在實際工作環境應用程式或基準化工作流程中使用訓練好的 Custom Speech-to-Text 模型。您必須透過專用端點部署及公開模型,而建立專用端點的部分目的是在所選區域中部署模型。您會透過辨識器物件自動取得程式輔助存取權。可透過 V2 API 直接使用,或在 Google Cloud 控制台使用。您可以在與訓練模型不同的區域部署模型,但系統會在端點指定的區域建立模型副本。
如要使用自訂語音模型,您必須透過專屬端點部署及公開模型。建立端點時,您會在所選區域部署模型。系統會透過辨識器物件自動授予程式輔助存取權,供您直接透過 V2 API 進行推論,或在 Google Cloud 控制台中使用。
事前準備
請確認您已註冊 Google Cloud 帳戶、建立專案,並訓練自訂語音模型。
- 前往 Google Cloud 控制台的「Speech」,然後前往 Speech-to-Text。
- 在左側導覽列的「自訂模型」部分中導覽。
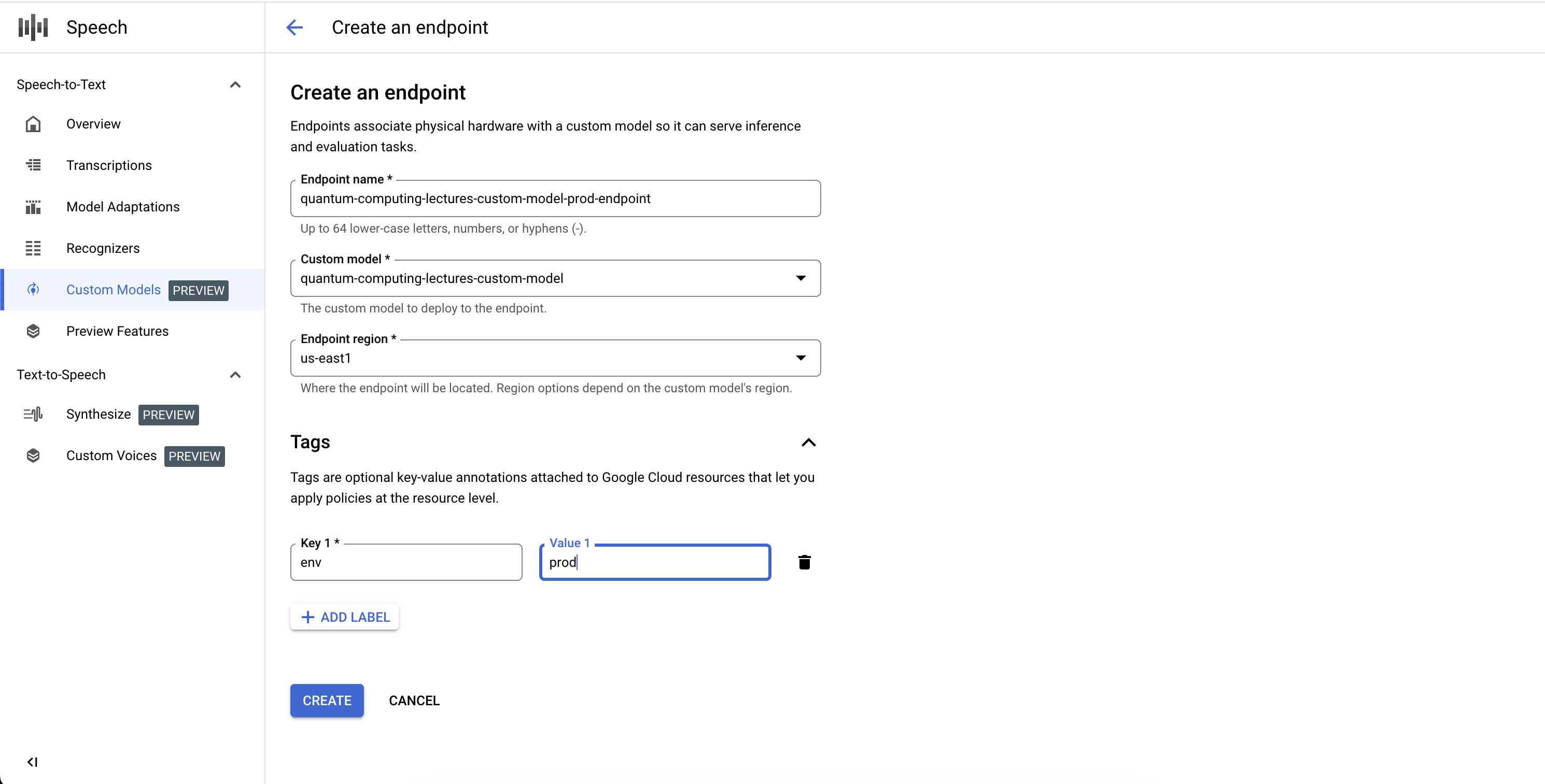
建立端點
- 前往「自訂模型」部分的「端點」分頁。
- 按一下「新增端點」。
- 定義端點名稱。這是端點資源的專屬 ID,用於叫用自訂語音模型進行推論。
- 定義要部署自訂語音模型的區域。如果模型是在與端點設定中定義的區域不同的區域訓練,系統會自動建立新的模型副本。
- 從清單中選取要透過端點公開的訓練完成自訂語音模型。
- 按一下「建立」,稍待片刻,自訂語音模型就會部署至端點,可供推論和基準化。
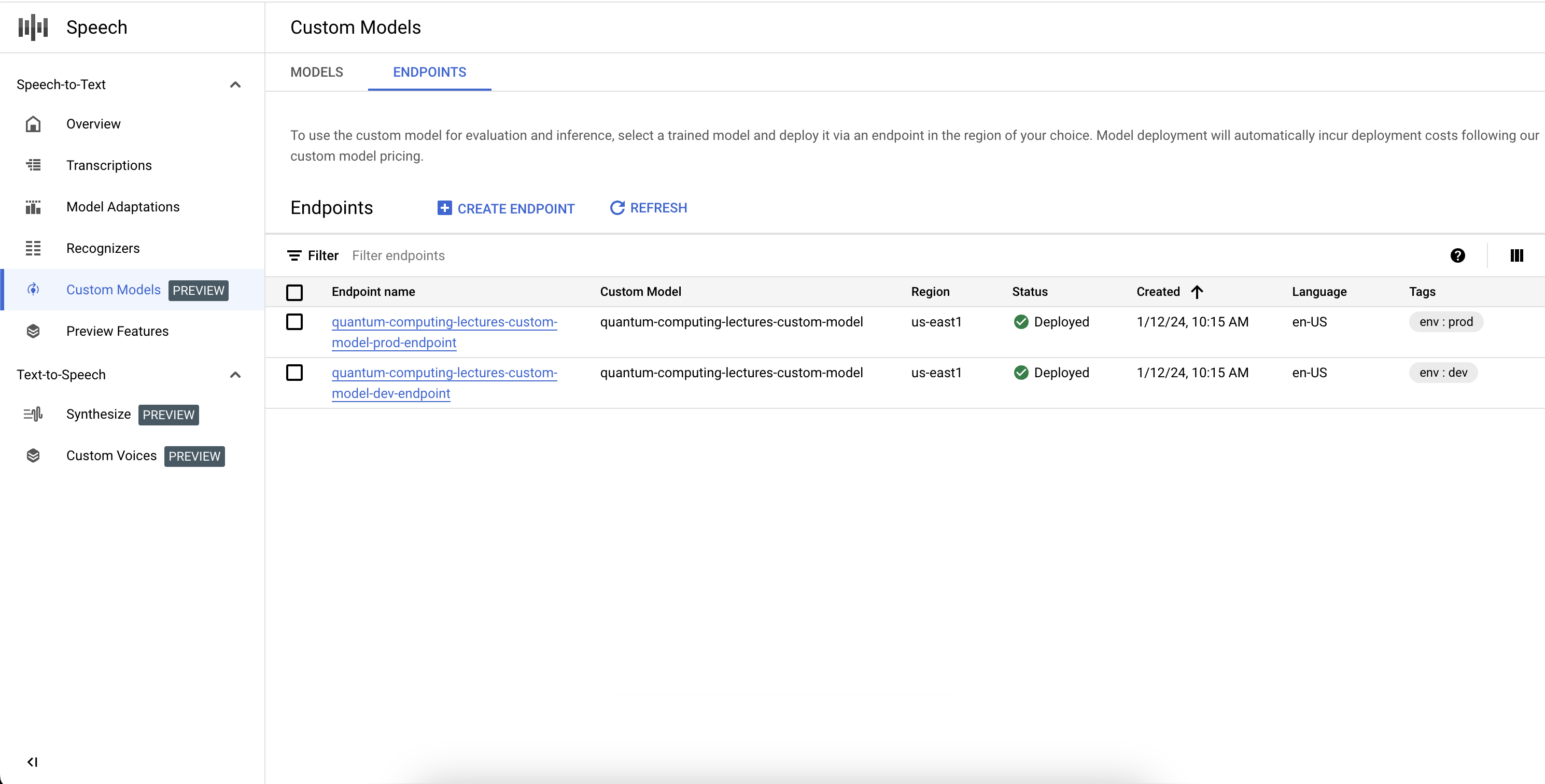
列出端點
如要管理相關聯的端點,請選取「自訂模型」部分下方的「端點」分頁。您也可以在控制台中列出您建立的端點,以及這些端點的目前狀態和相關聯的自訂語音轉文字模型。
刪除端點
開始前,請確認沒有任何流量透過端點轉送,因為刪除端點後,端點將停止處理任何要求。
- 前往「自訂模型」部分的「端點」分頁。
- 在「端點」分頁下方,按一下展開選項,然後點選「刪除」。過一會兒,端點就會刪除,不再提供任何流量。
將模型基準化
使用自訂語音轉文字模型和基準資料集評估模型準確度,然後按照「評估及提升準確度」指南操作。