Membuat kebijakan pemberitahuan untuk SLO
Halaman ini menjelaskan cara membuat kebijakan pemberitahuan di Cloud Monitoring untuk tujuan tingkat layanan (SLO) yang Anda buat di Cloud Service Mesh.
Untuk pengantar SLO, lihat Ringkasan tujuan tingkat layanan.
Cloud Monitoring dapat memicu pemberitahuan saat Layanan akan melanggar SLO. Anda dapat membuat kebijakan pemberitahuan berdasarkan tingkat penggunaan anggaran error. Semua pemberitahuan tentang anggaran error memiliki kondisi dasar yang sama: persentase yang ditentukan dari anggaran error untuk periode kepatuhan digunakan dalam periode lihat balik, yang merupakan jangka waktu, seperti 60 menit sebelumnya. Saat Anda membuat kebijakan pemberitahuan, Cloud Service Mesh akan otomatis menetapkan sebagian besar kondisi untuk pemberitahuan berdasarkan setelan di SLO. Anda menentukan periode lihat balik dan persentase konsumsi.
Menentukan nilai yang harus Anda tetapkan untuk periode lihat balik dan persentase konsumsi mungkin memerlukan beberapa percobaan. Anda dapat menggunakan periode lihat balik default selama 60 menit sebagai titik awal. Untuk menentukan persentase konsumsi, pantau perilaku layanan untuk melihat persentase total anggaran error (selama periode kepatuhan) yang digunakan dalam 60 menit sebelumnya. Anda ingin menetapkan persentase penggunaan agar tidak menghabiskan lebih banyak anggaran error dalam periode lihat balik daripada yang Anda mampu, tetapi Anda tidak ingin memicu pemberitahuan yang tidak perlu.
Misalnya, Anda membuat SLO dengan nama berikut:
95% < 300ms Latency in Calendar Week
Dengan SLO ini, hanya 5% dari total jumlah permintaan dalam seminggu yang dapat memiliki latensi > 300 md. Mencapai atau melebihi 5% akan menghabiskan total anggaran error Anda. Jika
Anda menetapkan periode lihat balik ke satu jam, setiap periode lihat balik adalah 1/168 dari
periode kepatuhan Anda (satu minggu terdiri dari 168 jam). Untuk menghitung persentase konsumsi
per jam yang tidak melebihi total anggaran error untuk minggu ini:
5% ÷ 168 ≈ 0.03%
Karena latensi untuk Layanan Anda dapat berfluktuasi bergantung pada beban atau kondisi lain, menetapkan 0,03% sebagai persentase penggunaan dapat memicu pemberitahuan yang tidak perlu. Anda dapat memulai dengan nilai dua kali lipat, atau 0,06%, lalu memantau Layanan dan menyesuaikan nilai sesuai kebutuhan.
Sebelum memulai
Buat SLO untuk salah satu Layanan Anda.
Membuat kebijakan pemberitahuan di SLO
Buka tab Health untuk layanan:
Di Google Cloud konsol, buka Cloud Service Mesh.
Pilih project Google Cloud dari menu drop-down di panel menu.
Klik layanan yang ingin Anda buatkan kebijakan pemberitahuannya.
Di menu navigasi sebelah kiri, klik Kesehatan.
Klik SLO yang ingin Anda buat kebijakan pemberitahuannya.
Di bagian Status SLO Saat Ini di sebelah kanan, klik link Create Alerting Policy.
Dialog Tambahkan kondisi akan ditampilkan. Cloud Service Mesh akan otomatis mengisi kondisi Laju Pengeluaran SLO berdasarkan setelan di SLO. Anda mengonfigurasi kondisi Laju Pengeluaran SLO sehingga Anda mendapatkan pemberitahuan saat anggaran error SLO menurun terlalu cepat. Anda ingin memastikan bahwa Anda mendapatkan pemberitahuan sebelum SLO kehabisan anggaran error.
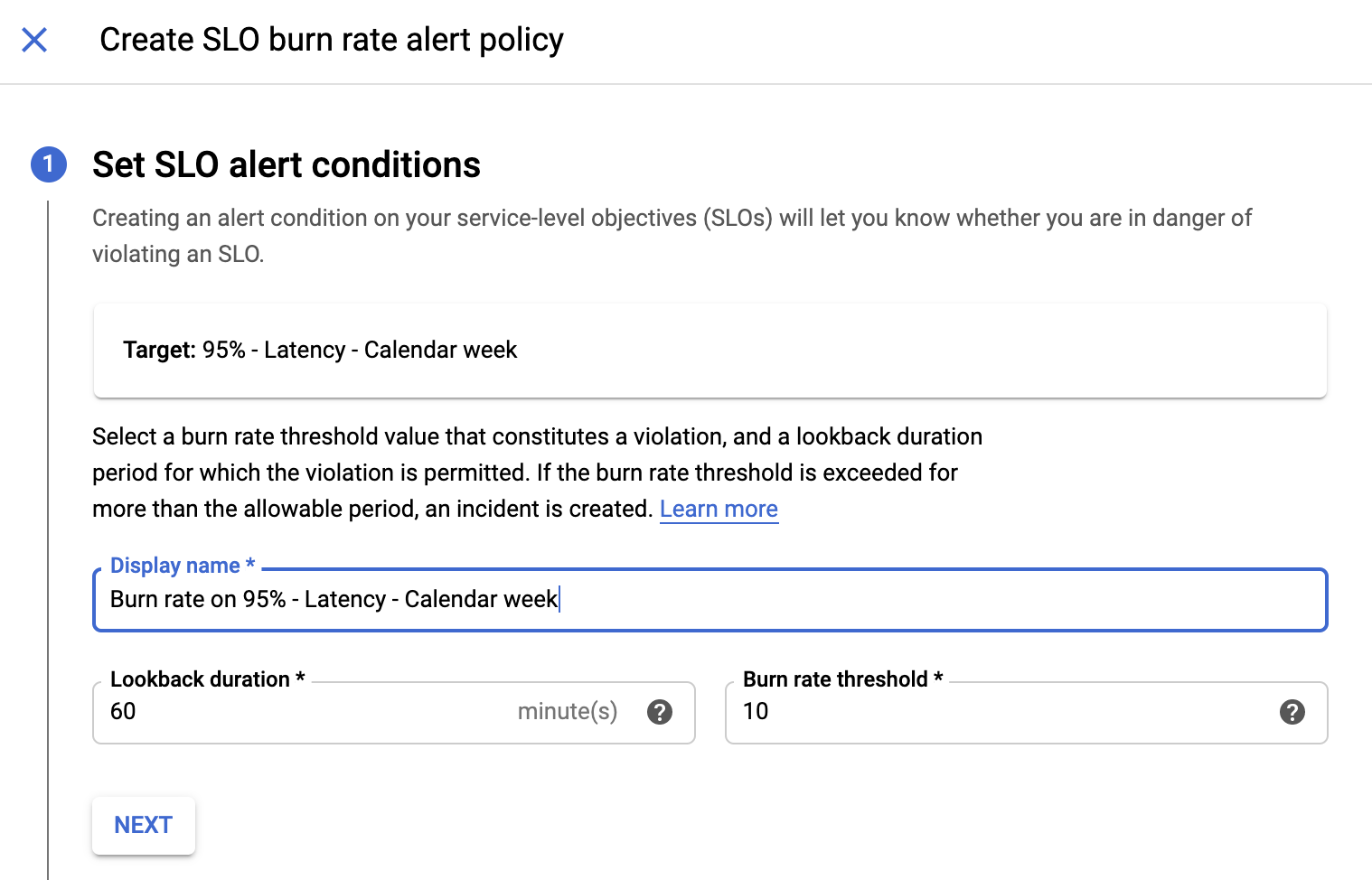
Konfigurasikan kondisi:
- Untuk memberi nama kondisi, klik link Judul yang disarankan untuk menggunakan nama berdasarkan SLO Anda, atau masukkan nama untuk kondisi tersebut.
- Di bagian Target, masukkan periode lihat balik di kolom Lookback Duration, atau gunakan nilai default.
- Di bagian Configuration, masukkan persentase penggunaan di kolom Threshold.
- Klik Simpan. Jendela Create new alerting policy akan ditampilkan.
Konfigurasikan kebijakan pemberitahuan:
- Masukkan nama kebijakan.
- Kondisi diisi secara otomatis, tetapi Anda dapat menambahkan kondisi lain secara opsional.
- Jika kebijakan pemberitahuan hanya memiliki satu kondisi, biarkan kolom Pemicu kebijakan pada nilai default Semua kondisi terpenuhi.
- Secara opsional, konfigurasikan bagian Notifikasi dan Dokumentasi. Lihat Mengelola kebijakan pemberitahuan untuk mengetahui informasi selengkapnya.
- Klik Simpan. Halaman Policy details akan ditampilkan.
- Untuk kembali ke dasbor Cloud Service Mesh, klik Navigation menu dehaze, lalu buka Anthos > Services.
Langkah berikutnya
Pelajari lebih lanjut pemberitahuan dari Site Reliability Engineering di Google: