En este instructivo, se describe cómo realizar las siguientes acciones:
- Crea una VM de Cloud TPU para implementar la Llama 2 familia de modelos de lenguaje extensos (LLM), disponible en diferentes tamaños (7B, 13B o 70B)
- Preparación de puntos de control para los modelos e implementarlos en SAX
- Interactúa con el modelo a través de un extremo HTTP
La entrega para experimentos de AGI (SAX) es un sistema experimental que Paxml, JAX, y modelos PyTorch para inferencia. Código y documentación para SAX se encuentran en el repositorio de Git para saxml. La versión estable actual compatible con TPU v5e es v1.1.0.
Acerca de las celdas SAX
Una celda (o clúster) SAX es la unidad principal para entregar tus modelos. Consta de dos partes principales:
- Servidor de administración: Este servidor realiza un seguimiento de los servidores de modelos, asigna modelos a esos servidores de modelos y ayuda a los clientes a encontrar el servidor de modelos correcto para interactuar.
- Servidores de modelos: Estos servidores ejecutan el modelo. Ellos son responsables de procesar solicitudes entrantes y generar respuestas.
En el siguiente diagrama, se muestra el diagrama de una celda SAX:
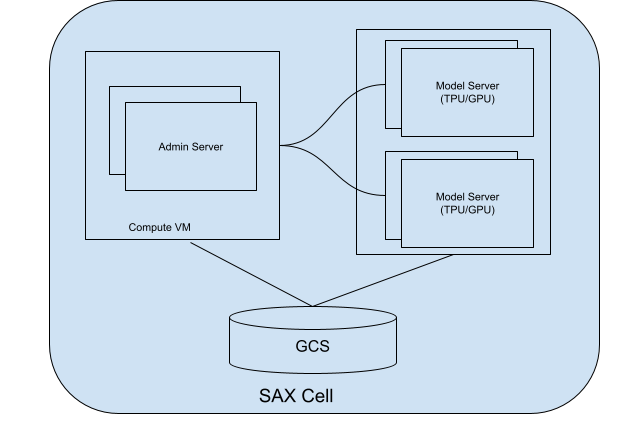
Figura 1. Celda SAX con servidor de administrador y servidor de modelos.
Puedes interactuar con una celda SAX mediante clientes escritos en Python, C++ o Go, o directamente a través de un servidor HTTP. En el siguiente diagrama, se muestra cómo se puede puede interactuar con una celda SAX:

Figura 2. Arquitectura del entorno de ejecución de un cliente externo que interactúa con un SAX de la celda.
Objetivos
- Configura recursos de TPU para la entrega
- Crea un clúster de SAX
- Publica el modelo de Llama 2
- Interactúa con el modelo
Costos
En este documento, usarás los siguientes componentes facturables de Google Cloud:
- Cloud TPU
- Compute Engine
- Cloud Storage
Para generar una estimación de costos en función del uso previsto, usa la calculadora de precios.
Antes de comenzar
Configura tu proyecto de Google Cloud, activa la API de Cloud TPU y crea una a través de las instrucciones en Configura la Cloud TPU entorno.
Crear una TPU
En los siguientes pasos, se muestra cómo crear una VM de TPU que entregará el modelo.
Crea variables de entorno:
export PROJECT_ID=PROJECT_ID export ACCELERATOR_TYPE=ACCELERATOR_TYPE export ZONE=ZONE export RUNTIME_VERSION=v2-alpha-tpuv5-lite export SERVICE_ACCOUNT=SERVICE_ACCOUNT export TPU_NAME=TPU_NAME export QUEUED_RESOURCE_ID=QUEUED_RESOURCE_ID
Descripciones de las variables de entorno
PROJECT_ID- El ID de tu proyecto de Google Cloud.
ACCELERATOR_TYPE- El tipo de acelerador especifica la versión y el tamaño del
y Cloud TPU que quieres crear. Los diferentes tamaños de modelos de Llama 2 tienen
diferentes requisitos de tamaño de TPU:
- 7B:
v5litepod-4o superior - 13B:
v5litepod-8o superior - 70B:
v5litepod-16o superior
- 7B:
ZONE- La zona en la que deseas crear tu Cloud TPU
SERVICE_ACCOUNT- La cuenta de servicio que deseas conectar a tu Cloud TPU.
TPU_NAME- Es el nombre de tu Cloud TPU.
QUEUED_RESOURCE_ID- Es un identificador para tu solicitud de recurso en cola.
Establece el ID del proyecto y la zona en tu configuración activa de Google Cloud CLI:
gcloud config set project $PROJECT_ID && gcloud config set compute/zone $ZONECrea la VM de TPU:
gcloud compute tpus queued-resources create ${QUEUED_RESOURCE_ID} \ --node-id ${TPU_NAME} \ --project ${PROJECT_ID} \ --zone ${ZONE} \ --accelerator-type ${ACCELERATOR_TYPE} \ --runtime-version ${RUNTIME_VERSION} \ --service-account ${SERVICE_ACCOUNT}Comprueba que la TPU esté activa:
gcloud compute tpus queued-resources list --project $PROJECT_ID --zone $ZONE
Configura el nodo de conversión de puntos de control
Para ejecutar los modelos LLama en un clúster SAX, debes convertir el Llamado original puntos de control en un formato compatible con SAX.
La conversión requiere una cantidad importante de recursos de memoria, según el modelo. tamaño:
| Modelo | Tipo de máquina |
|---|---|
| 7,000 millones | De 50 a 60 GB de memoria |
| 13,000 millones | 120 GB de memoria |
| 70,000 millones | De 500 a 600 GB de memoria (tipo de máquina N2 o M1) |
Para los modelos 7B y 13B, puedes ejecutar la conversión en la VM de TPU. Para el 70B, debes crear una instancia de Compute Engine con aproximadamente 1 TB de espacio en disco:
gcloud compute instances create INSTANCE_NAME --project=$PROJECT_ID --zone=$ZONE \ --machine-type=n2-highmem-128 \ --network-interface=network-tier=PREMIUM,stack-type=IPV4_ONLY,subnet=default \ --maintenance-policy=MIGRATE --provisioning-model=STANDARD \ --service-account=$SERVICE_ACCOUNT \ --scopes=https://www.googleapis.com/auth/cloud-platform \ --tags=http-server,https-server \ --create-disk=auto-delete=yes,boot=yes,device-name=bk-workday-dlvm,image=projects/ml-images/global/images/c0-deeplearning-common-cpu-v20230925-debian-10,mode=rw,size=500,type=projects/$PROJECT_ID/zones/$ZONE/diskTypes/pd-balanced \ --no-shielded-secure-boot \ --shielded-vtpm \ --shielded-integrity-monitoring \ --labels=goog-ec-src=vm_add-gcloud \ --reservation-affinity=any
Ya sea que uses una instancia de TPU o Compute Engine como servidor de conversiones, configura tu servidor para convertir los puntos de control de Llama 2:
Para los modelos 7B y 13B, configura la variable de entorno de nombre del servidor por el nombre de la TPU:
export CONV_SERVER_NAME=$TPU_NAMEPara el modelo 70B, establece la variable de entorno de nombre del servidor como tu instancia de Compute Engine:
export CONV_SERVER_NAME=INSTANCE_NAME
Conéctate al nodo de conversión mediante SSH.
Si tu nodo de conversión es una TPU, conéctate a la TPU:
gcloud compute tpus tpu-vm ssh $CONV_SERVER_NAME --project=$PROJECT_ID --zone=$ZONESi tu nodo de conversión es una instancia de Compute Engine, conéctate a la VM de Compute Engine:
gcloud compute ssh $CONV_SERVER_NAME --project=$PROJECT_ID --zone=$ZONEInstala los paquetes obligatorios en el nodo de conversión:
sudo apt update sudo apt-get install python3-pip sudo apt-get install git-all pip3 install paxml==1.1.0 pip3 install torch pip3 install jaxlib==0.4.14Descarga el guion de conversión del punto de control de Llama:
gcloud storage cp gs://cloud-tpu-inference-public/sax-tokenizers/llama/convert_llama_ckpt.py .
Descargar pesos de Llama 2
Antes de convertir el modelo, debes descargar los pesos de Llama 2. Para este debes usar los pesos originales de Llama 2 (por ejemplo, meta-llama/Llama-2-7b) y no los pesos que se convirtieron para el formato de Transformers de Hugging Face (por ejemplo, meta-llama/Llama-2-7b-hf).
Si ya tienes los pesos de Llama 2, avanza a Convertir pesos.
Para descargar los pesos del centro de Hugging Face, debes establecer un token de acceso de usuario y solicitar acceso a los modelos de Llama 2. Para solicitar acceso, sigue las instrucciones en la página Hugging Face del modelo que quieres usar, por ejemplo, meta-llama/Llama-2-7b.
Crea un directorio para los pesos:
sudo mkdir WEIGHTS_DIRECTORY
Obtén los pesos de Llama2 del centro de Hugging Face:
Instala la CLI de Hugging Face:
pip install -U "huggingface_hub[cli]"Cambia al directorio de pesos:
cd WEIGHTS_DIRECTORY
Descarga los archivos de Llama 2:
python3 from huggingface_hub import login login() from huggingface_hub import hf_hub_download, snapshot_download import os PATH=os.getcwd() snapshot_download(repo_id="meta-llama/LLAMA2_REPO", local_dir_use_symlinks=False, local_dir=PATH)
Reemplaza LLAMA2_REPO por el nombre del repositorio de Hugging Face. deseas descargar desde:
Llama-2-7b,Llama-2-13boLlama-2-70b.
Convierte las ponderaciones
Edita la secuencia de comandos de conversiones y, luego, ejecútala para convertir el modelo. los pesos.
Crea un directorio para contener las ponderaciones convertidas:
sudo mkdir CONVERTED_WEIGHTS
Clona el repositorio de Saxml de GitHub en un directorio donde hayas leído, escrito y ejecutar permisos:
git clone https://github.com/google/saxml.git -b r1.1.0Cambia al directorio
saxml:cd saxmlAbre el archivo
saxml/tools/convert_llama_ckpt.py.En el archivo
saxml/tools/convert_llama_ckpt.py, cambia la línea 169 de la siguiente manera:'scale': pytorch_vars[0]['layers.%d.attention_norm.weight' % (layer_idx)].type(torch.float16).numpy()Para:
'scale': pytorch_vars[0]['norm.weight'].type(torch.float16).numpy()Ejecuta la secuencia de comandos
saxml/tools/init_cloud_vm.sh:saxml/tools/init_cloud_vm.shSolo para 70B: Para desactivar el modo de prueba, haz lo siguiente:
- Abre el
saxml/server/pax/lm/params/lm_cloud.py. En la
saxml/server/pax/lm/params/lm_cloud.pycambia la línea 344 de:return TruePara:
return False
- Abre el
Convierte las ponderaciones:
python3 saxml/tools/convert_llama_ckpt.py --base-model-path WEIGHTS_DIRECTORY \ --pax-model-path CONVERTED_WEIGHTS \ --model-size MODEL_SIZE
Reemplaza lo siguiente:
- WEIGHTS_DIRECTORY: Directorio para las ponderaciones originales
- CONVERTED_WEIGHTS: Ruta de destino para las ponderaciones convertidas.
- MODEL_SIZE:
7b,13bo70b.
Prepara el directorio del punto de control
Después de convertir los puntos de control, el directorio de puntos de control debe tener la la siguiente estructura:
checkpoint_00000000
metadata/
metadata
state/
mdl_vars.params.lm*/
...
...
step/
Crea un archivo vacío llamado commit_success.txt y pon una copia de este en la
Directorios checkpoint_00000000, metadata y state. Esto le informa a SAX
que este punto de control esté completamente convertido y listo para cargarse:
Cambia al directorio del punto de control:
cd CONVERTED_WEIGHTS/checkpoint_00000000
Crea un nuevo archivo llamado
commit_success.txt:touch commit_success.txtCambia al directorio de metadatos y crea un archivo vacío llamado
commit_success.txt:cd metadata && touch commit_success.txtCambia al directorio de estado y crea un archivo vacío llamado
commit_success.txt:cd .. && cd state && touch commit_success.txt
El directorio del punto de control ahora debería tener la siguiente estructura:
checkpoint_00000000
commit_success.txt
metadata/
commit_success.txt
metadata
state/
commit_success.txt
mdl_vars.params.lm*/
...
...
step/
Cree un bucket de Cloud Storage
Debes almacenar el archivo puntos de control en un bucket de Cloud Storage para disponibles cuando se publica el modelo.
Establece una variable de entorno para el nombre de tu bucket de Cloud Storage:
export GSBUCKET=BUCKET_NAME
Crea un bucket:
gcloud storage buckets create gs://${GSBUCKET}Copia los archivos de punto de control convertidos en tu bucket:
gcloud storage cp -r CONVERTED_WEIGHTS/checkpoint_00000000 gs://$GSBUCKET/sax_models/llama2/SAX_LLAMA2_DIR/
Reemplaza SAX_LLAMA2_DIR por el valor adecuado:
- 7B:
saxml_llama27b - 13,000 millones:
saxml_llama213b - 70,000 millones:
saxml_llama270b
- 7B:
Crea un clúster de SAX
Para crear un clúster de SAX, debes hacer lo siguiente:
- Crea un servidor de administrador
- Crea un servidor de modelos
- Implementa el modelo en el servidor de modelos
En una implementación típica, ejecutarías el servidor de administrador en una Compute Engine y el servidor de modelos en una TPU o GPU. A los efectos de este En este instructivo, implementarás el servidor de administrador y el de modelos en la misma TPU v5e.
Crear servidor de administrador
Crea el contenedor de Docker del servidor de administrador:
En el servidor de conversión, instala Docker:
sudo apt-get update sudo apt-get install docker.ioInicia el contenedor de Docker del servidor de administrador:
sudo docker run --name sax-admin-server \ -it \ -d \ --rm \ --network host \ --env GSBUCKET=${GSBUCKET} us-docker.pkg.dev/cloud-tpu-images/inference/sax-admin-server:v1.1.0
Puedes ejecutar el comando docker run sin la opción -d para ver los registros y
asegúrate de que el servidor de administración se inicie correctamente.
Crear servidor de modelos
En las siguientes secciones, se muestra cómo crear un servidor de modelos.
Modelo 7b
Inicia el contenedor de Docker del servidor de modelos:
sudo docker run --privileged \
-it \
-d \
--rm \
--network host \
--name "sax-model-server" \
--env SAX_ROOT=gs://${GSBUCKET}/sax-root us-docker.pkg.dev/cloud-tpu-images/inference/sax-model-server:v1.1.0 \
--sax_cell="/sax/test" \
--port=10001 \
--platform_chip=tpuv5e \
--platform_topology='4'
Modelo 13b
Falta la configuración de LLaMA13BFP16TPUv5e en lm_cloud.py. El
Los siguientes pasos muestran cómo actualizar lm_cloud.py y confirmar una nueva imagen de Docker.
Inicia el servidor de modelos:
sudo docker run --privileged \ -it \ -d \ --rm \ --network host \ --name "sax-model-server" \ --env SAX_ROOT=gs://${GSBUCKET}/sax-root \ us-docker.pkg.dev/cloud-tpu-images/inference/sax-model-server:v1.1.0 \ --sax_cell="/sax/test" \ --port=10001 \ --platform_chip=tpuv5e \ --platform_topology='8'Conéctate al contenedor de Docker con SSH:
sudo docker exec -it sax-model-server bashInstala Vim en la imagen de Docker:
$ apt update $ apt install vimAbre el archivo
saxml/server/pax/lm/params/lm_cloud.py. BuscarLLaMA13BDeberías ver el siguiente código:@servable_model_registry.register @quantization.for_transformer(quantize_on_the_fly=False) class LLaMA13B(BaseLLaMA): """13B model on a A100-40GB. April 12, 2023 Latency = 5.06s with 128 decoded tokens. 38ms per output token. """ NUM_LAYERS = 40 VOCAB_SIZE = 32000 DIMS_PER_HEAD = 128 NUM_HEADS = 40 MODEL_DIMS = 5120 HIDDEN_DIMS = 13824 ICI_MESH_SHAPE = [1, 1, 1] @property def test_mode(self) -> bool: return TrueComenta o borra la línea que comienza con
@quantization. Después de esto el archivo debería verse de la siguiente manera:@servable_model_registry.register class LLaMA13B(BaseLLaMA): """13B model on a A100-40GB. April 12, 2023 Latency = 5.06s with 128 decoded tokens. 38ms per output token. """ NUM_LAYERS = 40 VOCAB_SIZE = 32000 DIMS_PER_HEAD = 128 NUM_HEADS = 40 MODEL_DIMS = 5120 HIDDEN_DIMS = 13824 ICI_MESH_SHAPE = [1, 1, 1] @property def test_mode(self) -> bool: return TrueAgrega el siguiente código para admitir la configuración de la TPU.
@servable_model_registry.register class LLaMA13BFP16TPUv5e(LLaMA13B): """13B model on TPU v5e-8. """ BATCH_SIZE = [1] BUCKET_KEYS = [128] MAX_DECODE_STEPS = [32] ENABLE_GENERATE_STREAM = False ICI_MESH_SHAPE = [1, 1, 8] @property def test_mode(self) -> bool: return FalseSal de la sesión de SSH del contenedor de Docker:
exitConfirma los cambios en una nueva imagen de Docker:
sudo docker commit sax-model-server sax-model-server:v1.1.0-modVerifica que se haya creado la nueva imagen de Docker:
sudo docker imagesPuedes publicar la imagen de Docker en el Artifact Registry de tu proyecto, pero esta continuará con la imagen local.
Detén el servidor del modelo. En el resto del instructivo, se usará el modelo actualizado. servidor.
sudo docker stop sax-model-serverInicia el servidor de modelos con la imagen de Docker actualizada. Asegúrate de especificar el nombre de la imagen actualizada,
sax-model-server:v1.1.0-mod:sudo docker run --privileged \ -it \ -d \ --rm \ --network host \ --name "sax-model-server" \ --env SAX_ROOT=gs://${GSBUCKET}/sax-root \ sax-model-server:v1.1.0-mod \ --sax_cell="/sax/test" \ --port=10001 \ --platform_chip=tpuv5e \ --platform_topology='8'
Modelo 70B
Conéctate a la TPU con SSH y, luego, inicia el servidor del modelo:
gcloud compute tpus tpu-vm ssh ${TPU_NAME} \
--project ${PROJECT_ID} \
--zone ${ZONE} \
--worker=all \
--command="
gcloud auth configure-docker \
us-docker.pkg.dev
# Pull SAX model server image
sudo docker pull us-docker.pkg.dev/cloud-tpu-images/inference/sax-model-server:v1.1.0
# Run model server
sudo docker run \
--privileged \
-it \
-d \
--rm \
--network host \
--name "sax-model-server" \
--env SAX_ROOT=gs://${GSBUCKET}/sax-root \
us-docker.pkg.dev/cloud-tpu-images/inference/sax-model-server:v1.1.0 \
--sax_cell="/sax/test" \
--port=10001 \
--platform_chip=tpuv5e \
--platform_topology='16'
"
Verifica los registros
Verifica los registros del servidor de modelos para asegurarte de que se haya iniciado. correctamente:
docker logs -f sax-model-server
Si el servidor de modelo no se inició, consulta la sección Cómo solucionar problemas. para obtener más información.
Para el modelo 70B, repite estos pasos para cada VM de TPU:
Conéctate a la TPU con SSH:
gcloud compute tpus tpu-vm ssh ${TPU_NAME} \ --project ${PROJECT_ID} \ --zone ${ZONE} \ --worker=WORKER_NUMBERWORKER_NUMBER es un índice basado en 0 que indica qué VM de TPU deseas. a la que te conectarás.
Verifica los registros:
sudo docker logs -f sax-model-serverTres VM de TPU deberían mostrar que se conectaron a las otras instancias:
I1117 00:16:07.196594 140613973207936 multi_host_sync.py:152] Received SPMD peer address 10.182.0.3:10001 I1117 00:16:07.197484 140613973207936 multi_host_sync.py:152] Received SPMD peer address 10.182.0.87:10001 I1117 00:16:07.199437 140613973207936 multi_host_sync.py:152] Received SPMD peer address 10.182.0.13:10001Una de las VMs de TPU debería tener registros que muestren cómo se inicia el servidor de modelos:
I1115 04:01:29.479170 139974275995200 model_service_base.py:867] Started joining SAX cell /sax/test ERROR: logging before flag.Parse: I1115 04:01:31.479794 1 location.go:141] Calling Join due to address update ERROR: logging before flag.Parse: I1115 04:01:31.814721 1 location.go:155] Joined 10.182.0.44:10000
Publica el modelo
SAX incluye una herramienta de línea de comandos llamada saxutil, que simplifica
que interactúan con servidores de modelos SAX. En este instructivo, usarás
saxutil para publicar el modelo. Para obtener la lista completa de comandos de saxutil, consulta
el archivo README de Saxml
archivo.
Cambia al directorio en el que clonaste el repositorio de Saxml de GitHub:
cd saxmlPara el modelo 70B, conéctate a tu servidor de conversiones:
gcloud compute ssh ${CONV_SERVER_NAME} \ --project ${PROJECT_ID} \ --zone ${ZONE}Instala Bazel:
sudo apt-get install bazelEstablece un alias para ejecutar
saxutilcon tu bucket de Cloud Storage:alias saxutil='bazel run saxml/bin:saxutil -- --sax_root=gs://${GSBUCKET}/sax-root'Publica el modelo con
saxutil. Esto tarda alrededor de 10 minutos en una TPU v5litepod-8.saxutil --sax_root=gs://${GSBUCKET}/sax-root publish '/sax/test/MODEL' \ saxml.server.pax.lm.params.lm_cloud.PARAMETERS \ gs://${GSBUCKET}/sax_models/llama2/SAX_LLAMA2_DIR/checkpoint_00000000/ \ 1Reemplaza las siguientes variables:
Tamaño del modelo Valores 7,000 millones MODEL: llama27b
PARAMETERS: saxml.server.pax.lm.params.lm_cloud.LLaMA7BFP16TPUv5e
SAX_LLAMA2_DIR: saxml_llama27b
13,000 millones MODEL: llama213b
PARAMETERS: saxml.server.pax.lm.params.lm_cloud.LLaMA13BFP16TPUv5e
SAX_LLAMA2_DIR: saxml_llama213b
70,000 millones MODEL: llama270b
PARAMETERS: saxml.server.pax.lm.params.lm_cloud.LLaMA70BFP16TPUv5e
SAX_LLAMA2_DIR: saxml_llama270b
Implementación de prueba
Para verificar si la implementación se realizó correctamente, usa el comando saxutil ls:
saxutil ls /sax/test/MODEL
Una implementación exitosa debe tener una cantidad de réplicas mayor que cero tendrá un aspecto similar al siguiente:
INFO: Running command line: bazel-bin/saxml/bin/saxutil_/saxutil '--sax_rootmgs://sax-admin2/sax-root is /sax/test/1lama27b
+----------+-------------------------------------------------------+-----------------------------------------------------------------------+---------------+---------------------------+
| MODEL | MODEL PATH | CHECKPOINT PATH | # OF REPLICAS | (SELECTED) REPLICAADDRESS |
+----------+-------------------------------------------------------+-----------------------------------------------------------------------+---------------+---------------------------+
| llama27b | saxml.server.pax.lm.params.lm_cloud.LLaMA7BFP16TPUv5e | gs://${MODEL_BUCKET}/sax_models/llama2/7b/pax_7B/checkpoint_00000000/ | 1 | 10.182.0.28:10001 |
+----------+-------------------------------------------------------+-----------------------------------------------------------------------+---------------+---------------------------+
Los registros de Docker para el servidor de modelos serán similares a los siguientes:
I1114 17:31:03.586631 140003787142720 model_service_base.py:532] Successfully loaded model for key: /sax/test/llama27b
INFO: Running command line: bazel-bin/saxml/bin/saxutil_/saxutil '--sax_rootmgs://sax-admin2/sax-root is /sax/test/1lama27b
Solucionar problemas
Si la implementación falla, verifica los registros del servidor de modelos:
sudo docker logs -f sax-model-server
Para que la implementación se realice de forma correcta, deberías ver el siguiente resultado:
Successfully loaded model for key: /sax/test/llama27b
Si los registros no muestran que el modelo se implementó, verifícalo. y la ruta de acceso al punto de control del modelo.
Genera respuestas
Puedes usar la herramienta saxutil para generar respuestas a las instrucciones.
Genera respuestas a una pregunta:
saxutil lm.generate -extra="temperature:0.2" /sax/test/MODEL "Q: Who is Harry Potter's mother? A:"
El resultado debería ser similar al siguiente ejemplo:
INFO: Running command line: bazel-bin/saxml/bin/saxutil_/saxutil '--sax_rootmgs://sax-admin2/sax-root' lm.generate /sax/test/llama27b 'Q: Who is Harry Potter's mother? A: `
+-------------------------------+------------+
| GENERATE | SCORE |
+-------------------------------+------------+
| 1. Harry Potter's mother is | -20.214787 |
| Lily Evans. 2. Harry Potter's | |
| mother is Petunia Evans | |
| (Dursley). | |
+-------------------------------+------------+
Interactúa con el modelo desde un cliente
El repositorio SAX incluye clientes que puedes usar para interactuar con una celda SAX. Los clientes están disponibles en C++, Python y Go. En el siguiente ejemplo, se muestra cómo compilar un cliente de Python.
Compila el cliente de Python:
bazel build saxml/client/python:sax.cc --compile_one_dependencyAgrega el cliente a
PYTHONPATH. En este ejemplo, se supone que tienessaxmlen tu directorio principal:export PYTHONPATH=${PYTHONPATH}:$HOME/saxml/bazel-bin/saxml/client/python/Interactúa con SAX desde la shell de Python:
$ python3 Python 3.10.12 (main, Jun 11 2023, 05:26:28) [GCC 11.4.0] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import sax >>>
Interactúa con el modelo desde un extremo HTTP
Para interactuar con el modelo desde un extremo HTTP, crea un cliente HTTP:
Crea una VM de Compute Engine:
export PROJECT_ID=PROJECT_ID export ZONE=ZONE export HTTP_SERVER_NAME=HTTP_SERVER_NAME export SERVICE_ACCOUNT=SERVICE_ACCOUNT export MACHINE_TYPE=e2-standard-8 gcloud compute instances create $HTTP_SERVER_NAME --project=$PROJECT_ID --zone=$ZONE \ --machine-type=$MACHINE_TYPE \ --network-interface=network-tier=PREMIUM,stack-type=IPV4_ONLY,subnet=default \ --maintenance-policy=MIGRATE --provisioning-model=STANDARD \ --service-account=$SERVICE_ACCOUNT \ --scopes=https://www.googleapis.com/auth/cloud-platform \ --tags=http-server,https-server \ --create-disk=auto-delete=yes,boot=yes,device-name=$HTTP_SERVER_NAME,image=projects/ml-images/global/images/c0-deeplearning-common-cpu-v20230925-debian-10,mode=rw,size=500,type=projects/$PROJECT_ID/zones/$ZONE/diskTypes/pd-balanced \ --no-shielded-secure-boot \ --shielded-vtpm \ --shielded-integrity-monitoring \ --labels=goog-ec-src=vm_add-gcloud \ --reservation-affinity=any
Conéctate a la VM de Compute Engine mediante SSH:
gcloud compute ssh $HTTP_SERVER_NAME --project=$PROJECT_ID --zone=$ZONEClona la IA en el repositorio de GitHub de GKE:
git clone https://github.com/GoogleCloudPlatform/ai-on-gke.gitCambia al directorio del servidor HTTP:
cd ai-on-gke/tools/saxml-on-gke/httpserverCompila el archivo Docker:
docker build -f Dockerfile -t sax-http .Ejecuta el servidor HTTP:
docker run -e SAX_ROOT=gs://${GSBUCKET}/sax-root -p 8888:8888 -it sax-http
Prueba tu extremo desde tu máquina local o algún otro servidor con acceso al puerto 8888 con los siguientes comandos:
Exporta las variables de entorno para la dirección IP y el puerto de tu servidor:
export LB_IP=HTTP_SERVER_EXTERNAL_IP export PORT=8888
Configura la carga útil de JSON, que contiene el modelo y la consulta:
json_payload=$(cat << EOF { "model": "/sax/test/MODEL", "query": "Example query" } EOF )Envía la solicitud:
curl --request POST --header "Content-type: application/json" -s $LB_IP:$PORT/generate --data "$json_payload"
Limpia
Para evitar que se apliquen cargos a tu cuenta de Google Cloud por los recursos usados en este instructivo, borra el proyecto que contiene los recursos o conserva el proyecto y borra los recursos individuales.
Cuando termines con este instructivo, sigue estos pasos para limpiar tu de Google Cloud.
Borra tu Cloud TPU.
$ gcloud compute tpus tpu-vm delete $TPU_NAME --zone $ZONEBorrar tu instancia de Compute Engine, si creaste una
gcloud compute instances delete INSTANCE_NAME
Borrar el bucket de Cloud Storage y su contenido
gcloud storage rm --recursive gs://BUCKET_NAME
¿Qué sigue?
- Todos los instructivos de TPU
- Modelos de referencia admitidos
- Inferencia con v5e
- Convierte un modelo para inferencia con v5e