Conserver la progression de l'entraînement à l'aide d'Autocheckpoint
Historiquement, lorsqu'une VM TPU nécessite une intervention de maintenance, la procédure est lancée immédiatement, sans laisser le temps aux utilisateurs conserver leur progression en créant par exemple un point de contrôle. C'est ce qu'illustre la figure 1(a).
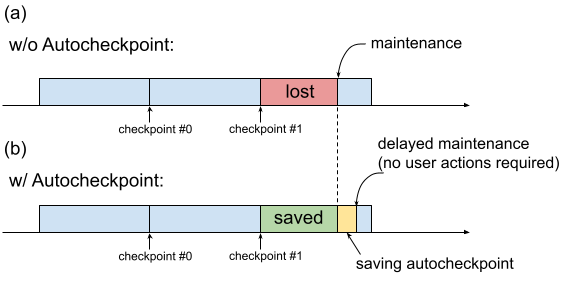
Fig. 1. Illustration de la fonctionnalité Autocheckpoint : (a) Sans Autocheckpoint, la progression de l'entraînement depuis le dernier point de contrôle est perdue en cas d'événement de maintenance à venir. (b) Avec Autocheckpoint, la progression de l'entraînement depuis le dernier point de contrôle peut être conservée en cas d'événement de maintenance à venir.
Autocheckpoint (Figure 1(b)) vous permet de conserver la progression de l'entraînement. Pour cela, vous devez configurer votre code afin qu'il enregistre un point de contrôle non planifié lorsqu'un événement de maintenance se produit. Lorsqu'un événement de maintenance se produit, la progression depuis le dernier point de contrôle est automatiquement enregistrée. Cette fonctionnalité est disponible à la fois pour les tranches uniques et le multitranche.
Autocheckpoint fonctionne avec les frameworks capables de capturer les signaux SIGTERM et d'enregistrer ensuite un point de contrôle. Voici les frameworks compatibles :
Utiliser Autocheckpoint
Autocheckpoint est désactivé par défaut. Lorsque vous créez un TPU ou demandez une ressource en file d'attente, vous pouvez activer Autocheckpoint en ajoutant le flag --autocheckpoint-enabled lors du provisionnement du TPU.
Lorsque cette fonctionnalité est activée, Cloud TPU effectue les étapes suivantes dès lors qu'il reçoit une notification d'événement de maintenance :
- Il capture le signal SIGTERM envoyé au processus à l'aide de l'appareil TPU.
- Il attend la fin du processus, ou que cinq minutes se soient écoulées, selon la situation qui se présente en premier.
- Il effectue la maintenance des tranches concernées.
L'infrastructure utilisée par Autocheckpoint est indépendante du framework de ML. Tout framework de ML capable de capturer le signal SIGTERM et d'initier un processus de point de contrôle peut prendre en charge la fonctionnalité Autocheckpoint.
Dans le code de l'application, vous devez activer les outils Autocheckpoint fournis par le framework de ML. Dans Pax, par exemple, vous devrez activer les flags de ligne de commande lors du lancement de l'entraînement. Pour en savoir plus, consultez le guide de démarrage rapide d'Autocheckpoint avec Pax. En arrière-plan, les frameworks enregistrent un point de contrôle non planifié lorsqu'un signal SIGTERM est reçu, et la VM TPU concernée subit une intervention de maintenance lorsque le TPU n'est plus utilisé.
Guide de démarrage rapide : Autocheckpoint avec MaxText
MaxText est un LLM Open Source hautes performances, évolutif à volonté et bien testé, écrit en Python/JAX pur et ciblant les Cloud TPU. MaxText dispose de la configuration nécessaire pour utiliser la fonctionnalité Autocheckpoint.
Le fichier MaxText README décrit deux façons d'exécuter MaxText à grande échelle :
- Avec
multihost_runner.py, recommandé pour les tests - Avec
multihost_job.py, recommandé pour la production
Lorsque vous utilisez multihost_runner.py, activez Autocheckpoint en définissant le fag autocheckpoint-enabled lors du provisionnement de la ressource en file d'attente.
Lorsque vous utilisez multihost_job.py, activez Autocheckpoint en spécifiant le flag de ligne de commande ENABLE_AUTOCHECKPOINT=true lorsque vous lancez le job.
Guide de démarrage rapide : Autocheckpoint avec Pax sur une seule tranche
Cette section fournit un exemple de configuration et d'utilisation d'Autocheckpoint avec Pax sur une seule tranche. Avec la configuration appropriée :
- Un point de contrôle est enregistré lorsqu'un événement de maintenance se produit.
- Cloud TPU effectue la maintenance sur les VM TPU concernées une fois le point de contrôle enregistré.
- Une fois la maintenance terminée, vous pouvez utiliser la VM TPU normalement.
Utilisez le flag
autocheckpoint-enabledlorsque vous créez la VM TPU ou que vous demandez une ressource en file d'attente.Exemple :
Définissez les variables d'environnement :
export PROJECT_ID=your-project-id export TPU_NAME=your-tpu-name export ZONE=zone-you-want-to-use export ACCELERATOR_TYPE=your-accelerator-type export RUNTIME_VERSION=tpu-ubuntu2204-base
Descriptions des variables d'environnement
Variable Description PROJECT_IDID de votre projet Google Cloud . Utilisez un projet existant ou créez-en un. TPU_NAMENom du TPU. ZONEZone dans laquelle créer la VM TPU. Pour en savoir plus sur les zones compatibles, consultez Régions et zones TPU. ACCELERATOR_TYPELe type d'accélérateur spécifie la version et la taille du Cloud TPU que vous souhaitez créer. Pour en savoir plus sur les types d'accélérateurs compatibles avec chaque version de TPU, consultez Versions de TPU. RUNTIME_VERSIONVersion logicielle de Cloud TPU. Définissez votre ID de projet et votre zone dans votre configuration active :
gcloud config set project $PROJECT_ID gcloud config set compute/zone $ZONE
Créez un TPU :
gcloud alpha compute tpus tpu-vm create $TPU_NAME \ --accelerator-type $ACCELERATOR_TYPE \ --version $RUNTIME_VERSION \ --autocheckpoint-enabled
Connectez-vous au TPU via SSH :
gcloud compute tpus tpu-vm ssh $TPU_NAMEInstaller Pax sur une seule tranche
Autocheckpoint fonctionne sur les versions 1.1.0 et ultérieures de Pax. Sur la VM TPU, installez
jax[tpu]ainsi que la dernière version depaxml:pip install paxml && pip install jax[tpu] -f https://storage.googleapis.com/jax-releases/libtpu_releases.html
Configurez le modèle
LmCloudSpmd2B. Avant d'exécuter le script d'entraînement, remplacezICI_MESH_SHAPEpar[1, 8, 1]:@experiment_registry.register class LmCloudSpmd2B(LmCloudSpmd): """SPMD model with 2B params. Global batch size = 2 * 2 * 1 * 32 = 128 """ PERCORE_BATCH_SIZE = 8 NUM_LAYERS = 18 MODEL_DIMS = 3072 HIDDEN_DIMS = MODEL_DIMS * 4 CHECKPOINT_POLICY = layers.AutodiffCheckpointType.SAVE_NOTHING ICI_MESH_SHAPE = [1, 8, 1]
Lancez l'entraînement avec la configuration appropriée.
L'exemple suivant montre comment configurer le modèle
LmCloudSpmd2Bpour enregistrer les points de contrôle déclenchés par Autocheckpoint dans un bucket Cloud Storage. Remplacez your-storage-bucket par le nom d'un bucket existant ou créez-en un.export JOB_LOG_DIR=gs://your-storage-bucket { python3 .local/lib/python3.10/site-packages/paxml/main.py \ --jax_fully_async_checkpoint=1 \ --exit_after_ondemand_checkpoint=1 \ --exp=tasks.lm.params.lm_cloud.LmCloudSpmd2B \ --job_log_dir=$JOB_LOG_DIR; } 2>&1 | tee pax_logs.txt
Relevez les deux flags transmis à la commande :
jax_fully_async_checkpoint: lorsque ce flag est activé,orbax.checkpoint.AsyncCheckpointerest utilisé. La classeAsyncCheckpointerenregistre automatiquement un point de contrôle lorsque le script d'entraînement reçoit un signal SIGTERM.exit_after_ondemand_checkpoint: lorsque ce flag est activé, le processus TPU se termine une fois le point de contrôle automatique enregistré, ce qui déclenche la maintenance immédiate. Si vous n'utilisez pas ce flag, l'entraînement se poursuit après l'enregistrement du point de contrôle, et Cloud TPU attend un délai d'inactivité (5 minutes) avant d'effectuer la maintenance requise.
Autocheckpoint avec Orbax
Autocheckpoint ne fonctionne pas seulement avec MaxText ou Pax. Tout framework capable de capturer le signal SIGTERM et d'initier un processus de point de contrôle est compatible avec l'infrastructure fournie par Autocheckpoint. Orbax, un espace de noms qui fournit des bibliothèques utilitaires courantes pour les utilisateurs de JAX, en fait partie.
Comme expliqué dans la documentation Orbax, les fonctionnalités nécessaires sont activées par défaut pour les utilisateurs de orbax.checkpoint.CheckpointManager. La méthode save appelée après chaque pas vérifie automatiquement si un événement de maintenance est imminent et, le cas échéant, enregistre un point de contrôle même si le numéro du pas n'est pas un multiple de save_interval_steps.
La documentation GitHub décrit également comment provoquer l'arrêt de l'entraînement après l'enregistrement d'un point de contrôle automatique, en modifiant le code utilisateur.