您可以使用 API 建立及訓練自訂 Speech-to-Text 模型,藉此提升現有 Speech-to-Text 模型的辨識準確度,完全不必編寫任何程式碼。這項全代管服務會自動佈建運算資源、執行訓練應用程式程式碼,並確保在訓練工作完成後刪除運算資源。您會獲得經過完整微調的語音轉錄模型,適用於任何下游應用程式。
與機器學習模型類似,訓練自訂 Speech-to-Text 模型通常需要反覆進行,包括選取基礎模型做為起點、使用文字和音訊資料集微調,然後測試模型的辨識品質。如果結果不符預期,您可以重新訓練新模型,並使用不同的資料組合、再次測試,或直接在網域中用於轉錄。
事前準備
請確認您已註冊 Google Cloud 帳戶、建立 Google Cloud 專案,並啟用 Speech-to-Text API:前往 Google Cloud 控制台的「Speech」(語音) ,然後前往 Speech-to-Text API。在左側導覽列的「自訂模型」部分操作。
建立自訂模型
首先,請建立自訂語音轉文字模型,並定義其參數,例如基礎模型和轉錄語言:
- 按一下「建立」,建立自訂模型。
- 輸入模型名稱,這個名稱會用於顯示,並在 API 要求和 Google Cloud 語音控制台中做為參照。
- 輸入模型的說明。
- 選取最適合您用途的基礎模型。
- 選取模型的語音轉錄語言。
- 選取要進行訓練的「Region」(區域)。
- 按一下「繼續」。
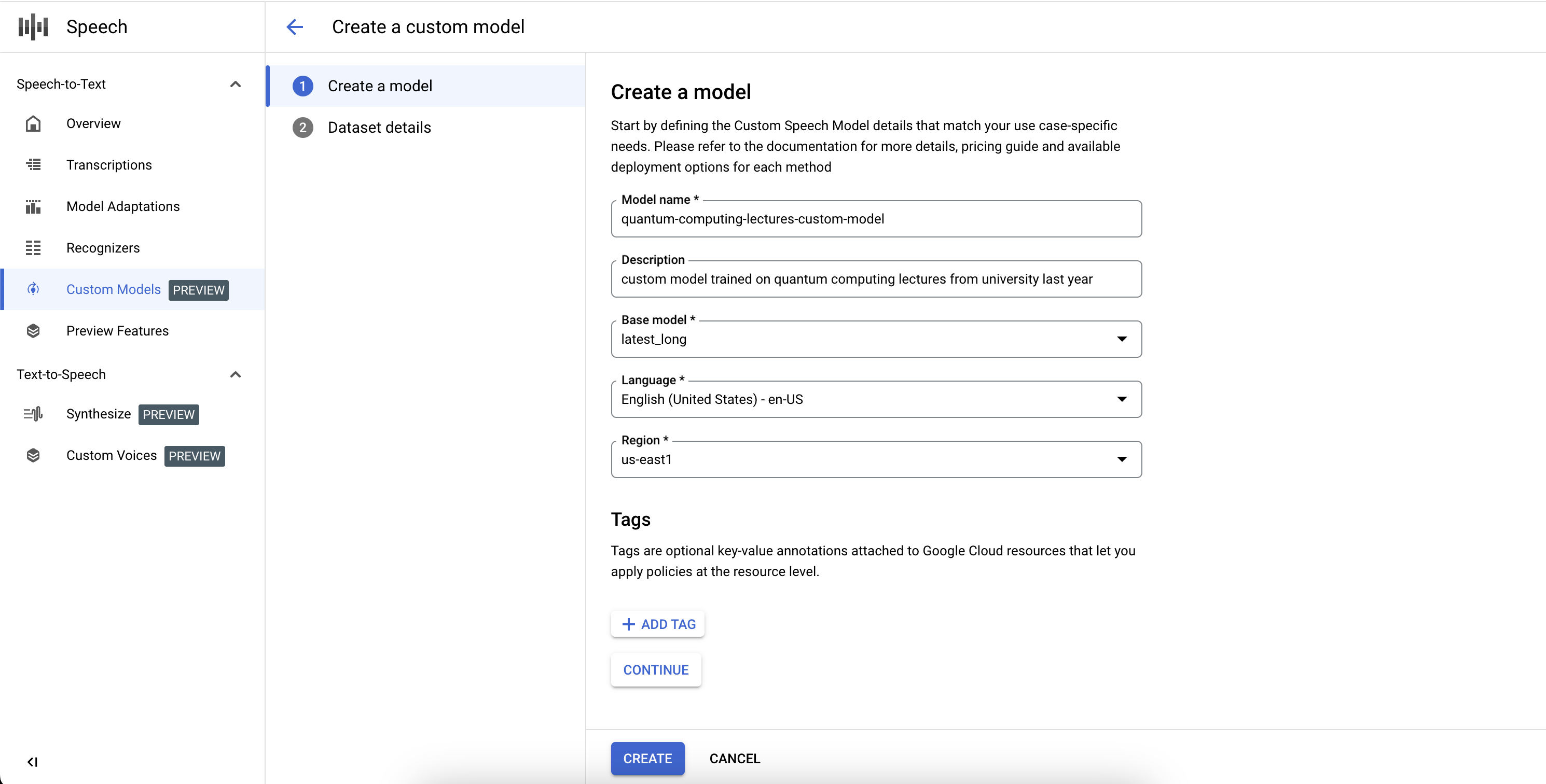
如要完成自訂語音轉文字模型工作的定義並開始訓練,您需要定義訓練和驗證資料集。
- 提供有效的 Cloud Storage 目錄 URI,選取訓練資料集。確認只有音訊和文字檔案,且音訊總長度符合訓練資料集規定。
- 提供有效的 Cloud Storage 目錄 URI,選取驗證資料集。確認只有音訊和文字檔,且音訊總長度符合驗證資料集規定。
- 按一下「建立」即可啟動訓練程序。
如果索引的音訊時數不足,或檔案不符合規範,訓練工作就會失敗。
訓練工作可能會在系統中排在其他工作之後,而訓練模型可能需要幾小時到幾天不等,視資料集大小而定。模型訓練完成後,狀態會標示為「已啟用」。
刪除自訂模型
開始前,請確認沒有任何端點將流量導向自訂語音轉文字模型,因為刪除模型後,系統就會停止處理任何要求。
- 前往「自訂模型」部分的「模型」分頁。
- 按一下展開選項,然後點選「刪除」。系統會在幾分鐘內刪除自訂語音轉文字模型和所有端點,且模型將不再提供任何流量。
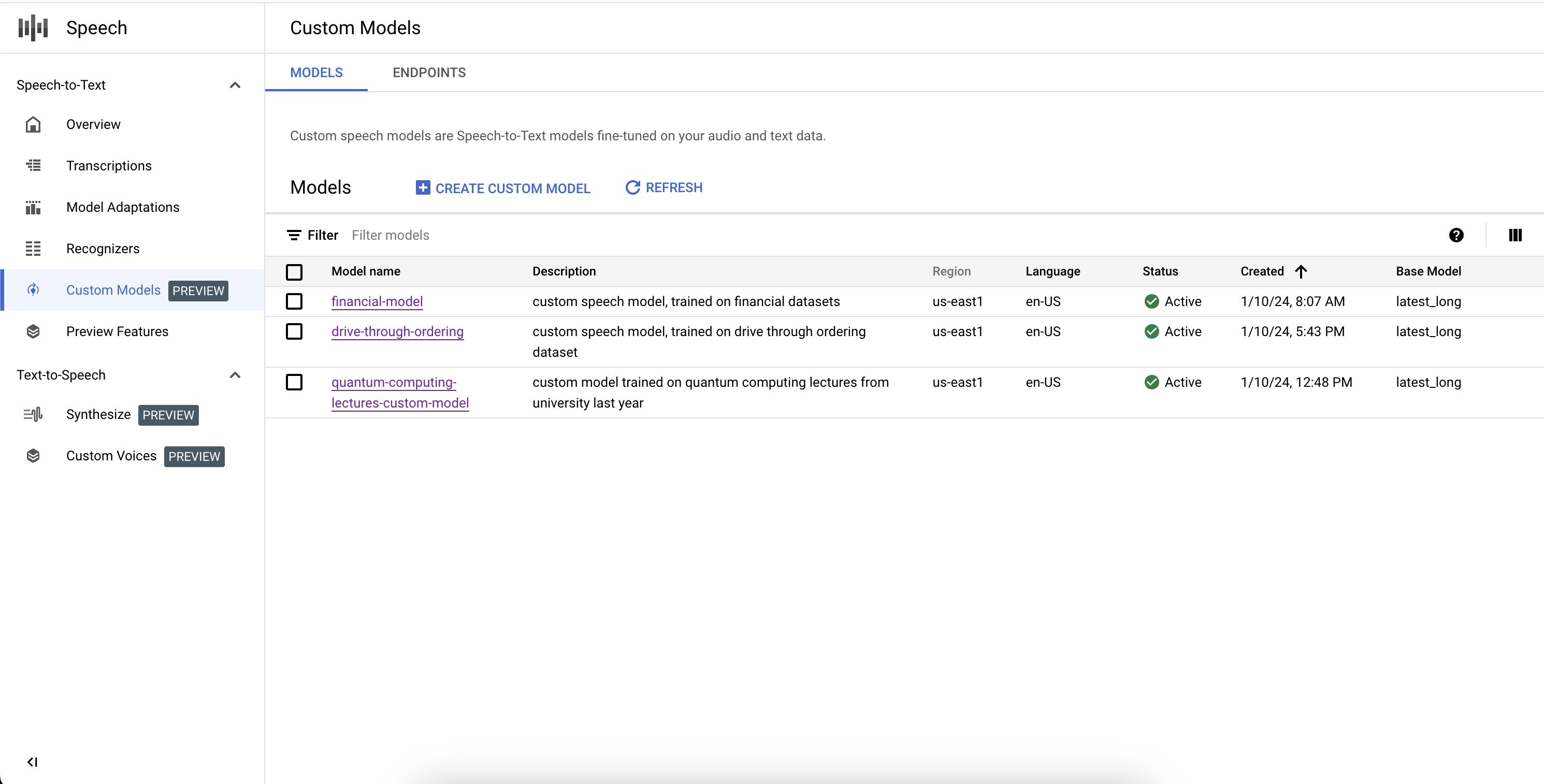
列出自訂模型
選取「自訂模型」部分中的「模型」,即可列出所有自訂語音轉文字模型,包括訓練中、有效和刪除中的模型。
後續步驟
請參閱下列資源,瞭解如何在應用程式中運用自訂語音模型: