Preserve o progresso da preparação com a funcionalidade Autocheckpoint
Historicamente, quando uma VM de TPU requer manutenção, o procedimento é iniciado imediatamente, sem dar tempo aos utilizadores para realizarem ações de preservação do progresso, como guardar um ponto de verificação. Isto é mostrado na Figura 1(a).
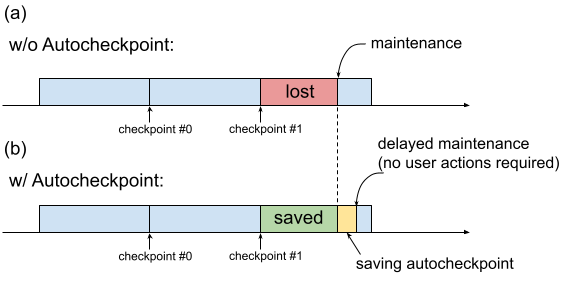
Fig. 1. Ilustração da funcionalidade de verificação automática: (a) Sem a verificação automática, o progresso da preparação do último ponto de verificação perde-se quando existe um evento de manutenção futuro. (b) Com o Autocheckpoint, o progresso da preparação desde o último ponto de verificação pode ser preservado quando existir um evento de manutenção futuro.
Pode usar o Autocheckpoint (Figura 1(b)) para preservar o progresso da preparação configurando o seu código para guardar um ponto de verificação não agendado quando ocorre um evento de manutenção. Quando ocorre um evento de manutenção, o progresso desde o último ponto de verificação é guardado automaticamente. A funcionalidade funciona com fatias únicas e com a funcionalidade de várias fatias.
A funcionalidade Autocheckpoint funciona com frameworks que podem capturar sinais SIGTERM e, posteriormente, guardar um ponto de verificação. Os frameworks suportados incluem:
Usar o Autocheckpoint
A funcionalidade de verificação automática está desativada por predefinição. Quando cria uma
TPU ou pede um recurso em fila,
pode ativar a verificação automática adicionando a flag --autocheckpoint-enabled quando aprovisiona
a TPU.
Com a funcionalidade ativada, o Cloud TPU
executa os seguintes passos assim que recebe uma notificação de um
evento de manutenção:
- Capture o sinal SIGTERM enviado para o processo através do dispositivo TPU
- Aguarde até que o processo termine ou que decorram 5 minutos, conforme o que ocorrer primeiro
- Faça a manutenção das fatias afetadas
A infraestrutura usada pelo Autocheckpoint é independente da framework de ML. Qualquer framework de ML pode suportar a funcionalidade Autocheckpoint se conseguir capturar o sinal SIGTERM e iniciar um processo de criação de pontos de verificação.
No código da aplicação, tem de ativar as capacidades do Autocheckpoint fornecidas pela framework de ML. No Pax, por exemplo, isto significa ativar as flags da linha de comandos quando iniciar a preparação. Para mais informações, consulte o início rápido do Autocheckpoint com o Pax. Nos bastidores, as frameworks guardam um ponto de verificação não agendado quando é recebido um sinal SIGTERM e a VM de TPU afetada passa por manutenção quando a TPU deixa de estar em utilização.
Início rápido: Autocheckpoint com MaxText
O MaxText é um LLM de código aberto, de elevado desempenho, arbitrariamente escalável e bem testado, escrito em Python/JAX puro, direcionado para TPUs na nuvem. O MaxText contém toda a configuração necessária para usar a funcionalidade Autocheckpoint.
O ficheiro MaxText descreve duas formas de executar o MaxText em grande escala:README
- Usar
multihost_runner.py, recomendado para experimentação - Usar
multihost_job.py, recomendado para produção
Quando usar multihost_runner.py, ative o Autocheckpoint definindo a flag autocheckpoint-enabled ao aprovisionar o recurso em fila.
Quando usar o
multihost_job.py, ative o Autocheckpoint especificando a flag da linha de comandos
ENABLE_AUTOCHECKPOINT=true quando iniciar a tarefa.
Início rápido: verificação automática com o Pax numa única fatia
Esta secção fornece um exemplo de como configurar e usar o Autocheckpoint com o Pax numa única fatia. Com a configuração adequada:
- É guardado um ponto de verificação quando ocorre um evento de manutenção.
- O Cloud TPU realiza a manutenção nas VMs da TPU afetadas após a gravação do ponto de verificação.
- Quando a manutenção da Cloud TPU estiver concluída, pode usar a VM de TPU como habitualmente.
Use a flag
autocheckpoint-enabledquando criar a VM de TPU ou pedir um recurso em fila.Por exemplo:
Defina variáveis de ambiente:
export PROJECT_ID=your-project-id export TPU_NAME=your-tpu-name export ZONE=zone-you-want-to-use export ACCELERATOR_TYPE=your-accelerator-type export RUNTIME_VERSION=tpu-ubuntu2204-base
Descrições das variáveis de ambiente
Variável Descrição PROJECT_IDO seu Google Cloud ID do projeto. Use um projeto existente ou crie um novo. TPU_NAMEO nome da TPU. ZONEA zona na qual criar a VM da TPU. Para mais informações sobre as zonas suportadas, consulte o artigo Regiões e zonas de TPUs. ACCELERATOR_TYPEO tipo de acelerador especifica a versão e o tamanho do Cloud TPU que quer criar. Para mais informações sobre os tipos de aceleradores suportados para cada versão da TPU, consulte o artigo Versões da TPU. RUNTIME_VERSIONA versão do software do Cloud TPU. Defina o ID do projeto e a zona na configuração ativa:
gcloud config set project $PROJECT_ID gcloud config set compute/zone $ZONE
Crie uma TPU:
gcloud alpha compute tpus tpu-vm create $TPU_NAME \ --accelerator-type $ACCELERATOR_TYPE \ --version $RUNTIME_VERSION \ --autocheckpoint-enabled
Estabeleça ligação à TPU através de SSH:
gcloud compute tpus tpu-vm ssh $TPU_NAMEInstale o Pax numa única fatia
A funcionalidade de verificação automática funciona nas versões 1.1.0 e posteriores do Pax. Na VM da TPU, instale o
jax[tpu]e a versão mais recente dopaxml:pip install paxml && pip install jax[tpu] -f https://storage.googleapis.com/jax-releases/libtpu_releases.html
Configure o modelo
LmCloudSpmd2B. Antes de executar o script de preparação, altereICI_MESH_SHAPEpara[1, 8, 1]:@experiment_registry.register class LmCloudSpmd2B(LmCloudSpmd): """SPMD model with 2B params. Global batch size = 2 * 2 * 1 * 32 = 128 """ PERCORE_BATCH_SIZE = 8 NUM_LAYERS = 18 MODEL_DIMS = 3072 HIDDEN_DIMS = MODEL_DIMS * 4 CHECKPOINT_POLICY = layers.AutodiffCheckpointType.SAVE_NOTHING ICI_MESH_SHAPE = [1, 8, 1]
Inicie a preparação com a configuração adequada.
O exemplo seguinte mostra como configurar o modelo
LmCloudSpmd2Bpara guardar pontos de verificação acionados pelo Autocheckpoint num contentor do Cloud Storage. Substitua your-storage-bucket pelo nome de um contentor existente ou crie um novo contentor.export JOB_LOG_DIR=gs://your-storage-bucket { python3 .local/lib/python3.10/site-packages/paxml/main.py \ --jax_fully_async_checkpoint=1 \ --exit_after_ondemand_checkpoint=1 \ --exp=tasks.lm.params.lm_cloud.LmCloudSpmd2B \ --job_log_dir=$JOB_LOG_DIR; } 2>&1 | tee pax_logs.txt
Tenha em atenção os dois indicadores transmitidos ao comando:
jax_fully_async_checkpoint: Com esta flag ativada, é usado oorbax.checkpoint.AsyncCheckpointer. A classeAsyncCheckpointerguarda automaticamente um ponto de verificação quando o script de preparação recebe um sinal SIGTERM.exit_after_ondemand_checkpoint: Com esta flag ativada, o processo da TPU termina após a gravação bem-sucedida do ponto de verificação automático, o que aciona a manutenção para ser realizada imediatamente. Se não usar esta flag, a preparação continua após a poupança do ponto de verificação e o Cloud TPU aguarda um limite de tempo (5 minutos) antes de realizar a manutenção necessária.
Autocheckpoint com Orbax
A funcionalidade de verificação automática não se limita ao MaxText nem ao Pax. Qualquer framework que possa capturar o sinal SIGTERM e iniciar um processo de criação de pontos de verificação funciona com a infraestrutura fornecida pela Autocheckpoint. O Orbax, um espaço de nomes que fornece bibliotecas de utilidades comuns para utilizadores do JAX, oferece estas capacidades.
Conforme explicado na documentação do Orbax,
estas capacidades estão ativadas por predefinição para os utilizadores
do orbax.checkpoint.CheckpointManager. O método save que é chamado após cada passo verifica automaticamente se um evento de manutenção é iminente e, se for, guarda um ponto de verificação, mesmo que o número do passo não seja um múltiplo de save_interval_steps.
A documentação do GitHub
também ilustra como fazer com que o treino termine após guardar um
ponto de verificação automático, com uma modificação no código do utilizador.