Pseudonimisasi adalah teknik de-identifikasi yang mengganti nilai data sensitif dengan token yang dibuat secara kriptografis. Pseudonimisasi banyak digunakan di industri seperti keuangan dan layanan kesehatan untuk membantu mengurangi risiko data yang digunakan, mempersempit cakupan kepatuhan, dan meminimalkan eksposur data sensitif ke sistem sambil mempertahankan utilitas dan akurasi data.
Perlindungan Data Sensitif mendukung tiga teknik pseudonimisasi de-identifikasi, dan membuat token dengan menerapkan salah satu dari tiga metode transformasi kriptografi ke nilai data sensitif asli. Setiap nilai sensitif asli kemudian diganti dengan token yang sesuai. Pseudonimisasi terkadang disebut sebagai tokenisasi atau penggantian surrogate.
Teknik pseudonimisasi memungkinkan token satu arah atau dua arah. Token satu arah telah diubah secara tidak dapat dibalik, sedangkan token dua arah dapat dibalik. Karena token dibuat menggunakan enkripsi simetris, kunci kriptografi yang sama yang dapat membuat token baru juga dapat membalikkan token. Untuk situasi yang tidak memerlukan kemampuan untuk dibalikkan, Anda dapat menggunakan token satu arah yang menggunakan mekanisme hashing aman.
Penting untuk memahami bagaimana pseudonymisasi dapat membantu melindungi data sensitif sekaligus memungkinkan operasi bisnis dan alur kerja analisis Anda mengakses dan menggunakan data yang mereka butuhkan dengan mudah. Topik ini membahas konsep pseudonimisasi dan tiga metode kriptografi untuk mengubah data yang didukung oleh Perlindungan Data Sensitif.
Untuk mengetahui petunjuk tentang cara menerapkan metode pseudonymisasi ini dan contoh lainnya tentang penggunaan Sensitive Data Protection, lihat De-identifikasi data sensitif.
Metode kriptografi yang didukung di Sensitive Data Protection
Perlindungan Data Sensitif mendukung tiga teknik pseudonimisasi, yang semuanya menggunakan kunci kriptografi. Berikut adalah metode yang tersedia:
- Enkripsi deterministik menggunakan AES-SIV: Nilai input diganti dengan nilai yang telah dienkripsi menggunakan algoritma enkripsi AES-SIV dengan kunci kriptografi, dienkode menggunakan base64, lalu ditambahkan dengan anotasi pengganti, jika ditentukan. Metode ini menghasilkan nilai hash, sehingga tidak mempertahankan himpunan karakter atau panjang nilai input. Nilai yang dienkripsi dan di-hash dapat diidentifikasi ulang menggunakan kunci kriptografi asli dan seluruh nilai output, termasuk anotasi pengganti. Pelajari lebih lanjut format nilai yang di-token menggunakan enkripsi AES-SIV.
- Enkripsi yang mempertahankan format: Nilai input diganti dengan nilai yang telah dienkripsi menggunakan algoritma enkripsi FPE-FFX dengan kunci kriptografi, lalu ditambahkan dengan anotasi pengganti, jika ditentukan. Secara desain, himpunan karakter dan panjang nilai input dipertahankan dalam nilai output. Nilai terenkripsi dapat diidentifikasi ulang menggunakan kunci kriptografi asli dan seluruh nilai output, termasuk anotasi pengganti. (Untuk beberapa pertimbangan penting terkait penggunaan metode enkripsi ini, lihat Enkripsi yang mempertahankan format di bagian selanjutnya dalam topik ini.)
- Hashing kriptografi: Nilai input diganti dengan nilai yang telah dienkripsi dan di-hash menggunakan Hash-based Message Authentication Code (HMAC)-Secure Hash Algorithm (SHA)-256 pada nilai input dengan kunci kriptografi. Output hash transformasi selalu memiliki panjang yang sama dan tidak dapat diidentifikasi ulang. Pelajari lebih lanjut format nilai yang di-token menggunakan hashing kriptografi.
Metode pseudonimisasi ini dirangkum dalam tabel berikut. Baris tabel dijelaskan setelah tabel.
| Enkripsi deterministik menggunakan AES-SIV | Enkripsi dengan mempertahankan format | Hashing kriptografi | |
|---|---|---|---|
| Jenis enkripsi | AES-SIV | FPE-FFX | HMAC-SHA-256 |
| Nilai input yang didukung | Panjang minimal 1 karakter; tidak ada batasan set karakter. | Panjang minimal 2 karakter; harus dienkode sebagai ASCII. | Harus berupa nilai string atau bilangan bulat. |
| Anotasi pengganti | Opsional. | Opsional. | T/A |
| Penyesuaian konteks | Opsional. | Opsional. | T/A |
| Set karakter dan panjang dipertahankan | ✗ | ✓ | ✗ |
| Dapat dibalikkan (Reversible) | ✓ | ✓ | ✗ |
| Integritas referensial | ✓ | ✓ | ✓ |
- Jenis enkripsi: Jenis enkripsi yang digunakan dalam transformasi de-identifikasi.
- Nilai input yang didukung: Persyaratan minimum untuk nilai input.
- Anotasi pengganti: Anotasi yang ditentukan pengguna yang ditambahkan ke
nilai terenkripsi untuk memberikan konteks kepada pengguna dan memberikan informasi bagi
Perlindungan Data Sensitif untuk digunakan dalam identifikasi ulang nilai yang dide-identifikasi. Anotasi pengganti diperlukan untuk identifikasi ulang
data tidak terstruktur. Hal ini bersifat opsional saat mentransformasi kolom data terstruktur atau tabel dengan
RecordTransformation. - Penyesuaian konteks: Referensi ke kolom data yang "menyesuaikan" nilai input sehingga nilai input yang identik dapat diubah identitasnya menjadi nilai output yang berbeda. Penyesuaian konteks bersifat opsional saat mentransformasi kolom data terstruktur atau tabel dengan
RecordTransformation. Untuk mempelajari lebih lanjut, lihat Menggunakan penyesuaian konteks. - Himpunan karakter dan panjang dipertahankan: Apakah nilai yang di-de-identifikasi terdiri dari himpunan karakter yang sama dengan nilai aslinya, dan apakah panjang nilai yang di-de-identifikasi cocok dengan nilai aslinya.
- Dapat dibalik: Dapat diidentifikasi ulang menggunakan kunci kriptografi, anotasi pengganti, dan penyesuaian konteks apa pun.
- Integritas referensial: Integritas referensial memungkinkan kumpulan data mempertahankan hubungannya satu sama lain meskipun setelah data mereka dide-identifikasi secara terpisah. Dengan kunci kripto dan penyesuaian konteks yang sama, tabel data akan diganti dengan bentuk yang sama dan di-obfuscate setiap kali ditransformasikan, yang memastikan bahwa koneksi antar-nilai (dan, dengan data terstruktur, antar-catatan) dipertahankan, bahkan di seluruh tabel.
Cara kerja tokenisasi di Sensitive Data Protection
Proses dasar tokenisasi sama untuk ketiga metode yang didukung oleh Perlindungan Data Sensitif.
Langkah 1: Sensitive Data Protection memilih data yang akan di-tokenisasi. Cara paling umum untuk melakukannya adalah dengan menggunakan detektor infoType bawaan atau kustom untuk mencocokkan nilai data sensitif yang diinginkan. Jika Anda memindai data terstruktur (seperti tabel BigQuery), Anda juga dapat melakukan tokenisasi pada seluruh kolom data menggunakan transformasi rekaman.
Untuk mengetahui informasi selengkapnya tentang dua kategori transformasi—infoType dan transformasi kumpulan data—lihat Transformasi de-identifikasi.
Langkah 2: Menggunakan kunci kriptografis, Perlindungan Data Sensitif mengenkripsi setiap nilai input. Anda dapat memberikan kunci ini dengan salah satu dari tiga cara berikut:
- Dengan melapisinya menggunakan Cloud Key Management Service (Cloud KMS). (Untuk keamanan maksimum, Cloud KMS adalah metode yang lebih disukai.)
- Dengan menggunakan kunci sementara, yang dibuat oleh Perlindungan Data Sensitif pada saat de-identifikasi, lalu dihapus. Kunci sementara hanya menjaga integritas per permintaan API. Jika Anda memerlukan integritas atau berencana untuk mengidentifikasi ulang data ini, jangan gunakan jenis kunci ini.
- Langsung dalam bentuk teks mentah. (Tidak direkomendasikan.)
Untuk mengetahui detail selengkapnya, lihat bagian Menggunakan kunci kriptografi di bawah ini.
Langkah 3 (Hashing kriptografis dan enkripsi deterministik dengan AES-SIV saja): Perlindungan Data Sensitif mengenkode nilai terenkripsi menggunakan base64. Dengan hashing kriptografi, nilai terenkripsi yang dienkode ini adalah token, dan proses berlanjut dengan Langkah 6. Dengan enkripsi deterministik menggunakan AES-SIV, nilai terenkripsi yang dienkode ini adalah nilai pengganti, yang hanya merupakan satu komponen token. Proses berlanjut dengan Langkah 4.
Langkah 4 (Enkripsi deterministik dan yang mempertahankan format dengan AES-SIV saja):
Sensitive Data Protection menambahkan anotasi pengganti opsional ke nilai yang dienkripsi. Anotasi pengganti membantu mengidentifikasi nilai pengganti terenkripsi dengan menambahkan string deskriptif yang Anda tentukan di depannya. Misalnya, tanpa anotasi, Anda mungkin tidak dapat membedakan nomor telepon yang dianonimkan dengan nomor Jaminan Sosial atau nomor identifikasi lainnya yang dianonimkan. Selain itu,
untuk mengidentifikasi ulang nilai dalam data tidak terstruktur yang telah dide-identifikasi menggunakan
enkripsi yang mempertahankan format atau enkripsi deterministik, Anda harus
menentukan anotasi pengganti. (Anotasi pengganti tidak diperlukan saat
mentransformasi kolom data terstruktur atau tabel dengan
RecordTransformation.)
Langkah 5 (Enkripsi deterministik dan mempertahankan format dengan AES-SIV untuk data terstruktur saja): Sensitive Data Protection dapat menggunakan konteks opsional dari kolom lain untuk "menyesuaikan" token yang dihasilkan. Hal ini memungkinkan Anda mengubah cakupan token. Misalnya, Anda memiliki database data kampanye pemasaran yang mencakup alamat email dan Anda ingin membuat token unik untuk alamat email yang sama yang "diubah" oleh ID kampanye. Hal ini akan memungkinkan seseorang menggabungkan data untuk pengguna yang sama dalam kampanye yang sama, tetapi tidak di seluruh kampanye yang berbeda. Jika penyesuaian konteks digunakan untuk membuat token, maka penyesuaian konteks ini juga diperlukan agar transformasi de-identifikasi dapat dibatalkan. Enkripsi deterministik dan mempertahankan format menggunakan konteks dukungan AES-SIV. Pelajari lebih lanjut cara menggunakan penyesuaian konteks.
Langkah 6: Sensitive Data Protection mengganti nilai asli dengan nilai yang tidak teridentifikasi.
Perbandingan nilai yang di-token
Bagian ini menunjukkan tampilan token umum setelah dianonimkan menggunakan setiap dari tiga metode yang dibahas dalam topik ini. Contoh nilai data sensitif adalah nomor telepon Amerika Utara (1-206-555-0123).
Enkripsi deterministik menggunakan AES-SIV
Dengan penghapusan identitas menggunakan enkripsi deterministik dan AES-SIV, nilai input (dan, secara opsional, penyesuaian konteks yang ditentukan) dienkripsi menggunakan AES-SIV dengan kunci kriptografi, dienkode menggunakan base64, lalu secara opsional ditambahkan dengan anotasi pengganti, jika ditentukan. Metode ini tidak mempertahankan set karakter (atau "alfabet") nilai input. Untuk menghasilkan output yang dapat dicetak, nilai yang dihasilkan dienkode dalam base64.
Token yang dihasilkan, dengan asumsi infoType surrogate telah ditentukan, berbentuk:
SURROGATE_INFOTYPE(SURROGATE_VALUE_LENGTH):SURROGATE_VALUE
Diagram beranotasi berikut menunjukkan contoh token—output dari operasi penghapusan identitas menggunakan enkripsi deterministik dengan AES-SIV pada nilai 1-206-555-0123. InfoType surrogate opsional telah disetel ke
NAM_PHONE_NUMB:

- Anotasi pengganti
- InfoType surrogate (ditentukan oleh pengguna)
- Panjang karakter nilai yang diubah
- Nilai pengganti (yang diubah)
Jika Anda tidak menentukan anotasi pengganti, token yang dihasilkan sama dengan
nilai yang diubah, atau #4 dalam diagram yang diberi anotasi. Untuk mengidentifikasi ulang
data tidak terstruktur, seluruh token ini diperlukan, termasuk anotasi
pengganti. Saat mengubah data terstruktur seperti tabel, anotasi pengganti bersifat opsional; Sensitive Data Protection dapat melakukan de-identifikasi dan re-identifikasi pada seluruh kolom menggunakan
RecordTransformation
tanpa anotasi pengganti.
Enkripsi yang mempertahankan format
Dengan penghilangan identitas menggunakan enkripsi yang mempertahankan format, nilai input (dan, secara opsional, penyesuaian konteks yang ditentukan) dienkripsi menggunakan mode FFX dari enkripsi yang mempertahankan format ("FPE-FFX") dengan kunci kriptografi, lalu secara opsional ditambahkan dengan anotasi pengganti, jika ditentukan.
Tidak seperti metode tokenisasi lainnya yang dijelaskan dalam topik ini, nilai pengganti output memiliki panjang yang sama dengan nilai input, dan tidak dienkode menggunakan base64. Anda menentukan set karakter—atau "alfabet"—yang membentuk nilai terenkripsi. Ada tiga cara untuk menentukan alfabet yang akan digunakan Perlindungan Data Sensitif dalam nilai output:
- Gunakan salah satu dari empat nilai yang di-enum yang mewakili empat set karakter/alfabet yang paling umum.
- Gunakan nilai radix, yang menentukan ukuran alfabet. Menentukan
nilai radix minimum
2akan menghasilkan alfabet yang hanya terdiri dari0dan1. Menentukan nilai radix maksimum95akan menghasilkan alfabet yang mencakup semua karakter numerik, karakter alfa huruf besar, karakter alfa huruf kecil, dan karakter simbol. - Buat alfabet dengan mencantumkan karakter persis yang akan digunakan. Misalnya, jika Anda menentukan
1234567890-*, nilai pengganti yang dihasilkan hanya akan terdiri dari angka, tanda hubung, dan tanda bintang.
Tabel berikut mencantumkan empat set karakter umum berdasarkan nilai yang dihitung
untuk masing-masing set
(FfxCommonNativeAlphabet),
nilai radix, dan daftar karakter set. Baris terakhir mencantumkan set karakter lengkap, yang sesuai dengan nilai radix maksimum.
| Nama set karakter/alfabet | Radix | Daftar karakter |
|---|---|---|
NUMERIC |
10 |
0123456789 |
HEXADECIMAL |
16 |
0123456789ABCDEF |
UPPER_CASE_ALPHA_NUMERIC |
36 |
0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ |
ALPHA_NUMERIC |
62 |
0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz |
| - | 95 |
0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz~`!@#$%^&*()_-+={[}]|\:;"'<,>.?/ |
Token yang dihasilkan, dengan asumsi infoType surrogate telah ditentukan, adalah dalam bentuk:
SURROGATE_INFOTYPE(SURROGATE_VALUE_LENGTH):SURROGATE_VALUE
Diagram beranotasi berikut adalah output dari operasi de-identifikasi Sensitive Data Protection menggunakan enkripsi yang mempertahankan format pada nilai 1-206-555-0123 menggunakan radix 95. InfoType surrogate opsional telah ditetapkan ke NAM_PHONE_NUMB:
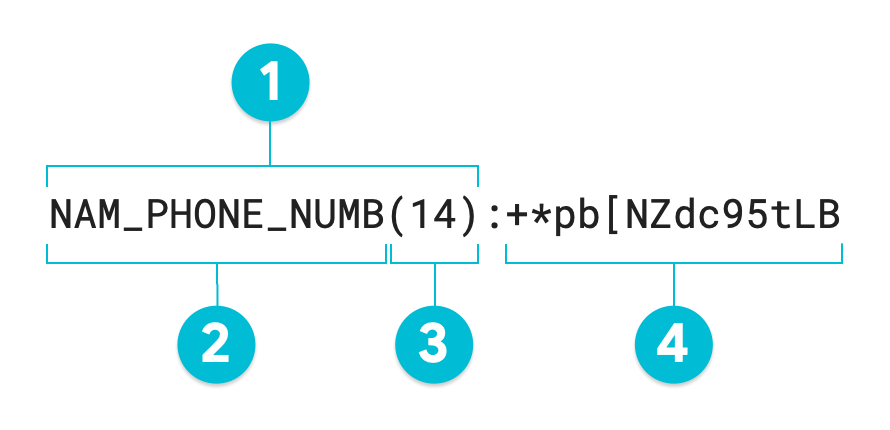
- Anotasi pengganti
- InfoType surrogate (ditentukan oleh pengguna)
- Panjang karakter nilai yang diubah
- Nilai pengganti (yang diubah)—panjang yang sama dengan nilai input
Jika Anda tidak menentukan anotasi pengganti, token yang dihasilkan sama dengan
nilai yang diubah, atau #4 dalam diagram yang diberi anotasi. Untuk mengidentifikasi ulang
data tidak terstruktur, seluruh token ini diperlukan, termasuk anotasi
pengganti. Saat mengubah data terstruktur seperti tabel, anotasi pengganti bersifat opsional; Sensitive Data Protection dapat melakukan de-identifikasi dan identifikasi ulang pada seluruh kolom menggunakan RecordTransformation tanpa pengganti.
Hashing kriptografi
Dengan de-identifikasi menggunakan hashing kriptografi, nilai input di-hash menggunakan HMAC-SHA-256 dengan kunci kriptografi, lalu dienkode menggunakan base64. Nilai yang di-de-identifikasi selalu memiliki panjang yang seragam, bergantung pada ukuran kunci.
Tidak seperti metode tokenisasi lainnya yang dibahas dalam topik ini, hashing kriptografi membuat token satu arah. Artinya, penghapusan identitas menggunakan hashing kriptografi tidak dapat dibatalkan.
Berikut adalah output operasi de-identifikasi menggunakan hashing kriptografi
pada nilai 1-206-555-0123. Output ini adalah representasi
nilai hash berenkode base64:
XlTCv8h0GwrCZK+sS0T3Z8txByqnLLkkF4+TviXfeZY=
Menggunakan kunci kriptografi
Ada tiga opsi untuk kunci kriptografis yang dapat Anda gunakan dengan metode de-identifikasi kriptografis di Perlindungan Data Sensitif:
Kunci kriptografis yang digabungkan Cloud KMS: Ini adalah jenis kunci kriptografis paling aman yang tersedia untuk digunakan dengan metode de-identifikasi Perlindungan Data Sensitif. Kunci gabungan Cloud KMS terdiri dari kunci kriptografis 128, 192, atau 256 bit yang telah dienkripsi menggunakan kunci lain. Anda menyediakan kunci kriptografi pertama, yang kemudian di-wrap menggunakan kunci kriptografi yang disimpan di Cloud Key Management Service. Jenis kunci ini disimpan di Cloud KMS untuk identifikasi ulang di kemudian hari. Untuk mengetahui informasi selengkapnya tentang cara membuat dan mengenkapsulasi kunci untuk tujuan penghapusan identitas dan identifikasi ulang, lihat Panduan memulai: Menghapus identitas dan mengidentifikasi ulang teks sensitif.
Kunci kriptografis sementara: Kunci kriptografis sementara dibuat oleh Perlindungan Data Sensitif pada saat de-identifikasi, lalu dihapus. Oleh karena itu, jangan gunakan kunci kriptografis sementara dengan metode de-identifikasi kriptografi yang ingin Anda batalkan. Kunci kriptografis sementara hanya menjaga integritas per permintaan API. Jika Anda memerlukan integritas di lebih dari satu permintaan API atau berencana mengidentifikasi ulang data Anda, jangan gunakan jenis kunci ini.
Kunci kriptografis yang tidak digabungkan: Kunci yang tidak digabungkan adalah kunci kriptografis 128, 192, atau 256 bit berenkode base64 mentah yang Anda berikan di dalam permintaan penghapusan identifikasi ke DLP API. Anda bertanggung jawab untuk menjaga keamanan jenis kunci kriptografi ini untuk identifikasi ulang di kemudian hari. Karena risiko kebocoran kunci secara tidak sengaja, jenis kunci ini tidak direkomendasikan. Kunci ini dapat berguna untuk pengujian, tetapi untuk beban kerja produksi, sebaiknya gunakan kunci kriptografis yang digabungkan dengan Cloud KMS.
Untuk mempelajari lebih lanjut opsi yang tersedia saat menggunakan kunci kriptografis, lihat
CryptoKey
dalam referensi DLP API.
Menggunakan penyesuaian konteks
Secara default, semua metode transformasi kriptografi de-identifikasi memiliki integritas referensial, baik token output bersifat satu arah maupun dua arah. Artinya, dengan kunci kriptografi yang sama, nilai input akan selalu diubah menjadi nilai terenkripsi yang sama. Dalam situasi ketika data atau pola data berulang mungkin terjadi, risiko identifikasi ulang meningkat. Untuk memastikan nilai input yang sama selalu diubah menjadi nilai terenkripsi yang berbeda, Anda dapat menentukan penyesuaian konteks yang unik.
Anda menentukan penyesuaian konteks (yang hanya disebut sebagai
context
di DLP API) saat mentransformasi data tabular, karena penyesuaian tersebut
secara efektif merupakan penunjuk ke kolom data, seperti ID.
Sensitive Data Protection menggunakan nilai di kolom yang ditentukan oleh penyesuaian konteks saat mengenkripsi nilai input. Untuk memastikan bahwa nilai terenkripsi selalu merupakan nilai unik, tentukan kolom untuk tweak yang berisi ID unik.
Perhatikan contoh sederhana ini. Tabel berikut menunjukkan beberapa catatan medis, beberapa di antaranya menyertakan ID pasien duplikat.
| record_id | patient_id | icd10_code |
|---|---|---|
| 5437 | 43789 | E11.9 |
| 5438 | 43671 | M25.531 |
| 5439 | 43789 | N39.0, I25.710 |
| 5440 | 43766 | I10 |
| 5441 | 43766 | I10 |
| 5442 | 42989 | R07.81 |
| 5443 | 43098 | I50.1, R55 |
| ... | ... | ... |
Jika Anda menginstruksikan Perlindungan Data Sensitif untuk melakukan de-identifikasi ID pasien dalam tabel, ID pasien yang berulang akan di-de-identifikasi ke nilai yang sama secara default, seperti yang ditunjukkan dalam tabel berikut. Misalnya, kedua instance ID pasien
"43789" diubah menjadi "47222". (Kolom patient_id menampilkan nilai token setelah pseudonymisasi menggunakan FPE-FFX dan tidak menyertakan anotasi pengganti. Lihat Enkripsi yang mempertahankan format untuk mengetahui informasi selengkapnya.)
| record_id | patient_id | icd10_codes |
|---|---|---|
| 5437 | 47222 | E11.9 |
| 5438 | 82160 | M25.531 |
| 5439 | 47222 | N39.0, I25.710 |
| 5440 | 04452 | I10 |
| 5441 | 04452 | I10 |
| 5442 | 47826 | R07.81 |
| 5443 | 52428 | I50.1, R55 |
| ... | ... | ... |
Artinya, cakupan integritas referensial mencakup seluruh set data.
Untuk mempersempit cakupan sehingga Anda menghindari perilaku ini, tentukan penyesuaian konteks. Anda dapat menentukan kolom apa pun sebagai penyesuaian konteks, tetapi untuk menjamin bahwa setiap nilai yang di-anonimkan bersifat unik, tentukan kolom yang setiap nilainya unik.
Misalkan Anda ingin melihat apakah pasien yang sama muncul per nilai icd10_codes, tetapi tidak jika pasien yang sama muncul dalam nilai icd10_codes yang berbeda. Untuk
melakukannya, Anda akan menentukan kolom icd10_codes sebagai penyesuaian konteks.
Berikut tabel setelah menghapus identitas kolom patient_id menggunakan kolom
icd10_codes sebagai penyesuaian konteks:
| record_id | patient_id | icd10_codes |
|---|---|---|
| 5437 | 18954 | E11.9 |
| 5438 | 33068 | M25.531 |
| 5439 | 76368 | N39.0, I25.710 |
| 5440 | 29460 | I10 |
| 5441 | 29460 | I10 |
| 5442 | 23877 | R07.81 |
| 5443 | 96129 | I50.1, R55 |
| ... | ... | ... |
Perhatikan bahwa nilai patient_id keempat dan kelima yang tidak diidentifikasi (29460) sama karena tidak hanya nilai patient_id asli yang identik, nilai icd10_codes kedua baris juga identik. Karena Anda perlu menjalankan analisis dengan ID pasien yang konsisten dalam cakupan nilai icd10_codes, perilaku ini adalah yang Anda cari.
Untuk sepenuhnya memutuskan integritas referensial antara nilai patient_id dan nilai icd10_codes, Anda dapat menggunakan kolom record_id sebagai penyesuaian konteks:
| record_id | patient_id | icd10_code |
|---|---|---|
| 5437 | 15826 | E11.9 |
| 5438 | 61722 | M25.531 |
| 5439 | 34424 | N39.0, I25.710 |
| 5440 | 02875 | I10 |
| 5441 | 52549 | I10 |
| 5442 | 17945 | R07.81 |
| 5443 | 19030 | I50.1, R55 |
| ... | ... | ... |
Perhatikan bahwa setiap nilai patient_id yang dide-identifikasi dalam tabel kini bersifat unik.
Untuk mempelajari cara menggunakan penyesuaian konteks di DLP API, perhatikan penggunaan context dalam topik referensi metode transformasi berikut:
- Enkripsi dengan mempertahankan format:
CryptoReplaceFfxFpeConfig - Enkripsi deterministik menggunakan AES-SIV:
CryptoDeterministicConfig - Perubahan tanggal:
DateShiftConfig
Langkah berikutnya
Lihat contoh kode yang menunjukkan cara melakukan tokenisasi data sensitif.
Pelajari cara menghilangkan identitas data menggunakan DLP API.