASA Opportunity rover is battling a massive dust storm on Mars .
Candidato 1: The Opportunity rover is combating a big sandstorm on Mars .
Candidato 2: A NASA rover is fighting a massive storm on Mars .
El ejemplo anterior consta de una sola referencia y de dos traducciones candidatas. A las oraciones se le asignan tokens antes de calcular la puntuación BLEU como se muestra arriba; por ejemplo, el punto final se cuenta como un token separado.
Para calcular la puntuación BLEU de cada traducción, calculamos las estadísticas a continuación.
- Precisiones de N-grama
En la siguiente tabla, se muestran las precisiones de n-grama para ambos candidatos. - Penalización por brevedad
La penalización por brevedad es la misma para el candidato 1 y el candidato 2, ya que ambas oraciones constan de 11 tokens. - Puntuación BLEU
Ten en cuenta que se requiere al menos un 4-grama que coincida para obtener una puntuación BLEU > 0. Dado que la traducción candidata 1 no tiene un 4-grama equivalente, tiene una puntuación BLEU de 0.
| Métrica | Candidato 1 | Candidato 2 |
|---|---|---|
| \(precision_1\) (1grama) | 11/8 | 9/11 |
| \(precision_2\) (2grama) | 4/10 | 5/10 |
| \(precision_3\) (3grama) | 2/9 | 2/9 |
| \(precision_4\) (4grama) | 0/8 | 1/8 |
| Penalización por brevedad | 0.83 | 0.83 |
| Puntuación BLEU | 0.0 | 0.27 |
Propiedades
BLEU es una métrica basada en corpus
La métrica BLEU tiene un mal rendimiento cuando se usa para evaluar oraciones individuales. Por ejemplo, ambas oraciones de ejemplo obtienen puntuaciones BLEU muy bajas a pesar de que capturan la mayor parte del significado. Debido a que las estadísticas del n-grama para oraciones individuales son menos significativas, BLEU es por diseño una métrica basada en el contenido, es decir, las estadísticas se acumulan sobre todo el contenido cuando se calcula la puntuación. Ten en cuenta que la métrica BLEU que se definió antes no se puede factorizar para oraciones individuales.No hay distinción entre palabras de contenido y de función
La métrica BLEU no distingue entre palabras de contenido y función, es decir, una palabra de función omitida como “un” obtiene la misma penalización que si el nombre “NASA” se reemplazara de forma errónea por “ESA”.No es buena para captar el significado y la gramaticalidad de una oración
La eliminación de una sola palabra como “no” puede cambiar la polaridad de una oración. Además, si solo se tienen en cuenta los n-gramas con n≤4, se ignoran las dependencias de largo alcance y, por lo tanto, BLEU suele imponer solo una pequeña penalización para las oraciones no gramaticales.Normalización y asignación de token
Antes de calcular la puntuación BLEU, tanto la traducción candidata como la referencia se normalizan y se les asigna un token. La elección de los pasos de normalización y asignación de token afectan de manera significativa la puntuación BLEU final.