客戶
Spanner 支援 SQL 查詢。以下是範例查詢:
SELECT s.SingerId, s.FirstName, s.LastName, s.SingerInfo
FROM Singers AS s
WHERE s.FirstName = @firstName;
@firstName 建構參照到查詢參數。可以使用文字值的地方就可以使用查詢參數。我們強烈建議您在程式輔助的 API 中使用參數。使用查詢參數可協助避免 SQL 植入攻擊,也讓產出的查詢更有可能利用多個伺服器端快取。請參閱下方的「快取」一節。
執行查詢時,查詢參數必須與值繫結。例如:
Statement statement =
Statement.newBuilder("SELECT s.SingerId...").bind("firstName").to("Jimi").build();
try (ResultSet resultSet = dbClient.singleUse().executeQuery(statement)) {
while (resultSet.next()) {
...
}
}
當 Spanner 接收到 API 呼叫時,便會分析查詢並繫結參數,判斷哪一個 Spanner 伺服器節點應處理這個查詢。伺服器會傳回呼叫 ResultSet.next() 所使用的一連串結果資料列。
查詢執行
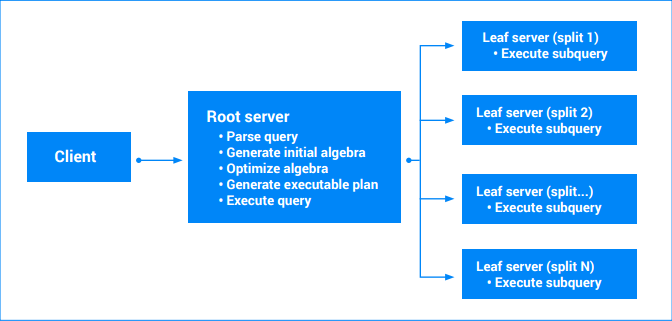
查詢執行的開頭是收到某個 Spanner 伺服器的「執行查詢」請求。伺服器會執行以下步驟:
- 驗證要求
- 剖析查詢文字
- 產生初始查詢代數
- 產生最佳化查詢代數
- 產生可執行的查詢計劃
- 執行計劃 (檢查權限、讀取資料、編碼結果等)
剖析
SQL 剖析器會分析查詢文字,並將查詢文字轉換成抽象語法樹。它會擷取基本的查詢結構 (SELECT …
FROM … WHERE …),然後進行語法檢查。
代數
Spanner 的類型系統可以表示純量、陣列和結構等等。查詢的代數會定義資料表掃描、篩選、排序/分組、各種形式的加入、匯總以及其他等運算子。初始的查詢代數是以剖析器的輸出做為建構基礎。剖析樹的欄位名稱參照是使用資料庫結構定義解析而來。此程式碼也會檢查語意錯誤,例如不正確的參數數量、類型不符等。
下一個步驟 (「查詢最佳化」) 使用初始的代數並產生更佳的代數,這可能較簡單、較有效率,或者更適合執行引擎功能。例如,初始的代數可能僅指定「加入」,而優化的代數則指定「雜湊加入」。
執行
最終可執行的查詢計劃是以重新寫入的代數做為建構基礎。基本上,可執行的計劃是「疊代器」的有向無環圖。每個疊代器都會公開一系列的值。疊代器可能會使用輸入來產生輸出 (例如排序疊代器)。涉及單一分割的查詢可由單一伺服器 (儲存資料的伺服器) 執行。該伺服器會掃描數個資料表的範圍、執行加入、執行匯總,以及其他由查詢代數定義的所有作業。
涉及多種分割的查詢會列為多個片段。有些查詢會在主要 (根) 伺服器上持續執行,其他部分子查詢則會移交給分葉節點 (擁有正在讀取的分割的節點)。針對複雜的查詢,此移交能夠重複套用,產生伺服器執行的樹狀結構。所有伺服器都有一致的時間戳記,因此查詢結果是資料的一致快照。每個分葉伺服器都會傳回一系列的部分結果。針對涉及匯總的查詢,這些可能是部分匯總的結果。查詢根伺服器會處理來自分葉伺服器的結果,並執行剩餘的查詢計劃。詳情請參閱「查詢執行計劃」。
如果查詢涉及多個分割作業,Spanner 可以跨分割作業平行執行查詢。平行處理的程度取決於查詢掃描的資料範圍、查詢執行計畫,以及資料在分割區中的分布情形。Spanner 會根據執行個體大小和執行個體設定 (區域或多區域),自動設定查詢的並行處理上限,以便達到最佳查詢效能,並避免CPU 超載。
快取
系統會自動快取查詢處理的許多成果,重新使用在後續的查詢中。這包含查詢代數、可執行的查詢計劃等。系統會根據查詢文字、名稱、繫結參數的類型等進行快取。這也是在查詢文字中使用繫結參數 (例如上方範例中的 @firstName) 比使用文字值來得好的原因。無論實際的繫結值為何,若使用繫結參數,則只能快取一次並重複使用。詳情請參閱「最佳化 Spanner 查詢效能」。
處理錯誤
executeQuery 方法的結果資料列串流可能會因多種原因中斷,例如:暫時性網路錯誤、從一個伺服器將分割交接至另一個伺服器 (例如負載平衡)、伺服器重新啟動 (例如升級至新版本) 等。為協助復原這些錯誤,Spanner 會傳送不透明的「繼續執行權杖」,以及部分結果資料批次。這些繼續憑證可用來重試查詢,繼續中斷的查詢作業。若使用 Spanner 用戶端程式庫,這個作業會自動執行;因此,用戶端程式庫的使用者不需要擔心這類暫時錯誤。