在 Cloud TPU 虚拟机上分析模型的性能
借助性能分析,您可以优化模型在 Cloud TPU 上的训练性能。您可以使用 TensorBoard 和 Cloud TPU TensorBoard 插件来分析模型。
如需详细了解如何将 TensorBoard 与其中一个支持的框架搭配使用,请参阅以下文档:
开始分析模型训练
在模型训练时,打开一个单独的终端窗口或 Cloud Shell。 请按照以下步骤开始对模型训练进行性能分析。
在新窗口或 Shell 中,使用端口转发连接到 TPU 虚拟机。
gcloud compute tpus tpu-vm ssh your-vm --zone=us-central2-b --ssh-flag="-4 -L 9001:localhost:9001"
通过端口转发,您的本地浏览器可以与 TPU 虚拟机上运行的 TensorBoard 服务器通信。
安装 Cloud TPU TensorBoard 插件。
在 TPU 虚拟机中,运行以下命令:
pip3 install --upgrade "cloud-tpu-profiler>=2.3.0" pip3 install tensorflow pip3 install tensorboard_plugin_profile
启动 TensorBoard 服务器
运行 TensorBoard,并在 TPU 虚拟机上创建一个日志目录 (
logdir),TensorBoard 可以将性能分析数据写入该目录。使用--logdir标志指定日志目录。例如:mkdir log-directory TPU_LOAD_LIBRARY=0 tensorboard --logdir log-directory --port 9001
TensorBoard 会启动一个网络服务器并显示其网址:
Serving TensorBoard on localhost; to expose to the network, use a proxy or pass --bind_all TensorBoard 2.3.0 at http://localhost:9001 (Press CTRL+C to quit)
打开网络浏览器并转到 TensorBoard 输出中显示的网址。从 TensorBoard 页面右上角的下拉菜单中选择 Profile。可用性能分析工具的列表显示在左侧边栏的工具下拉菜单中。
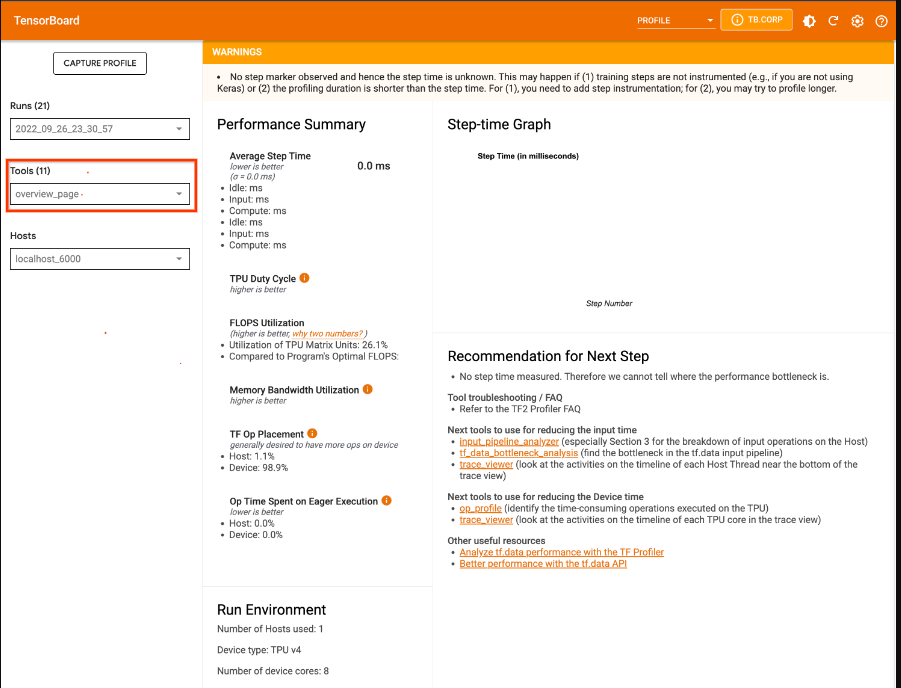
捕获 TPU 虚拟机上的性能剖析文件
- 选择捕获性能剖析文件按钮。
- 选择 IP 地址单选按钮。
- 在
Profile Service URL字段中输入 HOSTNAME:6000。 - 选择拍摄按钮。
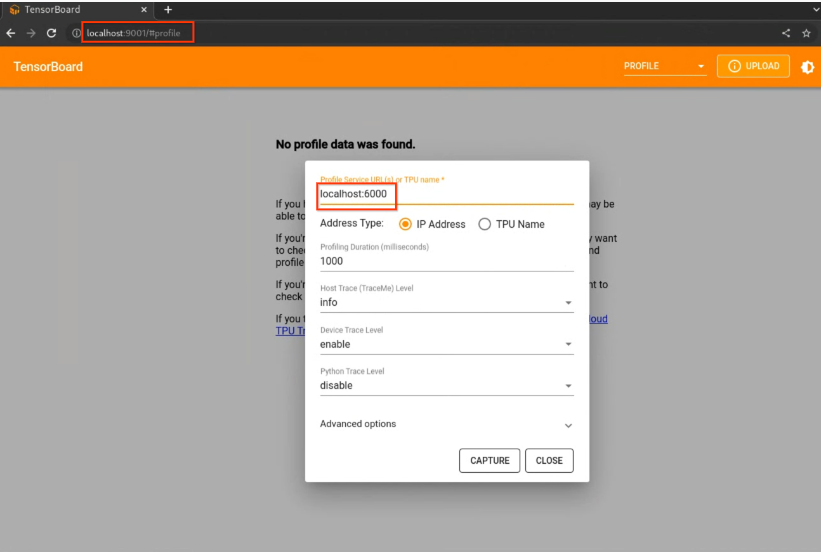
使用 TensorBoard 查看性能剖析文件数据
捕获性能配置文件后,TensorBoard 会显示概览页面。左侧窗格中会显示可用的性能分析工具列表。
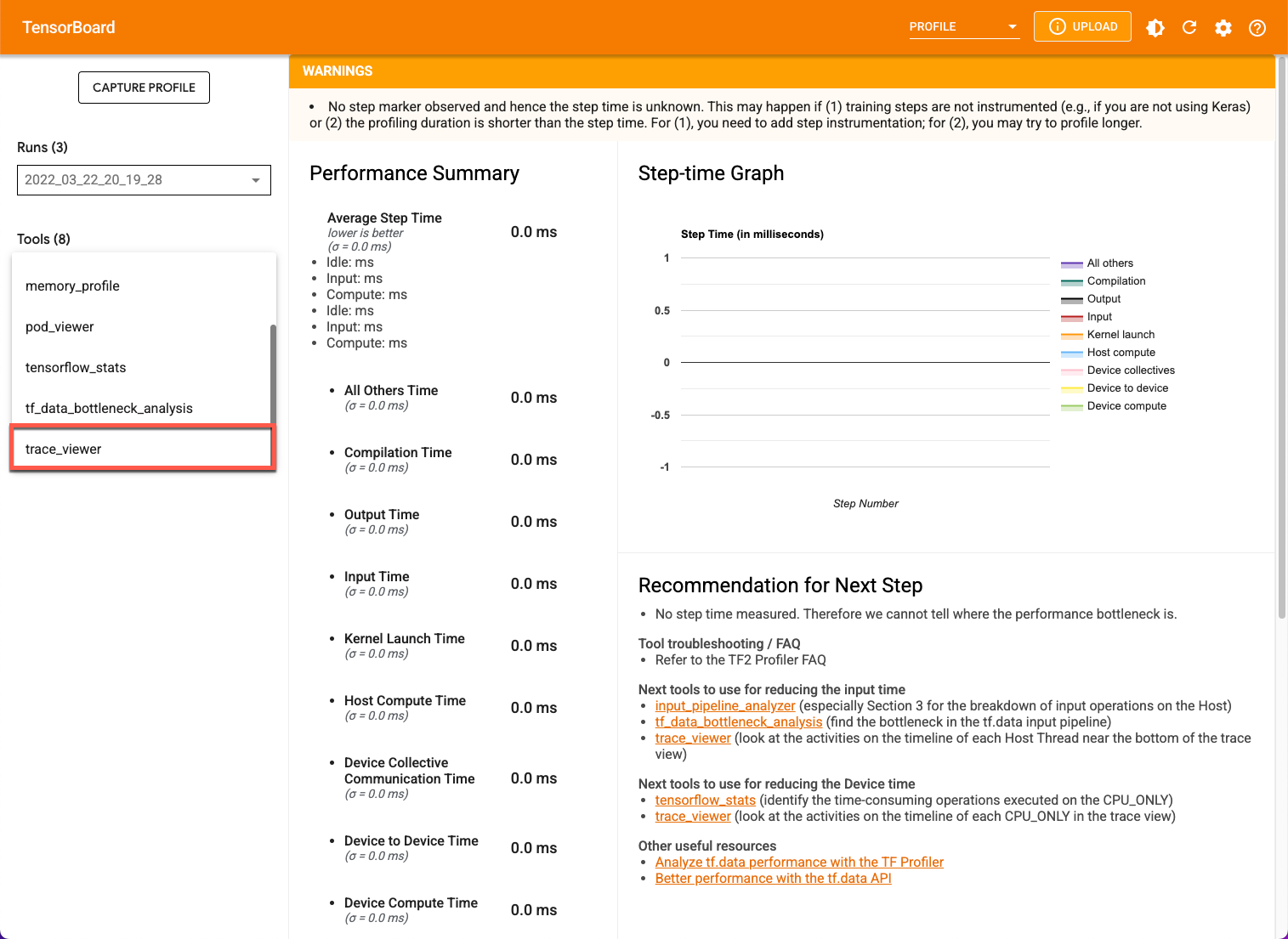
个人资料
性能剖析 (Profile) 标签页在您捕获某些模型数据后显示。您可能需要点击 TensorBoard 页面上的刷新按钮。数据可用后,点击性能剖析标签页会显示一系列有助于性能分析的工具。您可以使用以下任一工具对模型进行性能分析。
- 概览页面
- Input Pipeline Analyzer
- XLA Op Profile
- Trace Viewer(仅限 Chrome 浏览器)
- Memory Viewer
性能剖析概览页面
概览页面 (overview_page) 位于性能剖析页面中,该页面提供模型在捕获运行期间的执行情况汇总。该页面会显示所有 TPU 的汇总概览,以及整体输入流水线分析。您可以在主机下拉列表中选择单个 TPU。
该页面在以下面板中显示数据:
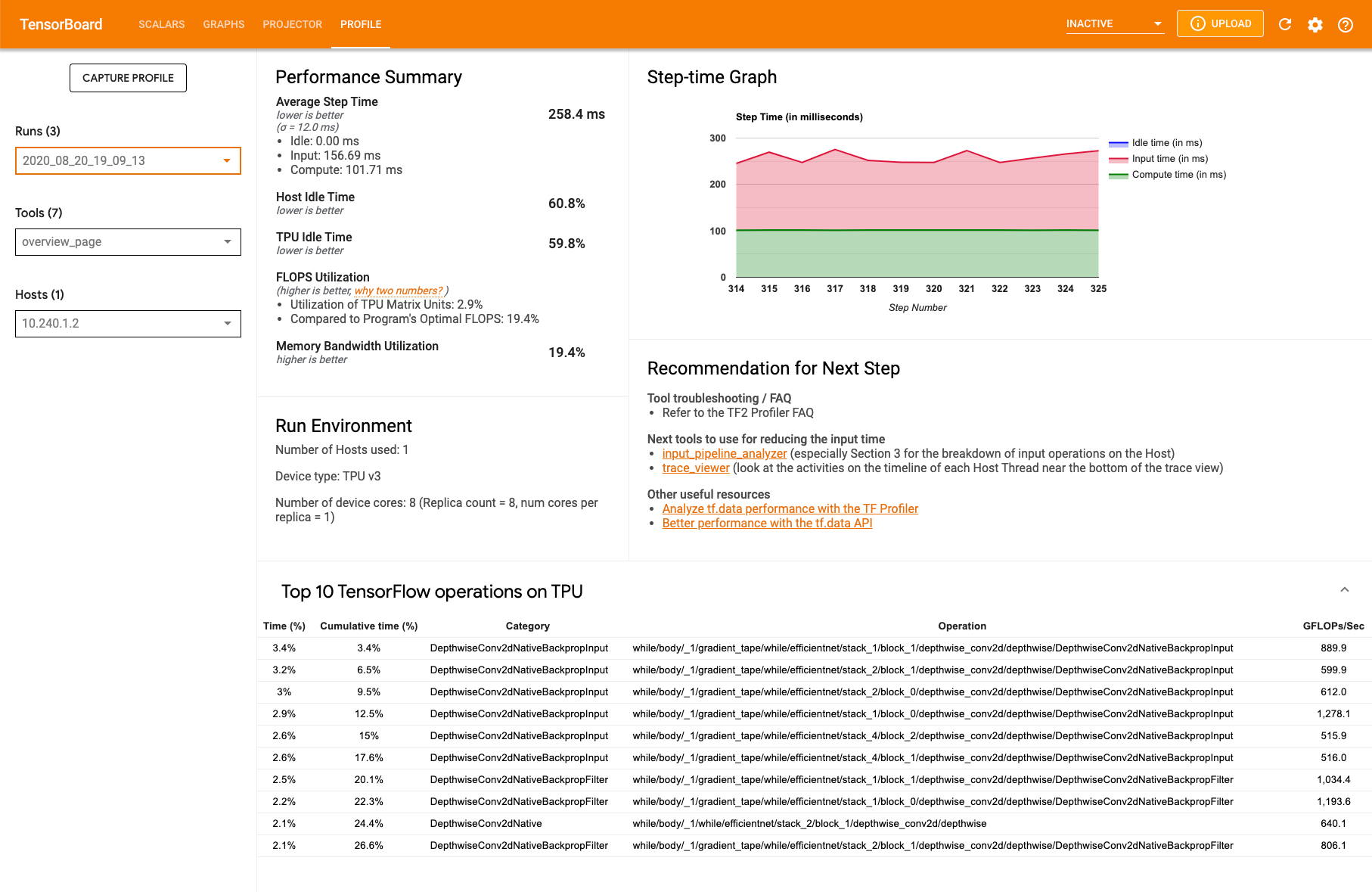
性能摘要
- FLOPS 利用率:TPU 矩阵单元的使用百分比
TPU 上最耗时的 10 个 TensorFlow 操作:显示占用了大部分时间的 TensorFlow 操作。每行显示操作的自用时间(以所有操作所用时间的百分比表示)、累计时间、类别、名称以及实现的 FLOPS 率。
运行环境
- 使用的主机数
- 使用的 TPU 类型
- TPU 核心数量
Input Pipeline Analyzer
Input Pipeline Analyzer 可提供有关性能结果的数据分析。该工具能够立即告知您程序是否输入受限,并可指导您完成设备端和主机端分析,以调试并确定流水线的哪个阶段存在瓶颈。
如需深入了解如何优化流水线性能,请参阅有关输入流水线性能的指南。
输入流水线
当 TensorFlow 程序从文件中读取数据时,读取过程会分为多个串联连接的数据处理阶段。一个阶段的输出是下一个阶段的输入。这个读取系统称为输入流水线。
从文件中读取记录的典型流水线具有以下阶段:
- 文件读取
- 文件预处理(可选)
- 将文件从主机传输到设备
效率低下的输入流水线可能会严重降低应用的速度。当应用在其输入流水线上花费大量时间时,我们将其称为输入受限。使用 Input Pipeline Analyzer 可以确定输入流水线的低效位置。
输入流水线信息中心
如需打开 Input Pipeline Analyzer,请选择性能剖析 (Profile),然后从工具 (Tools) 下拉列表中选择 input_pipeline_analyzer。
该信息中心会显示设备端和主机端分析详情。
设备端分析
本部分详细介绍了设备步骤时间。
- 设备单步用时统计信息
- 等待输入数据所占设备步骤时间的百分比
主机端分析
本部分显示主机端分析的详细信息,将主机端分析细分为几类:
- 将要传输到设备的数据加入队列:向设备传输数据之前将数据加入馈入队列所花费的时间。
- 数据预处理:用于预处理操作的时间,例如图片解压缩。
- 预先从文件中读取数据:读取文件所花费的时间,包括缓存、预取和交错。
- 按需从文件中读取数据:在没有缓存、预取和交错的情况下从文件读取数据所用的时间。
- 其他数据读取或处理:其他不使用
tf.data的输入相关操作所花费的时间。

如需查看按执行时间细分的各个输入操作及其类别的统计信息,请展开显示输入操作统计信息部分。
系统将显示如下所示的源数据表:
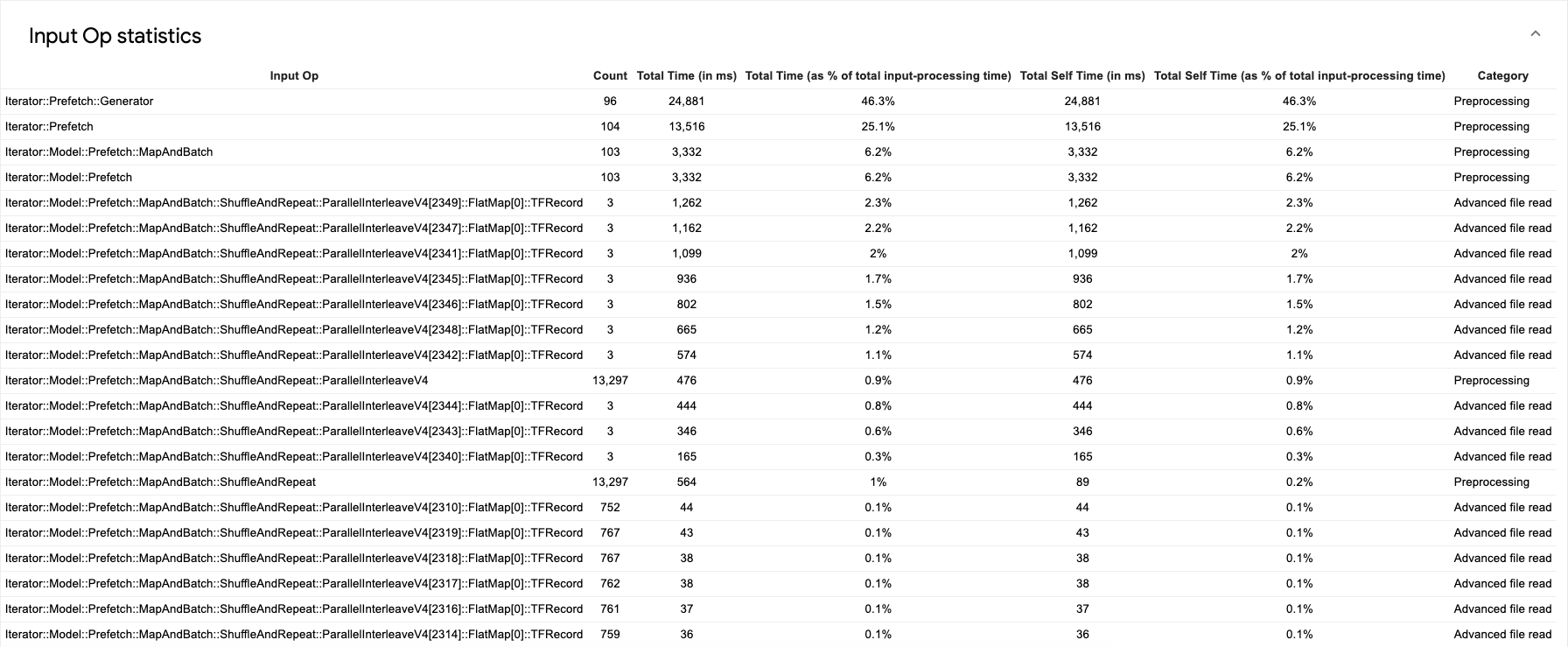
每个表条目包含以下信息:
- 输入操作:显示输入操作的 TensorFlow 操作名称。
- 计数:显示在性能剖析期间执行的操作的实例总数。
- 总时间(以毫秒为单位):显示每个操作实例所用时间的累计总和。
- 总时间百分比:显示在一个操作上花费的总时间占输入处理总时间的比例。
- 总自用时间(以毫秒为单位):显示函数的所有实例的累计时间。自用时间测量在函数体内部所用的时间,不包括它调用的任何函数所用的时间。例如,
Iterator::PaddedBatch::Filter::ForeverRepeat::Map由Iterator::PaddedBatch::Filter调用,因此前者的总自用时间不包括在后者的总自用时间内。 - 总自用时间百分比:显示总自用时间占输入处理总时间的比例。
- 类别:显示输入操作的处理类别。
Op Profile
Op Profile () 是一款 Cloud TPU 工具,它可展示在性能剖析期间执行的 XLA 操作的性能统计信息。操作配置文件会显示以下内容:
- 您的应用使用 Cloud TPU 的程度,按类别和 TPU FLOPS 利用率显示各操作所用时间的百分比。
- 最耗时的操作。这些操作可能有待优化。
- 各个操作的详细信息,包括形状、填充和使用该操作的表达式。
您可以使用 Op Profile 来查找需要优化的目标。例如,您可以使用操作性能分析找出运行时间最长的 XLA 操作并查看它们使用了多少 TPU FLOPS。
使用 Op Profile
Op Profile 工具包含 XLA 操作的性能统计信息。如需在 TensorBoard 中查看操作性能数据,请点击屏幕顶部的性能剖析 (Profile) 标签页,然后从工具下拉列表中选择 op_profile。您将看到如下所示的界面:
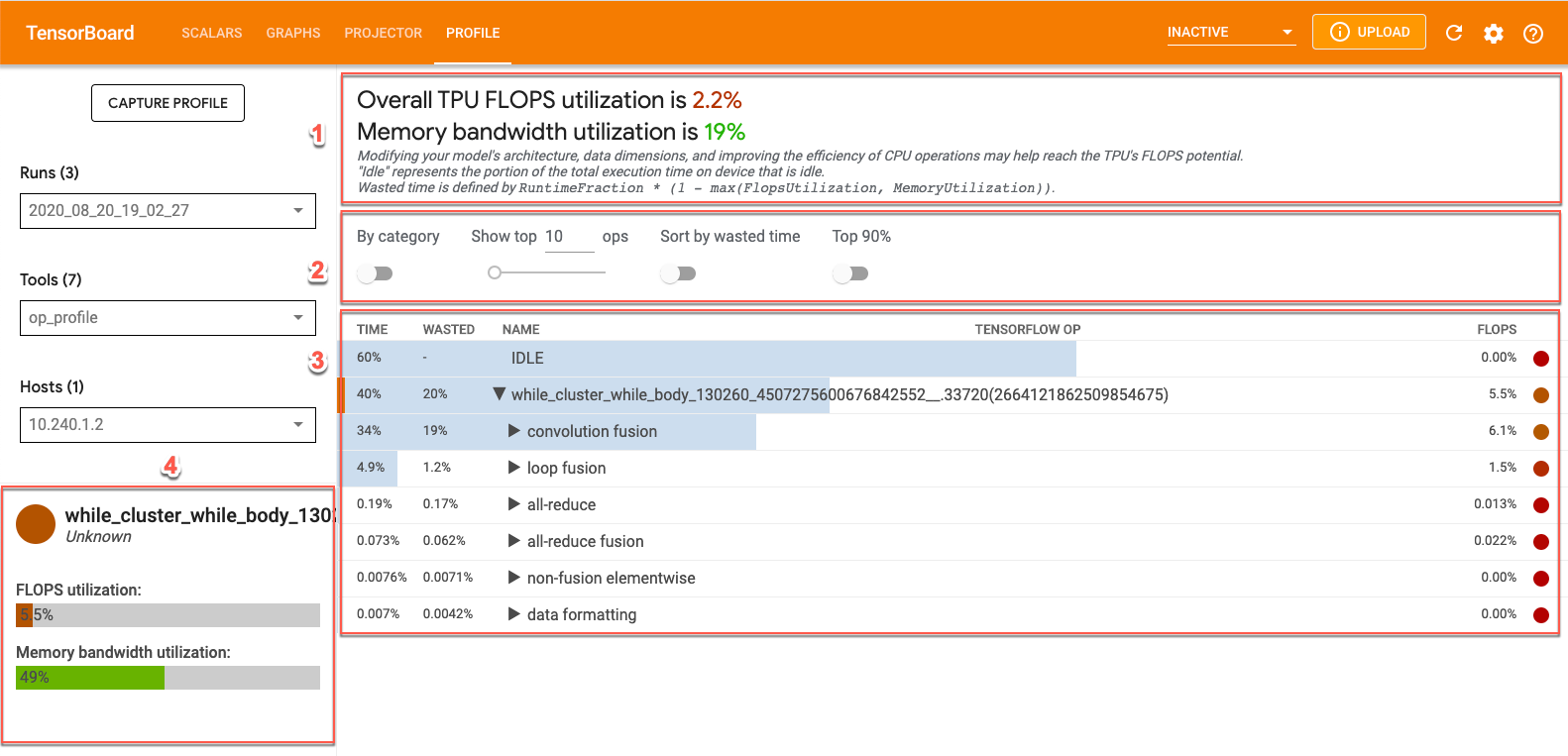
- “概览”部分:显示 Cloud TPU 利用率并提供优化建议。
- 控制台:通过包含的控件,您可设置表格中显示的操作数量、显示哪些操作,以及这些操作的排序方式。
- 操作表:列出与 XLA 操作相关联的主要 TensorFlow 操作类别。这些操作按 Cloud TPU 使用率百分比排序。
- 操作详情卡片:显示您在表格中指向某个操作时显示的操作详情。这些详细信息包括 FLOPS 利用率、使用该操作的表达式以及操作布局(匹配)。
XLA 操作表
操作表按照 Cloud TPU 使用率百分比从高到低的顺序列出 XLA 操作类别。该表会显示花费时间的百分比、操作类别名称、关联的 TensorFlow 操作的名称及其 FLOPS 利用率百分比。如需显示(或隐藏)某个类别中 10 个最耗时的 XLA 操作,请点击表格中类别名称旁边的三角形。
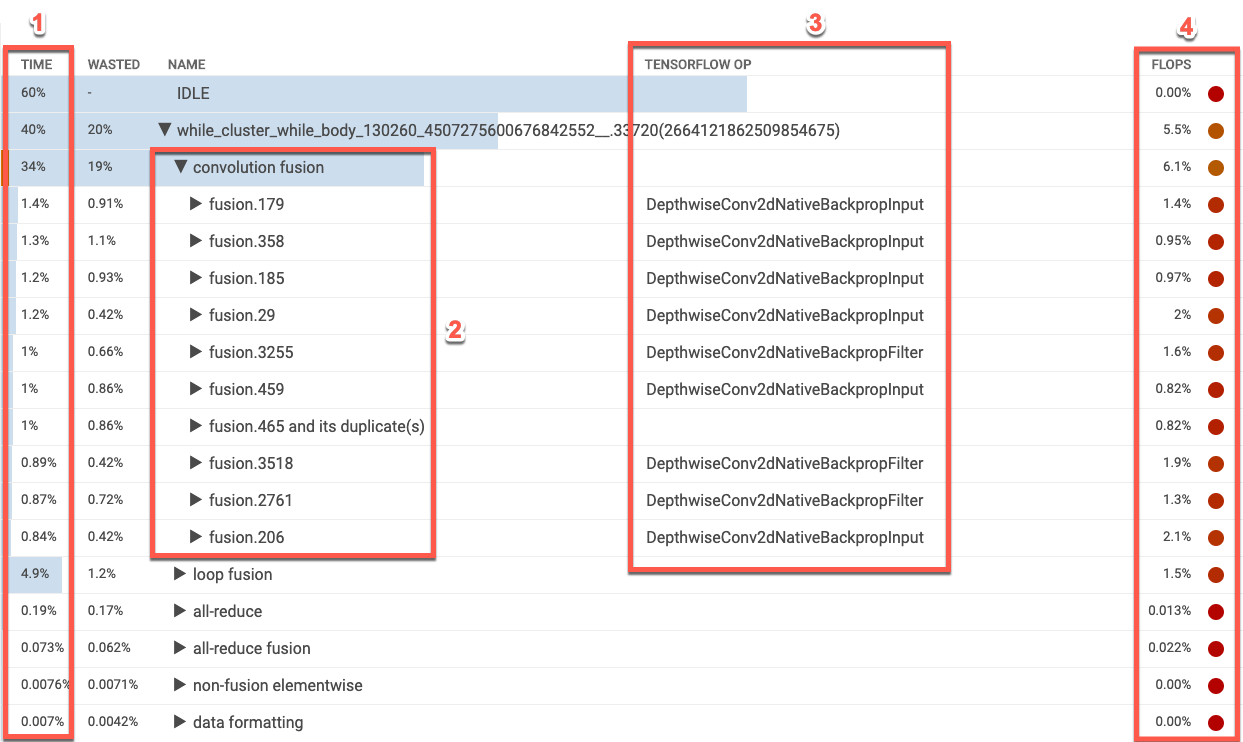
- 时间:显示该类别中所有操作所用时间的总百分比。您可以点击以展开条目,查看每个操作所用时间的明细。
- 十大操作:点击类别名称旁边的切换开关,即可显示或隐藏此类别中 10 个最耗时的操作。如果操作列表中显示了融合操作条目,您可以将其展开即可查看其包含的非融合元素级操作。
- TensorFlow 操作:显示与 XLA 操作关联的 TensorFlow 操作名称。
- FLOPS:显示 FLOPS 利用率,即以 Cloud TPU 峰值 FLOPS 的百分比表示的 FLOPS 的测量值。FLOPS 利用率百分比越高,操作运行速度越快。表单元格采用颜色编码:绿色表示 FLOPS 利用率高(好),红色表示 FLOPS 利用率低(差)。
操作详细信息卡片
选择一个表条目后,系统会显示一张卡片,上面显示有关 XLA 操作或该操作类别的详细信息。典型的卡片如下所示:
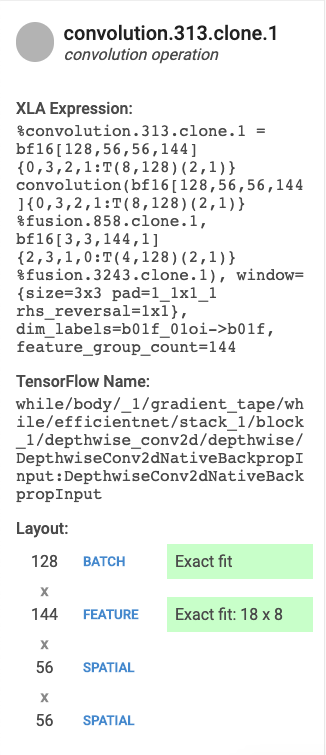
- 名称和类别:显示突出显示的 XLA 操作名称和类别。
- FLOPS 利用率:显示 FLOPS 利用率占总 FLOPS 的百分比。
- 表达式:显示包含该操作的 XLA 表达式。
- 内存利用率:显示程序峰值内存使用率的百分比。
- 布局:(仅限卷积运算)显示张量的形状和布局,包括 XLA 编译器执行的任何内边距的说明。
解读结果
对于卷积运算,TPU FLOPS 利用率低可能是由以下原因之一或全部造成的:
- 填充(矩阵单元仅被部分使用)
- 卷积运算受限于内存
本部分对 FLOPS 利用率较低的模型中的一些性能指标进行了解释。在这个例子中,输出融合和卷积占用了大部分执行时间。有许多矢量或标量运算的 FLOPS 利用率较低。
此类性能剖析文件的一种优化策略是将矢量或标量操作转换为卷积运算。
在以下示例中,%convolution.399 显示的 FLOPS 利用率和内存利用率低于上例中的 %convolution.340。
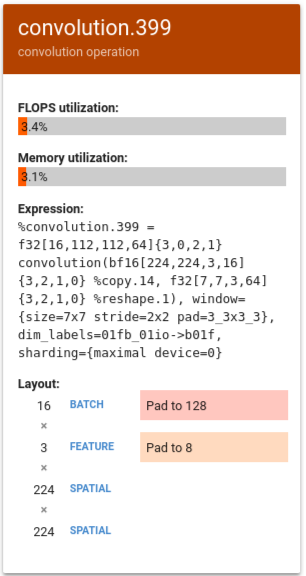
在此示例中,批量大小被填充至 128,特征大小被填充至 8。在这种情况下,只有 5% 的矩阵单元得到了有效使用。利用率的计算方法为:(((batch_time * num_of_features) / padding_size ) / num_of_cores)。将此示例中的 FLOPS 与前例中不使用填充的 %convolution.340 进行比较。
Trace Viewer
Trace Viewer 是性能剖析页面上的 Cloud TPU 性能分析工具。此工具使用 Chrome 跟踪记录事件分析查看器,因此仅适用于 Chrome 浏览器。
Trace Viewer 包含一个时间轴,其中显示了以下内容:
- 由 TensorFlow 模型执行的操作的时长。
- 系统的哪个部分(TPU 还是主机)执行了操作。通常,主机执行馈入操作,它会预处理训练数据并将其传输到 TPU,而 TPU 执行实际的模型训练。
您可以通过 Trace Viewer 找出模型中的性能问题,然后采取措施来加以解决。例如,从总括层面来讲,您可以确定占用大部分时间的是馈入还是模型训练。展开细目后,您可以确定哪些 TensorFlow 操作执行时间最长。
Trace Viewer 针对每个 Cloud TPU 仅限访问 100 万个事件。如果您需要访问更多事件,请改用Streaming Trace Viewer。
Trace Viewer 界面
如需打开 Trace Viewer,请前往 TensorBoard,点击屏幕顶部的性能剖析 (Profile) 标签页,然后从工具下拉列表中选择 trace_viewer。Trace Viewer 会显示最近的运行:
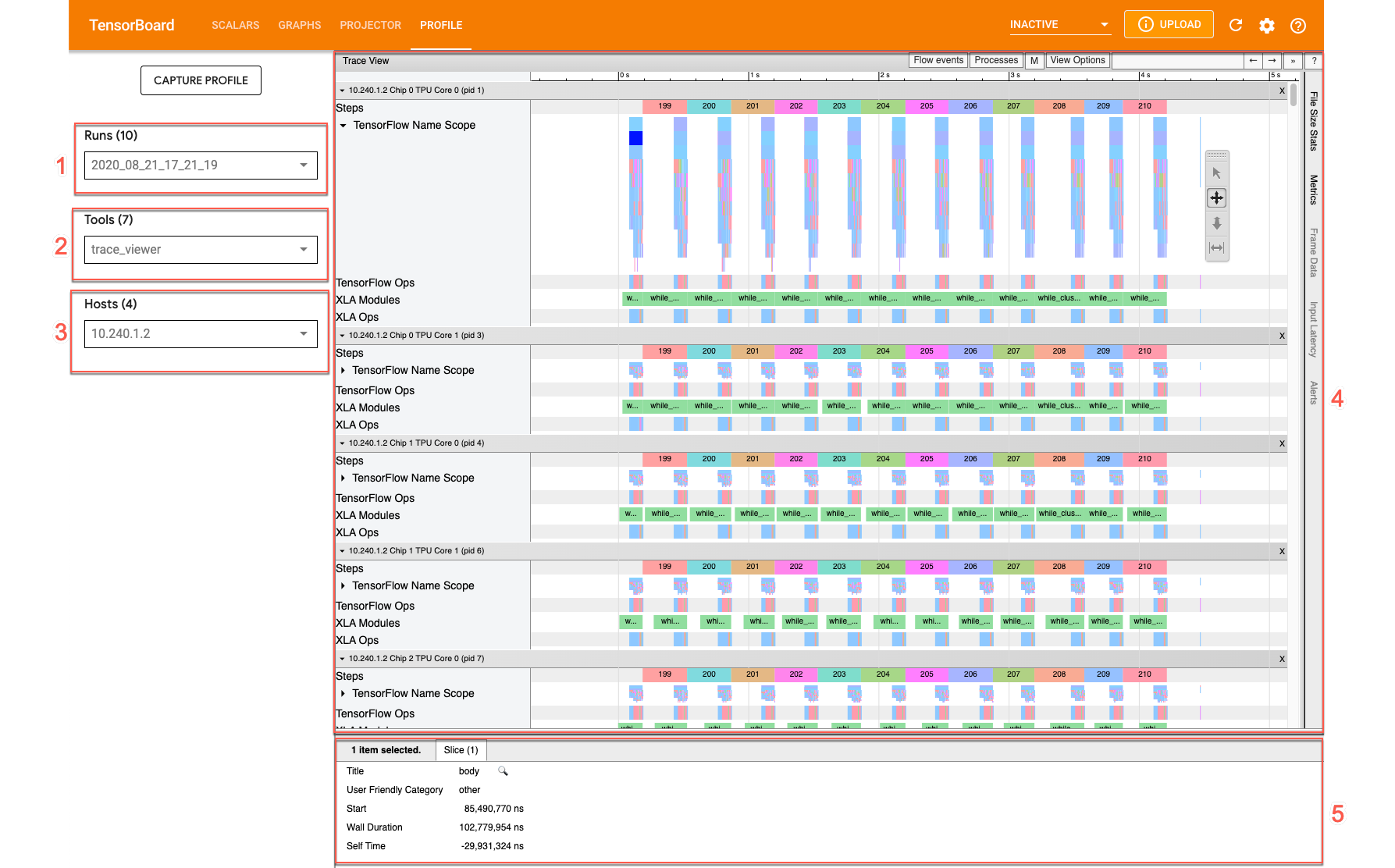
此屏幕包含以下主要元素(在前面的屏幕截图中标有数字):
- “运行”下拉菜单:包含已捕获其跟踪记录信息的所有运行。默认视图为最近的运行,您也可以打开下拉列表选择其他运行。
- “工具”下拉菜单:选择不同的性能分析工具。
- “主机”下拉菜单:选择包含 Cloud TPU 集的主机。
- 时间轴窗格:显示 Cloud TPU 和主机随时间执行操作的情况。
- “详细信息”窗格:显示时间轴窗格中所选操作的更多信息。
以下是时间轴窗格的详细信息:
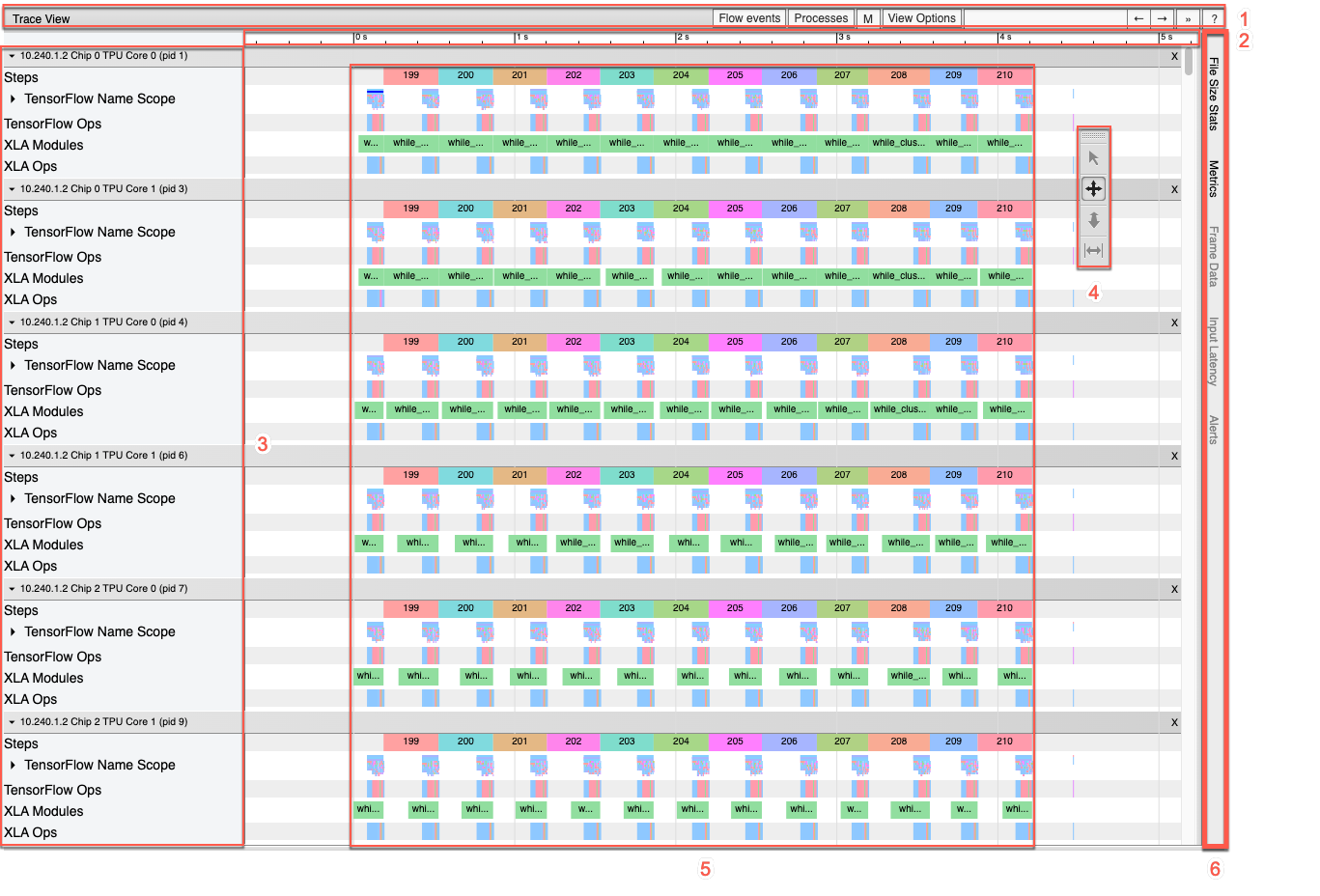
时间轴窗格包含以下元素:
- 顶栏:包含各种辅助控件。
- 时间轴:显示相对于跟踪记录开始时的时间。
- 版块和轨道标签:每个版块包含多个轨道,左侧有一个三角形,点击此三角形可展开和收起该版块。系统中的每个处理元素都有一个版块。
- 工具选择器:包含与 Trace Viewer 交互的各种工具。
- 事件:显示操作的执行时间或元事件(例如训练步)的时长。
- 垂直标签栏:此栏对 Cloud TPU 没有用处。此栏是 Chrome 提供的通用跟踪记录查看器工具的一部分,用于各种性能分析任务。
版块和跟踪记录
Trace Viewer 包含以下版块:
- 每个 TPU 节点有一个版块,上面标有 TPU 芯片的编号及芯片内 TPU 核心的编号(例如“芯片 2: TPU 核心 1”)。每个 TPU 节点版块包含以下跟踪记录:
- 步骤:显示 TPU 上运行的训练步的时长。
- TensorFlow 操作:显示在 TPU 上执行的 TensorFlow 操作。
- XLA 操作:显示在 TPU 上运行的 XLA 操作。(每个操作都会转换为一个或多个 XLA 操作。XLA 编译器会将这些 XLA 操作转换为在 TPU 上运行的代码。)
- 一个用于显示在宿主 CPU 上运行的线程的版块,上面标有“Host Threads”。对于每个 CPU 线程,此版块都包含一个跟踪记录。注意:您可以忽略版块标签旁边显示的信息。
时间轴工具选择器
您可以使用 TensorBoard 中的时间轴工具选择器与时间轴视图进行交互。点击时间轴工具以激活并突出显示该工具。 如需移动时间轴工具选择器,请点击顶部的虚线区域,然后将选择器拖动到所需位置。
以下是各个时间轴工具的使用方法:
|
选择工具 点击事件可将其选中,拖动可选择多个事件。有关所选事件(名称、开始时间和时长)的更多信息将显示在“详细信息”窗格中。 |
|
平移工具 拖动可在水平和垂直方向平移时间轴视图。 |
|
缩放工具 沿水平(时间)轴方向,向上拖动可放大视图,向下拖动可缩小视图。鼠标光标的水平位置决定缩放操作的中心。 注意:如果您松开鼠标按钮后缩放工具仍处于活动状态,请点击时间轴视图以停用缩放工具。 |
|
计时工具 水平拖动可以标记时间间隔。间隔的时长会显示在时间轴上。如需调整间隔,请拖动其末端。如需清除间隔,可点击时间轴视图内的任意位置。 如果您选择其他工具,间隔标记仍会保留。 |




Memory Viewer
借助 Memory Viewer,您可以直观地了解程序的峰值内存使用量和内存使用趋势。
Memory Viewer 界面如下所示:
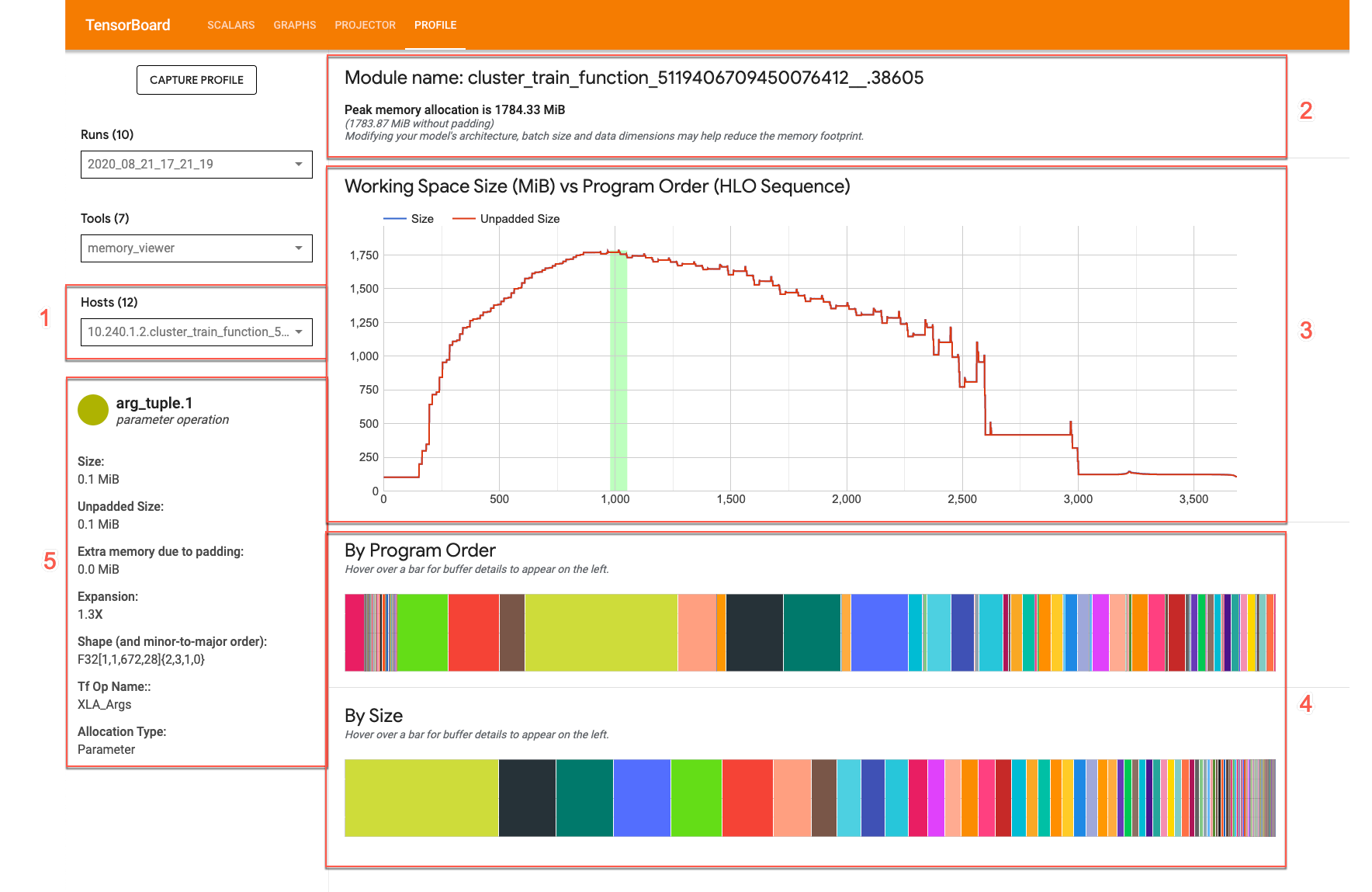
- 主机 下拉菜单:选择要直观显示的 TPU 主机和 XLA 高级优化器 (HLO) 模块。
- 内存概览:显示峰值内存分配和无填充的大小。
- 工作空间图表:显示程序的峰值内存用量和内存用量趋势图。将光标指向缓冲区图表中的某个缓冲区,即可在缓冲区分配卡片中显示更多信息。
- 缓冲区图表:这两个图表显示峰值内存使用量时的缓冲区分配。将光标指向缓冲区图表中的某个缓冲区,即可在缓冲区详细信息卡片中显示更多信息。
- 缓冲区分配详细信息卡片:显示有关缓冲区分配的详细信息。
内存概览面板
内存概览(顶部)面板显示模块名称,以及总缓冲区分配大小达到最大值时的峰值内存分配设置。此面板还显示未填充的峰值分配大小以供比较。

工作空间图表
此图表显示峰值内存使用量并绘制程序的内存使用趋势。垂直线表示程序的峰值内存利用率。此图表显示您的程序能否加载到可用的全局存储空间中。
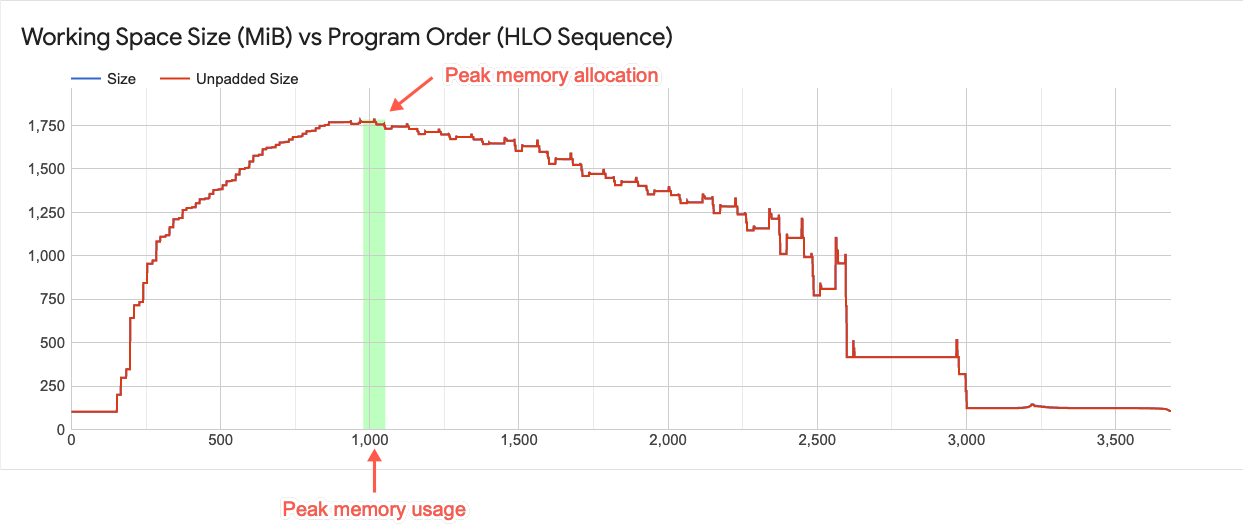
图中的每个点都代表 XLA HLO 程序中的“程序点”。该线条会显示程序内存用量随时间的变化情况。
与缓冲区图表元素的交互
当您在缓冲区图表中指向某个缓冲区时,工作空间图表中会显示一条水平线,用于显示该缓冲区的生命周期。
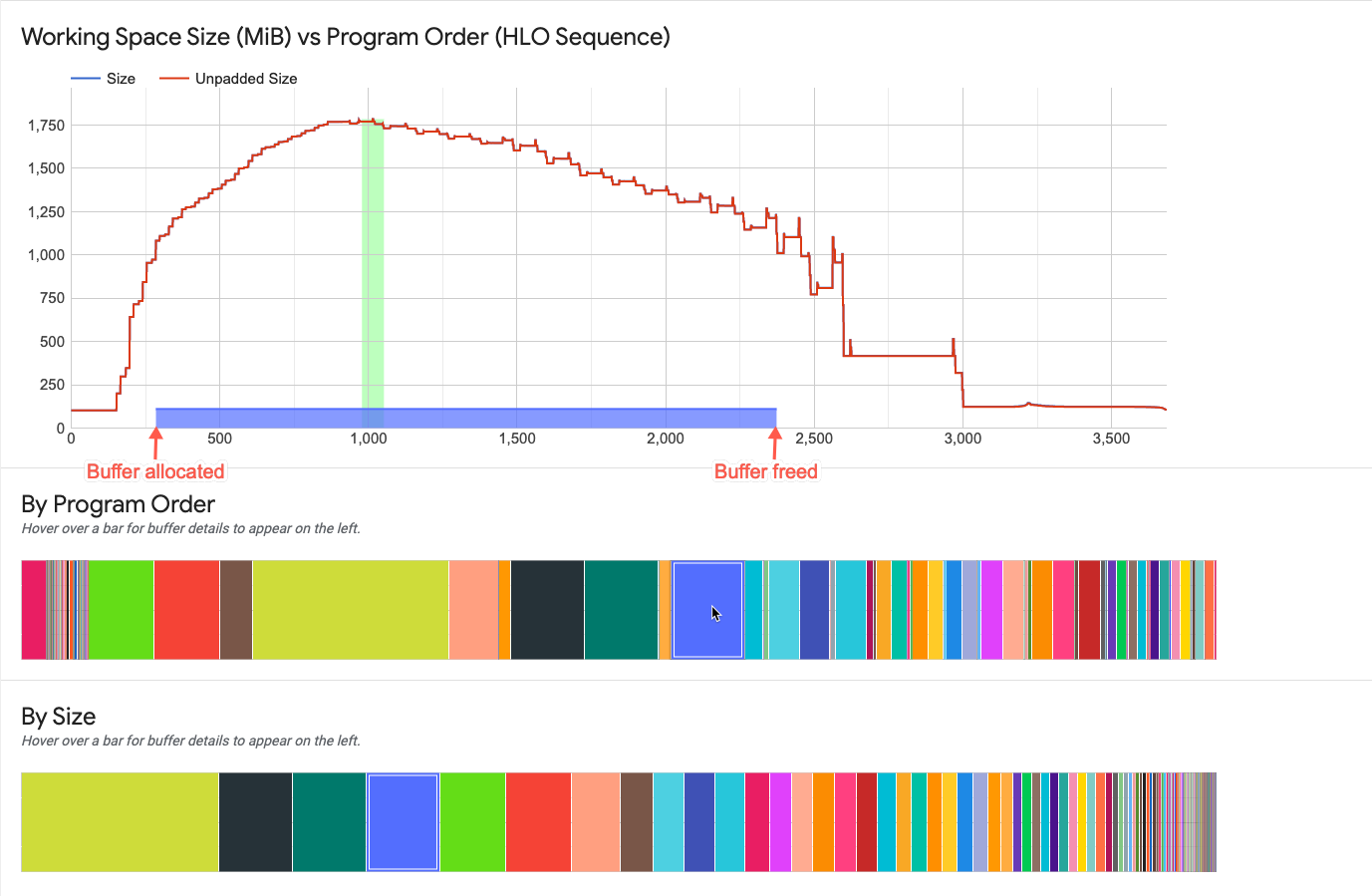
水平线的粗细程度表示缓冲区大小与峰值内存分配的相对量级。线条的长度表示缓冲区的生命周期。
缓冲区图表
这两个图表显示了峰值使用量处的内存使用量明细。
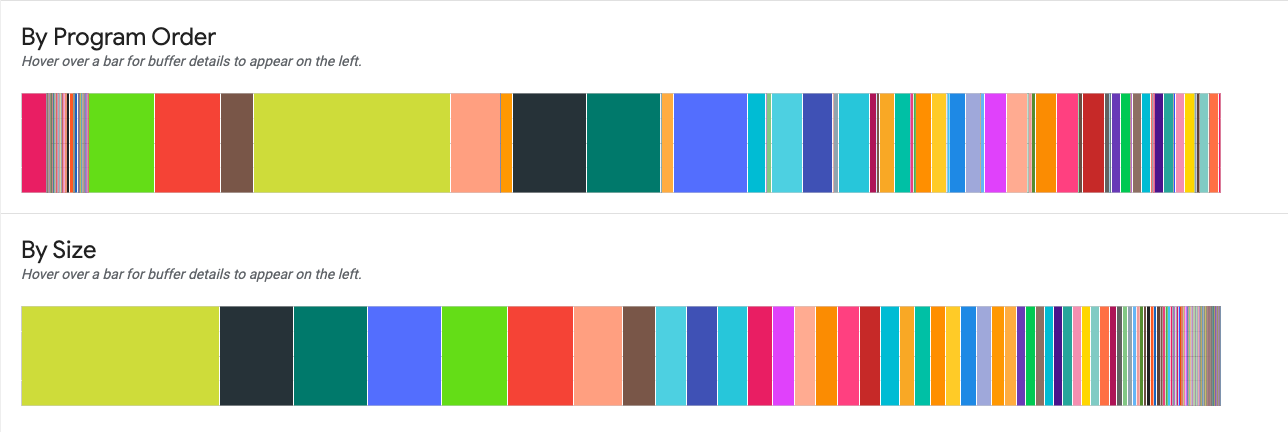
按程序顺序:按程序执行期间缓冲区的活动顺序从左到右显示缓冲区。
按大小:按大小从大到小显示程序执行期间的活动缓冲区。
缓冲区分配详细信息卡片
当您将光标指向其中一个缓冲区图表中显示的缓冲区时,系统会显示缓冲区分配详细信息卡片。典型的详细信息卡片如下所示:
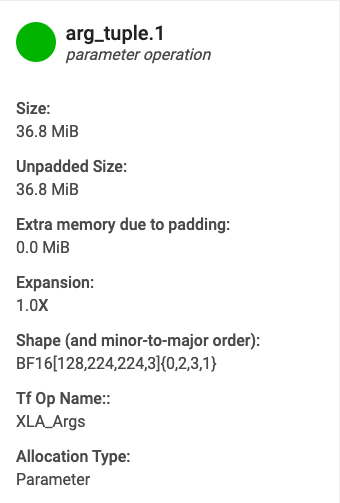
- 名称:XLA 操作的名称。
- 类别:操作类别。
- 大小:缓冲区分配的大小(包括填充)。
- 未填充大小:未填充的缓冲区分配的大小。
- 膨胀:填充的缓冲区大小与未填充的缓冲区大小的相对量级。
- 额外内存:指示填充额外使用了多少内存量。
- 形状:描述 N 维数组的阶、大小和数据类型。
- TensorFlow 操作名称:显示与缓冲区分配关联的 TensorFlow 操作名称。
- 分配类型:指示缓冲区分配类别:参数、输出、线程局部和临时(例如某个融合中的缓冲区分配)。
内存不足错误
如果运行模型时出现“内存不足”错误,请按照本文档中的准则捕获配置文件。等待脚本训练模型,然后再启动性能分析器。性能分析输出可以帮助您了解导致错误的原因。